SQL सर्वर का TRIM फ़ंक्शन एक वर्ण स्ट्रिंग से अग्रणी और अनुगामी व्हॉट्सएप को हटाने के लिए डिज़ाइन किया गया है। एक प्रमुख स्थान रिक्त स्थान है जो वास्तविक स्ट्रिंग से पहले होता है। एक अनुगामी स्थान के बाद होता है।
इस लेख में, हम TRIM फ़ंक्शन की जांच करने जा रहे हैं और व्यावहारिक उदाहरणों द्वारा इसके उपयोग का वर्णन करेंगे। तो, आइए बुनियादी बातों से शुरू करते हैं।
SQL सर्वर में TRIM फ़ंक्शन
SQL TRIM एक अंतर्निहित फ़ंक्शन है जो हमें एक क्रिया के साथ स्ट्रिंग के दोनों किनारों पर अनावश्यक वर्णों को ट्रिम करने की अनुमति देता है। अक्सर, हम इसका इस्तेमाल व्हाइटस्पेस को हटाने के लिए करते हैं। यह फ़ंक्शन SQL Server 2017 में दिखाई दिया, और अब यह Azure SQL डेटाबेस में भी मौजूद है।
SQL TRIM फ़ंक्शन का सिंटैक्स इस प्रकार है:
ट्रिम ([अक्षर से] स्ट्रिंग)
- पात्रों से एक वैकल्पिक है पैरामीटर जो परिभाषित करता है कि हमें किन वर्णों को हटाना चाहिए। डिफ़ॉल्ट रूप से, यह पैरामीटर हमारे स्ट्रिंग के दोनों ओर रिक्त स्थान पर लागू होता है।
- स्ट्रिंग एक अनिवार्य . है पैरामीटर जो उस स्ट्रिंग को निर्धारित करता है जहां हमें रिक्त स्थान/अन्य अनावश्यक वर्णों से छुटकारा पाने की आवश्यकता होती है।
लौटाया गया आउटपुट उन वर्णों के बिना एक स्ट्रिंग है जिसे हमने शुरुआत और अंत में ट्रिम करने के लिए निर्धारित किया है। उदाहरण देखें:
SELECT TRIM( ' example ') AS Result;आउटपुट है:
उदाहरण
जैसा कि हमने बताया कि TRIM फंक्शन दूसरे कैरेक्टर्स को भी हटा सकता है। उस उदाहरण पर एक नज़र डालें जहां हम अनावश्यक वर्णों और रिक्त स्थान से स्ट्रिंग को साफ़ करना चाहते हैं:
SELECT TRIM( '.,# ' FROM '# ! example .') AS Result;आउटपुट है:
<मजबूत>! उदाहरण
SQL TRIM फ़ंक्शन 2017 के संस्करण से शुरू होने वाले SQL सर्वर में उपलब्ध है, लेकिन उस रिलीज़ से पहले भी कार्य करना संभव था। उपयोगकर्ता एसक्यूएल एलटीआरआईएम लागू कर सकते हैं और एसक्यूएल आरटीआरआईएम कार्य। वे SQL सर्वर के सभी समर्थित संस्करणों में मौजूद हैं।
SQL सर्वर में LTRIM फ़ंक्शन
एसक्यूएल एलटीआरआईएम फ़ंक्शन स्ट्रिंग के बाईं ओर अनावश्यक रिक्त स्थान को हटाने का कार्य करता है। वाक्य रचना इस प्रकार है:
एलटीआरआईएम (स्ट्रिंग)
स्ट्रिंग अनिवार्य पैरामीटर है जो वर्णों के लक्ष्य स्ट्रिंग को निर्दिष्ट करता है जिसे हमें बाईं ओर ट्रिम करने की आवश्यकता होती है। आउटपुट निर्दिष्ट स्ट्रिंग की एक प्रति है, लेकिन शुरुआत में रिक्त स्थान के बिना:
SELECT LTRIM(' SQL Function');आउटपुट:
'एसक्यूएल फंक्शन'
SQL सर्वर में RTRIM फ़ंक्शन
एसक्यूएल आरटीआरआईएम फ़ंक्शन उसी तरह काम करता है जैसे LTRIM - अंतर यह है कि यह स्ट्रिंग के दाईं ओर रिक्त स्थान को हटा देता है। सिंटैक्स नीचे है:
RTRIM(स्ट्रिंग)
स्ट्रिंग आवश्यक पैरामीटर है जो वर्णों की स्ट्रिंग को इंगित करता है जहां हमें पिछली जगहों को हटाने की आवश्यकता होती है।
SELECT RTRIM('SQL Server ');आउटपुट:
‘एसक्यूएल सर्वर’
एलटीआरआईएम और आरटीआरआईएम का एक साथ उपयोग करना
SQL सर्वर के साथ काम करते हुए, हमें अक्सर केवल स्ट्रिंग के एक तरफ से रिक्त स्थान निकालने की आवश्यकता होती है। फिर भी, ऐसे मामले हैं जब हमें दोनों तरफ स्ट्रिंग को साफ़ करने की आवश्यकता होती है। पहले वर्णित TRIM फ़ंक्शन उस लक्ष्य को पूरा करता है, लेकिन, जैसा कि हमें याद है, यह केवल SQL Server 2017 और उच्चतर में उपलब्ध है।
क्या टीआरआईएम फ़ंक्शन के बिना एक स्ट्रिंग के लिए अग्रणी और पिछली दोनों जगहों को हटाने का कोई तरीका है? हां। हम LTRIM और RTRIM को एक साथ एक प्रश्न में उपयोग कर सकते हैं।
वाक्य रचना है:
एलटीआरआईएम(आरटीआरआईएम(स्ट्रिंग))
स्ट्रिंग वर्णों के उस लक्ष्य स्ट्रिंग को परिभाषित करता है जिसे हम दोनों तरफ अनावश्यक रिक्त स्थान से साफ़ करना चाहते हैं। यह भी ध्यान दें कि हम एलटीआरआईएम और आरटीआरआईएम को किसी भी क्रम में रख सकते हैं ।
SELECT LTRIM(RTRIM(' SQL Server '));आउटपुट:
‘एसक्यूएल सर्वर’
अब जबकि हमने इन सभी SQL फ़ंक्शन (TRIM, LTRIM, और RTRIM) के सार को स्पष्ट कर दिया है, आइए हम और गहराई में जाएं।
व्हाइटस्पेस क्यों मायने रखता है
कोई पूछ सकता है कि ऐसे स्थानों को हटाना क्यों महत्वपूर्ण हो सकता है। सरल शब्दों में, ऐसा इसलिए है क्योंकि, उदाहरण के लिए, मूल्यों की तुलना करते समय वे एक उपद्रव का गठन कर सकते हैं। व्हॉट्सएप को एक स्ट्रिंग का एक हिस्सा माना जाता है यदि यह वहां है, तो इस तरह के मुद्दों पर ध्यान देना बेहतर है।
आइए इन कार्यों की ठीक से जांच करें।
सबसे पहले, हम अपने उद्यम में चलने वाले डेटाबेस प्रकारों के लिए एक साधारण तालिका बनाते हैं। हमारी तालिका में तीन कॉलम हैं। प्रत्येक पंक्ति को विशिष्ट रूप से पहचानने के लिए आवश्यक पहला आईडी कॉलम है। दूसरा है DBTypeNameA . तीसरा है DBTypeNameB ।
अंतिम दो कॉलम डेटा प्रकार से भिन्न होते हैं। DBTypeNameA पहले VARCHAR . का उपयोग करता है डेटा प्रकार, और DBTypeNameB CHAR . का उपयोग करता है डेटा प्रकार।
दोनों स्तंभों के लिए, हम 50 की डेटा लंबाई आवंटित करते हैं।
- Listing 1: Create a Simple Table
USE DB2
GO
CREATE TABLE DBType (
ID INT IDENTITY(1,1)
,DBTypeNameA VARCHAR (50)
,DBTypeNameB CHAR (50))
GO
इन डेटा प्रकारों के बीच अंतर पर ध्यान दें।
- VARCHAR कॉलम के लिए, SQL सर्वर उन 50 वर्णों के लिए स्थान आवंटित नहीं करता है जिनकी हम कॉलम ab initio में अपेक्षा करते हैं। हम कहते हैं कि कॉलम को एक अधिकतम के लिए प्रावधान करना चाहिए 50 वर्णों में से, लेकिन आवश्यकतानुसार स्थान आवंटित करें।
