हाल ही में, मैं उस कार्यक्षमता के विकास में शामिल था जिसके लिए डिस्क पर बड़ी मात्रा में डेटा का तेज़ और लगातार स्थानांतरण आवश्यक था। इसके अलावा, इस डेटा को समय-समय पर डिस्क से पढ़ा जाना चाहिए था। इसलिए, मुझे इस डेटा को संग्रहीत करने का स्थान, तरीका और साधन खोजने के लिए नियत किया गया था। इस लेख में, मैं संक्षेप में कार्य की समीक्षा करूंगा, साथ ही इस कार्य को पूरा करने के लिए समाधानों की जांच और तुलना करूंगा।
कार्य का प्रसंग :मैं एक टीम में काम करता हूं जो सापेक्ष डेटाबेस विकास (एसक्यूएल सर्वर, माईएसक्यूएल, ओरेकल) के लिए उपकरण विकसित करता है। टूल श्रेणी में एमएस एसएसएमएस के लिए स्टैंडअलोन टूल और ऐड-इन्स दोनों शामिल हैं।
कार्य :IDE के अगले प्रारंभ में IDE के बंद होने के समय खोले गए दस्तावेज़ों को पुनर्स्थापित करना।
यूज़केस :कौन-से दस्तावेज़ सहेजे गए और कौन-से नहीं, यह सोचे बिना कि कार्यालय से निकलने से पहले आईडीई को शीघ्रता से बंद करना। आईडीई की अगली शुरुआत में, हमें वही वातावरण प्राप्त करने की आवश्यकता है जो बंद होने के समय था और काम जारी रखना चाहिए। काम के सभी परिणामों को अव्यवस्थित रूप से बंद होने के समय सहेजा जाना चाहिए, उदा। किसी प्रोग्राम या ऑपरेटिंग सिस्टम के क्रैश होने के दौरान, या पावर-ऑफ के दौरान।
कार्य विश्लेषण :वैसी ही सुविधा वेब ब्राउज़र में मौजूद है। हालाँकि, ब्राउज़र केवल उन्हीं URL को संग्रहीत करते हैं जिनमें लगभग 100 प्रतीक होते हैं। हमारे मामले में, हमें संपूर्ण दस्तावेज़ सामग्री को संग्रहीत करने की आवश्यकता है। इसलिए, हमें उपयोगकर्ता के दस्तावेज़ों को सहेजने और संग्रहीत करने के लिए एक स्थान की आवश्यकता होती है। क्या अधिक है, कभी-कभी उपयोगकर्ता अन्य भाषाओं की तुलना में SQL के साथ भिन्न तरीके से कार्य करते हैं। उदाहरण के लिए, यदि मैं 1000 से अधिक पंक्तियों की सी # कक्षा लिखता हूं, तो यह शायद ही स्वीकार्य होगा। जबकि, SQL ब्रह्मांड में, 10-20-पंक्ति प्रश्नों के साथ, राक्षसी डेटाबेस डंप मौजूद हैं। ऐसे डंप शायद ही संपादन योग्य हों, जिसका अर्थ है कि उपयोगकर्ता अपने संपादनों को सुरक्षित रखना पसंद करेंगे।
भंडारण की आवश्यकताएं:
- यह एक हल्का एम्बेडेड समाधान होना चाहिए।
- उच्च लेखन गति होनी चाहिए।
- इसमें मल्टीप्रोसेसिंग एक्सेस का विकल्प होना चाहिए। यह आवश्यकता महत्वपूर्ण नहीं है, क्योंकि हम सिंक्रोनाइज़ेशन ऑब्जेक्ट्स की मदद से एक्सेस सुनिश्चित कर सकते हैं, लेकिन फिर भी, यह विकल्प होना अच्छा होगा।
उम्मीदवार
पहला उम्मीदवार बल्कि अनाड़ी है, वह है सब कुछ एक फ़ोल्डर में, कहीं AppData में संग्रहीत करना।
दूसरा उम्मीदवार स्पष्ट है - SQLite, एम्बेडेड डेटाबेस का एक मानक। बहुत मजबूत और लोकप्रिय उम्मीदवार।
तीसरा उम्मीदवार लाइटडीबी डेटाबेस है। यह Google में ".net के लिए एम्बेडेड डेटाबेस" क्वेरी के लिए पहला परिणाम है।
पहली नजर
