परिचय
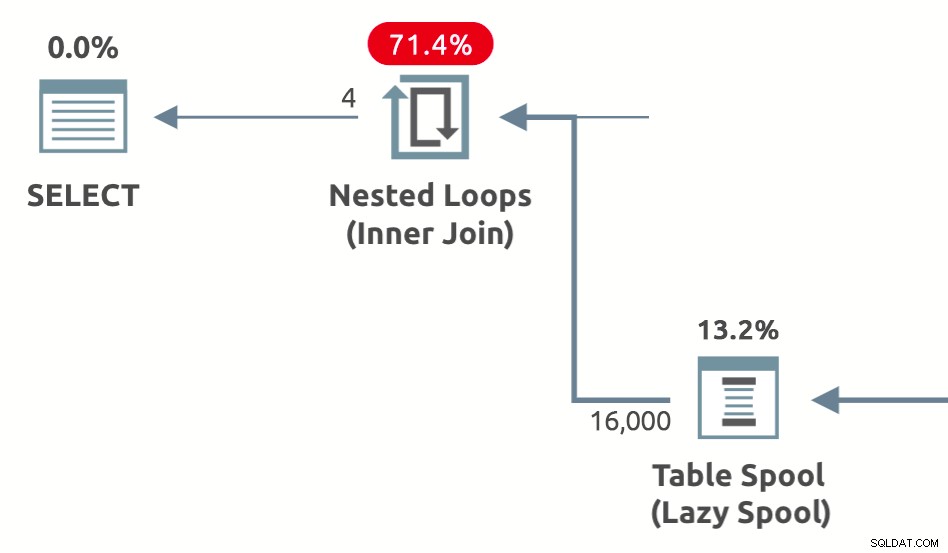
प्रदर्शन स्पूल आंतरिक पक्ष . की अनुमानित लागत को कम करने के लिए अनुकूलक द्वारा जोड़े गए आलसी स्पूल हैं नेस्टेड लूप जुड़ते हैं . वे तीन किस्मों में आते हैं:लेज़ी टेबल स्पूल , आलसी सूचकांक स्पूल , और आलसी पंक्ति गणना स्पूल . एक आलसी तालिका प्रदर्शन स्पूल दिखाने वाला एक उदाहरण योजना आकार नीचे है:
इस लेख में मैंने जिन सवालों के जवाब दिए हैं, वे हैं क्यों, कैसे और कब क्वेरी ऑप्टिमाइज़र प्रत्येक प्रकार के प्रदर्शन स्पूल का परिचय देता है।
शुरू करने से ठीक पहले, मैं एक महत्वपूर्ण बिंदु पर जोर देना चाहता हूं:निष्पादन योजनाओं में दो अलग-अलग प्रकार के नेस्टेड लूप शामिल होते हैं। मैं बाहरी संदर्भों . के साथ विविधता का उल्लेख करूंगा लागू करें . के रूप में , और जोड़ें विधेय . के साथ प्रकार नेस्टेड लूप जॉइन के रूप में जॉइन ऑपरेटर पर ही . स्पष्ट होने के लिए, यह अंतर निष्पादन योजना ऑपरेटरों . के बारे में है , टी-एसक्यूएल क्वेरी सिंटैक्स नहीं। अधिक विवरण के लिए, कृपया मेरा लिंक किया गया लेख देखें।
प्रदर्शन स्पूल
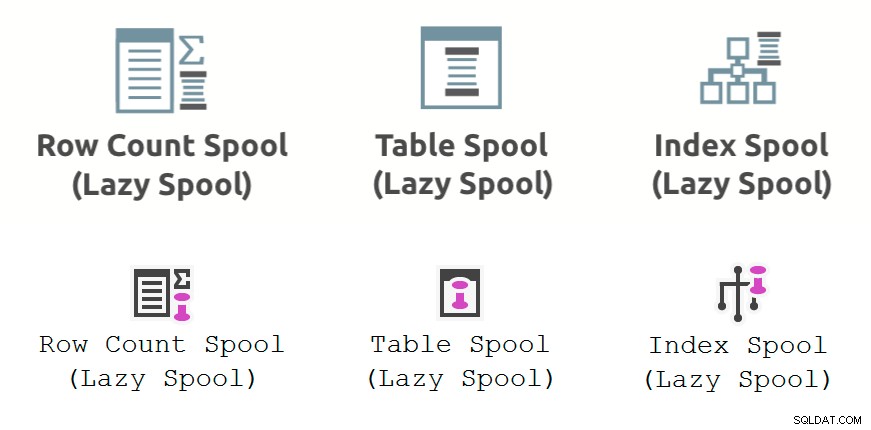
नीचे दिया गया चित्र प्रदर्शन स्पूल दिखाता है प्लान एक्सप्लोरर (शीर्ष पंक्ति) और एसएसएमएस 18.3 (निचली पंक्ति) में प्रदर्शित निष्पादन योजना ऑपरेटर:
सामान्य टिप्पणियां
सभी प्रदर्शन स्पूल आलसी हैं . स्पूल का वर्कटेबल धीरे-धीरे पॉप्युलेट होता है, एक समय में एक पंक्ति, क्योंकि स्पूल के माध्यम से पंक्तियाँ प्रवाहित होती हैं। (उत्सुक स्पूल, इसके विपरीत, अपने माता-पिता को कोई पंक्ति वापस करने से पहले अपने चाइल्ड ऑपरेटर से सभी इनपुट का उपभोग करते हैं)।
प्रदर्शन स्पूल हमेशा आंतरिक पक्ष . पर दिखाई देते हैं (चित्रमय निष्पादन योजनाओं में निचला इनपुट) एक नेस्टेड लूप के ऑपरेटर में शामिल होते हैं या लागू होते हैं। सामान्य विचार परिणामों को कैश करना और फिर से चलाना है, जहां भी संभव हो, आंतरिक-साइड ऑपरेटरों के बार-बार निष्पादन को सहेजना है।
जब स्पूल कैश्ड परिणामों को फिर से चलाने में सक्षम होता है, तो इसे रिवाइंड . के रूप में जाना जाता है . जब स्पूल को सही डेटा प्राप्त करने के लिए अपने चाइल्ड ऑपरेटरों को निष्पादित करना होता है, तो एक रिबाइंड होता है।
आपको स्पूल के बारे में सोचने में मदद मिल सकती है रिबाइंड कैश मिस के रूप में, और रिवाइंड कैश हिट के रूप में।
आलसी टेबल स्पूल
इस प्रकार के प्रदर्शन स्पूल का उपयोग लागू दोनों के साथ किया जा सकता है और नेस्टेड लूप जुड़ते हैं ।
लागू करें
एक रिबाइंड (कैश मिस) तब होता है जब कोई बाहरी संदर्भ मूल्य परिवर्तन। एक आलसी टेबल स्पूल छंटनी . द्वारा पुन:बंध जाती है इसकी कार्य तालिका और इसे अपने चाइल्ड ऑपरेटरों से पूरी तरह से फिर से तैयार करना।
एक रिवाइंड (कैश हिट) तब होता है जब आंतरिक पक्ष उसी . के साथ निष्पादित होता है बाहरी संदर्भ मान तुरंत पूर्ववर्ती . के रूप में लूप पुनरावृत्ति। एक रिवाइंड स्पूल के वर्कटेबल से कैश्ड परिणामों को रिप्ले करता है, स्पूल के नीचे योजना ऑपरेटरों को फिर से निष्पादित करने की लागत को बचाता है।
