सबसे पहले SQL सर्वर 2017 एंटरप्राइज़ संस्करण में पेश किया गया, एक अनुकूली जुड़ाव बैच मोड से रनटाइम ट्रांज़िशन को सक्षम करता है, हैश जॉइन को रो मोड में सहसंबद्ध नेस्टेड लूप्स को रनटाइम पर इंडेक्स जॉइन (लागू) करता है। संक्षिप्तता के लिए, मैं एक "सहसंबद्ध नेस्टेड लूप्स इंडेक्सेड जॉइन" को एक लागू के रूप में संदर्भित करूंगा इस लेख के बाकी हिस्सों में। अगर आपको नेस्टेड लूप के बीच अंतर पर एक पुनश्चर्या की आवश्यकता है और आवेदन करें, तो कृपया मेरा पिछला लेख देखें।
रनटाइम पर लागू करने के लिए हैश जॉइन से एडेप्टिव जॉइन ट्रांज़िशन या नहीं यह एडेप्टिव थ्रेसहोल्ड रो लेबल वाले मान पर निर्भर करता है अडैप्टिव जॉइन . पर निष्पादन योजना ऑपरेटर। यह लेख दिखाता है कि एक अनुकूली जुड़ाव कैसे काम करता है, इसमें थ्रेशोल्ड गणना का विवरण शामिल है, और इसमें किए गए कुछ डिज़ाइन विकल्पों के निहितार्थ शामिल हैं।
परिचय
इस पूरी रचना में एक बात मैं आपको ध्यान में रखना चाहता हूं कि एक अनुकूली जुड़ाव है हमेशा बैच मोड हैश जॉइन के रूप में निष्पादित करना शुरू करता है। यह सच है, भले ही निष्पादन योजना इंगित करती है कि अनुकूली जुड़ाव एक पंक्ति मोड के रूप में चलने की अपेक्षा करता है।
किसी भी हैश जॉइन की तरह, एडेप्टिव जॉइन इसके बिल्ड इनपुट पर उपलब्ध सभी पंक्तियों को पढ़ता है और आवश्यक डेटा को हैश टेबल में कॉपी करता है। हैश जॉइन का बैच मोड फ्लेवर इन पंक्तियों को एक अनुकूलित प्रारूप में संग्रहीत करता है, और एक या अधिक हैश फ़ंक्शन का उपयोग करके उन्हें विभाजित करता है। एक बार बिल्ड इनपुट का उपभोग हो जाने के बाद, हैश तालिका पूरी तरह से भर जाती है और विभाजित हो जाती है, हैश जॉइन के लिए तैयार होती है ताकि मैचों के लिए जांच-साइड पंक्तियों की जांच शुरू हो सके।
यह वह बिंदु है जहां एक अनुकूली जुड़ाव बैच मोड हैश जॉइन के साथ आगे बढ़ने या एक पंक्ति मोड में संक्रमण लागू करने का निर्णय लेता है। यदि हैश तालिका में पंक्तियों की संख्या सीमा . से कम है मान, जॉइन स्विच को लागू करने के लिए; अन्यथा, जांच इनपुट से पंक्तियों को पढ़ना शुरू करके हैश जॉइन के रूप में जुड़ना जारी रहता है।
