मैंने पहले वास्तविक पंक्तियों को पढ़ें संपत्ति के बारे में लिखा था। यह आपको बताता है कि इंडेक्स सीक द्वारा वास्तव में कितनी पंक्तियों को पढ़ा जाता है, ताकि आप देख सकें कि सीक प्रेडिकेट की चयनात्मकता की तुलना में सीक प्रेडिकेट कितना चयनात्मक है, साथ ही अवशिष्ट विधेय संयुक्त है।
लेकिन आइए एक नजर डालते हैं कि वास्तव में सीक ऑपरेटर के अंदर क्या चल रहा है। क्योंकि मुझे विश्वास नहीं है कि "वास्तविक पंक्तियाँ पढ़ें" अनिवार्य रूप से एक सटीक विवरण है कि क्या हो रहा है।
मैं एक उदाहरण देखना चाहता हूं जो एक ग्राहक के लिए विशेष प्रकार के पते के प्रश्नों का पता लगाता है, लेकिन यहां सिद्धांत आसानी से कई अन्य स्थितियों पर लागू होगा यदि आपकी क्वेरी का आकार फिट बैठता है, जैसे कि की-वैल्यू पेयर टेबल में विशेषताओं को देखना, उदाहरण के लिए।
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
मुझे पता है कि मैंने आपको मेटाडेटा के बारे में कुछ नहीं दिखाया है - मैं एक मिनट में उस पर वापस आऊंगा। आइए इस प्रश्न के बारे में सोचें और हम इसके लिए किस प्रकार का अनुक्रमणिका चाहते हैं।
सबसे पहले, हम CustomerID को ठीक-ठीक जानते हैं। इस तरह का एक समानता मैच आम तौर पर इसे एक इंडेक्स में पहले कॉलम के लिए एक उत्कृष्ट उम्मीदवार बनाता है। यदि हमारे पास इस कॉलम पर एक इंडेक्स होता तो हम सीधे उस ग्राहक के पते में गोता लगा सकते थे - इसलिए मैं कहूंगा कि यह एक सुरक्षित धारणा है।
विचार करने वाली अगली बात यह है कि एड्रेस टाइप आईडी पर फ़िल्टर करें। हमारे इंडेक्स की चाबियों में दूसरा कॉलम जोड़ना पूरी तरह से उचित है, तो चलिए ऐसा करते हैं। हमारी अनुक्रमणिका अब चालू है (CustomerID, AddressTypeID)। और चलिए FullAddress भी शामिल करते हैं, ताकि हमें चित्र को पूरा करने के लिए कोई लुकअप करने की आवश्यकता न पड़े।