नोट:एक आलसी टेबल स्पूल केवल लागू करें . के एक सेट के परिणामों को कैश करता है बाहरी संदर्भ एक समय में मान।
नेस्टेड लूप्स में शामिल हों
पहले लूप पुनरावृत्ति के दौरान आलसी टेबल स्पूल एक बार भर जाता है। स्पूल शामिल होने के प्रत्येक बाद के पुनरावृत्ति के लिए अपनी सामग्री को रिवाइंड करता है। नेस्टेड लूप जॉइन के साथ, जॉइन का आंतरिक भाग पंक्तियों का एक स्थिर सेट होता है क्योंकि जॉइन विधेय ज्वाइन पर ही होता है। इसलिए स्थिर आंतरिक-पक्ष पंक्ति सेट को स्पूल के माध्यम से कई बार कैश और पुन:उपयोग किया जा सकता है। नेस्टेड लूप प्रदर्शन स्पूल में शामिल होते हैं, कभी भी रिबाइंड नहीं होते हैं।
लेज़ी रो काउंट स्पूल
एक पंक्ति गणना स्पूल टेबल स्पूल . से थोड़ा अधिक है बिना कॉलम के। यह एक पंक्ति के अस्तित्व को कैश करता है, लेकिन कोई कॉलम डेटा प्रोजेक्ट नहीं करता है। इसके अस्तित्व पर ध्यान देने और यह उल्लेख करने के अलावा कि यह कर सकता है स्रोत क्वेरी में एक त्रुटि का संकेत हो, मेरे पास पंक्ति गणना स्पूल के बारे में कहने के लिए और कुछ नहीं होगा।
इस बिंदु से आगे, जब भी आपको टेक्स्ट में "टेबल स्पूल" दिखाई दे, तो कृपया इसे "टेबल (या रो काउंट) स्पूल" के रूप में पढ़ें क्योंकि वे बहुत समान हैं।
लेज़ी इंडेक्स स्पूल
आलसी सूचकांक स्पूल ऑपरेटर केवल लागू होने पर उपलब्ध है ।
इंडेक्स स्पूल एक वर्कटेबल को बनाए रखता है जो छोटा नहीं गया . है जब बाहरी संदर्भ मूल्य बदलते हैं। इसके बजाय, बाहरी संदर्भ मानों द्वारा अनुक्रमित, मौजूदा कैश में नया डेटा जोड़ा जाता है। एक आलसी इंडेक्स स्पूल एक आलसी टेबल स्पूल से इस मायने में भिन्न होता है कि वह किसी भी से परिणामों को फिर से चला सकता है पूर्व लूप पुनरावृत्ति, न कि केवल सबसे हाल का।
निष्पादन योजनाओं में प्रदर्शन स्पूल कब दिखाई देते हैं, इसे समझने के अगले चरण में ऑप्टिमाइज़र कैसे काम करता है, इसके बारे में थोड़ा समझने की आवश्यकता है।
ऑप्टिमाइज़र बैकग्राउंड
एक स्रोत क्वेरी को पार्सिंग, बीजगणित, सरलीकरण और सामान्यीकरण द्वारा तार्किक वृक्ष प्रतिनिधित्व में परिवर्तित किया जाता है। जब परिणामी पेड़ एक तुच्छ योजना के लिए योग्य नहीं होता है, तो लागत-आधारित अनुकूलक तार्किक विकल्पों की तलाश करता है जो समान परिणाम देने की गारंटी देते हैं, लेकिन कम अनुमानित लागत पर।
एक बार ऑप्टिमाइज़र ने संभावित विकल्प उत्पन्न कर लिए, यह उपयुक्त भौतिक ऑपरेटरों का उपयोग करके प्रत्येक को लागू करता है, और अनुमानित लागतों की गणना करता है। अंतिम निष्पादन योजना प्रत्येक ऑपरेटर समूह के लिए मिले न्यूनतम लागत विकल्प से बनाई गई है। आप मेरी क्वेरी ऑप्टिमाइज़र डीप डाइव श्रृंखला में प्रक्रिया के बारे में अधिक विवरण पढ़ सकते हैं।
ऑप्टिमाइज़र की अंतिम योजना में प्रदर्शन स्पूल के प्रकट होने के लिए आवश्यक सामान्य शर्तें हैं:
- अनुकूलक को अन्वेषण करना चाहिए एक तार्किक विकल्प जिसमें एक तार्किक स्पूल . शामिल है एक उत्पन्न विकल्प में। यह जितना लगता है उससे कहीं अधिक जटिल है, इसलिए मैं अगले मुख्य भाग में विवरण खोल दूंगा।