यदि लागू जॉइन में संक्रमण होता है, तो निष्पादन योजना लागू संचालन को चलाने के लिए हैश तालिका को पॉप्युलेट करने के लिए उपयोग की जाने वाली पंक्तियों को दोबारा नहीं पढ़ती है। इसके बजाय, एक आंतरिक घटक जिसे अनुकूली बफर रीडर . के रूप में जाना जाता है हैश तालिका में पहले से संग्रहीत पंक्तियों का विस्तार करता है और उन्हें लागू ऑपरेटर के बाहरी इनपुट पर ऑन-डिमांड उपलब्ध कराता है। अनुकूली बफर रीडर के साथ एक लागत जुड़ी हुई है, लेकिन यह बिल्ड इनपुट को पूरी तरह से रिवाइंड करने की लागत से काफी कम है।
अडैप्टिव जॉइन चुनना
क्वेरी अनुकूलन में तार्किक अन्वेषण और विकल्पों के भौतिक कार्यान्वयन के एक या अधिक चरण शामिल हैं। प्रत्येक चरण में, जब अनुकूलक एक तार्किक . के लिए भौतिक विकल्पों की खोज करता है शामिल हों, यह बैच मोड हैश जॉइन और रो मोड दोनों विकल्प लागू करने पर विचार कर सकता है।
यदि उन भौतिक जुड़ाव विकल्पों में से एक वर्तमान चरण के दौरान पाए जाने वाले सबसे सस्ते समाधान का हिस्सा है—और अन्य प्रकार के जुड़ाव समान आवश्यक तार्किक गुण प्रदान कर सकते हैं—अनुकूलक तार्किक जुड़ाव समूह को संभावित के रूप में चिह्नित करता है एक अनुकूली जुड़ाव के लिए उपयुक्त। यदि नहीं, तो एडेप्टिव जॉइन पर विचार यहीं समाप्त होता है (और कोई एडेप्टिव जॉइन विस्तारित ईवेंट सक्रिय नहीं होता है)।
ऑप्टिमाइज़र के सामान्य संचालन का मतलब है कि सबसे सस्ते समाधान में केवल एक भौतिक जुड़ाव विकल्प शामिल होगा-या तो हैश या लागू, जो भी सबसे कम अनुमानित लागत हो। अगली चीज़ जो ऑप्टिमाइज़र करता है वह है उस प्रकार के जुड़ाव का एक नया कार्यान्वयन बनाना और खर्च करना जो नहीं था सबसे सस्ता चुना गया।
चूंकि वर्तमान अनुकूलन चरण पहले ही सबसे सस्ते समाधान के साथ समाप्त हो चुका है, इसलिए अनुकूली जुड़ाव के लिए एक विशेष एकल-समूह अन्वेषण और कार्यान्वयन दौर किया जाता है। अंत में, ऑप्टिमाइज़र अनुकूली सीमा . की गणना करता है ।
यदि पिछला कोई भी कार्य असफल होता है, तो विस्तारित ईवेंट अनुकूली_जॉइन_स्किप्ड को एक कारण के साथ सक्रिय कर दिया जाता है।
अगर एडेप्टिव जॉइन प्रोसेसिंग सफल होती है, तो एक Concat ऑपरेटर को हैश के ऊपर आंतरिक योजना में जोड़ा जाता है और अनुकूली बफर रीडर और किसी भी आवश्यक बैच/पंक्ति मोड एडेप्टर के साथ विकल्प लागू करता है। याद रखें, एडेप्टिव थ्रेशोल्ड की तुलना में वास्तव में सामने आई पंक्तियों की संख्या के आधार पर शामिल होने के विकल्पों में से केवल एक ही रनटाइम पर निष्पादित होगा।
