NULL हैंडलिंग SQL के साथ डेटा मॉडलिंग और डेटा हेरफेर के पेचीदा पहलुओं में से एक है। आइए इस तथ्य से शुरू करें कि बिल्कुल एक NULL क्या है को समझाने का प्रयास है अपने आप में तुच्छ नहीं है। यहां तक कि उन लोगों के बीच भी जिनके पास रिलेशनल थ्योरी और एसक्यूएल की अच्छी समझ है, आप अपने डेटाबेस में एनयूएलएल का उपयोग करने के पक्ष और विपक्ष दोनों में बहुत मजबूत राय सुनेंगे। उनकी तरह या नहीं, एक डेटाबेस प्रैक्टिशनर के रूप में आपको अक्सर उनसे निपटना पड़ता है, और यह देखते हुए कि एनयूएलएल आपके एसक्यूएल कोड लेखन में जटिलता जोड़ते हैं, उन्हें अच्छी तरह से समझने के लिए इसे प्राथमिकता देना एक अच्छा विचार है। इस तरह आप अनावश्यक बग और नुकसान से बच सकते हैं।
यह आलेख NULL जटिलताओं के बारे में श्रृंखला में पहला है। मैं कवरेज के साथ शुरू करता हूं कि एनयूएलएल क्या हैं और तुलना में वे कैसे व्यवहार करते हैं। मैं फिर विभिन्न भाषा तत्वों में NULL उपचार विसंगतियों को कवर करता हूं। अंत में, मैं टी-एसक्यूएल में न्यूल हैंडलिंग से संबंधित लापता मानक सुविधाओं को कवर करता हूं और टी-एसक्यूएल में उपलब्ध विकल्पों का सुझाव देता हूं।
अधिकांश कवरेज किसी भी प्लेटफ़ॉर्म के लिए प्रासंगिक है जो SQL की एक बोली को लागू करता है, लेकिन कुछ मामलों में मैं उन पहलुओं का उल्लेख करता हूं जो T-SQL के लिए विशिष्ट हैं।
अपने उदाहरणों में मैं TSQLV5 नामक एक नमूना डेटाबेस का उपयोग करूँगा। आप इस डेटाबेस को बनाने और भरने वाली स्क्रिप्ट यहां और इसके ईआर आरेख यहां पा सकते हैं।
अनुपलब्ध मान के लिए मार्कर के रूप में NULL
आइए समझने के साथ शुरू करें कि एनयूएलएल क्या हैं। SQL में, एक अनुपलब्ध मान के लिए NULL एक मार्कर, या प्लेसहोल्डर है। यह आपके डेटाबेस में एक वास्तविकता का प्रतिनिधित्व करने के लिए SQL का प्रयास है जहाँ एक निश्चित विशेषता मान कभी-कभी मौजूद होता है और कभी-कभी गायब होता है। उदाहरण के लिए, मान लें कि आपको कर्मचारी डेटा को कर्मचारी तालिका में संग्रहीत करने की आवश्यकता है। आपके पास प्रथम नाम, मध्य नाम और अंतिम नाम के लिए विशेषताएँ हैं। प्रथम नाम और अंतिम नाम विशेषताएँ अनिवार्य हैं, और इसलिए आप उन्हें NULLs की अनुमति नहीं देने के रूप में परिभाषित करते हैं। मध्यनाम विशेषता वैकल्पिक है, और इसलिए आप इसे NULLs की अनुमति के रूप में परिभाषित करते हैं।
यदि आप सोच रहे हैं कि लापता मूल्यों के बारे में संबंधपरक मॉडल का क्या कहना है, तो मॉडल के निर्माता एडगर एफ। कॉड ने उन पर विश्वास किया। वास्तव में, उन्होंने दो प्रकार के लापता मूल्यों के बीच भी अंतर किया:गुम लेकिन लागू (ए-वैल्यू मार्कर), और लापता लेकिन अनुपयोगी (आई-वैल्यू मार्कर)। यदि हम एक उदाहरण के रूप में मध्य नाम विशेषता लेते हैं, ऐसे मामले में जहां किसी कर्मचारी का मध्य नाम होता है, लेकिन गोपनीयता कारणों से जानकारी साझा नहीं करना चुनता है, तो आप ए-वैल्यू मार्कर का उपयोग करेंगे। ऐसे मामले में जहां किसी कर्मचारी का मध्य नाम बिल्कुल नहीं है, आप आई-वैल्यू मार्कर का उपयोग करेंगे। यहां, वही विशेषता कभी-कभी प्रासंगिक और वर्तमान हो सकती है, कभी-कभी गुम लेकिन लागू होती है और कभी-कभी गुम लेकिन लागू नहीं होती है। अन्य मामलों को केवल एक प्रकार के लापता मूल्यों का समर्थन करते हुए स्पष्ट कटौती की जा सकती है। उदाहरण के लिए, मान लें कि आपके पास एक ऑर्डर तालिका है जिसमें एक विशेषता है जिसे शिपडेट कहा जाता है जिसमें ऑर्डर की शिपिंग तिथि होती है। शिप किए गए ऑर्डर में हमेशा एक वर्तमान और प्रासंगिक शिप की गई तारीख होगी। एक ज्ञात शिपिंग तिथि न होने का एकमात्र मामला उन आदेशों के लिए होगा जो अभी तक शिप नहीं किए गए थे। तो यहाँ, या तो एक प्रासंगिक शिप किया गया दिनांक मान मौजूद होना चाहिए, या I-मान मार्कर का उपयोग किया जाना चाहिए।