- तार्किक स्पूल कार्यान्वयन योग्य . होना चाहिए एक भौतिक स्पूल . के रूप में निष्पादन इंजन में ऑपरेटर। SQL सर्वर के आधुनिक संस्करणों के लिए, इसका अनिवार्य रूप से मतलब है कि इंडेक्स स्पूल में सभी प्रमुख कॉलम तुलनीय के होने चाहिए। टाइप करें, कुल 900 बाइट्स* से अधिक नहीं, 64 कुंजी कॉलम या उससे कम के साथ।
- द सर्वश्रेष्ठ लागत-आधारित अनुकूलन के बाद पूरी योजना में स्पूल विकल्पों में से एक शामिल होना चाहिए। दूसरे शब्दों में, स्पूल और गैर-स्पूल विकल्पों के बीच किया गया कोई भी लागत-आधारित विकल्प स्पूल के पक्ष में आना चाहिए।
<उप>* यह मान SQL सर्वर में हार्ड-कोडेड है और गैर-क्लस्टर किए गए के लिए 1700 बाइट्स में वृद्धि के बाद इसे बदला नहीं गया है SQL सर्वर 2016 से अनुक्रमणिका कुंजियाँ। ऐसा इसलिए है क्योंकि स्पूल अनुक्रमणिका एक संकुलित . है अनुक्रमणिका, गैर-संकुल अनुक्रमणिका नहीं।
ऑप्टिमाइज़र नियम
हम टी-एसक्यूएल का उपयोग करके स्पूल निर्दिष्ट नहीं कर सकते हैं, इसलिए निष्पादन योजना में एक प्राप्त करने का मतलब है कि अनुकूलक को इसे जोड़ना चुनना होगा। पहले चरण के रूप में, इसका मतलब है कि अनुकूलक को उन विकल्पों में से एक में तार्किक स्पूल शामिल करना होगा जिसे वह एक्सप्लोर करना चाहता है।
ऑप्टिमाइज़र उन सभी तार्किक तुल्यता नियमों को पूरी तरह से लागू नहीं करता है जिन्हें वह प्रत्येक क्वेरी ट्री के लिए जानता है। ऑप्टिमाइज़र के एक उचित योजना को शीघ्रता से तैयार करने के लक्ष्य को देखते हुए यह बेकार होगा। इसके कई पहलू हैं। सबसे पहले, अनुकूलक चरणों में आगे बढ़ता है, सस्ते और अधिक बार लागू होने वाले नियमों के साथ पहले प्रयास किया जाता है। यदि प्रारंभिक चरण में एक उचित योजना मिल जाती है, या क्वेरी बाद के चरणों के लिए योग्य नहीं होती है, तो अनुकूलन प्रयास अब तक मिली सबसे कम लागत वाली योजना के साथ जल्दी समाप्त हो सकता है। यह रणनीति वृद्धिशील लागत सुधारों द्वारा बचाए जाने की तुलना में अनुकूलन पर अधिक समय खर्च करने से रोकने में मदद करती है।
नियम मिलान
वर्तमान अनुकूलन चरण में उपलब्ध नियमों के विरुद्ध पैटर्न मिलान के लिए क्वेरी ट्री में प्रत्येक तार्किक ऑपरेटर की शीघ्रता से जाँच की जाती है। उदाहरण के लिए, प्रत्येक नियम केवल तार्किक ऑपरेटरों के एक सबसेट से मेल खाएगा, और इसके लिए विशिष्ट गुणों की भी आवश्यकता हो सकती है, जैसे गारंटीकृत सॉर्ट किए गए इनपुट। एक नियम एक व्यक्तिगत तार्किक संचालन (एक समूह) या एक से अधिक सन्निहित समूहों (योजना का एक उपखंड) से मेल खा सकता है।
एक बार मिलान हो जाने पर, एक उम्मीदवार नियम को वादा मूल्य . उत्पन्न करने के लिए कहा जाता है . यह एक संख्या है जो दर्शाती है कि स्थानीय संदर्भ को देखते हुए वर्तमान नियम के उपयोगी परिणाम देने की कितनी संभावना है। उदाहरण के लिए, एक नियम एक उच्च वादा मूल्य उत्पन्न कर सकता है जब लक्ष्य के इनपुट पर कई डुप्लिकेट, पंक्तियों की एक बड़ी अनुमानित संख्या, गारंटीकृत क्रमबद्ध इनपुट, या कुछ अन्य वांछनीय संपत्ति होती है।
एक बार होनहार अन्वेषण नियमों की पहचान हो जाने के बाद, अनुकूलक उन्हें वादा मूल्य क्रम में क्रमबद्ध करता है, और उनसे नए तार्किक विकल्प उत्पन्न करने के लिए कहता है। प्रत्येक नियम एक या अधिक विकल्प उत्पन्न कर सकता है जिसे बाद में भौतिक ऑपरेटरों का उपयोग करके लागू किया जाएगा। उस प्रक्रिया के हिस्से के रूप में, अनुमानित लागत की गणना की जाती है।
प्रदर्शन स्पूल पर लागू होने वाले इस सब का बिंदु यह है कि तार्किक योजना आकार और गुण स्पूल-सक्षम नियमों से मेल खाने के लिए अनुकूल होना चाहिए, और स्थानीय संदर्भ को एक उच्च पर्याप्त वादा मूल्य उत्पन्न करना चाहिए जो अनुकूलक नियम का उपयोग करके विकल्प उत्पन्न करने के लिए चुनता है। ।
स्पूल नियम
ऐसे कई नियम हैं जो तार्किक नेस्टेड लूप जॉइन . को एक्सप्लोर करते हैं या लागू करें विकल्प। इनमें से कुछ नियम एक विशेष प्रकार के प्रदर्शन स्पूल के साथ एक या अधिक विकल्प उत्पन्न कर सकते हैं। अन्य नियम जो नेस्टेड लूप से मेल खाते हैं, जुड़ते हैं या लागू होते हैं, कभी भी स्पूल विकल्प उत्पन्न नहीं करते हैं।
उदाहरण के लिए, नियम ApplyToNL एक तार्किक लागू करें . को लागू करता है एक भौतिक लूप के रूप में बाहरी संदर्भों के साथ जुड़ते हैं। यह नियम कई विकल्प उत्पन्न कर सकता है हर बार यह चलता है। फिजिकल जॉइन ऑपरेटर के अलावा, प्रत्येक विकल्प में एक आलसी टेबल स्पूल, एक आलसी इंडेक्स स्पूल या बिल्कुल भी स्पूल नहीं हो सकता है। तार्किक स्पूल विकल्प को बाद में व्यक्तिगत रूप से लागू किया जाता है और उचित रूप से टाइप किए गए भौतिक स्पूल के रूप में खर्च किया जाता है, एक अन्य नियम जिसे BuildSpool कहा जाता है। ।
दूसरे उदाहरण के रूप में, नियम JNtoIdxLookup भौतिक लागू . के रूप में तार्किक जुड़ाव लागू करता है , एक अनुक्रमणिका के साथ तुरंत आंतरिक पक्ष की तलाश करें। यह नियम कभी नहीं स्पूल घटक के साथ एक विकल्प उत्पन्न करता है। JNtoIdxLookup जल्दी मूल्यांकन किया जाता है और जब यह मेल खाता है तो एक उच्च वादा मूल्य देता है, इसलिए सरल इंडेक्स-लुकअप योजनाएं जल्दी मिल जाती हैं।
जब ऑप्टिमाइज़र को इस तरह का कम लागत वाला विकल्प जल्दी मिल जाता है, तो अधिक जटिल विकल्पों को आक्रामक रूप से काट दिया जा सकता है या पूरी तरह से छोड़ दिया जा सकता है। तर्क यह है कि उन विकल्पों को आगे बढ़ाने का कोई मतलब नहीं है जो पहले से ही कम लागत वाले विकल्प में सुधार की संभावना नहीं रखते हैं। समान रूप से, यदि वर्तमान सर्वोत्तम पूर्ण योजना की कुल लागत पहले से ही काफी कम है, तो यह आगे की खोज के लायक नहीं है।
तीसरा नियम उदाहरण:नियम JNtoNL ApplyToNL . के समान है , लेकिन यह केवल भौतिक नेस्टेड लूप जॉइन . को लागू करता है , या तो आलसी टेबल स्पूल के साथ, या बिल्कुल भी स्पूल के साथ। यह नियम कभी नहीं एक इंडेक्स स्पूल उत्पन्न करता है क्योंकि उस प्रकार के स्पूल के लिए एक आवेदन की आवश्यकता होती है।
स्पूल जेनरेशन एंड कॉस्टिंग
एक नियम जो सक्षम . है एक तार्किक स्पूल उत्पन्न करने के लिए जरूरी नहीं कि हर बार इसे कहा जाए। ऐसे तार्किक विकल्प उत्पन्न करना बेकार होगा जिनके पास सबसे सस्ते के रूप में चुने जाने की कोई संभावना नहीं है। नए विकल्प उत्पन्न करने की लागत भी है, जो बदले में और अधिक विकल्प उत्पन्न कर सकते हैं - जिनमें से प्रत्येक को कार्यान्वयन और लागत की आवश्यकता हो सकती है।