Concat ऑपरेटर और व्यक्तिगत हैश/लागू विकल्प आम तौर पर अंतिम निष्पादन योजना में नहीं दिखाए जाते हैं। इसके बजाय हमें एक ही अडैप्टिव जॉइन . के साथ प्रस्तुत किया जाता है ऑपरेटर। यह एक प्रस्तुतिकरण निर्णय है—Concat और जॉइन अभी भी SQL सर्वर निष्पादन इंजन द्वारा चलाए जा रहे कोड में मौजूद हैं। आप इसके बारे में अधिक विवरण इस लेख के परिशिष्ट और संबंधित पठन अनुभागों में प्राप्त कर सकते हैं।
अनुकूली सीमा
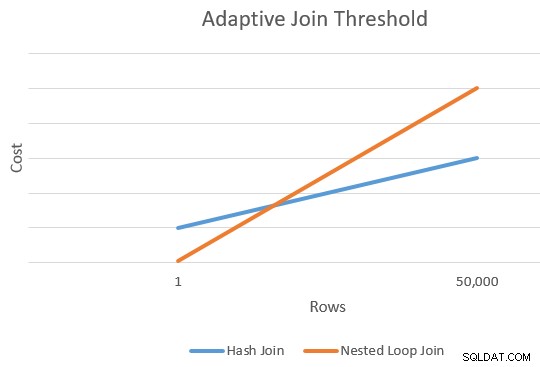
ड्राइविंग पंक्तियों की एक छोटी संख्या के लिए हैश जॉइन की तुलना में एक आवेदन आम तौर पर सस्ता होता है। हैश जॉइन की हैश तालिका बनाने के लिए एक अतिरिक्त स्टार्टअप लागत होती है लेकिन जब यह मैचों की जांच शुरू करता है तो प्रति-पंक्ति लागत कम होती है।
आम तौर पर एक बिंदु होता है जहां एक आवेदन और हैश जॉइन की अनुमानित लागत बराबर होगी। इस विचार को जो सैक ने अपने लेख, परिचय बैच मोड एडेप्टिव जॉइन में अच्छी तरह से चित्रित किया था:
सीमा की गणना करना
इस बिंदु पर, ऑप्टिमाइज़र के पास हैश जॉइन के बिल्ड इनपुट में प्रवेश करने वाली पंक्तियों की संख्या और विकल्पों को लागू करने के लिए एक ही अनुमान है। इसमें हैश की अनुमानित लागत भी है और संपूर्ण रूप से लागू ऑपरेटर हैं।
यह हमें ऊपर दिए गए आरेख में नारंगी और नीली रेखाओं के दाहिने किनारे पर एक एकल बिंदु देता है। ऑप्टिमाइज़र को प्रत्येक जुड़ने के प्रकार के लिए एक और संदर्भ बिंदु की आवश्यकता होती है ताकि यह "रेखाएँ खींच सके" और प्रतिच्छेदन ढूंढ सके (यह सचमुच रेखाएँ नहीं खींचता है, लेकिन आपको विचार मिलता है)।
लाइनों के लिए दूसरा बिंदु खोजने के लिए, ऑप्टिमाइज़र दो जुड़ने को एक अलग (और काल्पनिक) इनपुट कार्डिनैलिटी के आधार पर एक नया लागत अनुमान तैयार करने के लिए कहता है। यदि पहला कार्डिनैलिटी अनुमान 100 से अधिक पंक्तियों का था, तो यह जॉइन को एक पंक्ति के लिए नई लागतों का अनुमान लगाने के लिए कहता है। यदि मूल कार्डिनैलिटी 100 पंक्तियों से कम या उसके बराबर थी, तो दूसरा बिंदु 10,000 पंक्तियों की इनपुट कार्डिनैलिटी पर आधारित है (इसलिए एक्सट्रपलेट करने के लिए पर्याप्त रेंज है)।
किसी भी मामले में, परिणाम दो अलग-अलग लागत और प्रत्येक प्रकार के लिए पंक्ति गणना है, जिससे लाइनों को "खींचा" जा सकता है।
द इंटरसेक्शन फॉर्मूला