और मुझे लगता है कि हम कर चुके हैं। हमें सुरक्षित रूप से यह मानने में सक्षम होना चाहिए कि इस क्वेरी के लिए आदर्श अनुक्रमणिका है:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
हम संभावित रूप से इसे एक अद्वितीय अनुक्रमणिका के रूप में घोषित कर सकते हैं - हम बाद में इसके प्रभाव को देखेंगे।
तो चलिए एक टेबल बनाते हैं (मैं tempdb का उपयोग कर रहा हूं, क्योंकि मुझे इस ब्लॉग पोस्ट से आगे बने रहने की आवश्यकता नहीं है) और इसका परीक्षण करें।
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
मुझे विदेशी कुंजी बाधाओं में दिलचस्पी नहीं है, या अन्य कौन से कॉलम हो सकते हैं। मुझे केवल अपने आदर्श सूचकांक में दिलचस्पी है। तो उसे भी बनाएं, अगर आपने पहले से नहीं बनाया है।
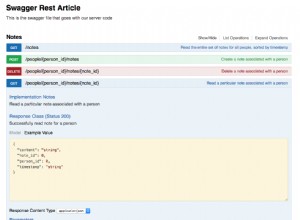
मेरी योजना बहुत अच्छी लगती है।
मेरे पास एक इंडेक्स सीक है, और बस यही है।
दी, कोई डेटा नहीं है, इसलिए कोई रीड नहीं है, कोई सीपीयू नहीं है, और यह बहुत जल्दी चलता है। यदि केवल सभी प्रश्नों को इसके साथ ही ट्यून किया जा सकता है।
आइए देखें कि सीक के गुणों को देखकर थोड़ा और करीब से क्या हो रहा है।
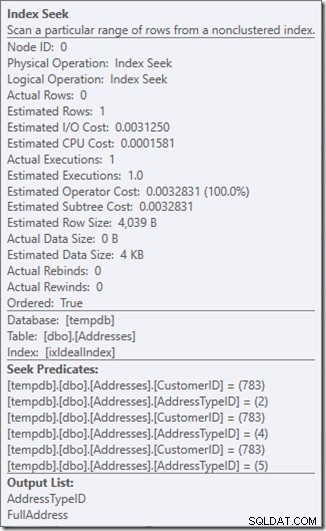
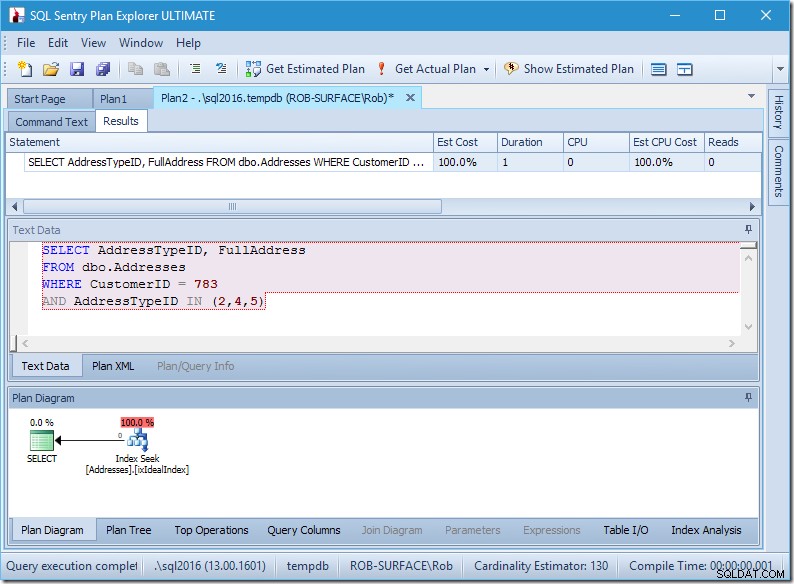
हम सीक प्रेडिकेट्स देख सकते हैं। कुल छः हैं। तीन CustomerID के बारे में, और तीन AddressTypeID के बारे में। हमारे यहां वास्तव में सीक विधेय के तीन सेट हैं, जो सिंगल सीक ऑपरेटर के भीतर तीन सीक ऑपरेशंस को दर्शाता है। पहली तलाश ग्राहक 783 और पता प्रकार 2 की तलाश में है। दूसरा 783 और 4 की तलाश में है, और अंतिम 783 और 5 की तलाश में है। हमारा सीक ऑपरेटर एक बार दिखाई दिया, लेकिन इसके अंदर तीन तलाश चल रही थीं।
हमारे पास डेटा भी नहीं है, लेकिन हम देख सकते हैं कि हमारी अनुक्रमणिका का उपयोग कैसे किया जाएगा।
