Azure SQL डेटाबेस की शुरुआत और v12 में अधिक कार्यक्षमता के जुड़ने के साथ, डेटाबेस व्यवस्थापक अपने संगठनों को डेटाबेस को इस प्लेटफ़ॉर्म पर ले जाने में अधिक रुचि दिखाना शुरू कर रहे हैं।
मैंने हाल ही में Azure SQL डेटाबेस में और अधिक गोता लगाना शुरू किया है, यह देखने के लिए कि दुनिया भर के डेटासेंटर और Azure SQL डेटाबेस में बॉक्स संस्करण का समर्थन करने से क्या अलग है। अपने पिछले लेख में, "ट्यूनिंग:ए गुड प्लेस टू स्टार्ट," मैंने SQL सर्वर ट्यूनिंग के साथ आरंभ करने के लिए अपने दृष्टिकोण को कवर किया। मैंने प्रमुख अंतरों को खोजने के लिए Azure SQL डेटाबेस के विरुद्ध इसकी समीक्षा करने का निर्णय लिया।
अपने मूल लेख में, मैंने सामान्य इंस्टेंस-स्तरीय सेटिंग्स के साथ शुरुआत की, जिन्हें मैं अनदेखा या डिफ़ॉल्ट के रूप में छोड़ देता हूं, साथ ही साथ रखरखाव आइटम भी देखता हूं। इनमें मेमोरी, मैक्सडॉप, समांतरता के लिए लागत सीमा, तदर्थ कार्यभार के लिए अनुकूलन को सक्षम करना और tempdb को कॉन्फ़िगर करना शामिल है। Azure SQL डेटाबेस के साथ, आप उदाहरण के लिए ज़िम्मेदार नहीं हैं, और उन सेटिंग्स को संशोधित नहीं कर सकते हैं। Azure SQL डेटाबेस एक सेवा (Paa) के रूप में एक प्लेटफ़ॉर्म है, जिसका अर्थ है कि Microsoft आपके लिए इंस्टेंस का प्रबंधन करता है; आप बस अपने डेटाबेस या डेटाबेस के साथ एक किरायेदार हैं।
हालांकि, आप रखरखाव के लिए जिम्मेदार हैं, इसलिए आपको आंकड़ों को अपडेट करना होगा और इंडेक्स विखंडन को संभालना होगा जैसे आप बॉक्स उत्पाद के लिए करते हैं। उन कार्यों के लिए, मैंने पाया है कि अधिकांश क्लाइंट उन प्रक्रियाओं का प्रबंधन एक समर्पित Azure VM के साथ SQL सर्वर चलाने वाले और अनुसूचित नौकरियों के साथ SQL सर्वर एजेंट का उपयोग करके करते हैं।
मेरे लेख के चरणों का पालन करते हुए, मैं जिन अगले क्षेत्रों पर गौर करना शुरू करता हूं, वे हैं फ़ाइल और प्रतीक्षा आँकड़े और उच्च-लागत वाली क्वेरी। यदि आप सोच रहे हैं कि Azure SQL डेटाबेस के साथ काम करते समय ऑन-प्रिमाइसेस डेटाबेस के साथ प्रोडक्शन dba के रूप में आपकी नौकरी का यह पहलू बदल जाएगा, तो इसका उत्तर है वास्तव में नहीं . फ़ाइल और प्रतीक्षा आँकड़े अभी भी हैं, लेकिन हमें उन्हें थोड़ा अलग तरीके से प्राप्त करना होगा। यदि आप फ़ाइल आँकड़ों और प्रतीक्षा आँकड़ों के लिए पॉल रान्डल की स्क्रिप्ट का उपयोग करने के आदी हैं (या समय की अवधि के लिए फ़ाइल आँकड़ों के लिए प्रश्न और समय की अवधि के लिए प्रतीक्षा आँकड़े), तो आपको क्रम में कुछ बदलाव करने होंगे Azure SQL डेटाबेस के साथ काम करने के लिए वे स्क्रिप्ट।
जब मैंने पहली बार पॉल की फ़ाइल आँकड़े स्क्रिप्ट की कोशिश की, तो Azure SQL डेटाबेस sys.master_files का समर्थन नहीं करने के कारण यह विफल हो गया। :
अवैध वस्तु नाम 'sys.master_files'।
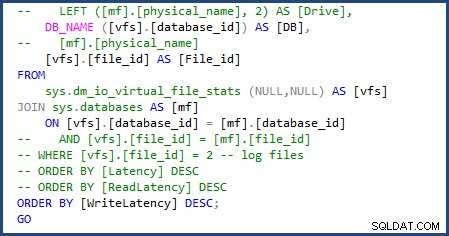
मैं sys.databases . का उपयोग करने के लिए स्क्रिप्ट को संशोधित करने में सक्षम था डेटाबेस नाम प्राप्त करने के लिए शामिल हों और व्यक्तिगत फ़ाइल नाम प्राप्त करने के लिए स्क्रिप्ट के हिस्से को हटा दें क्योंकि हम केवल एक डेटा और लॉग फ़ाइल से निपटेंगे। आप निम्न छवि में मेरे द्वारा किए गए परिवर्तनों को देख सकते हैं:
