मेरे सिर के ऊपर से, मेरे पास आपके लिए 50% समाधान है।
समस्या
एसएसआईएस वास्तव में मेटा डेटा की परवाह करता है इसलिए इसमें बदलाव के परिणामस्वरूप अपवाद होते हैं। इस अर्थ में डीटीएस कहीं अधिक क्षमाशील था। लगातार मेटा डेटा की वह प्रबल आवश्यकता फ़्लैट फ़ाइल स्रोत के उपयोग को कठिन बना देती है।
क्वेरी आधारित समाधान
यदि समस्या घटक है, तो इसका उपयोग न करें। इस दृष्टिकोण के बारे में मुझे जो पसंद है वह यह है कि अवधारणात्मक रूप से, यह तालिका को क्वेरी करने जैसा ही है-स्तंभों का क्रम मायने नहीं रखता और न ही अतिरिक्त स्तंभों की उपस्थिति मायने रखती है।
चर
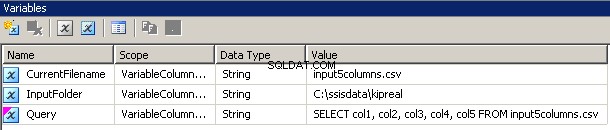
मैंने 3 चर बनाए, सभी प्रकार की स्ट्रिंग:CurrentFileName, InputFolder और Query।
- इनपुट फोल्डर को सोर्स फोल्डर से हार्ड वायर किया जाता है। मेरे उदाहरण में, यह
C:\ssisdata\Kipreal. है - CurrentFileName एक फ़ाइल का नाम है। डिजाइन समय के दौरान, यह
input5columns.csvथा लेकिन वह रन टाइम पर बदल जाएगा। - क्वेरी एक एक्सप्रेशन है
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
कनेक्शन प्रबंधक
JET OLEDB ड्राइवर का उपयोग करके इनपुट फ़ाइल से कनेक्शन सेट करें। लिंक किए गए आलेख में वर्णित अनुसार इसे बनाने के बाद, मैंने इसका नाम बदलकर FileOLEDB कर दिया और "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
नियंत्रण प्रवाह
मेरा नियंत्रण प्रवाह एक डेटा प्रवाह कार्य की तरह दिखता है जो Foreach फ़ाइल गणक में नेस्टेड है
फॉरच फ़ाइल एन्यूमरेटर
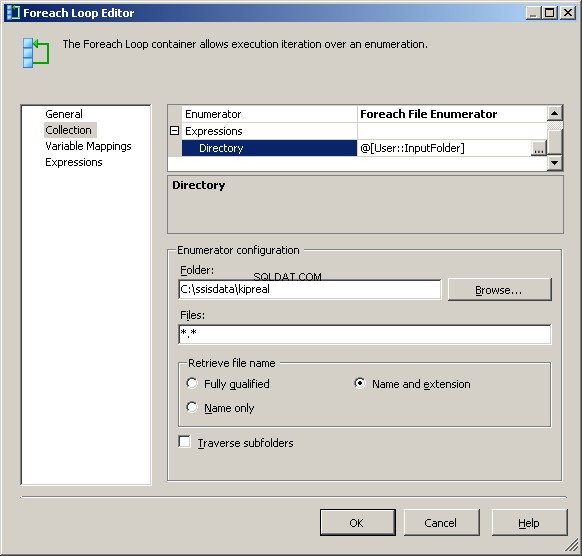
माई फ़ोरैच फ़ाइल एन्यूमरेटर को फाइलों पर काम करने के लिए कॉन्फ़िगर किया गया है। मैंने @[User::InputFolder] . के लिए डायरेक्टरी पर एक एक्सप्रेशन रखा है ध्यान दें कि इस बिंदु पर, यदि उस फ़ोल्डर के मान को बदलने की आवश्यकता है, तो इसे कनेक्शन प्रबंधक और फ़ाइल एन्यूमरेटर दोनों में सही ढंग से अपडेट किया जाएगा। "फ़ाइल नाम पुनर्प्राप्त करें" में, डिफ़ॉल्ट "पूरी तरह से योग्य" के बजाय, "नाम और एक्सटेंशन" चुनें