आइए कुछ डमी डेटा डालें, ताकि हम इसके कुछ प्रभावों को देख सकें। मैं टाइप 1 से 6 के लिए पते डालने जा रहा हूं। प्रत्येक ग्राहक (2000 से अधिक, master..spt_values के आकार के आधार पर) ) में टाइप 1 का पता होगा। हो सकता है कि वह प्राथमिक पता हो। मैं 80% को टाइप 2 एड्रेस, 60% टाइप 3, और इसी तरह, टाइप 5 के लिए 20% तक की अनुमति दे रहा हूं। पंक्ति 783 को टाइप 1, 2, 3, और 4 के पते मिलेंगे, लेकिन 5 नहीं। मैं इसके बजाय यादृच्छिक मूल्यों के साथ गया होता, लेकिन मैं यह सुनिश्चित करना चाहता हूं कि हम उदाहरणों के लिए एक ही पृष्ठ पर हैं।
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; अब डेटा के साथ हमारी क्वेरी को देखें। दो पंक्तियाँ निकल रही हैं। यह पहले की तरह है, लेकिन अब हम दो पंक्तियों को सीक ऑपरेटर से निकलते हुए देखते हैं, और हम छह रीड्स (ऊपर-दाईं ओर) देखते हैं।
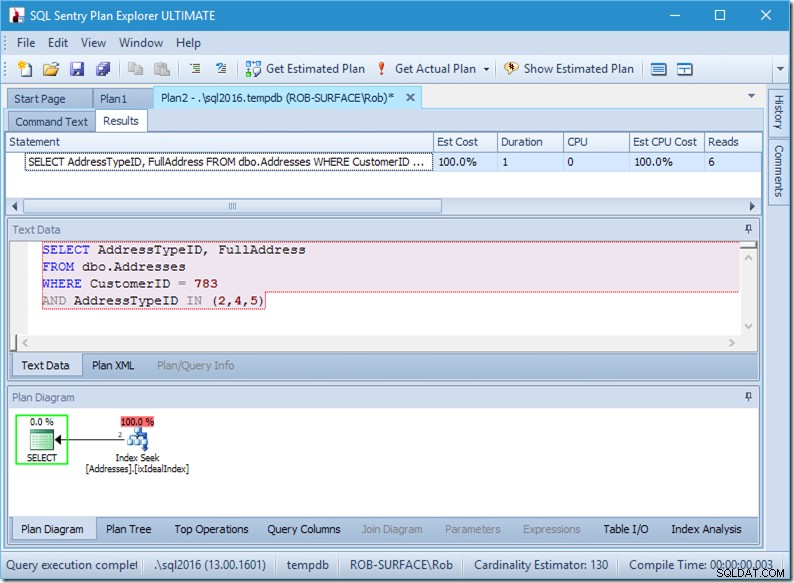
छह पढ़ना मुझे समझ में आता है। हमारे पास एक छोटी सी तालिका है, और सूचकांक सिर्फ दो स्तरों पर फिट बैठता है। हम तीन खोज कर रहे हैं (हमारे एक ऑपरेटर के भीतर), इसलिए इंजन रूट पेज पढ़ रहा है, यह पता लगा रहा है कि किस पेज पर जाना है और उसे पढ़ना है, और तीन बार ऐसा करना है।
यदि हम केवल दो एड्रेस टाइप आईडी की तलाश करते हैं, तो हम केवल 4 रीड्स देखेंगे (और इस मामले में, एक पंक्ति आउटपुट की जा रही है)। बहुत बढ़िया।
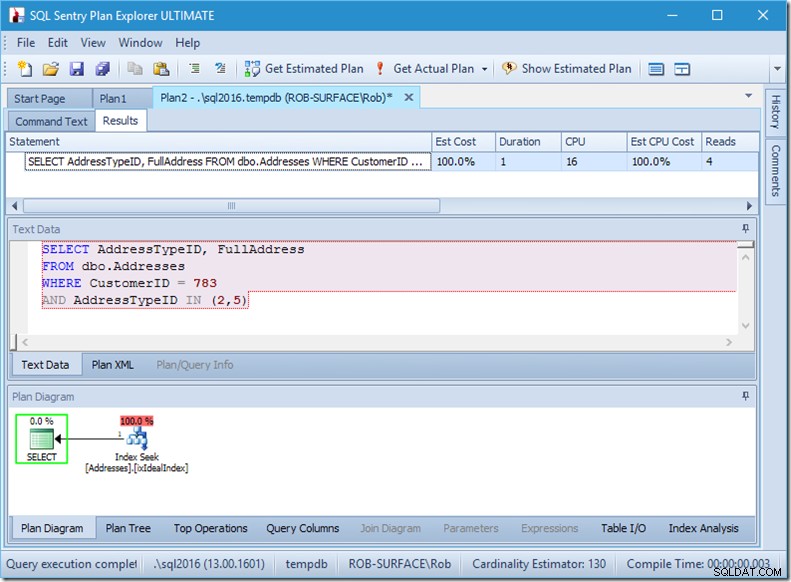
और अगर हम 8 प्रकार के पते ढूंढ रहे थे, तो हमें 16 दिखाई देंगे।
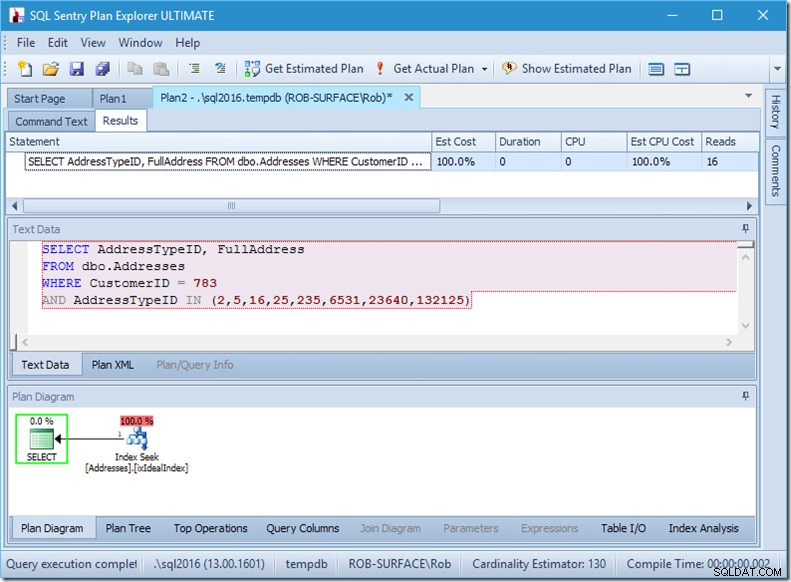
फिर भी इनमें से प्रत्येक दिखाता है कि वास्तविक पंक्तियाँ वास्तविक पंक्तियों से बिल्कुल मेल खाती हैं। कोई अक्षमता बिल्कुल नहीं!
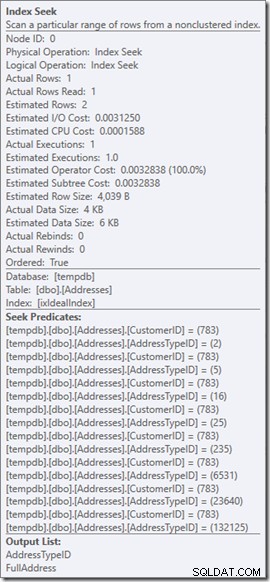
आइए अपनी मूल क्वेरी पर वापस जाएं, पता प्रकार 2, 4, और 5, (जो 2 पंक्तियों को लौटाता है) की तलाश में है और इस बारे में सोचें कि खोज के अंदर क्या हो रहा है।
मुझे लगता है कि क्वेरी इंजन ने यह पता लगाने के लिए पहले ही काम कर लिया है कि इंडेक्स सीक सही ऑपरेशन है, और इसमें इंडेक्स रूट का पेज नंबर आसान है।
