IRI अब अपने मुफ़्त डेटाबेस और फ़्लैट-फ़ाइल प्रोफाइलिंग टूल दोनों में, और डेटा गुणवत्ता, सुरक्षा और MDM क्षमताओं को बढ़ाने के लिए IRI CoSort, FieldShield, और Voracity में उपलब्ध फ़ील्ड-फ़ंक्शन लाइब्रेरी के रूप में फ़ज़ी खोज फ़ंक्शन भी प्रदान कर रहा है। आईआरआई फजी सर्च सॉल्यूशंस पर लेखों की श्रृंखला में यह पहला लेख है जिसमें डेटा गुणवत्ता सुधार के लिए उनके आवेदन को शामिल किया गया है।
परिचय
डेटा और उद्यम सूचना प्रबंधन के संदर्भ में आईआरआई एट अल के बारे में बात करने वाले बड़े 'वी' शब्दों (वॉल्यूम, विविधता, वेग और मूल्य के साथ) के डेटा की सत्यता या विश्वसनीयता। आम तौर पर, आईआरआई संदेह में डेटा को इन विशेषताओं में से एक या अधिक होने के रूप में परिभाषित करता है:
- निम्न गुणवत्ता, क्योंकि यह असंगत, गलत या अपूर्ण है
- अस्पष्ट (एमडीएम सोचें), सटीक (असंरचित), या भ्रामक (सोशल मीडिया)
- पक्षपातपूर्ण (सर्वेक्षण प्रश्न), शोर (अनावश्यक या दूषित), या असामान्य (बाहरी)
- किसी अन्य कारण से अमान्य (क्या डेटा अपने इच्छित उपयोग के लिए सही और सटीक है?)
- असुरक्षित - क्या इसमें PII या रहस्य हैं, और क्या यह ठीक से नकाबपोश, प्रतिवर्ती, आदि है?
यह आलेख केवल पहली समस्या, डेटा गुणवत्ता के नए फ़ज़ी खोज समाधानों पर केंद्रित है। इस ब्लॉग के अन्य लेख चर्चा करते हैं कि आईआरआई सॉफ्टवेयर अन्य चार सत्यता समस्याओं का समाधान कैसे करता है; यदि आप नहीं कर सकते तो उन्हें ढूंढने में सहायता मांगें।
अस्पष्ट खोज के बारे में
फ़ज़ी खोजों में ऐसे शब्द या वाक्यांश (मान) मिलते हैं जो दूसरे शब्दों या वाक्यांशों (मानों) से मिलते-जुलते हैं, लेकिन ज़रूरी नहीं कि एक जैसे हों। इस प्रकार की खोज के कई उपयोग हैं, जैसे अनुक्रम त्रुटियां, वर्तनी त्रुटियां, ट्रांसपोज़्ड वर्ण, और अन्य जिन्हें हम बाद में कवर करेंगे।
अनुमानित शब्दों या वाक्यांशों के लिए अस्पष्ट खोज करने से उस डेटा को खोजने में मदद मिल सकती है जो पहले संग्रहीत डेटा का डुप्लिकेट हो सकता है। हालांकि, उपयोगकर्ता इनपुट या स्वतः सुधार ने रिकॉर्ड को स्वतंत्र दिखाने के लिए डेटा को किसी तरह से बदल दिया हो सकता है।
शेष लेख में चार अस्पष्ट खोज फ़ंक्शन शामिल होंगे जिनका IRI अब समर्थन करता है, उनका उपयोग कैसे करें अपने डेटा को खंगालने के लिए, और उन रिकॉर्ड को वापस करें जो खोज मूल्य का अनुमान लगाते हैं।
1. लेवेनशेटिन
लेवेनशेटिन एल्गोरिथम दो शब्दों या वाक्यांशों को लेकर काम करता है, और यह गिनता है कि एक शब्द या वाक्यांश को दूसरे में बदलने के लिए कितने संपादन चरण लगेंगे। यह जितने कम कदम उठाएगा, शब्द या वाक्यांश के मेल होने की संभावना उतनी ही अधिक होगी। लेवेनशेटिन फंक्शन निम्नलिखित कदम उठा सकता है:
- किसी वर्ण को शब्द या वाक्यांश में सम्मिलित करना
- शब्द या वाक्यांश से किसी वर्ण को हटाना
- किसी शब्द या वाक्यांश के एक वर्ण को दूसरे वर्ण से बदलना
निम्नलिखित एक CoSort SortCL प्रोग्राम (जॉब स्क्रिप्ट) है जो दिखाता है कि लेवेनशेटिन फ़ज़ी सर्च फ़ंक्शन का उपयोग कैसे किया जाता है:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
वांछित आउटपुट उत्पन्न करने के लिए दो भागों का उपयोग किया जाना चाहिए।
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
यह लाइन फ़ंक्शन fs_levenshtein को कॉल करती है, और परिणाम को FS_RESULT फ़ील्ड में संग्रहीत करती है। फ़ंक्शन दो इनपुट पैरामीटर लेता है:
- फ़ज़ी खोज चलाने के लिए फ़ील्ड (हमारे उदाहरण में NAME)
- वह स्ट्रिंग जिससे इनपुट फ़ील्ड की तुलना की जाएगी (हमारे उदाहरण में ("बार्नी ओकले")।
/INCLUDE WHERE FS_RESULT GT 50
यह लाइन FS_RESULT फ़ील्ड की तुलना करती है और जाँचती है कि क्या यह 50 से अधिक है, तो केवल 50 से अधिक के FS_RESULT वाले रिकॉर्ड आउटपुट हैं। निम्नलिखित हमारे उदाहरण से आउटपुट दिखाता है।

जैसा कि आउटपुट दिखाता है कि इस प्रकार की खोज खोजने के लिए उपयोगी है:
- सम्मिलित नाम
- शोर
- वर्तनी की त्रुटियां
- स्थानांतरित वर्ण
- ट्रांसक्रिप्शन गलतियां
- टाइपिंग त्रुटियां
इस प्रकार लेवेनशेटिन फ़ंक्शन सामान्य डेटा प्रविष्टि त्रुटियों की पहचान करने के लिए भी उपयोगी है। हालांकि, चार एल्गोरिदम में से प्रदर्शन करने में सबसे लंबा समय लगता है, क्योंकि यह एक स्ट्रिंग में प्रत्येक वर्ण की तुलना दूसरे वर्ण से करता है।
<मजबूत>2. पासा गुणांक
पासा गुणांक, या पासा एल्गोरिथ्म, शब्दों या वाक्यांशों को वर्ण जोड़े में तोड़ता है, उन जोड़ियों की तुलना करता है, और मैचों की गणना करता है। शब्दों के जितने अधिक मेल होंगे, उतनी ही अधिक संभावना होगी कि शब्द स्वयं एक मिलान हो।
निम्न SortCL स्क्रिप्ट पासा गुणांक फ़ज़ी खोज फ़ंक्शन को प्रदर्शित करती है।
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
हमें वांछित आउटपुट देने के लिए दो भागों का उपयोग किया जाना चाहिए।
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
यह लाइन फ़ंक्शन fs_dice को कॉल करती है, और परिणाम को FS_RESULT फ़ील्ड में संग्रहीत करती है। फ़ंक्शन दो इनपुट पैरामीटर लेता है:
- फ़ज़ी खोज चलाने के लिए फ़ील्ड (हमारे उदाहरण में NAME)।
- वह स्ट्रिंग जिससे इनपुट फ़ील्ड की तुलना की जाएगी (हमारे उदाहरण में "रॉबर्ट थॉमस स्मिथ")।
/INCLUDE WHERE FS_RESULT GT 50
