तालिका भावों के बारे में श्रृंखला की यह तेरहवीं और अंतिम किस्त है। इस महीने मैं इनलाइन टेबल-वैल्यूड फंक्शन्स (iTVFs) के बारे में पिछले महीने शुरू की गई चर्चा को जारी रखता हूं।
पिछले महीने मैंने समझाया कि जब SQL सर्वर इनपुट के रूप में स्थिरांक के साथ पूछे गए iTVFs को इनलाइन करता है, तो यह डिफ़ॉल्ट रूप से पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन लागू करता है। पैरामीटर एम्बेडिंग का अर्थ है कि SQL सर्वर क्वेरी में पैरामीटर संदर्भों को वर्तमान निष्पादन से शाब्दिक स्थिर मानों से बदल देता है, और फिर स्थिरांक वाला कोड अनुकूलित हो जाता है। यह प्रक्रिया सरलीकरण को सक्षम करती है जिसके परिणामस्वरूप अधिक इष्टतम क्वेरी योजनाएँ बन सकती हैं। इस महीने मैं इस विषय पर विस्तार से बताता हूं, जैसे कि निरंतर तह और गतिशील फ़िल्टरिंग और ऑर्डरिंग जैसे सरलीकरण के लिए विशिष्ट मामलों को कवर करना। यदि आपको पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन पर एक पुनश्चर्या की आवश्यकता है, तो पिछले महीने के लेख के साथ-साथ पॉल व्हाइट के उत्कृष्ट लेख पैरामीटर स्नीफ़िंग, एम्बेडिंग और RECOMPILE विकल्प देखें।
मेरे उदाहरणों में, मैं TSQLV5 नामक एक नमूना डेटाबेस का उपयोग करूँगा। आप इसे यहां और इसके ईआर आरेख को बनाने और पॉप्युलेट करने वाली स्क्रिप्ट यहां पा सकते हैं।
लगातार तह करना
क्वेरी प्रोसेसिंग के शुरुआती चरणों के दौरान, SQL सर्वर स्थिरांक से जुड़े कुछ भावों का मूल्यांकन करता है, उन्हें परिणाम स्थिरांक में बदल देता है। उदाहरण के लिए, व्यंजक 40 + 2 को स्थिरांक 42 में मोड़ा जा सकता है। आप “स्थिर मोड़ और व्यंजक मूल्यांकन” के अंतर्गत फोल्डेबल और नॉनफोल्डेबल व्यंजकों के नियम यहाँ पा सकते हैं।
आईटीवीएफ के संबंध में जो दिलचस्प है वह यह है कि पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन के लिए धन्यवाद, आईटीवीएफ से जुड़े प्रश्न जहां आप इनपुट के रूप में स्थिरांक पास करते हैं, सही परिस्थितियों में, निरंतर फोल्डिंग से लाभान्वित हो सकते हैं। फोल्डेबल और नॉन फोल्डेबल एक्सप्रेशन के नियमों को जानने से आपके iTVF को लागू करने का तरीका प्रभावित हो सकता है। कुछ मामलों में, अपने भावों में बहुत सूक्ष्म परिवर्तन लागू करके, आप अनुक्रमण के बेहतर उपयोग के साथ अधिक इष्टतम योजनाओं को सक्षम कर सकते हैं।
एक उदाहरण के रूप में, Sales.MyOrders नामक iTVF के निम्नलिखित कार्यान्वयन पर विचार करें:
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO iTVF से संबंधित निम्नलिखित प्रश्न जारी करें (मैं इसे प्रश्न 1 के रूप में संदर्भित करूंगा):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
प्रश्न 1 की योजना चित्र 1 में दिखाई गई है।
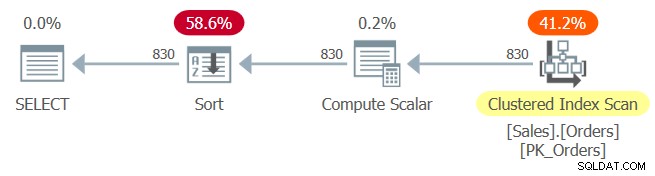 चित्र 1:प्रश्न 1 के लिए योजना
चित्र 1:प्रश्न 1 के लिए योजना
संकुल सूचकांक PK_Orders को key के रूप में orderid के साथ परिभाषित किया गया है। यदि पैरामीटर एम्बेडिंग के बाद यहां लगातार फोल्डिंग होती, तो ऑर्डरिंग एक्सप्रेशन ऑर्डरिड + 1 - 10248 को ऑर्डरिड - 10247 में फोल्ड किया जाता। इस एक्सप्रेशन को ऑर्डरिड के संबंध में ऑर्डर-प्रिजर्विंग एक्सप्रेशन माना जाता, और इस तरह से सक्षम होता इंडेक्स ऑर्डर पर भरोसा करने के लिए ऑप्टिमाइज़र। काश, ऐसा नहीं होता, जैसा कि योजना में स्पष्ट सॉर्ट ऑपरेटर द्वारा स्पष्ट किया गया है। तो क्या हुआ?