इस बिंदु पर, यह उस पृष्ठ को स्मृति में लोड करता है, यदि वह पहले से मौजूद नहीं है। यह पहला पठन है जो तलाश के निष्पादन में गिना जाता है। फिर यह उस पंक्ति के लिए पृष्ठ संख्या का पता लगाता है जिसे वह ढूंढ रहा है, और उस पृष्ठ को पढ़ता है। यह दूसरा पढ़ा है।
लेकिन हम अक्सर इस बात पर प्रकाश डालते हैं कि 'पेज नंबर' बिट का पता लगाता है।
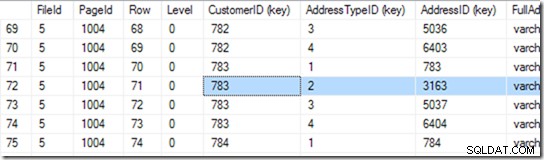
DBCC IND(2, N'dbo.Address', 2); . का उपयोग करके (पहला 2 डेटाबेस आईडी है क्योंकि मैं tempdb का उपयोग कर रहा हूँ; दूसरा 2 ixIdealIndex . की अनुक्रमणिका आईडी है ), मुझे पता चल सकता है कि फ़ाइल 1 में 712 उच्चतम इंडेक्सलेवल वाला पृष्ठ है। नीचे स्क्रीनशॉट में, मैं देख सकता हूं कि पेज 668 इंडेक्सलेवल 0 है, जो रूट पेज है।

तो अब मैं DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); पृष्ठ 712 की सामग्री देखने के लिए। मेरी मशीन पर, मुझे 84 पंक्तियाँ वापस आ रही हैं, और मैं बता सकता हूँ कि CustomerID 783 फ़ाइल 5 के पृष्ठ 1004 पर होने जा रहा है।
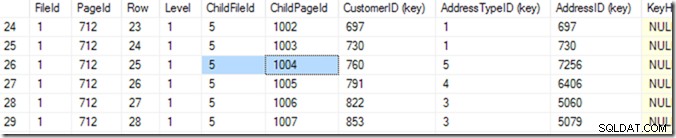
लेकिन मैं इसे अपनी सूची में स्क्रॉल करके जानता हूं जब तक कि मुझे वह नहीं मिल जाता जो मैं चाहता हूं। मैंने थोड़ा नीचे स्क्रॉल करके शुरू किया, और फिर वापस ऊपर आया, जब तक कि मुझे वह पंक्ति नहीं मिल गई जो मुझे चाहिए थी। एक कंप्यूटर इसे एक द्विआधारी खोज कहता है, और यह मुझसे थोड़ा अधिक सटीक है। यह उस पंक्ति की तलाश में है जहां (ग्राहक आईडी, पता टाइप आईडी) संयोजन छोटा है जिसे मैं ढूंढ रहा हूं, अगला पृष्ठ बड़ा या उसके जैसा ही है। मैं "वही" कहता हूं क्योंकि दो पेज में फैले दो मैच हो सकते हैं। यह जानता है कि उस पृष्ठ में डेटा की 84 पंक्तियाँ (0 से 83) हैं (यह पृष्ठ शीर्षलेख में पढ़ता है), इसलिए यह पंक्ति 41 की जाँच करके शुरू होगा। वहाँ से, यह जानता है कि कौन सा आधा खोजना है, और (में यह उदाहरण), यह पंक्ति 20 को पढ़ेगा। कुछ और पढ़ता है (कुल मिलाकर 6 या 7 बनाता है)* और यह जानता है कि पंक्ति 25 (कृपया इस मान के लिए 'पंक्ति' नामक कॉलम देखें, एसएसएमएस द्वारा प्रदान की गई पंक्ति संख्या नहीं। ) बहुत छोटा है, लेकिन पंक्ति 26 बहुत बड़ी है - इसलिए 25 उत्तर है!
*द्विआधारी खोज में, यदि मध्य स्लॉट न होने पर ब्लॉक को दो भागों में विभाजित कर देता है, और इस पर निर्भर करता है कि मध्य स्लॉट को हटाया जा सकता है या नहीं, तो यह भाग्यशाली होने पर खोज थोड़ी तेज हो सकती है।
अब यह फ़ाइल 5 में पेज 1004 में जा सकता है। आइए उस पर DBCC पेज का उपयोग करें।
यह मुझे 94 पंक्तियाँ देता है। यह उस श्रेणी की शुरुआत खोजने के लिए एक और बाइनरी खोज करता है जिसे वह ढूंढ रहा है। इसे खोजने के लिए इसे 6 या 7 पंक्तियों में देखना होगा।
"सीमा की शुरुआत?" मैं सुन सकता हूँ तुम पूछते हो। लेकिन हम ग्राहक 783 का पता टाइप 2 ढूंढ रहे हैं।
ठीक है, लेकिन हमने इस इंडेक्स को यूनिक घोषित नहीं किया। तो दो हो सकते हैं। यदि यह अद्वितीय है, तो खोज सिंगलटन खोज कर सकती है, और बाइनरी खोज के दौरान इसे पार कर सकती है, लेकिन इस मामले में, इसे श्रेणी में पहली पंक्ति खोजने के लिए बाइनरी खोज को पूरा करना होगा। इस मामले में, यह पंक्ति 71 है।
लेकिन हम यहीं नहीं रुकते। अब हमें यह देखने की जरूरत है कि क्या वास्तव में कोई दूसरा है! तो यह पंक्ति 72 को भी पढ़ता है, और पाता है कि CustomerID+AddressTypeiD जोड़ी वास्तव में बहुत बड़ी है, और इसकी तलाश पूरी हो गई है।
और ऐसा तीन बार होता है। तीसरी बार, उसे ग्राहक 783 और पता प्रकार 5 के लिए कोई पंक्ति नहीं मिली, लेकिन उसे यह समय से पहले पता नहीं था, और उसे अभी भी खोज को पूरा करने की आवश्यकता है।