यह लाइन FS_RESULT फ़ील्ड की तुलना करती है और जाँचती है कि क्या यह 50 से अधिक है, तो केवल 50 से अधिक के FS_RESULT वाले रिकॉर्ड आउटपुट हैं। निम्नलिखित हमारे उदाहरण से आउटपुट दिखाता है।
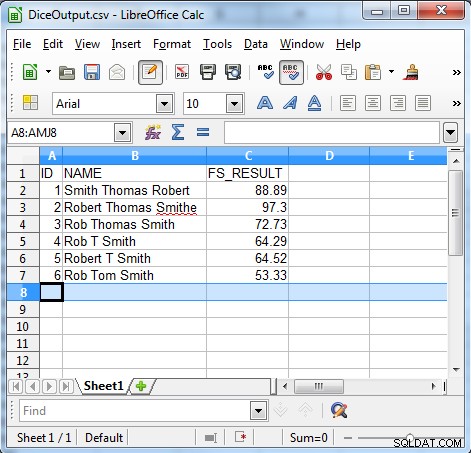
जैसा कि आउटपुट दिखाता है कि पासा गुणांक एल्गोरिथ्म असंगत डेटा खोजने के लिए उपयोगी है जैसे:
- अनुक्रम त्रुटियां
- अनैच्छिक सुधार
- उपनाम
- आद्याक्षर और उपनाम
- आद्याक्षर का अप्रत्याशित उपयोग
- स्थानीयकरण
डाइस एल्गोरिथम लेवेनशेटिन की तुलना में तेज़ है, लेकिन टाइपो जैसी कई सरल त्रुटियां होने पर कम सटीक हो सकता है।
<बी>3. मेटाफोन और 4. साउंडेक्स
मेटाफोन और साउंडेक्स एल्गोरिदम शब्दों या वाक्यांशों की तुलना उनकी ध्वन्यात्मक ध्वनियों के आधार पर करते हैं। साउंडएक्स शब्द या वाक्यांश को पढ़कर और अलग-अलग पात्रों को देखकर ऐसा करता है, जबकि मेटाफोन अलग-अलग पात्रों और चरित्र समूहों दोनों को देखता है। फिर दोनों शब्द की वर्तनी और उच्चारण के आधार पर कोड देते हैं।
निम्नलिखित सॉर्टसीएल स्क्रिप्ट साउंडेक्स और मेटासफोन खोज कार्यों को प्रदर्शित करती है:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
प्रत्येक मामले में, तीन भाग होते हैं जिनका उपयोग हमें वांछित आउटपुट देने के लिए किया जाना चाहिए।
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
लाइन फ़ंक्शन को कॉल करती है, और परिणाम को परिणाम फ़ील्ड में संग्रहीत करती है। दोनों फ़ंक्शन दो इनपुट पैरामीटर लेते हैं:
- फ़ज़ी खोज चलाने के लिए फ़ील्ड (हमारे उदाहरण में NAME)
- वह xstring जिससे इनपुट फ़ील्ड की तुलना की जाएगी (हमारे उदाहरण में "जॉन")
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
यह पंक्ति SE_RESULT और MP_RESULT फ़ील्ड की तुलना करती है, और पंक्ति की जांच करती है और यदि दोनों में से कोई एक 0 से अधिक है तो लौटाती है।
साउंडेक्स मैच के लिए या तो 100 देता है, या यदि यह मैच नहीं है तो 0 देता है। मेटाफोन के अधिक विशिष्ट परिणाम हैं, और एक मजबूत मैच के लिए 100, एक सामान्य मैच के लिए 66 और एक मामूली मैच के लिए 33 रिटर्न देता है।
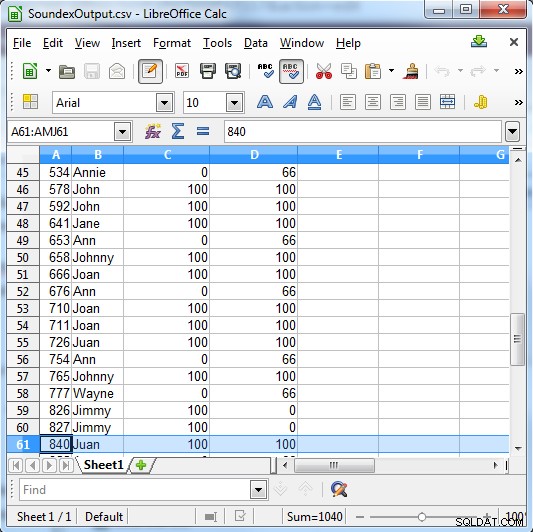
कॉलम C साउंडेक्स परिणाम दिखाता है। Cस्तंभ D मेटाफ़ोन परिणाम दिखाता है
जैसा कि आउटपुट दिखाता है कि इस प्रकार की खोज खोजने के लिए उपयोगी है:
- फोनेटिक त्रुटियां
कृपया नीचे इस लेख पर फ़ीडबैक सबमिट करें, और यदि आप इन कार्यों का उपयोग करने में रुचि रखते हैं तो कृपया अपने आईआरआई प्रतिनिधि से संपर्क करें। IRI कार्यक्षेत्र डेटा समेकन (गुणवत्ता) विज़ार्ड में इन एल्गोरिदम का उपयोग करने पर हमारा अगला लेख देखें।