प्रत्येक पंक्ति के लिए दो बिंदुओं के आधार पर दो रेखाओं का प्रतिच्छेदन ज्ञात करना कई प्रसिद्ध समाधानों के साथ एक समस्या है। SQL सर्वर निर्धारकों . के आधार पर एक का उपयोग करता है जैसा कि विकिपीडिया पर बताया गया है:
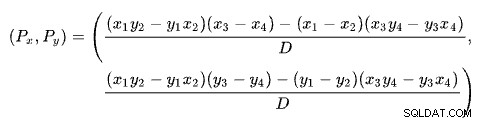
कहां:
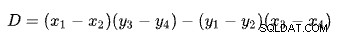
पहली पंक्ति को बिंदुओं द्वारा परिभाषित किया गया है (x1 , वाई<उप>1 ) और (x2 , वाई<उप>2 ) दूसरी पंक्ति बिंदुओं द्वारा दी गई है (x3 , वाई<उप>3 ) और (x4 , वाई<उप>4 ) चौराहा (Px .) पर है , प<उप>वाई )।
हमारी योजना में x-अक्ष पर पंक्तियों की संख्या और y-अक्ष पर अनुमानित लागत है। हम उन पंक्तियों की संख्या में रुचि रखते हैं जहाँ रेखाएँ प्रतिच्छेद करती हैं। यह Px . के सूत्र द्वारा दिया गया है . यदि हम चौराहे पर अनुमानित लागत जानना चाहते हैं, तो यह Py . होगा ।
Px . के लिए पंक्तियों में, लागू और हैश जॉइन समाधानों की अनुमानित लागत समान होगी। यह अनुकूली सीमा है जिसकी हमें आवश्यकता है।
एक सफल उदाहरण
बैच मोड निष्पादन पर बिना शर्त विचार प्राप्त करने के लिए एडवेंचरवर्क्स2017 नमूना डेटाबेस और इत्ज़िक बेन-गण द्वारा निम्नलिखित इंडेक्सिंग ट्रिक का उपयोग करते हुए एक उदाहरण यहां दिया गया है:
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123; निष्पादन योजना एक अनुकूली जुड़ाव . दिखाती है 1502.07 . की सीमा के साथ पंक्तियाँ:
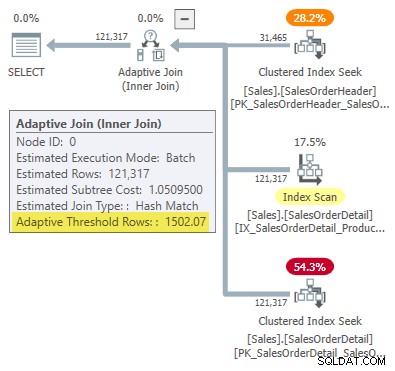
अनुकूली जुड़ने वाली पंक्तियों की अनुमानित संख्या 31,465 . है ।
लागत में शामिल हों
इस सरलीकृत मामले में, हम हैश के लिए अनुमानित सबट्री लागत ढूंढ सकते हैं और संकेतों का उपयोग करके शामिल होने के विकल्प लागू कर सकते हैं:
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1);

-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1);
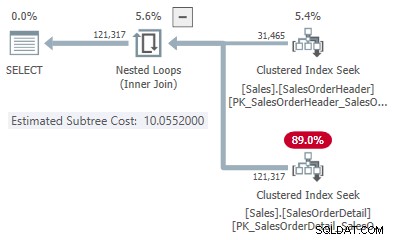
यह हमें प्रत्येक प्रकार के जुड़ने के लिए लाइन पर एक बिंदु देता है:
- 31,465 पंक्तियां
- हैश की कीमत 1.05083
- लागत 10.0552 लागू करें
रेखा पर दूसरा बिंदु
चूंकि पंक्तियों की अनुमानित संख्या 100 से अधिक है, इसलिए दूसरे संदर्भ बिंदु एक सम्मिलित इनपुट पंक्ति के आधार पर विशेष आंतरिक अनुमानों से आते हैं। दुर्भाग्य से, इस आंतरिक गणना के लिए सटीक लागत संख्या प्राप्त करने का कोई आसान तरीका नहीं है (मैं इसके बारे में जल्द ही और बात करूंगा)।