लगातार तह नियम बारीक हैं। निरंतर तह उद्देश्यों के लिए अभिव्यक्ति कॉलम 1 + स्थिरांक 1 - स्थिरांक 2 का मूल्यांकन बाएं से दाएं किया जाता है। पहला भाग, कॉलम 1 + स्थिरांक 1 मुड़ा नहीं है। आइए इस अभिव्यक्ति को 1 कहते हैं। अगले भाग का मूल्यांकन किया जाता है जिसे अभिव्यक्ति 1 - स्थिर 2 के रूप में माना जाता है, जिसे या तो फोल्ड नहीं किया जाता है। फोल्डिंग के बिना, कॉलम 1 + स्थिरांक 1 - स्थिर 2 के रूप में एक अभिव्यक्ति को कॉलम 1 के संबंध में ऑर्डर संरक्षित नहीं माना जाता है, और इसलिए इंडेक्स ऑर्डरिंग पर भरोसा नहीं किया जा सकता है, भले ही आपके पास कॉलम 1 पर सहायक इंडेक्स हो। इसी तरह, अभिव्यक्ति निरंतर 1 + कॉलम 1 - स्थिरांक 2 स्थिर नहीं है। हालाँकि, व्यंजक स्थिरांक1 - स्थिरांक2 + स्तंभ1 मुड़ने योग्य है। अधिक विशेष रूप से, पहले भाग स्थिरांक1 - स्थिरांक2 को एक स्थिरांक में मोड़ा जाता है (इसे स्थिरांक 3 कहते हैं), जिसके परिणामस्वरूप व्यंजक स्थिरांक3 + स्तंभ1 प्राप्त होता है। कॉलम 1 के संबंध में इस अभिव्यक्ति को ऑर्डर-संरक्षित अभिव्यक्ति माना जाता है। इसलिए जब तक आप अंतिम फॉर्म का उपयोग करके अपनी अभिव्यक्ति लिखना सुनिश्चित करते हैं, तब तक आप ऑप्टिमाइज़र को इंडेक्स ऑर्डरिंग पर भरोसा करने में सक्षम कर सकते हैं।
निम्नलिखित प्रश्नों पर विचार करें (मैं उन्हें प्रश्न 2, प्रश्न 3 और प्रश्न 4 के रूप में संदर्भित करूंगा), और क्वेरी योजनाओं को देखने से पहले, देखें कि क्या आप बता सकते हैं कि योजना में स्पष्ट छँटाई शामिल होगी और कौन नहीं:
-- Query 2 SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 3 SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 4 SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid;
अब इन प्रश्नों के लिए योजनाओं की जाँच करें जैसा कि चित्र 2 में दिखाया गया है।
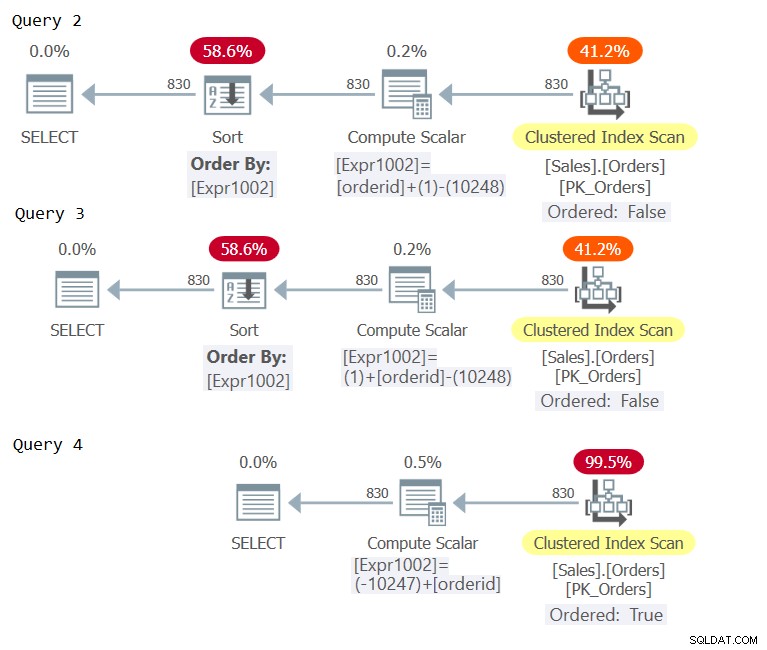 चित्र 2:क्वेरी 2, क्वेरी 3 और क्वेरी 4 के लिए योजनाएं
चित्र 2:क्वेरी 2, क्वेरी 3 और क्वेरी 4 के लिए योजनाएं