एसक्यूएल के डिजाइनरों ने लागू बनाम अनुपयोगी लापता मूल्यों के भेद में नहीं आना चुना, और हमें किसी भी प्रकार के लापता मूल्य के लिए मार्कर के रूप में एनयूएलएल प्रदान किया। अधिकांश भाग के लिए, SQL को यह मानने के लिए डिज़ाइन किया गया था कि NULLs गुम लेकिन लागू प्रकार के लापता मान का प्रतिनिधित्व करते हैं। नतीजतन, विशेष रूप से जब NULL का आपका उपयोग एक अनुपयुक्त मान के लिए प्लेसहोल्डर के रूप में होता है, तो डिफ़ॉल्ट SQL NULL हैंडलिंग वह नहीं हो सकती है जिसे आप सही मानते हैं। कभी-कभी आपको उस उपचार को प्राप्त करने के लिए स्पष्ट NULL हैंडलिंग लॉजिक जोड़ने की आवश्यकता होगी जिसे आप अपने लिए सही मानते हैं।
सर्वोत्तम अभ्यास के रूप में, यदि आप जानते हैं कि किसी विशेषता को NULLs की अनुमति नहीं देनी चाहिए, तो सुनिश्चित करें कि आप इसे स्तंभ परिभाषा के भाग के रूप में NOT NULL बाधा के साथ लागू करते हैं। इसके कुछ महत्वपूर्ण कारण हैं। एक कारण यह है कि यदि आप इसे लागू नहीं करते हैं, तो एक बिंदु या किसी अन्य पर, एनयूएलएल वहां पहुंच जाएंगे। यह एप्लिकेशन में बग या खराब डेटा आयात करने का परिणाम हो सकता है। एक बाधा का उपयोग करके, आप जानते हैं कि एनयूएलएल इसे टेबल पर कभी नहीं बनायेगा। एक अन्य कारण यह है कि ऑप्टिमाइज़र बेहतर अनुकूलन के लिए NOT NULL जैसी बाधाओं का मूल्यांकन करता है, NULLs की तलाश में अनावश्यक काम से बचता है, और कुछ परिवर्तन नियमों को सक्षम करता है।
NULL से संबंधित तुलना
एनयूएलएल शामिल होने पर भविष्यवाणी के एसक्यूएल के मूल्यांकन में कुछ मुश्किल है। मैं पहले स्थिरांक वाली तुलनाओं को कवर करूंगा। बाद में मैं वेरिएबल, पैरामीटर और कॉलम वाली तुलनाओं को कवर करूंगा।
जब आप WHERE, ON और HAVING जैसे क्वेरी तत्वों में ऑपरेंड की तुलना करने वाले विधेय का उपयोग करते हैं, तो तुलना के संभावित परिणाम इस बात पर निर्भर करते हैं कि क्या कोई ऑपरेंड NULL हो सकता है। यदि आप निश्चित रूप से जानते हैं कि कोई भी ऑपरेंड NULL नहीं हो सकता है, तो विधेय का परिणाम हमेशा TRUE या FALSE होगा। इसे दो-मूल्यवान विधेय तर्क के रूप में जाना जाता है, या संक्षेप में, केवल दो-मूल्यवान तर्क। यह मामला है, उदाहरण के लिए, जब आप किसी ऐसे कॉलम की तुलना कर रहे हैं जिसे किसी अन्य गैर-नल ऑपरेंड के साथ NULLs को अनुमति नहीं देने के रूप में परिभाषित किया गया है।
यदि तुलना में कोई भी ऑपरेंड एक NULL हो सकता है, मान लें, एक कॉलम जो NULLs को समानता (=) और असमानता (<>,>, <,>=, <=, आदि) ऑपरेटरों का उपयोग करके अनुमति देता है, तो आप हैं अब तीन-मूल्यवान विधेय तर्क की दया पर। यदि किसी दी गई तुलना में दो ऑपरेंड गैर-शून्य मान होते हैं, तो भी आपको परिणाम के रूप में TRUE या FALSE मिलता है। हालाँकि, यदि कोई ऑपरेंड NULL है, तो आपको UNKNOWN नामक तीसरा तार्किक मान मिलता है। ध्यान दें कि दो NULLs की तुलना करते समय भी यही स्थिति है। SQL के अधिकांश तत्वों द्वारा TRUE और FALSE का उपचार बहुत सहज है। UNKNOWN का उपचार हमेशा इतना सहज नहीं होता है। इसके अलावा, SQL के विभिन्न तत्व UNKNOWN मामले को अलग तरह से संभालते हैं, जैसा कि मैं बाद में "NULL उपचार विसंगतियों" के तहत लेख में विस्तार से बताऊंगा।
एक उदाहरण के रूप में, मान लीजिए कि आपको TSQLV5 नमूना डेटाबेस में Sales.Orders तालिका को क्वेरी करने की आवश्यकता है, और 2 जनवरी, 2019 को शिप किए गए ऑर्डर लौटाने हैं। आप निम्न क्वेरी का उपयोग करते हैं:
USE TSQLV5; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = '20190102';