फाइल सिस्टम। फ़ाइलें फ़ाइलें हैं, उन्हें रखरखाव और उचित नामकरण की आवश्यकता होती है। फ़ाइल सामग्री के अलावा, हमें गुणों का एक छोटा सेट (डिस्क पर मूल पथ, कनेक्शन स्ट्रिंग, आईडीई का संस्करण, जिसमें इसे खोला गया था) को संग्रहीत करने की आवश्यकता होगी। इसका मतलब है कि हमें या तो एक दस्तावेज़ के लिए दो फाइलें बनानी होंगी, या एक ऐसे प्रारूप का आविष्कार करना होगा जो गुणों को सामग्री से अलग करता है।
SQLite एक क्लासिक रिलेशनल डेटाबेस है। डेटाबेस को डिस्क पर एक फ़ाइल द्वारा दर्शाया जाता है। इस फाइल को डेटाबेस स्कीमा के साथ बांधा जा रहा है, जिसके बाद हमें SQL माध्यमों की मदद से इसके साथ इंटरैक्ट करना होता है। हम 2 टेबल बनाने में सक्षम होंगे, एक प्रॉपर्टीज के लिए, और दूसरा कंटेंट के लिए, - अगर हमें प्रॉपर्टीज या कंटेंट को अलग से इस्तेमाल करने की आवश्यकता होगी।
लाइटडीबी एक गैर-संबंधपरक डेटाबेस है। SQLite के समान, डेटाबेस को एकल फ़ाइल द्वारा दर्शाया जाता है। यह पूरी तरह से С#में लिखा है। इसमें आकर्षक उपयोग सरलता है:हमें केवल पुस्तकालय को एक वस्तु देने की आवश्यकता है, जबकि क्रमांकन अपने स्वयं के माध्यम से किया जाएगा।
प्रदर्शन परीक्षण
कोड प्रदान करने से पहले, मैं सामान्य अवधारणा की व्याख्या करना चाहता हूं और तुलना परिणाम प्रदान करना चाहता हूं।
सामान्य अवधारणा डेटाबेस में बड़ी मात्रा में छोटी फाइलों को लिखने की गति, औसत फाइलों की औसत मात्रा और बड़ी फाइलों की एक छोटी मात्रा की तुलना कर रही है। औसत फाइलों वाला मामला ज्यादातर वास्तविक मामले के करीब होता है, जबकि छोटी और बड़ी फाइलों वाले मामले सीमावर्ती मामले होते हैं, जिन्हें भी ध्यान में रखा जाना चाहिए।
मैं मानक बफर आकार के साथ फ़ाइलस्ट्रीम की सहायता से फ़ाइल में सामग्री लिख रहा था।
SQLite में एक बारीकियां थी जिसका मैं उल्लेख करना चाहूंगा। हम सभी दस्तावेज़ सामग्री (जैसा कि मैंने ऊपर उल्लेख किया है, वे वास्तव में बड़े हो सकते हैं) को एक डेटाबेस सेल में रखने में असमर्थ थे। बात यह है कि अनुकूलन उद्देश्यों के लिए, हम दस्तावेज़ टेक्स्ट लाइन को लाइन से स्टोर करते हैं। इसका मतलब यह है कि टेक्स्ट को एक सेल में डालने के लिए, हमें सभी दस्तावेज़ों को एक ही पंक्ति में रखना होगा, जो इस्तेमाल की गई ऑपरेटिंग मेमोरी की मात्रा को दोगुना कर देगा। समस्या का दूसरा पक्ष डेटाबेस से पढ़े गए डेटा के दौरान खुद को प्रकट करेगा। इसलिए, SQLite में एक अलग तालिका थी, जहाँ डेटा को पंक्ति दर पंक्ति संग्रहीत किया जाता था और डेटा को केवल फ़ाइल गुणों वाली तालिका के साथ विदेशी कुंजी की सहायता से जोड़ा जाता था। इसके अलावा, मैं लॉगिंग के बिना और एक लेनदेन के भीतर ऑफ सिंक्रोनाइज़ेशन मोड में बैच डेटा इंसर्ट (एक बार में कई हजार पंक्तियों) के साथ डेटाबेस को गति देने में कामयाब रहा।
लाइटडीबी को एक ऑब्जेक्ट प्राप्त हुआ जिसमें उसके गुणों के बीच सूची थी और लाइब्रेरी ने इसे अपने आप डिस्क पर सहेज लिया।