जब मैंने फ़ाइल-आंकड़े-ओवर-ए-पीरियड-ऑफ-टाइम स्क्रिप्ट को चलाया, तो sys.databases में वही परिवर्तन किया। और file_id . के संदर्भों को हटाना शामिल होने में, Azure SQL डेटाबेस v12 वैश्विक ##temp तालिकाओं का समर्थन नहीं करने के कारण विफल हो गया।
एक बार जब मैंने सभी वैश्विक ## अस्थायी तालिकाओं को स्थानीय में बदल दिया, तो मेरे पास स्क्रिप्ट के साथ एक और समस्या थी जो मौजूदा अस्थायी तालिकाओं को छोड़ने में असमर्थ थी, क्योंकि स्थानीय #temp तालिकाओं को सीधे नाम से संदर्भित नहीं किया जा सकता है जिस तरह से वैश्विक ## अस्थायी तालिकाएँ कर सकती हैं, लेकिन ऐसे चेकों को OBJECT_ID('tempdb..#SQLskillsStats1') में बदलकर इस पर काबू पाना आसान था। . मैंने दूसरी अस्थायी तालिका के लिए एक ही परिवर्तन किया, और स्क्रिप्ट की शुरुआत और अंत में कोड के ब्लॉक को अपडेट किया।
मुझे एक और बदलाव करना पड़ा और [mf].[type_desc] . को हटाना पड़ा और LEFT ([mf].[physical_name], 2) AS [Drive] चूंकि वे sys.master_files . पर निर्भर हैं . तब स्क्रिप्ट पूरी हो गई थी और Azure SQL डेटाबेस के साथ उपयोग करने के लिए तैयार थी।
प्रदर्शन समस्याओं का निवारण करते समय मैं नियमित रूप से फ़ाइल-आँकड़ों-समय-समय पर उपयोग करता हूं। संचयी डेटा का अपना उद्देश्य होता है, लेकिन मुझे उस समय के विशिष्ट खंडों में अधिक दिलचस्पी है जब उपयोगकर्ता कार्यभार चलाया जा रहा हो।
फ़ाइल आँकड़ों के साथ, हम प्रति डेटाबेस फ़ाइल में हमारी विलंबता और समग्र I/O को कम करने में मदद करने के लिए हम कैसे ट्यून कर सकते हैं, इसके बारे में चिंतित हैं। दृष्टिकोण SQL सर्वर के समान है, जहां आपको अपने प्रश्नों को ठीक से ट्यून करने और सही अनुक्रमणिका रखने की आवश्यकता होती है। यदि कार्यभार बहुत बड़ा है, तो आपको तेजी से प्रदर्शन करने वाले DTU डेटाबेस स्तर पर जाना होगा। मेरे लिए, यह बहुत अच्छा है:आप बस उस पर हार्डवेयर फेंक दें; लेकिन यह वास्तव में पारंपरिक अर्थों में हार्डवेयर नहीं है। Azure SQL डेटाबेस के साथ, जैसे-जैसे आपका व्यवसाय और I/O माँगें बढ़ती हैं, आपको कम खर्चीले स्तर और पैमाने के साथ शुरुआत करनी पड़ती है - अनिवार्य रूप से केवल एक स्विच को फ़्लिप करके।
प्रतीक्षा आँकड़े प्राप्त करने के लिए सर्वोत्तम विधि खोजने का प्रयास करना आसान था। हम में से कई लोग जिस मानक स्क्रिप्ट का उपयोग करते हैं, वह अभी भी काम करती है, हालाँकि यह उस कंटेनर के लिए प्रतीक्षा आँकड़े खींच रही है जिसमें आपका डेटाबेस चल रहा है। वे प्रतीक्षा अभी भी आपके सिस्टम पर लागू होती हैं, लेकिन इसमें उसी कंटेनर में अन्य डेटाबेस द्वारा किए गए प्रतीक्षा शामिल हो सकते हैं। Azure SQL डेटाबेस में एक नया DMV शामिल है, sys.dm_db_wait_stats , जो वर्तमान डेटाबेस को फ़िल्टर करता है। यदि आप मेरे जैसे हैं और मुख्य रूप से पॉल की प्रतीक्षा आँकड़े स्क्रिप्ट का उपयोग करते हैं जो सभी सौम्य प्रतीक्षा को छोड़ देती है, तो बस sys.dm_os_wait_stats बदलें करने के लिए sys.dm_db_wait_stats . वही परिवर्तन समय-समय पर प्रतीक्षा-अवधि-स्क्रिप्ट के लिए भी काम करता है, लेकिन आपको वैश्विक चर से स्थानीय में भी परिवर्तन करना होगा।