यह स्पष्ट है कि फ़िल्टर विधेय उन पंक्तियों के लिए TRUE का मूल्यांकन करता है जहां शिप करने की तिथि 2 जनवरी, 2019 है, और उन पंक्तियों को वापस किया जाना चाहिए। यह भी स्पष्ट है कि विधेय उन पंक्तियों के लिए FALSE का मूल्यांकन करता है जहां शिप की गई तारीख मौजूद है, लेकिन 2 जनवरी, 2019 नहीं है, और उन पंक्तियों को छोड़ दिया जाना चाहिए। लेकिन NULL शिप की गई तारीख वाली पंक्तियों के बारे में क्या? याद रखें कि समानता-आधारित विधेय और असमानता-आधारित दोनों विधेय UNKNOWN लौटाते हैं यदि कोई भी ऑपरेंड NULL है। WHERE फ़िल्टर ऐसी पंक्तियों को हटाने के लिए डिज़ाइन किया गया है। आपको यह याद रखने की आवश्यकता है कि WHERE फ़िल्टर उन पंक्तियों को लौटाता है जिनके लिए फ़िल्टर TRUE का मूल्यांकन करता है, और उन पंक्तियों को छोड़ देता है जिनके लिए विधेय FALSE या UNKNOWN का मूल्यांकन करता है।
यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
मान लीजिए कि आपको 2 जनवरी, 2019 को शिप नहीं किए गए ऑर्डर वापस करने की आवश्यकता है। जहां तक आपका संबंध है, जो ऑर्डर अभी तक शिप नहीं किए गए थे, उन्हें आउटपुट में शामिल किया जाना चाहिए। आप पिछली जैसी क्वेरी का उपयोग करते हैं, केवल विधेय को नकारते हुए, जैसे:
SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = '20190102');
यह क्वेरी निम्न आउटपुट लौटाती है:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
आउटपुट स्वाभाविक रूप से 2 जनवरी, 2019 को शिप की गई तारीख वाली पंक्तियों को बाहर कर देता है, लेकिन साथ ही NULL शिप की गई तारीख वाली पंक्तियों को भी शामिल नहीं करता है। यहां जो बात सहज ज्ञान युक्त हो सकती है, वह यह है कि जब आप NOT ऑपरेटर का उपयोग किसी ऐसे विधेय को नकारने के लिए करते हैं जो UNKNOWN का मूल्यांकन करता है। जाहिर है, सच नहीं गलत है और झूठ नहीं सच है। हालाँकि, NOT UNKNOWN UNKNOWN रहता है। इस डिज़ाइन के पीछे SQL का तर्क यह है कि यदि आप नहीं जानते कि कोई प्रस्ताव सत्य है या नहीं, तो आप यह भी नहीं जानते कि प्रस्ताव सत्य नहीं है। इसका मतलब यह है कि फ़िल्टर विधेय में समानता और असमानता ऑपरेटरों का उपयोग करते समय, विधेय के न तो सकारात्मक और न ही नकारात्मक रूप NULLs के साथ पंक्तियों को लौटाते हैं।
यह उदाहरण काफी सरल है। उपश्रेणियों से जुड़े पेचीदा मामले हैं। जब आप सबक्वेरी के साथ NOT IN विधेय का उपयोग करते हैं, तो एक सामान्य बग होता है, जब सबक्वेरी लौटाए गए मानों के बीच NULL देता है। क्वेरी हमेशा एक खाली परिणाम देती है। इसका कारण यह है कि विधेय का सकारात्मक रूप (IN भाग) एक TRUE देता है जब बाहरी मान पाया जाता है, और UNKNOWN जब यह NULL के साथ तुलना के कारण नहीं मिलता है। फिर NOT ऑपरेटर के साथ विधेय का निषेध हमेशा क्रमशः FALSE या UNKNOWN लौटाता है - कभी भी TRUE नहीं। मैं इस बग को टी-एसक्यूएल बग, नुकसान, और सर्वोत्तम प्रथाओं में विस्तार से कवर करता हूं - सुझाए गए समाधान, अनुकूलन विचार और सर्वोत्तम प्रथाओं सहित सबक्वायरी। यदि आप पहले से ही इस क्लासिक बग से परिचित नहीं हैं, तो सुनिश्चित करें कि आपने इस लेख की जांच की है क्योंकि बग काफी सामान्य है, और इससे बचने के लिए आप कुछ सरल उपाय कर सकते हैं।
हमारी जरूरत पर वापस, एक शिप की गई तारीख के साथ ऑर्डर वापस करने का प्रयास करने के बारे में क्या है जो 2 जनवरी, 2019 से भिन्न है, (<>) ऑपरेटर से भिन्न का उपयोग करके:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102';
दुर्भाग्य से, समानता और असमानता दोनों ऑपरेटर UNKNOWN उत्पन्न करते हैं जब कोई भी ऑपरेंड NULL होता है, इसलिए यह क्वेरी NULLs को छोड़कर, पिछली क्वेरी की तरह निम्न आउटपुट उत्पन्न करती है:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
दो प्रकार के ऑपरेटरों की समानता, असमानता और नकार का उपयोग करके UNKNOWN उत्पन्न करने वाले NULLs के साथ तुलना के मुद्दे को अलग करने के लिए, निम्नलिखित सभी प्रश्न एक खाली परिणाम सेट लौटाते हैं:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = NULL); SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate <> NULL);