तीन योजनाओं में कंप्यूट स्केलर ऑपरेटरों की जांच करें। केवल क्वेरी 4 के लिए योजना में लगातार फोल्डिंग होती है, जिसके परिणामस्वरूप एक ऑर्डरिंग अभिव्यक्ति होती है जिसे ऑर्डर-संरक्षण के संबंध में ऑर्डर-संरक्षण माना जाता है, स्पष्ट सॉर्टिंग से परहेज करता है।
निरंतर तह के इस पहलू को समझते हुए, आप अभिव्यक्ति क्रम + @add – @subtract to @add – @subtract + orderid, जैसे:
को बदलकर आसानी से iTVF को ठीक कर सकते हैं:CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO फ़ंक्शन को फिर से क्वेरी करें (मैं इसे क्वेरी 5 के रूप में संदर्भित करूंगा):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
इस क्वेरी की योजना चित्र 3 में दिखाई गई है।
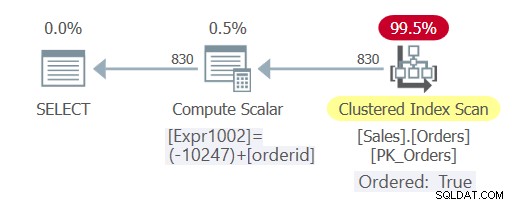 चित्र 3:प्रश्न 5 के लिए योजना
चित्र 3:प्रश्न 5 के लिए योजना
जैसा कि आप देख सकते हैं, इस बार क्वेरी ने लगातार फोल्डिंग का अनुभव किया और ऑप्टिमाइज़र स्पष्ट सॉर्टिंग से बचते हुए इंडेक्स ऑर्डरिंग पर भरोसा करने में सक्षम था।
मैंने इस अनुकूलन तकनीक को प्रदर्शित करने के लिए एक सरल उदाहरण का उपयोग किया है, और इस तरह यह थोड़ा सा प्रतीत हो सकता है। आप इस तकनीक का एक व्यावहारिक अनुप्रयोग लेख संख्या श्रृंखला जनरेटर चुनौती समाधान - भाग 1 में पा सकते हैं।
डायनामिक फ़िल्टरिंग/ऑर्डर करना
पिछले महीने मैंने एक संग्रहीत प्रक्रिया में एक ही क्वेरी बनाम एक आईटीवीएफ में एक क्वेरी को एसक्यूएल सर्वर अनुकूलित करने के तरीके के बीच अंतर को कवर किया। SQL सर्वर आमतौर पर इनपुट के रूप में स्थिरांक वाले iTVF को शामिल करने वाली क्वेरी के लिए डिफ़ॉल्ट रूप से पैरामीटर-एम्बेडिंग ऑप्टिमाइज़ेशन लागू करेगा, लेकिन संग्रहीत प्रक्रिया में क्वेरी के पैरामीटरयुक्त रूप को अनुकूलित करेगा। हालाँकि, यदि आप संग्रहीत कार्यविधि में क्वेरी में OPTION(RECOMPILE) जोड़ते हैं, तो SQL सर्वर आमतौर पर इस मामले में भी पैरामीटर-एम्बेडिंग ऑप्टिमाइज़ेशन लागू करेगा। आईटीवीएफ मामले में लाभों में यह तथ्य शामिल है कि आप इसे एक प्रश्न में शामिल कर सकते हैं, और जब तक आप लगातार इनपुट दोहराते हैं, तब तक पहले से कैश की गई योजना का पुन:उपयोग करने की संभावना है। एक संग्रहीत कार्यविधि के साथ, आप इसे किसी क्वेरी में शामिल नहीं कर सकते हैं, और यदि आप पैरामीटर-एम्बेडिंग ऑप्टिमाइज़ेशन प्राप्त करने के लिए OPTION(RECOMPILE) जोड़ते हैं, तो कोई योजना पुन:उपयोग की संभावना नहीं है। संग्रहीत कार्यविधि आपके द्वारा उपयोग किए जा सकने वाले कोड तत्वों के संदर्भ में बहुत अधिक लचीलेपन की अनुमति देती है।