इसे प्रबंधित करने के लिए, ऑप्टिमाइज़र सभी स्पूल-सक्षम नियमों के लिए सामान्य तर्क लागू करता है ताकि यह निर्धारित किया जा सके कि स्थानीय योजना स्थितियों के आधार पर स्पूल विकल्प का कौन सा प्रकार उत्पन्न करना है।
नेस्टेड लूप्स जॉइन करें
नेस्टेड लूप में शामिल होने के लिए , एक आलसी टेबल स्पूल . प्राप्त करने का मौका के अनुरूप बढ़ता है:
- पंक्तियों की अनुमानित संख्या शामिल होने के बाहरी इनपुट पर।
- अनुमानित लागत इनर-साइड प्लान ऑपरेटरों की।
स्पूल की लागत को आंतरिक-साइड ऑपरेटर निष्पादन से बचने के लिए की गई बचत से चुकाया जाता है। अधिक आंतरिक पुनरावृत्तियों और उच्च आंतरिक-पक्ष लागत के साथ बचत बढ़ती है। यह विशेष रूप से सच है क्योंकि लागत मॉडल टेबल स्पूल रिवाइंड (कैश हिट) को अपेक्षाकृत कम I/O और CPU लागत संख्या प्रदान करता है। याद रखें कि नेस्टेड लूप पर एक टेबल स्पूल केवल कभी भी रिवाइंड का अनुभव करता है, क्योंकि पैरामीटर की कमी का मतलब है कि आंतरिक-साइड डेटा सेट स्थिर है।
स्पूल डेटा को अधिक सघनता से स्टोर कर सकता है इसे खिलाने वाले ऑपरेटरों की तुलना में। उदाहरण के लिए, एक बेस टेबल क्लस्टर इंडेक्स औसतन प्रति पेज 100 पंक्तियों को स्टोर कर सकता है। मान लें कि किसी क्वेरी को प्रत्येक विस्तृत क्लस्टर इंडेक्स पंक्ति से केवल एक पूर्णांक कॉलम मान की आवश्यकता होती है। स्पूल वर्कटेबल में केवल पूर्णांक मान संग्रहीत करने का अर्थ है कि प्रति पृष्ठ 800 से अधिक ऐसी पंक्तियों को संग्रहीत किया जा सकता है। यह महत्वपूर्ण है क्योंकि ऑप्टिमाइज़र कार्य योग्य पृष्ठों की संख्या के अनुमान का उपयोग करके आंशिक रूप से तालिका स्पूल की लागत का आकलन करता है आवश्यकता है। अन्य लागत कारकों में लूप पुनरावृत्तियों की अनुमानित संख्या से अधिक, स्पूल को लिखने और पढ़ने में शामिल प्रति-पंक्ति CPU लागत शामिल है।
ऑप्टिमाइज़र निश्चित रूप से आलसी टेबल स्पूल को नेस्टेड लूप्स जॉइन के अंदरूनी हिस्से में जोड़ने के लिए बहुत उत्सुक है। फिर भी, अनुमानित लागत के संदर्भ में अनुकूलक का निर्णय हमेशा समझ में आता है। मैं व्यक्तिगत रूप से नेस्टेड लूप्स जॉइन को उच्च जोखिम . के रूप में मानता हूं , क्योंकि इनपुट कार्डिनैलिटी अनुमान बहुत कम होने पर वे जल्दी से धीमे हो सकते हैं।
एक टेबल स्पूल हो सकता है लागत को कम करने में मदद करता है, लेकिन यह एक भोले नेस्टेड लूप में शामिल होने के सबसे खराब स्थिति के प्रदर्शन को पूरी तरह से छिपा नहीं सकता है। एक अनुक्रमित लागू जुड़ाव सामान्य रूप से बेहतर होता है, और अनुमान त्रुटियों के लिए अधिक लचीला होता है। प्रश्नों को लिखना भी एक अच्छा विचार है जिसे ऑप्टिमाइज़र हैश के साथ कार्यान्वित कर सकता है या उपयुक्त होने पर मर्ज में शामिल हो सकता है।
लेज़ी टेबल स्पूल लागू करें