SQL के अनुसार, आपको यह जांचने की आवश्यकता नहीं है कि क्या कुछ NULL के बराबर है या NULL से अलग है, बल्कि यदि कुछ NULL है या NULL नहीं है, तो विशेष ऑपरेटरों IS NULL और IS NOT NULL का उपयोग करके क्रमशः। ये ऑपरेटर दो-मूल्यवान तर्क का उपयोग करते हैं, हमेशा TRUE या FALSE लौटाते हैं। उदाहरण के लिए, बिना शिपिंग वाले ऑर्डर वापस करने के लिए IS NULL ऑपरेटर का उपयोग करें, जैसे:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NULL;
यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
शिप किए गए ऑर्डर वापस करने के लिए IS NOT NULL ऑपरेटर का उपयोग करें, जैसे:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT NULL;
यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
2 जनवरी, 2019 से अलग तारीख पर शिप किए गए ऑर्डर और साथ ही अनशिप किए गए ऑर्डर वापस करने के लिए निम्न कोड का उपयोग करें:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102' OR shippeddate IS NULL;
यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
श्रृंखला के एक बाद के भाग में मैं NULL उपचार के लिए मानक सुविधाओं को शामिल करता हूँ जो वर्तमान में T-SQL में अनुपलब्ध हैं, जिसमें DISTINCT विधेय शामिल हैं। , जो कि NULL को बहुत हद तक सरल बनाने की क्षमता रखता है।
चर, पैरामीटर और कॉलम के साथ तुलना
पिछला खंड विधेय पर केंद्रित था जो एक स्थिरांक के साथ एक स्तंभ की तुलना करता है। हकीकत में, हालांकि, आप ज्यादातर कॉलम की तुलना चर/पैरामीटर या अन्य कॉलम के साथ करेंगे। इस तरह की तुलनाओं में और जटिलताएं शामिल हैं।
NULL-हैंडलिंग दृष्टिकोण से, चर और मापदंडों को समान माना जाता है। मैं अपने उदाहरणों में चर का उपयोग करूंगा, लेकिन उनके संचालन के बारे में मैं जो बिंदु बनाता हूं, वे मापदंडों के लिए उतने ही प्रासंगिक हैं।
निम्नलिखित मूल क्वेरी पर विचार करें (मैं इसे क्वेरी 1 कहूंगा), जो किसी दिए गए दिनांक को शिप किए गए ऑर्डर को फ़िल्टर करता है:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
मैं इस उदाहरण में एक चर का उपयोग करता हूं और इसे कुछ नमूना तिथि के साथ प्रारंभ करता हूं, लेकिन यह संग्रहीत प्रक्रिया या उपयोगकर्ता द्वारा परिभाषित फ़ंक्शन में पैरामीटरयुक्त क्वेरी भी हो सकता था।
यह क्वेरी निष्पादन निम्न आउटपुट उत्पन्न करता है:
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
प्रश्न 1 की योजना चित्र 1 में दिखाई गई है।
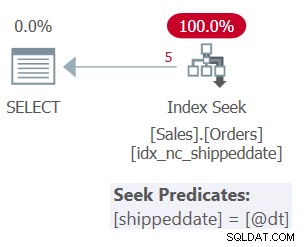 चित्र 1:प्रश्न 1 के लिए योजना
चित्र 1:प्रश्न 1 के लिए योजना
इस क्वेरी का समर्थन करने के लिए तालिका में एक कवरिंग इंडेक्स है। इंडेक्स को idx_nc_shippeddate कहा जाता है, और इसे की-लिस्ट (शिपडेट, ऑर्डरिड) के साथ परिभाषित किया जाता है। क्वेरी का फ़िल्टर विधेय खोज तर्क (SARG) . के रूप में व्यक्त किया जाता है , जिसका अर्थ है कि यह ऑप्टिमाइज़र को सहायक इंडेक्स में सीक ऑपरेशन लागू करने पर विचार करने में सक्षम बनाता है, सीधे क्वालिफाइंग पंक्तियों की सीमा तक जाता है। फ़िल्टर जो SARGable को प्रेडिकेट करता है, वह यह है कि यह एक ऐसे ऑपरेटर का उपयोग करता है जो इंडेक्स में क्वालिफाइंग पंक्तियों की एक क्रमिक श्रेणी का प्रतिनिधित्व करता है, और यह फ़िल्टर किए गए कॉलम में हेरफेर लागू नहीं करता है। आपको जो प्लान मिलता है वह इस क्वेरी के लिए सबसे अच्छा प्लान है।
लेकिन क्या होगा यदि आप उपयोगकर्ताओं को अनशिप्ड ऑर्डर के लिए पूछने की अनुमति देना चाहते हैं? ऐसे आदेशों में एक पूर्ण शिप की गई तिथि होती है। यहाँ एक NULL को इनपुट तिथि के रूप में पास करने का प्रयास है:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