आइए देखें कि क्लासिक पैरामीटर एम्बेडिंग और ऑर्डरिंग कार्य में यह सब कैसे चलता है। निम्नलिखित एक सरलीकृत संग्रहीत कार्यविधि है जो अपने लेख में उपयोग किए गए पॉल के समान गतिशील फ़िल्टरिंग और छँटाई लागू करती है:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END; GO
ध्यान दें कि संग्रहीत कार्यविधि के वर्तमान कार्यान्वयन में क्वेरी में OPTION(RECOMPILE) शामिल नहीं है।
संग्रहीत कार्यविधि के निम्नलिखित निष्पादन पर विचार करें:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
इस निष्पादन की योजना चित्र 4 में दिखाई गई है।
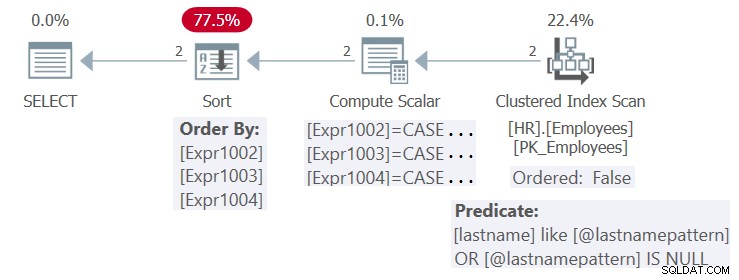 चित्र 4:प्रक्रिया के लिए योजना HR.GetEmpsP
चित्र 4:प्रक्रिया के लिए योजना HR.GetEmpsP
अंतिम नाम कॉलम पर एक इंडेक्स परिभाषित किया गया है। सैद्धांतिक रूप से, वर्तमान इनपुट के साथ, अनुक्रमणिका फ़िल्टरिंग (एक तलाश के साथ) और ऑर्डरिंग (एक ऑर्डर किए गए:ट्रू रेंज स्कैन के साथ) क्वेरी की ज़रूरतों दोनों के लिए फायदेमंद हो सकती है। हालाँकि, डिफ़ॉल्ट रूप से SQL सर्वर क्वेरी के पैरामीटरयुक्त रूप को अनुकूलित करता है और पैरामीटर-एम्बेडिंग लागू नहीं करता है, यह फ़िल्टरिंग और ऑर्डरिंग उद्देश्यों दोनों के लिए इंडेक्स से लाभ उठाने में सक्षम होने के लिए आवश्यक सरलीकरण लागू नहीं करता है। इसलिए, योजना पुन:प्रयोज्य है, लेकिन यह इष्टतम नहीं है।
यह देखने के लिए कि पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन के साथ चीजें कैसे बदलती हैं, संग्रहीत कार्यविधि क्वेरी को OPTION(RECOMPILE) जोड़कर बदल दें, जैसे:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END OPTION(RECOMPILE); GO
संग्रहीत कार्यविधि को उसी इनपुट के साथ फिर से निष्पादित करें जिसका आपने पहले उपयोग किया था:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