परीक्षण अनुप्रयोग के विकास के दौरान, मैं समझ गया कि मैं लाइटडीबी पसंद करता हूं। बात यह है कि SQLite के लिए परीक्षण कोड 120 पंक्तियों से अधिक लेता है, जबकि कोड, जो लाइटडीबी में एक ही समस्या को हल करता है, केवल 20 पंक्तियां लेता है।
डेटा निर्माण का परीक्षण करें
FileStrings.cs
internal class FileStrings {
private static readonly Random random = new Random();
public List Strings {
get;
set;
} = new List();
public int SomeInfo {
get;
set;
}
public FileStrings() {
}
public FileStrings(int id, int minLines, decimal lineIncrement) {
SomeInfo = id;
int lines = minLines + (int)(id * lineIncrement);
for (int i = 0; i < lines; i++) {
Strings.Add(GetString());
}
}
private string GetString() {
int length = 250;
StringBuilder builder = new StringBuilder(length);
for (int i = 0; i < length; i++) { builder.Append(random.Next((int)'a', (int)'z')); } return builder.ToString(); } } Program.cs List files = Enumerable.Range(1, NUM_FILES + 1) .Select(f => new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES))
.ToList();
SQLite
private static void SaveToDb(List files) {
using (var connection = new SQLiteConnection()) {
connection.ConnectionString = @"Data Source=data\database.db;FailIfMissing=False;";
connection.Open();
var command = connection.CreateCommand();
command.CommandText = @"CREATE TABLE files
(
id INTEGER PRIMARY KEY,
file_name TEXT
);
CREATE TABLE strings
(
id INTEGER PRIMARY KEY,
string TEXT,
file_id INTEGER,
line_number INTEGER
);
CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number);
PRAGMA synchronous = OFF;
PRAGMA journal_mode = OFF";
command.ExecuteNonQuery();
var insertFilecommand = connection.CreateCommand();
insertFilecommand.CommandText = "INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();";
insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter());
insertFilecommand.Prepare();
var insertLineCommand = connection.CreateCommand();
insertLineCommand.CommandText = "INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);";
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Prepare();
foreach (var item in files) {
using (var tr = connection.BeginTransaction()) {
SaveToDb(item, insertFilecommand, insertLineCommand);
tr.Commit();
}
}
}
}
private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) {
string fileName = Path.Combine("data", item.SomeInfo + ".sql");
insertFileCommand.Parameters[0].Value = fileName;
var fileId = insertFileCommand.ExecuteScalar();
int lineIndex = 0;
foreach (var line in item.Strings) {
insertLinesCommand.Parameters[0].Value = line;