जैसा कि आप पहले से ही जानते हैं, एक समानता ऑपरेटर का उपयोग करते हुए एक विधेय UNKNOWN उत्पन्न करता है जब कोई भी ऑपरेंड एक NULL होता है। नतीजतन, यह क्वेरी एक खाली परिणाम देता है:
orderid shippeddate ----------- ----------- (0 rows affected)
भले ही टी-एसक्यूएल IS NULL ऑपरेटर का समर्थन करता है, यह एक स्पष्ट IS <अभिव्यक्ति> ऑपरेटर का समर्थन नहीं करता है। इसलिए आप फ़िल्टर विधेय का उपयोग नहीं कर सकते जैसे कि WHERE शिपडेट IS @dt। दोबारा, मैं भविष्य के लेख में असमर्थित मानक विकल्प के बारे में बात करूंगा। T-SQL में इस आवश्यकता को हल करने के लिए कितने लोग करते हैं ISNULL या COALESCE फ़ंक्शन का उपयोग NULL को उस मान से बदलने के लिए करना है जो सामान्य रूप से दोनों पक्षों के डेटा में प्रकट नहीं हो सकता है, जैसे (मैं इस क्वेरी 2 को कॉल करूंगा):
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');
यह क्वेरी सही आउटपुट उत्पन्न करती है:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
लेकिन इस प्रश्न की योजना, जैसा कि चित्र 2 में दिखाया गया है, इष्टतम नहीं है।
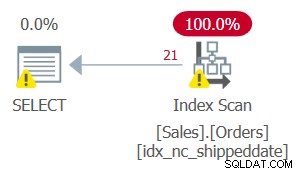 चित्र 2:क्वेरी 2 के लिए योजना
चित्र 2:क्वेरी 2 के लिए योजना
चूंकि आपने फ़िल्टर किए गए कॉलम में हेरफेर लागू किया है, इसलिए फ़िल्टर विधेय को अब SARG नहीं माना जाता है। सूचकांक अभी भी कवर कर रहा है, इसलिए इसका उपयोग किया जा सकता है; लेकिन इंडेक्स में सीधे क्वालिफाइंग पंक्तियों की श्रेणी में जाने के बजाय, पूरे इंडेक्स लीफ को स्कैन किया जाता है। मान लीजिए कि तालिका में 50,000,000 ऑर्डर थे, जिनमें से केवल 1,000 अनशिप्ड ऑर्डर थे। यह योजना सीधे क्वालिफाइंग 1,000 पंक्तियों तक जाने वाली खोज करने के बजाय सभी 50,000,000 पंक्तियों को स्कैन करेगी।
फ़िल्टर का एक रूप यह बताता है कि दोनों का सही अर्थ है कि हम खोज रहे हैं और इसे एक खोज तर्क माना जाता है (shippeddate =@dt OR (shippeddate IS NULL और @dt IS NULL))। यहाँ इस SARGable विधेय का उपयोग करने वाली एक क्वेरी है (हम इसे क्वेरी 3 कहेंगे):
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));
इस क्वेरी की योजना चित्र 3 में दिखाई गई है।
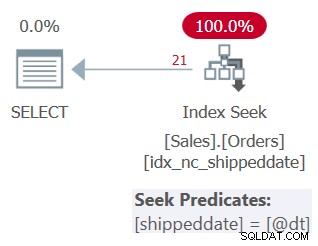 चित्र 3:क्वेरी 3 के लिए योजना
चित्र 3:क्वेरी 3 के लिए योजना
जैसा कि आप देख सकते हैं, योजना सहायक सूचकांक में एक खोज लागू करती है। सीक विधेय कहता है शिपडेट =@dt, लेकिन इसे आंतरिक रूप से तुलना के लिए गैर-नल मानों की तरह NULLs को संभालने के लिए डिज़ाइन किया गया है।
यह समाधान आम तौर पर एक उचित माना जाता है। यह मानक, इष्टतम और सही है। इसका मुख्य दोष यह है कि यह क्रिया है। क्या होगा यदि आपके पास NULLable कॉलम के आधार पर कई फ़िल्टर विधेय हों? आप जल्दी से एक लंबे और बोझिल WHERE क्लॉज के साथ समाप्त हो जाएंगे। और यह तब और भी खराब हो जाता है जब आपको एक फ़िल्टर विधेय लिखने की आवश्यकता होती है जिसमें एक NULLable कॉलम शामिल होता है जो पंक्तियों की तलाश में होता है जहाँ कॉलम इनपुट पैरामीटर से अलग होता है। विधेय तब बन जाता है:(shippeddate <> @dt और ((shippeddate IS NULL और @dt IS NOT NULL) या (shippeddate IS NOT NULL और @dt IS NULL)))।
आप स्पष्ट रूप से एक अधिक सुरुचिपूर्ण समाधान की आवश्यकता देख सकते हैं जो संक्षिप्त और इष्टतम दोनों हो। दुर्भाग्य से, कुछ गैर-मानक समाधान का सहारा लेते हैं जहां आप ANSI_NULLS सत्र विकल्प को बंद कर देते हैं। यह विकल्प SQL सर्वर को तीन-मूल्यवान तर्क के बजाय दो-मूल्यवान तर्क के साथ समानता (=) और (<>) से भिन्न (<>) ऑपरेटरों के गैर-मानक हैंडलिंग का उपयोग करने का कारण बनता है, तुलना उद्देश्यों के लिए गैर-नल मानों की तरह एनयूएलएल का इलाज करता है। कम से कम ऐसा तब तक है जब तक कोई एक ऑपरेंड एक पैरामीटर/चर या एक शाब्दिक है।