- CHAR कॉलम के लिए, हर बार एक पंक्ति डालने पर 50 वर्णों के लिए प्रावधान किया जाता है, भले ही वास्तविक मान को उस स्थान की आवश्यकता हो या नहीं।
इस प्रकार, VARCHAR (वैरिएबल कैरेक्टर) का उपयोग करना स्थान बचाने का एक तरीका है।
तालिका बनाने के बाद, हम लिस्टिंग 2 में कोड का उपयोग करके इसे पॉप्युलेट करते हैं।
-- Listing 2: Populate the Table
USE DB2
GO
INSERT INTO DBType VALUES ('SQL Server','SQL Server');
INSERT INTO DBType VALUES (' SQL Server ',' SQL Server ');
INSERT INTO DBType VALUES (' SQL Server ',' SQL Server ');
INSERT INTO DBType VALUES ('Oracle','Oracle');
INSERT INTO DBType VALUES (' Oracle ',' Oracle ');
INSERT INTO DBType VALUES (' Oracle ',' Oracle ');
INSERT INTO DBType VALUES ('MySQL','MySQL');
INSERT INTO DBType VALUES (' MySQL ',' MySQL ');
INSERT INTO DBType VALUES (' MySQL ',' MySQL ');
अपनी तालिका को पॉप्युलेट करते समय, हमने जानबूझकर अग्रणी और अनुगामी रिक्त स्थान वाले मान दर्ज किए हैं। हम अपने प्रदर्शन में उनका उपयोग करेंगे।
जब हम तालिका को क्वेरी करते हैं (सूची 3 देखें), तो हम डेटा में "विरूपण" देख सकते हैं जैसा कि SSMS (चित्र 1) में दिया गया है।
-- Listing 3: Query the Table
USE DB2
GO
SELECT * FROM DBType;
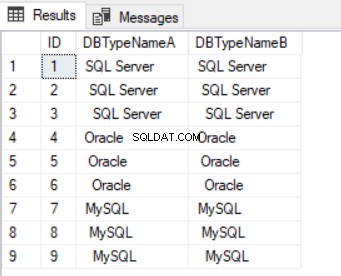
यह विकृति दिखाई दे रही है क्योंकि हमारे पास प्रमुख स्थान हैं। पिछली जगहों को इस तरह से कल्पना करना अधिक कठिन होता है।
क्वेरी लिस्टिंग 4 इस "विरूपण" पर एक गहरी नज़र प्रदान करती है। यह LEN और DATALENGTH फ़ंक्शंस का परिचय देता है:
- LEN() पिछली जगहों को छोड़कर एक स्ट्रिंग में वर्णों की संख्या देता है।
- DATALENGTH() किसी व्यंजक को दर्शाने के लिए प्रयुक्त बाइट्स की संख्या देता है।
-- Listing 4: Query the Table
USE DB2
GO
SELECT DBTypeNameA
, LEN(DBTypeNameA) LenVarcharCol
, DATALENGTH(DBTypeNameA) DataLenVarcharCol
, DBTypeNameB
, LEN(DBTypeNameB) LenCharCol
, DATALENGTH(DBTypeNameB) DataLenCharCol
FROM DBType;
चित्र 2 हमें "एसक्यूएल सर्वर," "ओरेकल," और "माईएसक्यूएल" जैसे अभिव्यक्तियों के लिए अग्रणी और अनुगामी रिक्त स्थान के कारण लंबाई में भिन्नता दिखाता है।
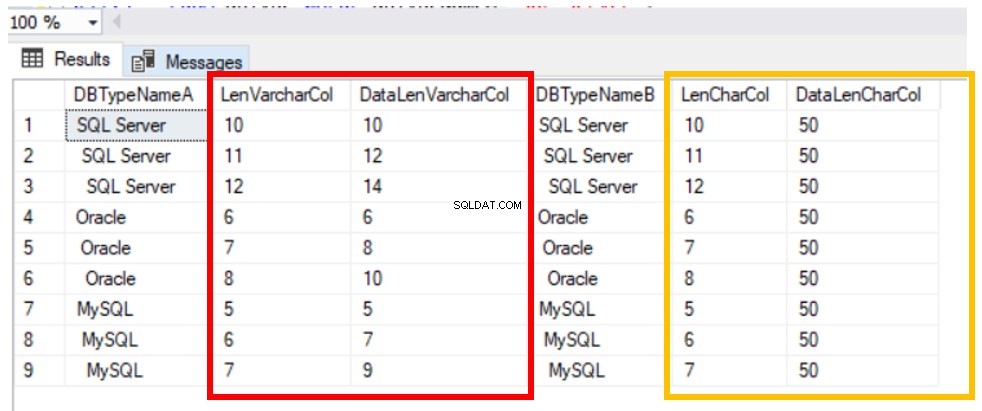
इसका तात्पर्य यह है कि ये अभिव्यक्तियाँ SQL सर्वर क्वेरी इंजन के समान नहीं हैं। हम लिस्टिंग 5 में कोड चलाकर इसे स्पष्ट रूप से देख सकते हैं।
-- Listing 5: Query for Specific
USE DB2
GO
SELECT * FROM DBType WHERE DBTypeNameA='SQL Server';
SELECT * FROM DBType WHERE DBTypeNameA='Oracle';
SELECT * FROM DBType WHERE DBTypeNameA='MySQL';