इस निष्पादन की योजना चित्र 5 में दिखाई गई है।
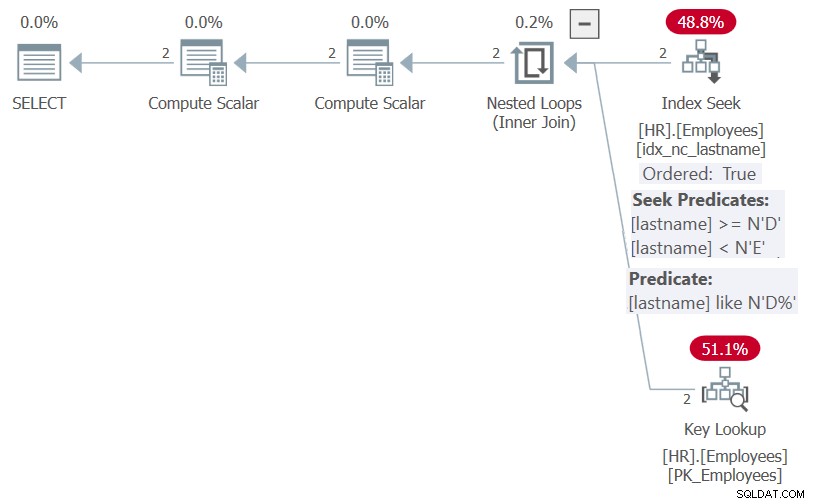 चित्र 5:प्रक्रिया के लिए योजना HR.GetEmpsP with OPTION(RECOMPILE)
चित्र 5:प्रक्रिया के लिए योजना HR.GetEmpsP with OPTION(RECOMPILE)
जैसा कि आप देख सकते हैं, पैरामीटर-एम्बेडिंग ऑप्टिमाइज़ेशन के लिए धन्यवाद, SQL सर्वर सर्गेबल विधेय अंतिम नाम LIKE N'D% ', और NULL, NULL, अंतिम नाम के लिए ऑर्डरिंग सूची को फ़िल्टर करने में सक्षम था। दोनों तत्व अंतिम नाम पर सूचकांक से लाभान्वित हो सकते हैं, और इसलिए योजना सूचकांक में खोज दिखाती है और कोई स्पष्ट छँटाई नहीं करती है।
सैद्धांतिक रूप से, आप समान सरलीकरण प्राप्त करने में सक्षम होने की उम्मीद करते हैं यदि आप एक iTVF में क्वेरी को लागू करते हैं, और इसलिए समान अनुकूलन लाभ, लेकिन समान इनपुट मानों का पुन:उपयोग होने पर कैश्ड योजनाओं का पुन:उपयोग करने की क्षमता के साथ। तो चलिए कोशिश करते हैं…
यहां iTVF में उसी क्वेरी को लागू करने का प्रयास किया गया है (अभी तक इस कोड को न चलाएं):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GO इससे पहले कि आप इस कोड को निष्पादित करने का प्रयास करें, क्या आप इस कार्यान्वयन में कोई समस्या देख सकते हैं? याद रखें कि इस श्रृंखला की शुरुआत में मैंने समझाया था कि एक टेबल एक्सप्रेशन एक टेबल है। एक टेबल का शरीर पंक्तियों का एक सेट (या मल्टीसेट) होता है, और इस तरह इसका कोई क्रम नहीं होता है। इसलिए, सामान्य रूप से, तालिका अभिव्यक्ति के रूप में उपयोग की जाने वाली क्वेरी में ORDER BY खंड नहीं हो सकता है। वास्तव में, यदि आप इस कोड को चलाने का प्रयास करते हैं, तो आपको निम्न त्रुटि मिलती है:
Msg 1033, स्तर 15, राज्य 1, प्रक्रिया GetEmps, लाइन 16 [बैच स्टार्ट लाइन 128]ORDER BY क्लॉज विचारों, इनलाइन कार्यों, व्युत्पन्न तालिकाओं, उपश्रेणियों और सामान्य तालिका अभिव्यक्तियों में अमान्य है, जब तक कि TOP, OFFSET या एक्सएमएल के लिए भी निर्दिष्ट है।