सत्र में ANSI_NULLS विकल्प को बंद करने के लिए निम्न कोड चलाएँ:
SET ANSI_NULLS OFF;
एक साधारण समानता-आधारित विधेय का उपयोग करके निम्न क्वेरी चलाएँ:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
यह क्वेरी 21 अनशिप्ड ऑर्डर लौटाती है। आपको वही योजना मिलती है जो पहले चित्र 3 में दिखाई गई है, जो अनुक्रमणिका में खोज दिखाती है।
जहां ANSI_NULLS चालू है, वहां मानक व्यवहार पर वापस जाने के लिए निम्न कोड चलाएँ:
SET ANSI_NULLS ON;
इस तरह के गैर-मानक व्यवहार पर भरोसा करने की सख्त मनाही है। दस्तावेज़ीकरण यह भी बताता है कि इस विकल्प के लिए समर्थन SQL सर्वर के कुछ भविष्य के संस्करण में हटा दिया जाएगा। इसके अलावा, कई लोगों को यह एहसास नहीं होता है कि यह विकल्प केवल तभी लागू होता है जब कम से कम एक ऑपरेंड एक पैरामीटर/चर या स्थिर हो, भले ही दस्तावेज़ीकरण इसके बारे में बिल्कुल स्पष्ट हो। दो स्तंभों की तुलना करते समय यह लागू नहीं होता है जैसे कि एक में शामिल हों।
तो यदि आप दोनों पक्षों के NULLs होने पर एक मैच प्राप्त करना चाहते हैं, तो आप NULLable जॉइन कॉलम से जुड़े जॉइन को कैसे हैंडल करते हैं? उदाहरण के तौर पर, T1 और T2 टेबल बनाने और भरने के लिए निम्न कोड का उपयोग करें:
DROP TABLE IF EXISTS dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
कोड दोनों पक्षों में जॉइन कीज़ (k1, k2, k3) के आधार पर जॉइन का समर्थन करने के लिए दोनों टेबलों पर कवरिंग इंडेक्स बनाता है।
कार्डिनैलिटी आँकड़ों को अद्यतन करने के लिए निम्नलिखित कोड का उपयोग करें, संख्याओं को बढ़ाएँ ताकि अनुकूलक को लगे कि आप बड़ी तालिकाओं के साथ काम कर रहे हैं:
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000; UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;
सरल समानता-आधारित विधेय का उपयोग करके दो तालिकाओं में शामिल होने के प्रयास में निम्न कोड का उपयोग करें:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3; पहले के फ़िल्टरिंग उदाहरणों की तरह, यहाँ भी एक समानता ऑपरेटर उपज UNKNOWN का उपयोग करके NULLs के बीच तुलना की जाती है, जिसके परिणामस्वरूप गैर-मिलान होता है। यह क्वेरी एक खाली आउटपुट उत्पन्न करती है:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
पहले के फ़िल्टरिंग उदाहरण की तरह ISNULL या COALESCE का उपयोग करना, NULL को उस मान से बदलना जो सामान्य रूप से दोनों पक्षों के डेटा में प्रकट नहीं हो सकता है, परिणामस्वरूप एक सही क्वेरी होती है (मैं इस क्वेरी को क्वेरी 4 के रूप में संदर्भित करूंगा):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648); यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
हालाँकि, जैसे फ़िल्टर किए गए कॉलम में हेरफेर करने से फ़िल्टर विधेय की SARGability टूट जाती है, वैसे ही जॉइन कॉलम में हेरफेर इंडेक्स ऑर्डर पर भरोसा करने की क्षमता को रोकता है। इसे इस क्वेरी की योजना में देखा जा सकता है जैसा कि चित्र 4 में दिखाया गया है।
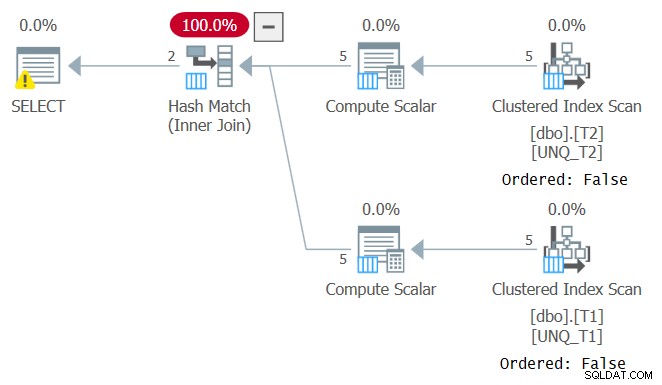 चित्र 4:क्वेरी 4 के लिए योजना
चित्र 4:क्वेरी 4 के लिए योजना
इस क्वेरी के लिए एक इष्टतम योजना वह है जो दो कवरिंग इंडेक्स के ऑर्डर किए गए स्कैन को लागू करती है, जिसके बाद मर्ज जॉइन एल्गोरिदम होता है, जिसमें कोई स्पष्ट सॉर्टिंग नहीं होती है। ऑप्टिमाइज़र ने एक अलग योजना चुनी क्योंकि यह इंडेक्स ऑर्डर पर भरोसा नहीं कर सका। यदि आप INNER MERGE JOIN का उपयोग करके मर्ज जॉइन एल्गोरिदम को बाध्य करने का प्रयास करते हैं, तो योजना अभी भी इंडेक्स के अनियंत्रित स्कैन पर निर्भर करेगी, इसके बाद स्पष्ट सॉर्टिंग होगी। कोशिश करो!