वैरिएबल मैपिंग टैब में, हमारे @[User::CurrentFileName] को मान असाइन करें परिवर्तनशील
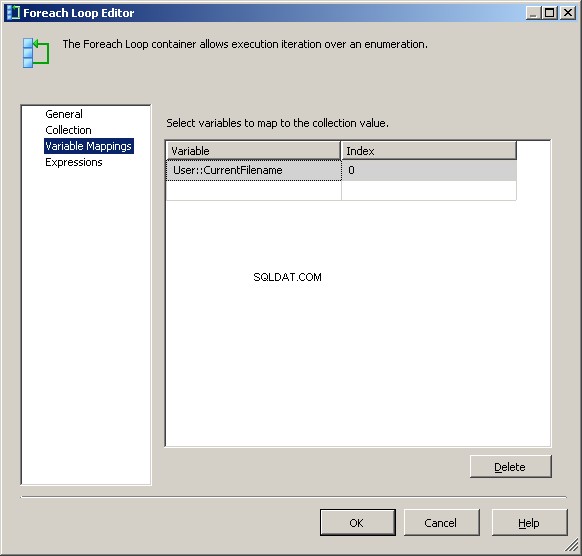
इस बिंदु पर, लूप का प्रत्येक पुनरावृत्ति @[User::Query के मान को बदल देगा वर्तमान फ़ाइल नाम को प्रतिबिंबित करने के लिए।
डेटा प्रवाह
यह वास्तव में सबसे आसान टुकड़ा है। एक OLE DB स्रोत का उपयोग करें और इसे बताए अनुसार तार करें।
FileOLEDB कनेक्शन मैनेजर का उपयोग करें और डेटा एक्सेस मोड को "वैरिएबल से SQL कमांड" में बदलें। @[User::Query] . का उपयोग करें वहाँ चर, ठीक क्लिक करें और आप काम करने के लिए तैयार हैं। 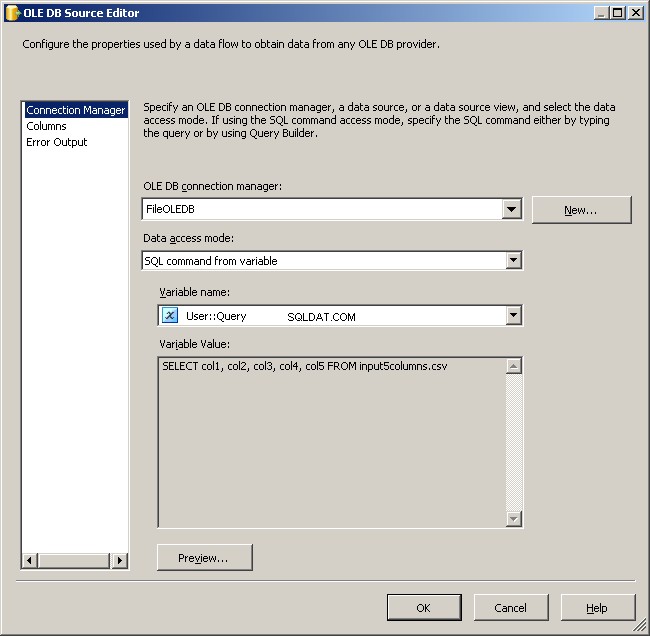
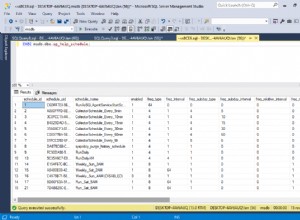
नमूना डेटा
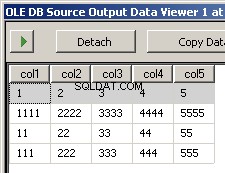
मैंने दो नमूना फाइलें बनाई हैं input5columns.csv और input7columns.csv 5 के सभी कॉलम 7 में हैं लेकिन 7 में उन्हें एक अलग क्रम में रखा गया है (col2 क्रमिक स्थिति 2 और 6 है)। मैंने 7 में सभी मानों को नकार दिया ताकि यह आसानी से स्पष्ट हो सके कि कौन सी फ़ाइल संचालित की जा रही है।
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
और
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
पैकेज चलाने से इन दो स्क्रीन शॉट्स में परिणाम मिलते हैं
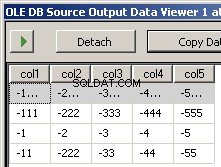
क्या गुम है
मुझे क्वेरी आधारित दृष्टिकोण को बताने का कोई तरीका नहीं पता है कि यदि कोई कॉलम मौजूद नहीं है तो यह ठीक है। यदि कोई अद्वितीय कुंजी है, तो मुझे लगता है कि आप अपनी क्वेरी को केवल उन स्तंभों के लिए परिभाषित कर सकते हैं जो होना चाहिए वहां रहें और फिर उन स्तंभों को प्राप्त करने का प्रयास करने के लिए फ़ाइल के विरुद्ध लुकअप करें जो चाहिए यदि कॉलम मौजूद नहीं है तो वहां रहें और लुकअप को विफल न करें। हालांकि बहुत कुटिल।