तो वास्तव में इन तीनों खोजों में पढ़ी जा रही पंक्तियों (आउटपुट में दो पंक्तियों को खोजने के लिए) लौटाई जा रही संख्या से बहुत अधिक है। सूचकांक स्तर 1 पर लगभग 7 हैं, और केवल सीमा की शुरुआत का पता लगाने के लिए लीफ स्तर पर लगभग 7 और हैं। फिर यह उस पंक्ति को पढ़ता है जिसकी हम परवाह करते हैं, और फिर उसके बाद की पंक्ति। यह मेरे लिए 16 से अधिक की तरह लगता है, और यह तीन बार ऐसा करता है, जिससे लगभग 48 पंक्तियाँ बनती हैं।
लेकिन वास्तविक पंक्तियाँ पढ़ें वास्तव में पढ़ी जाने वाली पंक्तियों की संख्या के बारे में नहीं है, बल्कि सीक प्रेडिकेट द्वारा लौटाई गई पंक्तियों की संख्या है, जो अवशिष्ट विधेय के विरुद्ध परीक्षण की जाती हैं। और उसमें, यह केवल 2 पंक्तियाँ हैं जो 3 खोज द्वारा पाई जाती हैं।
आप इस बिंदु पर सोच रहे होंगे कि यहाँ एक निश्चित मात्रा में अप्रभावीता है। दूसरा खोज पृष्ठ 712 को भी पढ़ेगा, वहां वही 6 या 7 पंक्तियों की जाँच करेगा, और फिर पृष्ठ 1004 को पढ़ेगा, और इसके माध्यम से शिकार करेगा ... जैसा कि तीसरा खोज होगा।
तो शायद इसे एक ही खोज में प्राप्त करना बेहतर होगा, पृष्ठ 712 और पृष्ठ 1004 प्रत्येक को केवल एक बार पढ़ना। आखिरकार, अगर मैं इसे कागज-आधारित प्रणाली के साथ कर रहा होता, तो मैं ग्राहक 783 को खोजने की कोशिश करता, और फिर उनके सभी प्रकार के पते के माध्यम से स्कैन करता। क्योंकि मुझे पता है कि ग्राहक के पास कई पते नहीं होते हैं। यह एक फायदा है जो मेरे पास डेटाबेस इंजन पर है। डेटाबेस इंजन अपने आँकड़ों के माध्यम से जानता है कि एक खोज सबसे अच्छा होगा, लेकिन यह नहीं जानता कि खोज केवल एक स्तर नीचे जाना चाहिए, जब यह बता सके कि इसमें आदर्श सूचकांक जैसा दिखता है।
यदि मैं 2 से 5 तक, कई प्रकार के पते प्राप्त करने के लिए अपनी क्वेरी बदलता हूं, तो मुझे लगभग वैसा ही व्यवहार मिलता है जैसा मैं चाहता हूं:
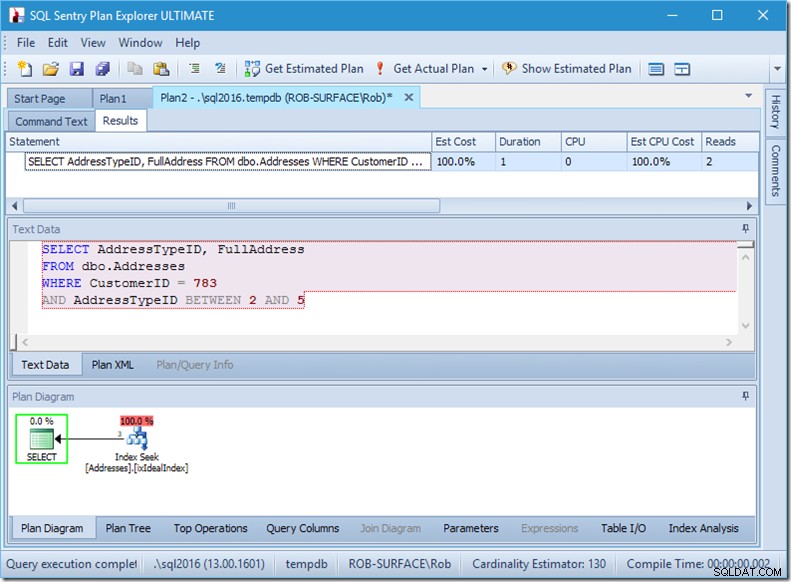
देखो - पढ़ने की संख्या 2 से नीचे है, और मुझे पता है कि वे कौन से पृष्ठ हैं...