निश्चित रूप से, जैसे त्रुटि कहती है, SQL सर्वर एक अपवाद बना देगा यदि आप फ़िल्टरिंग तत्व जैसे TOP या OFFSET-FETCH का उपयोग करते हैं, जो फ़िल्टर के ऑर्डरिंग पहलू को परिभाषित करने के लिए ORDER BY क्लॉज पर निर्भर करता है। लेकिन भले ही आप इस अपवाद के लिए आंतरिक क्वेरी में ORDER BY क्लॉज शामिल करते हैं, फिर भी आपको टेबल एक्सप्रेशन के खिलाफ बाहरी क्वेरी में परिणाम के क्रम की गारंटी नहीं मिलती है, जब तक कि इसका अपना ऑर्डर बाय क्लॉज न हो। ।
यदि आप अभी भी एक iTVF में क्वेरी को लागू करना चाहते हैं, तो आप आंतरिक क्वेरी को डायनामिक फ़िल्टरिंग भाग को संभाल सकते हैं, लेकिन डायनेमिक ऑर्डरिंग नहीं, जैसे:
CREATE OR ALTER FUNCTION HR.GetEmpsF ( @lastnamepattern AS NVARCHAR(50) ) RETURNS TABLE AS RETURN SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL; GO
बेशक, आप बाहरी क्वेरी को किसी विशिष्ट ऑर्डरिंग आवश्यकता को संभाल सकते हैं, जैसे निम्न कोड में (मैं इसे क्वेरी 6 के रूप में संदर्भित करूंगा):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY lastname;
इस क्वेरी की योजना चित्र 6 में दिखाई गई है।
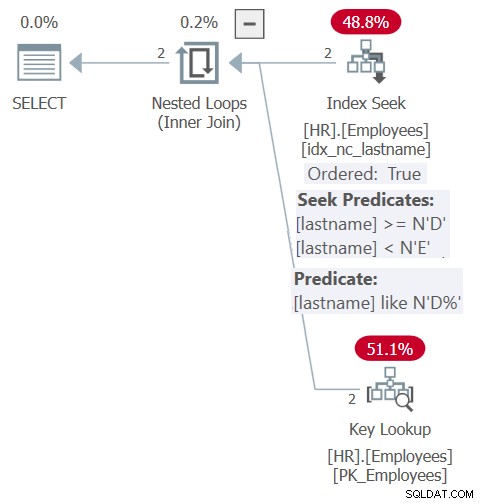 चित्र 6:प्रश्न 6 के लिए योजना
चित्र 6:प्रश्न 6 के लिए योजना
इनलाइनिंग और पैरामीटर एम्बेडिंग के लिए धन्यवाद, योजना चित्र 5 में संग्रहीत कार्यविधि क्वेरी के लिए पहले दिखाए गए के समान है। योजना कुशलतापूर्वक फ़िल्टरिंग और ऑर्डरिंग उद्देश्यों दोनों के लिए सूचकांक पर निर्भर करती है। हालाँकि, आपको डायनामिक ऑर्डरिंग इनपुट का लचीलापन नहीं मिलता है, जैसा कि आपके पास संग्रहीत कार्यविधि के साथ था। आपको फ़ंक्शन के विरुद्ध क्वेरी में ORDER BY क्लॉज में ऑर्डरिंग के बारे में स्पष्ट होना चाहिए।
निम्न उदाहरण में फ़ंक्शन के विरुद्ध कोई फ़िल्टरिंग और कोई ऑर्डरिंग आवश्यकता नहीं है (मैं इसे क्वेरी 7 के रूप में संदर्भित करूंगा):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(NULL);
इस क्वेरी की योजना चित्र 7 में दिखाई गई है।
 चित्र 7:प्रश्न 7 की योजना
चित्र 7:प्रश्न 7 की योजना
इनलाइनिंग और पैरामीटर एम्बेडिंग के बाद, क्वेरी को सरल बनाया जाता है ताकि कोई फ़िल्टर विधेय न हो और कोई ऑर्डर न हो, और क्लस्टर इंडेक्स के पूर्ण अनियंत्रित स्कैन के साथ अनुकूलित हो जाता है।