अभी के लिए, मैं आपको केवल लागत संख्या दिखाऊंगा (निष्पादन योजनाओं में प्रस्तुत छह महत्वपूर्ण आंकड़ों के बजाय पूर्ण आंतरिक सटीकता का उपयोग करके):
- एक पंक्ति (आंतरिक गणना)
- हैश की कीमत 0.999027422729
- लागत लागू करें 0.547927305023
- 31,465 पंक्तियां
- हैश की कीमत 1.05082787359
- लागत लागू करें 10.0552890166
जैसा कि अपेक्षित था, एक छोटे इनपुट कार्डिनैलिटी के लिए हैश की तुलना में आवेदन में शामिल होना सस्ता है, लेकिन 31,465 पंक्तियों की अपेक्षित कार्डिनैलिटी के लिए बहुत अधिक महंगा है।
चौराहे की गणना
इन कार्डिनैलिटी और लागत संख्याओं को लाइन इंटरसेक्शन फॉर्मूला में प्लग करने से आपको निम्नलिखित मिलता है:
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
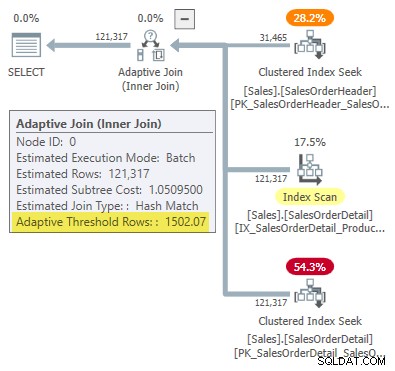
-- Returns 1502.06521571273 छह महत्वपूर्ण अंकों में पूर्णांकित, यह परिणाम 1502.07 . से मेल खाता है अनुकूली सम्मिलित निष्पादन योजना में दिखाई गई पंक्तियाँ:
दोष या डिज़ाइन?
याद रखें, SQL सर्वर को अनुकूली जॉइन थ्रेशोल्ड खोजने के लिए पंक्ति गणना बनाम लागत लाइनों को "आकर्षित" करने के लिए चार बिंदुओं की आवश्यकता होती है। वर्तमान मामले में, इसका अर्थ है एक-पंक्ति और 31,465-पंक्ति कार्डिनैलिटी के लिए लागू और हैश जॉइन कार्यान्वयन दोनों के लिए लागत अनुमान खोजना।
ऑप्टिमाइज़र sqllang!CuNewJoinEstimate . नाम के रूटीन को कॉल करता है अनुकूली जुड़ाव के लिए इन चार लागतों की गणना करने के लिए। अफसोस की बात है कि इस गतिविधि का एक आसान अवलोकन प्रदान करने के लिए कोई ट्रेस फ़्लैग या विस्तारित ईवेंट नहीं हैं। अनुकूलक व्यवहार और प्रदर्शन लागतों की जांच करने के लिए उपयोग किए जाने वाले सामान्य ट्रेस फ़्लैग यहां काम नहीं करते हैं (यदि आप अधिक विवरण में रुचि रखते हैं तो परिशिष्ट देखें)।
एक-पंक्ति लागत अनुमान प्राप्त करने का एकमात्र तरीका एक डीबगर संलग्न करना और चौथी कॉल के बाद एक ब्रेकपॉइंट सेट करना है CuNewJoinEstimate sqllang!CardSolveForSwitch . के कोड में . मैंने SQL Server 2019 CU12 पर इस कॉल स्टैक को प्राप्त करने के लिए WinDbg का उपयोग किया:

कोड में इस बिंदु पर, डबल-सटीक फ़्लोटिंग पॉइंट लागत चार मेमोरी स्थानों में संग्रहीत की जाती है, जिन्हें पतों द्वारा इंगित किया जाता है rsp+b0 , rsp+d0 , rsp+30 , और rsp+28 (जहां rsp एक सीपीयू रजिस्टर है और ऑफसेट हेक्साडेसिमल में हैं):