बेशक आप फ़िल्टरिंग कार्यों के लिए पहले दिखाए गए SARGable विधेय के समान लंबी विधेय का उपयोग कर सकते हैं:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL)); यह क्वेरी वांछित परिणाम उत्पन्न करती है और ऑप्टिमाइज़र को इंडेक्स ऑर्डर पर भरोसा करने में सक्षम बनाती है। हालांकि, हमारी आशा है कि हम एक ऐसा समाधान ढूंढे जो इष्टतम और संक्षिप्त दोनों हो।
एक अल्पज्ञात सुरुचिपूर्ण और संक्षिप्त तकनीक है जिसका उपयोग आप जॉइन और फिल्टर दोनों में कर सकते हैं, दोनों मैचों की पहचान करने और गैर-मिलानों की पहचान करने के उद्देश्य से। इस तकनीक को वर्षों पहले खोजा और प्रलेखित किया गया था, जैसे कि पॉल व्हाइट के उत्कृष्ट लेखन में अनिर्दिष्ट क्वेरी योजनाएं:2011 से समानता तुलना। लेकिन किसी कारण से ऐसा लगता है कि अभी भी बहुत से लोग इससे अनजान हैं, और दुर्भाग्य से उप-इष्टतम, लंबी और का उपयोग कर समाप्त हो जाते हैं। गैर मानक समाधान। यह निश्चित रूप से अधिक जोखिम और प्यार का पात्र है।
तकनीक इस तथ्य पर निर्भर करती है कि INTERSECT और EXCEPT जैसे सेट ऑपरेटर मूल्यों की तुलना करते समय एक विशिष्टता-आधारित तुलना दृष्टिकोण का उपयोग करते हैं, न कि समानता- या असमानता-आधारित तुलना दृष्टिकोण।
एक उदाहरण के रूप में हमारे शामिल होने के कार्य पर विचार करें। यदि हमें जॉइन कीज़ के अलावा अन्य कॉलम वापस करने की आवश्यकता नहीं है, तो हम एक INTERSECT ऑपरेटर के साथ एक साधारण क्वेरी (मैं इसे क्वेरी 5 के रूप में संदर्भित करूंगा) का उपयोग करता, जैसे:
SELECT k1, k2, k3 FROM dbo.T1 INTERSECT SELECT k1, k2, k3 FROM dbo.T2;
यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
इस क्वेरी के लिए योजना चित्र 5 में दिखाई गई है, यह पुष्टि करते हुए कि ऑप्टिमाइज़र इंडेक्स ऑर्डर पर भरोसा करने और मर्ज जॉइन एल्गोरिथम का उपयोग करने में सक्षम था।
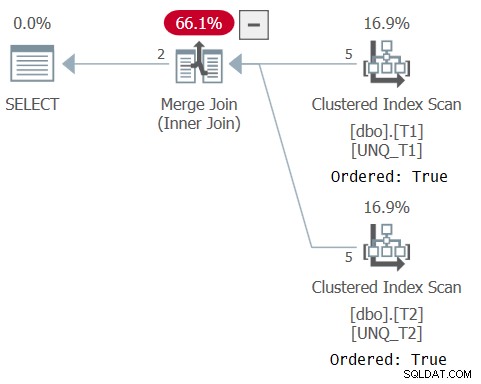 चित्र 5:प्रश्न 5 की योजना
चित्र 5:प्रश्न 5 की योजना
जैसा कि पॉल ने अपने लेख में लिखा है, सेट ऑपरेटर के लिए एक्सएमएल योजना एक अंतर्निहित आईएस तुलना ऑपरेटर का उपयोग करती है (CompareOp="IS" ) सामान्य जुड़ाव में उपयोग किए जाने वाले EQ तुलना ऑपरेटर के विपरीत (CompareOp="EQ" ) एक समाधान के साथ समस्या जो पूरी तरह से एक सेट ऑपरेटर पर निर्भर करती है वह यह है कि यह आपको केवल उन स्तंभों को वापस करने के लिए सीमित करता है जिनकी आप तुलना कर रहे हैं। हमें वास्तव में एक जॉइन और एक सेट ऑपरेटर के बीच एक हाइब्रिड की तरह की आवश्यकता होती है, जिससे आप तत्वों के एक सबसेट की तुलना कर सकते हैं, जबकि एक जॉइन की तरह अतिरिक्त लोगों को वापस कर सकते हैं, और एक सेट ऑपरेटर की तरह विशिष्टता-आधारित तुलना (आईएस) का उपयोग कर सकते हैं। यह बाहरी निर्माण के रूप में शामिल होने का उपयोग करके प्राप्त किया जा सकता है, और एक EXISTS एक इंटरसेक्ट ऑपरेटर के साथ एक क्वेरी के आधार पर शामिल होने के ON क्लॉज में दोनों पक्षों से जुड़ने वाली कुंजियों की तुलना करता है, जैसे (मैं इस समाधान को क्वेरी के रूप में संदर्भित करूंगा) 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