अंत में, इनपुट अंतिम नाम फ़िल्टरिंग पैटर्न के रूप में एन'डी%' के साथ फ़ंक्शन को क्वेरी करें और परिणाम को प्रथम नाम कॉलम द्वारा ऑर्डर करें (मैं इसे क्वेरी 8 के रूप में संदर्भित करूंगा):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY firstname;
इस क्वेरी की योजना चित्र 8 में दिखाई गई है।
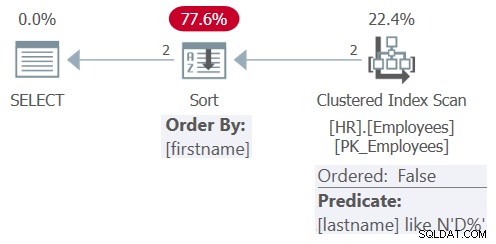 चित्र 8:क्वेरी 8 के लिए योजना
चित्र 8:क्वेरी 8 के लिए योजना
सरलीकरण के बाद, क्वेरी में केवल फ़िल्टरिंग विधेय अंतिम नाम LIKE N'D%' और आदेश देने वाला तत्व प्रथम नाम शामिल है। इस बार ऑप्टिमाइज़र क्लस्टर इंडेक्स के एक अनियंत्रित स्कैन को लागू करने का विकल्प चुनता है, जिसमें अवशिष्ट विधेय अंतिम नाम LIKE N'D%' होता है, इसके बाद स्पष्ट छँटाई होती है। इसने अंतिम नाम पर अनुक्रमणिका में खोज लागू नहीं करना चुना क्योंकि अनुक्रमणिका एक आवरण नहीं है, तालिका इतनी छोटी है, और अनुक्रमणिका क्रम वर्तमान क्वेरी आदेश आवश्यकताओं के लिए फायदेमंद नहीं है। साथ ही, प्रथम नाम कॉलम पर कोई अनुक्रमणिका परिभाषित नहीं है, इसलिए एक स्पष्ट प्रकार को वैसे भी लागू किया जाना चाहिए।
निष्कर्ष
iTVFs के डिफ़ॉल्ट पैरामीटर-एम्बेडिंग ऑप्टिमाइज़ेशन के परिणामस्वरूप निरंतर फोल्डिंग हो सकती है, जिससे अधिक इष्टतम योजनाएं सक्षम हो सकती हैं। हालांकि, आपको अपने भावों को सर्वोत्तम रूप से तैयार करने का तरीका निर्धारित करने के लिए निरंतर तह नियमों के प्रति सचेत रहने की आवश्यकता है।
एक संग्रहीत प्रक्रिया में तर्क को लागू करने की तुलना में iTVF में तर्क को लागू करने के फायदे और नुकसान हैं। यदि आप पैरामीटर-एम्बेडिंग ऑप्टिमाइज़ेशन में रुचि नहीं रखते हैं, तो संग्रहीत प्रक्रियाओं के डिफ़ॉल्ट पैरामीटरयुक्त क्वेरी ऑप्टिमाइज़ेशन के परिणामस्वरूप अधिक इष्टतम योजना कैशिंग और पुन:उपयोग व्यवहार हो सकता है। ऐसे मामलों में जहां आप पैरामीटर-एम्बेडिंग ऑप्टिमाइज़ेशन में रुचि रखते हैं, आप आमतौर पर इसे डिफ़ॉल्ट रूप से iTVFs के साथ प्राप्त करते हैं। संग्रहीत प्रक्रियाओं के साथ इस अनुकूलन को प्राप्त करने के लिए, आपको RECOMPILE क्वेरी