आवेदन करें . के लिए , आलसी टेबल स्पूल . प्राप्त करने की संभावना डुप्लिकेट . की अनुमानित संख्या के साथ वृद्धि आवेदन के बाहरी इनपुट पर प्रमुख मूल्यों में शामिल हों। अधिक डुप्लिकेट के साथ, सांख्यिकीय रूप से . है स्पूल के प्रत्येक पुनरावृत्ति पर इसके वर्तमान में संग्रहीत परिणामों को रिवाइंड करने की उच्च संभावना। कम अनुमानित लागत के साथ लागू आलसी टेबल स्पूल अंतिम निष्पादन योजना में शामिल होने का एक बेहतर मौका है।
जब लागू बाहरी इनपुट पर आने वाली पंक्तियों का कोई विशेष क्रम नहीं होता है, तो अनुकूलक एक सांख्यिकीय मूल्यांकन करता है। प्रत्येक पुनरावृत्ति के सस्ते रिवाइंड या महंगे रिबाइंड के परिणामस्वरूप होने की कितनी संभावना है। यह आकलन उपलब्ध होने पर हिस्टोग्राम चरणों से डेटा का उपयोग करता है, लेकिन यह सबसे अच्छा मामला परिदृश्य भी एक शिक्षित अनुमान है। गारंटी के बिना, लागू बाहरी इनपुट पर आने वाली पंक्तियों का क्रम अप्रत्याशित है।
वही अनुकूलक नियम जो तार्किक स्पूल विकल्प उत्पन्न करते हैं भी . हो सकते हैं निर्दिष्ट करें कि लागू ऑपरेटर आवश्यकता क्रमबद्ध पंक्तियाँ इसके बाहरी इनपुट पर। यह आलसी स्पूल को अधिकतम करता है रिवाइंड क्योंकि सभी डुप्लीकेट ब्लॉक में होने की गारंटी है। जब बाहरी इनपुट सॉर्ट ऑर्डर की गारंटी दी जाती है, या तो संरक्षित ऑर्डरिंग या स्पष्ट सॉर्ट करें . द्वारा , स्पूल की लागत बहुत कम है। स्पूल रिवाइंड और रिबाइंड की संख्या पर सॉर्ट ऑर्डर के प्रभाव में ऑप्टिमाइज़र कारक।
एक सॉर्ट करें . के साथ योजनाएं लागू बाहरी इनपुट पर, और एक आलसी टेबल स्पूल आंतरिक इनपुट पर काफी आम हैं। बाहरी तरफ छँटाई अनुकूलन अभी भी प्रति-उत्पादक हो सकता है। उदाहरण के लिए, ऐसा तब हो सकता है जब बाहरी तरफ कार्डिनैलिटी का अनुमान इतना कम हो कि सॉर्ट tempdb तक फैल जाए। ।
लेज़ी इंडेक्स स्पूल लागू करें
आवेदन करें . के लिए , एक आलसी अनुक्रमणिका स्पूल . प्राप्त करना विकल्प योजना के आकार के साथ-साथ लागत पर भी निर्भर करता है।
अनुकूलक की आवश्यकता है:
- कुछ डुप्लिकेट बाहरी इनपुट पर मूल्यों में शामिल हों।
- एक समानता विधेय में शामिल हों (या एक तार्किक समकक्ष जिसे अनुकूलक समझता है, जैसे
x <= y AND x >= y)। - एक गारंटी कि बाहरी संदर्भ अद्वितीय हैं प्रस्तावित आलसी सूचकांक स्पूल के नीचे।
निष्पादन योजनाओं में, आवश्यक विशिष्टता अक्सर बाहरी संदर्भों, या एक अदिश समुच्चय (बिना किसी समूह के) द्वारा एक समग्र समूह द्वारा प्रदान की जाती है। विशिष्टता अन्य तरीकों से भी प्रदान की जा सकती है, उदाहरण के लिए एक अद्वितीय सूचकांक या बाधा का अस्तित्व।
एक खिलौना उदाहरण जो योजना का आकार दिखाता है वह नीचे है:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
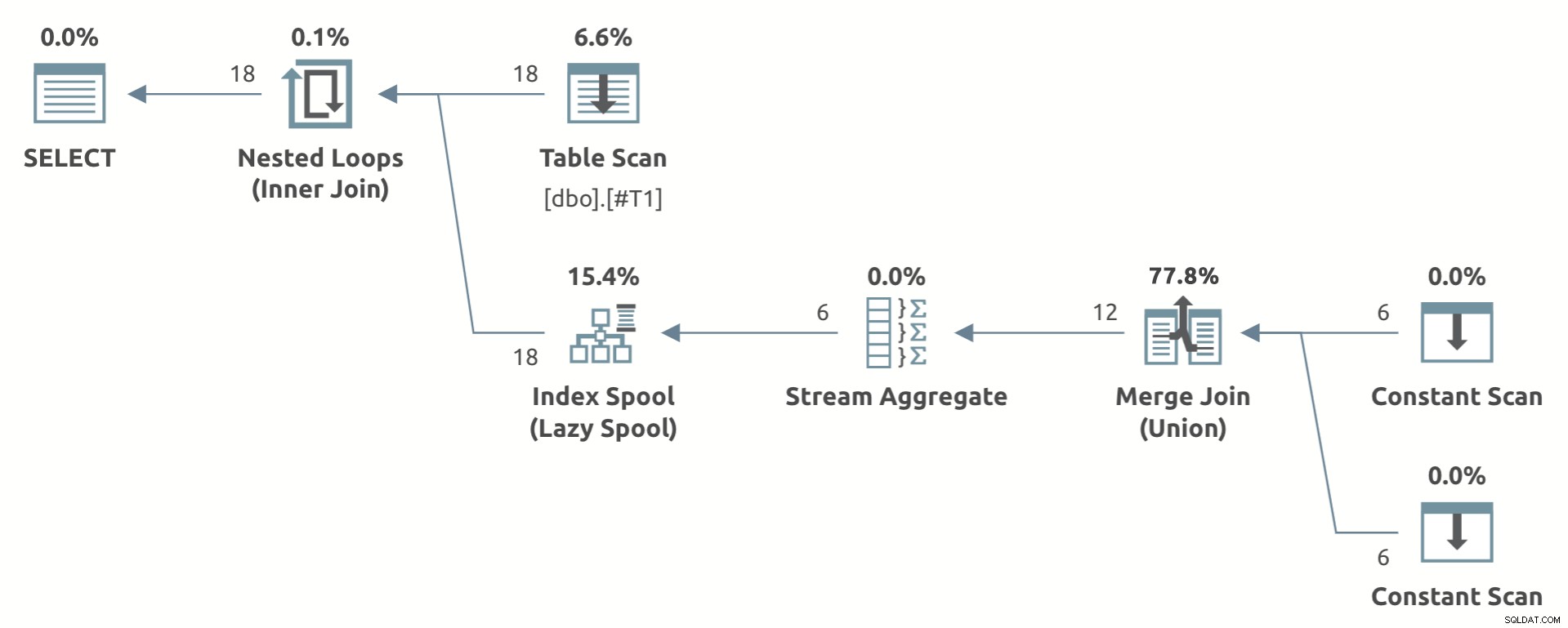
स्ट्रीम एग्रीगेट पर ध्यान दें आलसी अनुक्रमणिका स्पूल . के नीचे ।
यदि योजना आकार की आवश्यकताओं को पूरा किया जाता है, तो अनुकूलक अक्सर एक आलसी सूचकांक विकल्प उत्पन्न करेगा (पहले उल्लेखित चेतावनियों के अधीन)। अंतिम योजना में आलसी इंडेक्स स्पूल शामिल है या नहीं यह लागत पर निर्भर करता है।
इंडेक्स स्पूल बनाम टेबल स्पूल