...लेकिन मेरे परिणाम गलत हैं। क्योंकि मुझे केवल पता प्रकार 2, 4, और 5 चाहिए, न कि 3। मुझे यह बताना है कि 3 नहीं है, लेकिन मुझे सावधान रहना होगा कि मैं यह कैसे करूं। अगले दो उदाहरण देखें।
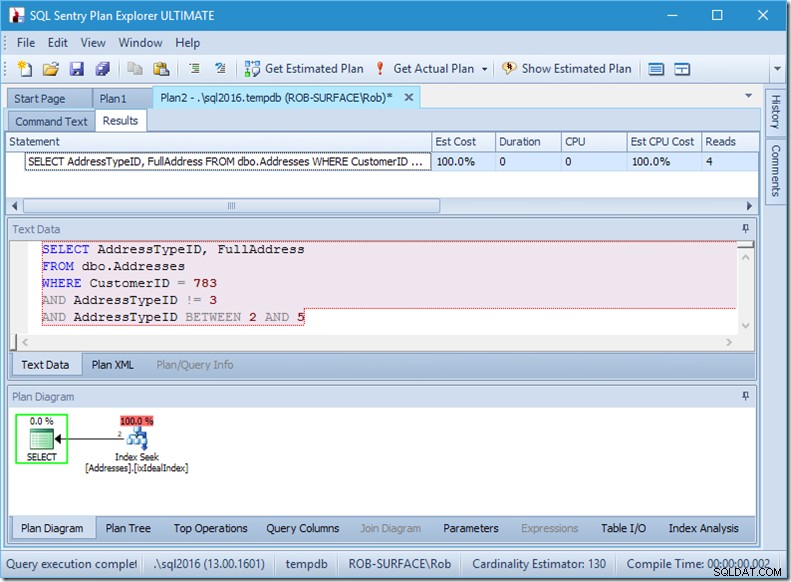
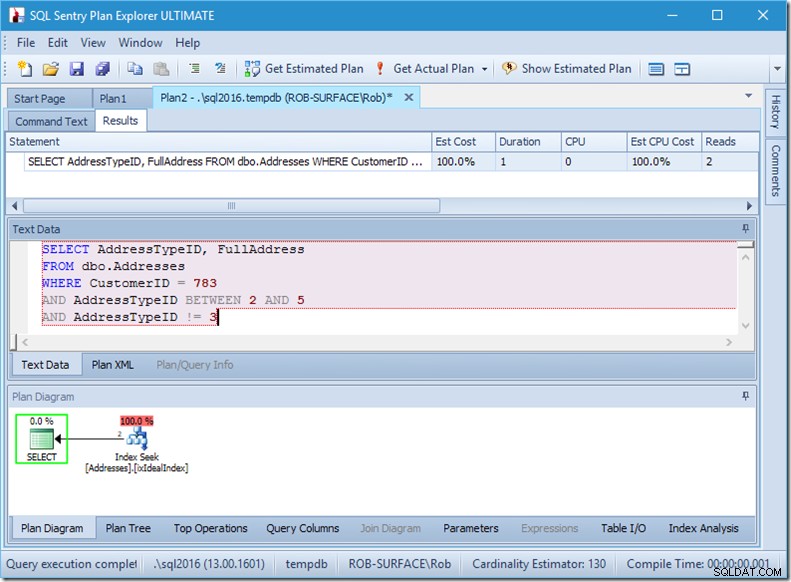
मैं आपको आश्वस्त कर सकता हूं कि विधेय आदेश कोई मायने नहीं रखता, लेकिन यहां यह स्पष्ट रूप से करता है। यदि हम पहले "3 नहीं" डालते हैं, तो यह दो खोज करता है (4 पढ़ता है), लेकिन अगर हम "3 नहीं" सेकेंड डालते हैं, तो यह एक ही खोज (2 पढ़ता है)।
समस्या यह है कि AddressTypeID !=3 (AddressTypeID> 3 OR AddressTypeID <3) में परिवर्तित हो जाता है, जिसे तब दो बहुत उपयोगी खोज विधेय के रूप में देखा जाता है।
और इसलिए मेरी प्राथमिकता यह बताने के लिए एक गैर-सूक्ष्म विधेय का उपयोग करना है कि मुझे केवल पता प्रकार 2, 4, और 5 चाहिए। और मैं इसे किसी तरह से AddressTypeID को संशोधित करके कर सकता हूं, जैसे कि इसमें शून्य जोड़ना।