इंटरसेक्ट ऑपरेटर दो प्रश्नों पर काम करता है, प्रत्येक एक पंक्ति का एक सेट बनाता है जो दोनों ओर से जुड़ने वाली कुंजियों के आधार पर होता है। जब दो पंक्तियाँ समान होती हैं, तो INTERSECT क्वेरी एक पंक्ति लौटाती है; EXISTS विधेय TRUE लौटाता है, जिसके परिणामस्वरूप एक मैच होता है। जब दो पंक्तियाँ समान नहीं होती हैं, तो INTERSECT क्वेरी एक खाली सेट लौटाती है; EXISTS विधेय FALSE लौटाता है, जिसके परिणामस्वरूप एक गैर-मिलान होता है।
यह समाधान वांछित आउटपुट उत्पन्न करता है:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
इस क्वेरी की योजना चित्र 6 में दिखाई गई है, यह पुष्टि करते हुए कि अनुकूलक अनुक्रमणिका क्रम पर भरोसा करने में सक्षम था।
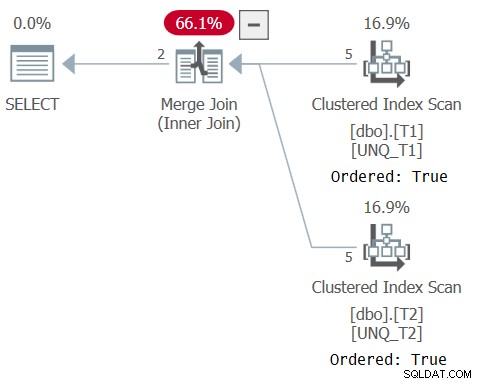 चित्र 6:प्रश्न 6 की योजना
चित्र 6:प्रश्न 6 की योजना
आप एक समान निर्माण का उपयोग फ़िल्टर विधेय के रूप में कर सकते हैं जिसमें एक स्तंभ और एक पैरामीटर/चर शामिल है, जो विशिष्टता के आधार पर मिलान देखने के लिए है, जैसे:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
योजना वही है जो पहले चित्र 3 में दिखाई गई थी।
आप गैर-मिलानों को देखने के लिए विधेय को नकार भी सकते हैं, जैसे:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
वैकल्पिक रूप से, आप एक सकारात्मक विधेय का उपयोग कर सकते हैं, लेकिन INTERSECT को EXCEPT से बदल सकते हैं, जैसे:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
ध्यान दें कि दोनों मामलों में योजनाएँ भिन्न हो सकती हैं, इसलिए बड़ी मात्रा में डेटा के साथ दोनों तरह से प्रयोग करना सुनिश्चित करें।
निष्कर्ष
एनयूएलएल आपके एसक्यूएल कोड लेखन में जटिलता का अपना हिस्सा जोड़ते हैं। आप हमेशा डेटा में एनयूएलएल की उपस्थिति की संभावना के बारे में सोचना चाहते हैं, और सुनिश्चित करें कि आप सही क्वेरी संरचनाओं का उपयोग करते हैं, और एनयूएलएल को सही तरीके से संभालने के लिए अपने समाधानों में प्रासंगिक तर्क जोड़ते हैं। उन्हें अनदेखा करना आपके कोड में बग को समाप्त करने का एक निश्चित तरीका है। इस महीने मैंने इस बात पर ध्यान केंद्रित किया कि स्थिरांक, चर, पैरामीटर और कॉलम की तुलना में एनयूएलएल क्या हैं और उन्हें कैसे नियंत्रित किया जाता है। अगले महीने मैं विभिन्न भाषा तत्वों में NULL उपचार विसंगतियों और NULL हैंडलिंग के लिए अनुपलब्ध मानक सुविधाओं पर चर्चा करके कवरेज जारी रखूंगा।