अनुमानित रिवाइंड . की संख्या और फिर से बांधता है आलसी इंडेक्स स्पूल के लिए समान . है आलसी टेबल स्पूल के लिए बिना सॉर्ट किया गया बाहरी इनपुट लागू करें।
यह एक दुर्भाग्यपूर्ण स्थिति की तरह लग सकता है। इंडेक्स स्पूल का प्राथमिक लाभ यह है कि यह पहले देखे गए सभी परिणामों को कैश करता है। यह इंडेक्स स्पूल को रिवाइंड्स बनाना चाहिए समान परिस्थितियों में टेबल स्पूल (बाहरी-इनपुट छँटाई के बिना) की तुलना में अधिक संभावना है। मेरी समझ यह है कि यह विचित्रता मौजूद है क्योंकि इसके बिना, ऑप्टिमाइज़र बहुत अधिक बार एक इंडेक्स स्पूल का चयन करेगा।
भले ही, इंडेक्स और टेबल स्पूल के लिए अलग-अलग प्रारंभिक और अनुवर्ती-पंक्ति I/O और CPU लागत संख्याओं का उपयोग करके लागत मॉडल कुछ हद तक उपरोक्त के लिए समायोजित करता है। शुद्ध प्रभाव यह है कि एक इंडेक्स स्पूल की कीमत आमतौर पर बिना सॉर्ट किए गए बाहरी इनपुट के टेबल स्पूल से कम होती है, लेकिन प्रतिबंधात्मक योजना आकार की आवश्यकताओं को याद रखें, जो आलसी इंडेक्स स्पूल को अपेक्षाकृत बनाती हैं। दुर्लभ।
फिर भी, एक आलसी स्पूल इंडेक्स के लिए प्राथमिक लागत प्रतियोगी एक टेबल स्पूल है साथ बाहरी इनपुट को क्रमबद्ध करें। इसके लिए अंतर्ज्ञान काफी सीधा है:सॉर्ट किए गए बाहरी इनपुट का मतलब है कि टेबल स्पूल को सभी डुप्लिकेट बाहरी संदर्भों को क्रमिक रूप से देखने की गारंटी है। इसका अर्थ यह है कि यह पुन:बाँध देगा प्रति विशिष्ट मान केवल एक बार, और रिवाइंड करें सभी डुप्लिकेट के लिए। यह एक इंडेक्स स्पूल के अपेक्षित व्यवहार के समान है (तार्किक रूप से कम से कम बोलना)।
व्यवहार में, एक इंडेक्स स्पूल को कम डुप्लिकेट लागू कुंजी मानों के लिए सॉर्ट-ऑप्टिमाइज़्ड टेबल स्पूल पर पसंद किए जाने की अधिक संभावना है। कम डुप्लीकेट कुंजियाँ होने से रिवाइंड पहले बताए गए "दुर्भाग्यपूर्ण" इंडेक्स स्पूल अनुमानों की तुलना में सॉर्ट-ऑप्टिमाइज़्ड टेबल स्पूल का लाभ।
इंडेक्स स्पूल विकल्प को टेबल स्पूल के बाहरी हिस्से की अनुमानित लागत के रूप में भी लाभ मिलता है सॉर्ट करें बढ़ती है। यह अक्सर योजना में उस बिंदु पर अधिक (या व्यापक) पंक्तियों से जुड़ा होता है।
ट्रेस फ़्लैग और संकेत
-
प्रदर्शन स्पूल अक्षम हो सकते हैं हल्के ढंग से प्रलेखित ट्रेस फ्लैग के साथ 8690 , या प्रलेखित क्वेरी संकेत
NO_PERFORMANCE_SPOOLSQL सर्वर 2016 या बाद के संस्करण पर। -
अनिर्दिष्ट ट्रेस ध्वज 8691 हमेशा एक प्रदर्शन स्पूल जोड़ने . के लिए (एक परीक्षण प्रणाली पर) उपयोग किया जा सकता है जब संभव। प्रकार आलसी स्पूल जो आपको मिलता है (पंक्ति गणना, तालिका, या अनुक्रमणिका) को मजबूर नहीं किया जा सकता है; यह अभी भी लागत अनुमान पर निर्भर करता है।
-
गैर-दस्तावेज ट्रेस ध्वज 2363 विशिष्ट अनुमान की व्युत्पत्ति देखने के लिए नए कार्डिनैलिटी अनुमान मॉडल के साथ उपयोग किया जा सकता है किसी आवेदन के बाहरी इनपुट पर, और सामान्य रूप से कार्डिनैलिटी अनुमान पर।
-
गैर-दस्तावेज ट्रेस ध्वज 9198 आलसी अनुक्रमणिका प्रदर्शन स्पूल अक्षम करने . के लिए उपयोग किया जा सकता है विशेष रूप से। लागत के आधार पर आपको अभी भी एक आलसी तालिका या पंक्ति गणना स्पूल मिल सकती है (सॉर्ट ऑप्टिमाइज़ेशन के साथ या बिना)।