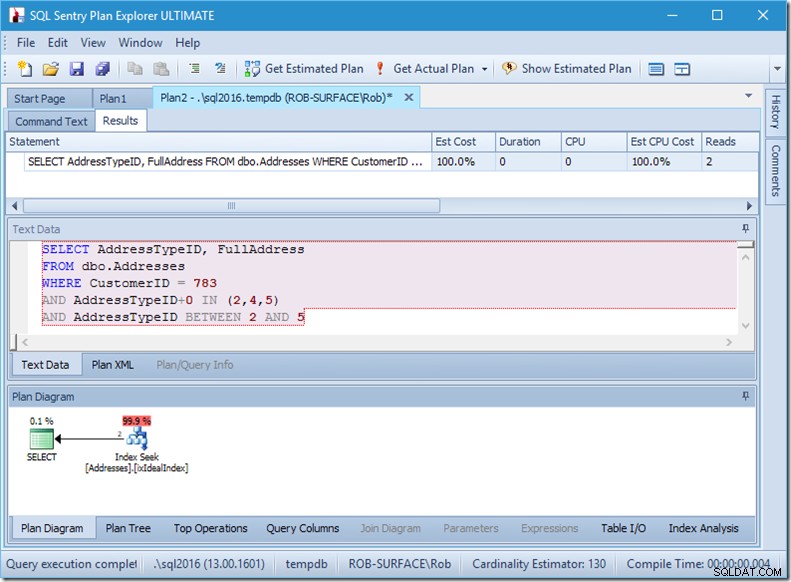
अब मेरे पास एक ही खोज के भीतर एक अच्छा और तंग रेंज स्कैन है, और मैं अभी भी यह सुनिश्चित कर रहा हूं कि मेरी क्वेरी केवल वही पंक्तियां लौटा रही है जो मैं चाहता हूं।
ओह, लेकिन वह वास्तविक पंक्तियाँ संपत्ति पढ़ें? यह अब वास्तविक पंक्तियों की संपत्ति से अधिक है, क्योंकि सीक प्रेडिकेट को पता प्रकार 3 मिलता है, जिसे अवशिष्ट विधेय अस्वीकार करता है।
मैंने एक अपूर्ण खोज के लिए तीन संपूर्ण खोज का व्यापार किया है, जिसे मैं एक अवशिष्ट विधेय के साथ ठीक कर रहा हूं।
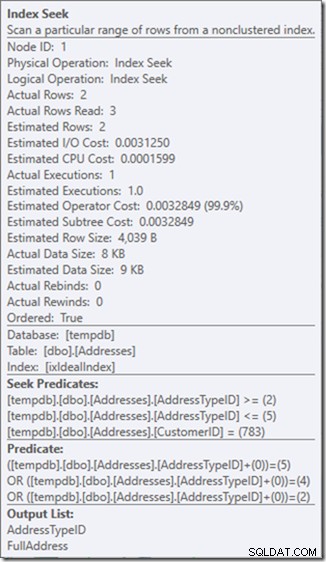
और मेरे लिए, यह कभी-कभी भुगतान करने लायक कीमत होती है, जिससे मुझे एक प्रश्न योजना मिलती है जिसके बारे में मैं बहुत खुश हूं। यह काफी सस्ता नहीं है, भले ही इसमें केवल एक तिहाई पठन हैं (क्योंकि कभी-कभी केवल दो भौतिक पठन होंगे), लेकिन जब मैं उस काम के बारे में सोचता हूं जो मैं कर रहा हूं, तो मैं जो पूछ रहा हूं उसके साथ मैं अधिक सहज हूं ऐसा करने के लिए।