जब उच्च लागत वाले प्रश्नों को खोजने की बात आती है, तो चलाने के लिए मेरी पसंदीदा स्क्रिप्ट में से एक सबसे अधिक उपयोग की जाने वाली निष्पादन योजनाएं ढूंढती है। मेरे अनुभव में, एक क्वेरी को ट्यून करना जिसे प्रति दिन 100,000 बार कहा जाता है, आमतौर पर उस क्वेरी को ट्यून करने की तुलना में एक बड़ी जीत होती है जिसमें उच्चतम आईओ होता है लेकिन प्रति सप्ताह केवल एक बार चलाया जाता है। सबसे अधिक उपयोग की जाने वाली योजनाओं को खोजने के लिए मैं निम्नलिखित क्वेरी का उपयोग करता हूं:
उपयोग गणनाएं, कैशोबजटाइप, ओब्जेटाइप, [पाठ] sys.dm_exec_cached_plans से क्रॉस लागू करें sys.dm_exec_sql_text(plan_handle) का चयन करें जहां गणनाओं का उपयोग करें> 1 और objtype IN ( N'Adhoc', N'Prepared usecounts) आदेश द्वारा पूर्व>डेमो में इस क्वेरी का उपयोग करते समय, मैं मूल्यों को रीसेट करने के लिए हमेशा अपना प्लान कैश फ्लश करता हूं। जब मैंने
DBCC FREEPROCCACHEचलाने की कोशिश की Azure SQL डेटाबेस में, मुझे निम्न त्रुटि दी गई थी:यह पता चला है कि
SQL Azure वर्तमान में DBCC FREEPROCCACHE (Transact-SQL) का समर्थन नहीं करता है, इसलिए आप कैश से निष्पादन योजना को मैन्युअल रूप से नहीं हटा सकते। हालाँकि, यदि आप क्वेरी द्वारा संदर्भित तालिका या दृश्य में परिवर्तन करते हैं (तालिका बदलें और देखें) तो योजना कैश से हटा दी जाएगी।DBCC FREEPROCCACHEAzure SQL डेटाबेस में समर्थित नहीं है। यह मेरे लिए परेशान कर रहा था, क्या होगा यदि मैं उत्पादन में हूं और कुछ खराब योजनाएं हैं और मैं बॉक्स संस्करण के साथ प्रक्रिया कैश को साफ़ करना चाहता हूं। थोड़ा सा Google/Bing शोध मुझे Microsoft लेख "एसक्यूएल एज़्योर पर प्रक्रिया कैश को समझना" खोजने के लिए प्रेरित करता है, जिसमें कहा गया है:उस वर्णित व्यवहार को न देखने के बाद किम्बर्ली ट्रिप के साथ इस पर चर्चा करने में, यह कैश से योजना को फ्लश नहीं करता है, लेकिन यह योजना को अमान्य कर देता है (और फिर योजना अंततः कैश से बाहर हो जाएगी)। हालांकि यह कुछ स्थितियों में मददगार है, लेकिन मुझे इसकी आवश्यकता नहीं थी। अपने डेमो के लिए मैं sys.dm_exec_cached_plans में काउंटरों को रीसेट करना चाहता था। नई योजना बनाने से मुझे वांछित परिणाम नहीं मिलेंगे। मैं अपनी टीम के पास पहुंचा और ग्लेन बेरी ने मुझे निम्न स्क्रिप्ट आज़माने के लिए कहा:
ALTER DATABASE स्कोप्ड कॉन्फ़िगरेशन स्पष्ट PROCEDURE_CACHE;यह आदेश काम किया; मैं विशिष्ट डेटाबेस के लिए प्रक्रिया कैश को साफ़ करने में सक्षम था। डेटाबेस स्कोप्ड कॉन्फ़िगरेशन SQL सर्वर 2016 RC0 में जोड़ी गई एक नई सुविधा है; ग्लेन ने इसके बारे में यहां ब्लॉग किया:SQL सर्वर 2016 में ALTER DATABASE स्कोप्ड कॉन्फ़िगरेशन का उपयोग करना।
मैं अपने कई डेटाबेस को Azure SQL डेटाबेस में स्थानांतरित करने और नई सुविधाओं और मापनीयता विकल्पों के बारे में सीखना जारी रखने के लिए उत्साहित हूं। मैं सेंट्रीऑन डीबी सेंट्री के साथ काम करने के लिए भी उत्सुक हूं, जो हाल ही में सेंट्रीऑन प्लेटफॉर्म में जोड़ा गया है। मुझे DTU उपयोग डैशबोर्ड के साथ प्रयोग करने में सबसे अधिक दिलचस्पी है, जिसका वर्णन माइक वुड ने अपनी हालिया पोस्ट में किया है।