DataLenCharCol फ़ील्ड CHAR कॉलम पर DATALENGTH () फ़ंक्शन के आउटपुट का प्रतिनिधित्व करता है। इसलिए, "एसक्यूएल सर्वर" और "एसक्यूएल सर्वर" के बीच इस असमानता का एक परिणाम चित्र 3 में प्रदर्शित क्वेरी परिणाम है।
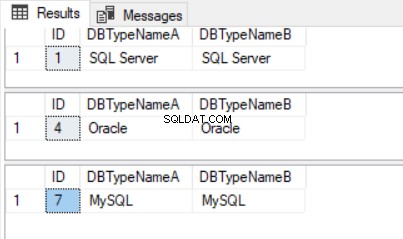
हम देखते हैं कि भले ही हमारे पास प्रत्येक डेटाबेस प्रकार के साथ तीन पंक्तियाँ हों, हमारे प्रश्न प्रत्येक में से केवल एक को लौटाते हैं क्योंकि अग्रणी और अनुगामी रिक्त स्थान मानों को अलग करते हैं।
समस्या का समाधान
लिस्टिंग 5 में क्वेरी के लिए सही परिणाम प्राप्त करना संभव और आसान है। हमें SQL सर्वर TRIM() फ़ंक्शन की आवश्यकता है जैसा कि लिस्टिंग 6 में दिखाया गया है।
-- Listing 6: Query for Specific
USE DB2
GO
SELECT * FROM DBType WHERE TRIM(DBTypeNameA)='SQL Server';
SELECT * FROM DBType WHERE TRIM(DBTypeNameA)='Oracle';
SELECT * FROM DBType WHERE TRIM(DBTypeNameA)='MySQL';
इस TRIM() फ़ंक्शन के बिना, हम कुछ परिदृश्यों में गलत परिणाम प्राप्त कर सकते हैं।
हम डेटा को एक अलग तालिका में लोड करके इसे और आगे ले जा सकते हैं, यह मानते हुए कि हम समस्या को स्थायी रूप से हल करना चाहते हैं (एक प्रकार का डेटा क्लीनअप)।
-- Listing 7: Query for Specific
USE DB2
GO
SELECT ID, TRIM(DBTypeNameA) DBTypeNameA, TRIM(DBTypeNameB) DBTypeNameB FROM DBType;
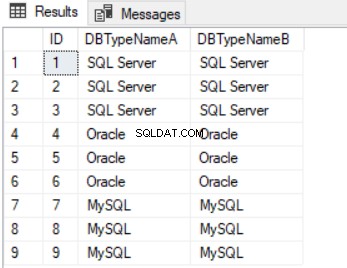
लिस्टिंग 7 (चित्र 5) के परिणामों की तुलना लिस्टिंग 3 (चित्र 1) से करें। हम डेटा को साफ करने के लिए इस परिणाम सेट के साथ एक और टेबल भी बना सकते हैं (लिस्टिंग 8 देखें)।
-- Listing 8: Create a New Table (Data Cleanup)
USE DB2
GO
SELECT ID, TRIM(DBTypeNameA) DBTypeNameA, TRIM(DBTypeNameB) DBTypeNameB INTO DBType_New FROM DBType;
SELECT * FROM DBType_New;
इस तरह, हम अपनी समस्याओं को स्थायी रूप से हल कर सकते हैं और हर बार जब हमें अपनी तालिका से डेटा निकालने की आवश्यकता होती है तो निष्पादन कार्यों के ऊपरी हिस्से को हटा सकते हैं।
निष्कर्ष
SQL सर्वर TRIM () फ़ंक्शन का उपयोग स्ट्रिंग्स से अग्रणी और अनुगामी दोनों रिक्त स्थान को निकालने के लिए किया जा सकता है। एलटीआरआईएम और आरटीआरआईएम इस फ़ंक्शन के दो प्रकार हैं जो क्रमशः अग्रणी (बाएं) और अनुगामी (दाएं) रिक्त स्थान पर ध्यान केंद्रित करते हैं।
हम परिणाम सेट को व्यवस्थित करने और सही परिणाम सेट प्राप्त करना सुनिश्चित करने के लिए तुरंत TRIM () लागू कर सकते हैं। साथ ही, हम डेटा को एक टेबल से दूसरी टेबल पर बड़े करीने से ले जाने के दौरान स्पेस को हटाने के लिए इसका इस्तेमाल कर सकते हैं।
संबंधित लेख
SQL सबस्ट्रिंग () फ़ंक्शन का उपयोग करके प्रो की तरह स्ट्रिंग्स को कैसे पार्स करें?