-
अनिर्दिष्ट ट्रेस ध्वज 2387 CPU लागत को कम करने . के लिए उपयोग किया जा सकता है आलसी अनुक्रमणिका स्पूल . से पंक्तियों को पढ़ने का . यह ध्वज बी-पेड़ से पंक्तियों की एक श्रृंखला को पढ़ने के लिए सामान्य CPU लागत अनुमानों को प्रभावित करता है। लागत कारणों से यह फ़्लैग इंडेक्स स्पूल चयन को अधिक संभावित बनाता है।
क्वेरी संकलन के दौरान कौन से ऑप्टिमाइज़र नियम सक्रिय किए गए थे, यह निर्धारित करने के लिए अन्य ट्रेस फ़्लैग और विधियाँ मेरी क्वेरी ऑप्टिमाइज़र डीप डाइव श्रृंखला में पाई जा सकती हैं।
अंतिम विचार
बहुत सारे आंतरिक विवरण हैं जो प्रभावित करते हैं कि अंतिम निष्पादन योजना एक प्रदर्शन स्पूल का उपयोग करती है या नहीं। मैंने इस लेख में स्पूल ऑपरेटर लागत फ़ार्मुलों के अत्यंत जटिल विवरणों में बहुत दूर जाने के बिना, मुख्य विचारों को कवर करने का प्रयास किया है। उम्मीद है कि निष्पादन योजना (या इसके अभाव) में किसी विशेष प्रदर्शन स्पूल प्रकार के संभावित कारणों को निर्धारित करने में आपकी सहायता करने के लिए यहां पर्याप्त सामान्य सलाह है।
प्रदर्शन स्पूल अक्सर खराब रैप प्राप्त करते हैं, मुझे लगता है कि यह कहना उचित है। इसमें से कुछ निस्संदेह योग्य हैं। आप में से कई लोगों ने एक डेमो देखा होगा जहां एक योजना "प्रदर्शन स्पूल" के बिना तेजी से निष्पादित होती है। कुछ हद तक यह अप्रत्याशित नहीं है। किनारे के मामले मौजूद हैं, लागत मॉडल सही नहीं है, और इसमें कोई संदेह नहीं है कि डेमो में अक्सर खराब कार्डिनैलिटी अनुमान, या अन्य अनुकूलक-सीमित मुद्दों के साथ योजनाएं होती हैं।
उस ने कहा, मैं कभी-कभी चाहता हूं कि SQL सर्वर किसी प्रकार की चेतावनी या अन्य प्रतिक्रिया प्रदान करे, जब यह एक नेस्टेड लूप में एक आलसी टेबल स्पूल जोड़ने का सहारा लेता है (या एक उपयोग किए गए समर्थन वाले आंतरिक-साइड इंडेक्स के बिना लागू होता है)। जैसा कि मुख्य भाग में बताया गया है, जब कार्डिनैलिटी का अनुमान बहुत ही कम हो जाता है, तो मुझे लगता है कि ये वे स्थितियां हैं जो अक्सर बुरी तरह से गलत हो जाती हैं।
शायद एक दिन क्वेरी ऑप्टिमाइज़र विकल्पों की योजना बनाने के लिए जोखिम की कुछ अवधारणा में कारक होगा, या अधिक "अनुकूली" क्षमताएं प्रदान करेगा। इस बीच, यह आपके नेस्टेड लूप्स को उपयोगी इंडेक्स के साथ जोड़ने का समर्थन करता है, और उन प्रश्नों को लिखने से बचने के लिए जिन्हें केवल नेस्टेड लूप का उपयोग करके लागू किया जा सकता है। मैं निश्चित रूप से सामान्यीकरण कर रहा हूं, लेकिन ऑप्टिमाइज़र बेहतर प्रदर्शन करता है जब उसके पास अधिक विकल्प होते हैं, एक उचित स्कीमा, अच्छा मेटाडेटा, और साथ काम करने के लिए प्रबंधनीय टी-एसक्यूएल स्टेटमेंट। मैं जैसा हूं, इसके बारे में सोचने के लिए आओ।
अन्य स्पूल लेख
गैर-प्रदर्शन स्पूल का उपयोग SQL सर्वर के भीतर कई उद्देश्यों के लिए किया जाता है, जिनमें शामिल हैं:
- हैलोवीन सुरक्षा
- कुछ पंक्ति-मोड विंडो फ़ंक्शन
- एकाधिक समुच्चय की गणना करना
- डेटा बदलने वाले कथनों को अनुकूलित करना