विकल्प जोड़ने की आवश्यकता है, लेकिन तब आपको योजना का पुन:उपयोग नहीं मिलेगा। कम से कम iTVFs के साथ, आप योजना का पुन:उपयोग प्राप्त कर सकते हैं बशर्ते समान पैरामीटर मान दोहराए जाएं। फिर से, आपके पास आईटीवीएफ में उपयोग किए जा सकने वाले क्वेरी तत्वों के साथ कम लचीलापन है; उदाहरण के लिए, आपको खंड के अनुसार ORDER प्रस्तुत करने की अनुमति नहीं है।
तालिका अभिव्यक्तियों पर पूरी श्रृंखला पर वापस, मुझे लगता है कि विषय डेटाबेस प्रैक्टिशनर्स के लिए अति महत्वपूर्ण है। अधिक पूर्ण श्रृंखला में संख्या श्रृंखला जनरेटर पर उप-श्रृंखला शामिल है, जिसे आईटीवीएफ के रूप में कार्यान्वित किया जाता है। कुल मिलाकर श्रृंखला में निम्नलिखित 19 भाग शामिल हैं:
- तालिका भाव के मूल तत्व, भाग 1
- टेबल एक्सप्रेशन के मूल तत्व, भाग 2 - व्युत्पन्न टेबल, तार्किक विचार
- टेबल एक्सप्रेशन के मूल तत्व, भाग 3 - व्युत्पन्न टेबल, अनुकूलन विचार
- टेबल एक्सप्रेशन के मूल तत्व, भाग 4 - व्युत्पन्न टेबल, अनुकूलन विचार, जारी रखा
- तालिका अभिव्यक्तियों के मूल तत्व, भाग 5 - सीटीई, तार्किक विचार
- टेबल एक्सप्रेशन के मूल तत्व, भाग 6 - रिकर्सिव सीटीई
- तालिका अभिव्यक्तियों के मूल तत्व, भाग 7 - CTE, अनुकूलन विचार
- तालिका अभिव्यक्तियों के मूल तत्व, भाग 8 - CTE, अनुकूलन विचार जारी रहे
- तालिका अभिव्यक्तियों के मूल तत्व, भाग 9 - व्युत्पन्न तालिकाओं और सीटीई की तुलना में दृश्य
- टेबल एक्सप्रेशन के मूल तत्व, भाग 10 - दृश्य, चुनें *, और डीडीएल परिवर्तन
- तालिका अभिव्यक्तियों के मूल तत्व, भाग 11 - विचार, संशोधन संबंधी विचार
- तालिका अभिव्यक्तियों के मूल तत्व, भाग 12 - इनलाइन तालिका-मूल्यवान कार्य
- तालिका अभिव्यक्तियों के मूल तत्व, भाग 13 - इनलाइन तालिका-मूल्यवान कार्य, जारी रखा
- चुनौती जारी है! सबसे तेज संख्या श्रृंखला जनरेटर बनाने के लिए सामुदायिक कॉल
- संख्या श्रृंखला जनरेटर चुनौती समाधान - भाग 1
- संख्या श्रृंखला जनरेटर चुनौती समाधान - भाग 2
- संख्या श्रृंखला जनरेटर चुनौती समाधान - भाग 3
- संख्या श्रृंखला जनरेटर चुनौती समाधान - भाग 4
- नंबर श्रृंखला जनरेटर चुनौती समाधान - भाग 5