insertLinesCommand.Parameters[1].Value = fileId;
insertLinesCommand.Parameters[2].Value = lineIndex++;
insertLinesCommand.ExecuteNonQuery();
}
} लाइटडीबी
private static void SaveToNoSql(List item) {
using (var db = new LiteDatabase("data\\litedb.db")) {
var data = db.GetCollection("files");
data.EnsureIndex(f => f.SomeInfo);
data.Insert(item);
}
}
निम्न तालिका परीक्षण कोड के कई रनों के लिए औसत परिणाम दिखाती है। संशोधनों के दौरान, सांख्यिकीय विचलन काफी समझ से बाहर था।
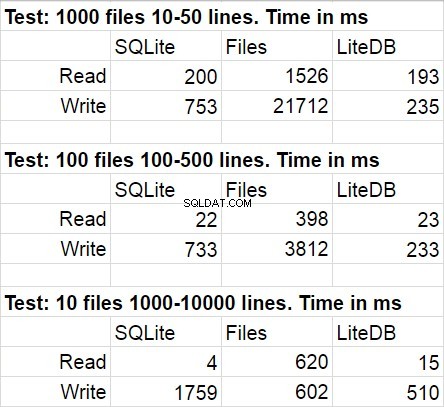
मुझे आश्चर्य नहीं हुआ कि लाइटडीबी ने इस तुलना में जीत हासिल की। हालाँकि, मैं फाइलों पर लाइटडीबी की जीत से हैरान था। लाइब्रेरी रिपॉजिटरी के एक संक्षिप्त अध्ययन के बाद, मैंने डिस्क पर पेजिनल राइट टू डिस्क को बहुत सावधानी से लागू किया, लेकिन मुझे यकीन है कि यह वहां उपयोग की जाने वाली कई प्रदर्शन चालों में से एक है। एक और बात जो मैं इंगित करना चाहता हूं वह यह है कि जब फ़ोल्डर में फाइलों की मात्रा वास्तव में बड़ी हो जाती है तो फाइल सिस्टम एक्सेस की तेज गति कम हो जाती है।
हमने अपनी सुविधा के विकास के लिए लाइटडीबी का चयन किया, और हमें इस विकल्प के बारे में शायद ही कोई पछतावा हो। बात यह है कि पुस्तकालय सभी सी # के लिए मूल में लिखा गया है, और अगर कुछ भी स्पष्ट नहीं था, तो हम हमेशा स्रोत कोड का उल्लेख कर सकते थे।
विपक्ष
अपने दावेदारों की तुलना में लाइटडीबी के उपर्युक्त पेशेवरों के अलावा, हमने विकास के दौरान विपक्ष को देखना शुरू कर दिया। इनमें से अधिकांश विपक्ष को पुस्तकालय के 'युवाओं' द्वारा समझाया जा सकता है। 'मानक' परिदृश्य की सीमाओं से थोड़ा परे पुस्तकालय का उपयोग शुरू करने के बाद, हमने कई मुद्दों (#419, #420, #483, #496) की खोज की। पुस्तकालय के लेखक ने प्रश्नों के उत्तर काफी तेजी से दिए, और अधिकांश समस्याओं का समाधान शीघ्रता से किया गया। अब, केवल एक ही कार्य बचा है (इसकी बंद स्थिति से भ्रमित न हों)। यह प्रतिस्पर्धी पहुंच का मुद्दा है। ऐसा लगता है कि पुस्तकालय में कहीं गहराई में बहुत ही खराब दौड़-स्थिति छिपी हुई है। हमने इस बग को काफी मूल तरीके से पारित किया (मैं इस विषय पर एक अलग लेख लिखने का इरादा रखता हूं)।
मैं साफ-सुथरे संपादक और दर्शक की अनुपस्थिति का भी उल्लेख करना चाहूंगा। लाइटडीबीशेल है, लेकिन केवल सच्चे कंसोल प्रशंसकों के लिए है।
सारांश
हमने लाइटडीबी पर एक बड़ी और महत्वपूर्ण कार्यक्षमता का निर्माण किया है, और अब हम एक और बड़ी सुविधा पर काम कर रहे हैं जहां हम इस पुस्तकालय का भी उपयोग करेंगे। इन-प्रोसेस डेटाबेस की तलाश करने वालों के लिए, मैं लाइटडीबी पर ध्यान देने का सुझाव देता हूं और जिस तरह से यह आपके कार्य के संदर्भ में खुद को साबित करेगा, क्योंकि जैसा कि आप जानते हैं, अगर कुछ एक कार्य के लिए काम करता है, तो यह जरूरी नहीं होगा दूसरे काम के लिए कसरत करें।