दिखाई गई ऑपरेटर सबट्री लागत संख्या अनुकूली जॉइन थ्रेशोल्ड गणना सूत्र में उपयोग की गई संख्याओं से मेल खाती है।
उन एक-पंक्ति लागत अनुमानों के बारे में
आपने देखा होगा कि एक पंक्ति में शामिल होने के लिए अनुमानित सबट्री लागत एक पंक्ति में शामिल होने में शामिल कार्य की मात्रा के लिए काफी अधिक लगती है:
- एक पंक्ति
- हैश की कीमत 0.999027422729
- लागत लागू करें 0.547927305023
यदि आप हैश जॉइन के लिए एक-पंक्ति इनपुट निष्पादन योजना तैयार करने और उदाहरण लागू करने का प्रयास करते हैं, तो आपको बहुत दिखाई देगा ऊपर दिखाए गए लोगों की तुलना में शामिल होने पर कम अनुमानित उपट्री लागत। इसी तरह, मूल क्वेरी को एक के पंक्ति लक्ष्य (या एक पंक्ति के इनपुट के लिए अपेक्षित आउटपुट पंक्तियों की संख्या) के साथ चलाने से भी अनुमानित लागत तरीका उत्पन्न होगी दिखाए गए से कम।
इसका कारण है CuNewJoinEstimate नियमित अनुमान एक-पंक्ति एक तरह से मुझे लगता है कि ज्यादातर लोगों को सहज ज्ञान युक्त नहीं लगेगा।
अंतिम लागत तीन मुख्य घटकों से बनी होती है:
- बिल्ड इनपुट सबट्री लागत
- शामिल होने की स्थानीय लागत
- जांच इनपुट सबट्री लागत
आइटम 2 और 3 शामिल होने के प्रकार पर निर्भर करते हैं। हैश जॉइन के लिए, वे जांच इनपुट से सभी पंक्तियों को पढ़ने की लागत के लिए खाते हैं, हैश तालिका में एक पंक्ति के साथ उनका मिलान (या नहीं) करते हैं, और परिणाम अगले ऑपरेटर को पास करते हैं। एक आवेदन के लिए, लागत में शामिल होने के लिए कम इनपुट, खुद में शामिल होने की आंतरिक लागत, और मिलान वाली पंक्तियों को मूल ऑपरेटर को वापस करना शामिल है।
इनमें से कुछ भी असामान्य या आश्चर्यजनक नहीं है।
लागत आश्चर्य
आश्चर्य निर्माण पक्ष . पर आता है शामिल होने का (सूची में आइटम 1)। कोई उम्मीद कर सकता है कि ऑप्टिमाइज़र 31,465 पंक्तियों के लिए पहले से गणना की गई सबट्री लागत को एक औसत पंक्ति, या ऐसा कुछ करने के लिए कुछ फैंसी गणना करेगा।
वास्तव में, हैश और लागू एक-पंक्ति में शामिल होने का अनुमान दोनों ही केवल मूल के लिए पूरी उपट्री लागत का उपयोग करते हैं 31,465 पंक्तियों का कार्डिनैलिटी अनुमान। हमारे चल रहे उदाहरण में, यह "सबट्री" है 0.54456 हेडर टेबल पर बैच मोड क्लस्टर्ड इंडेक्स की लागत:
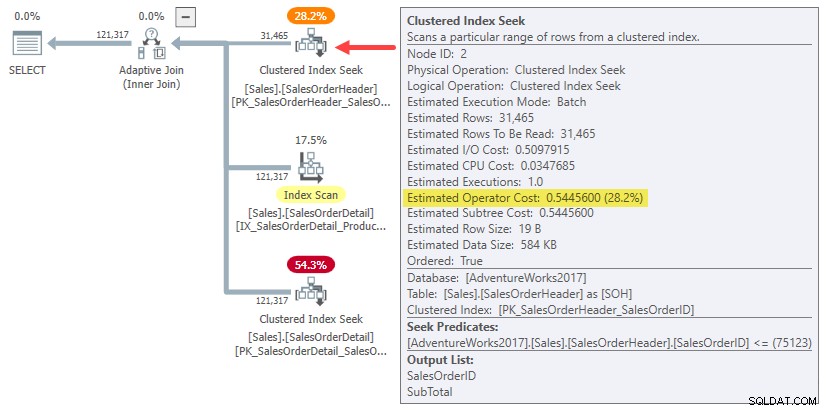
स्पष्ट होने के लिए:एक-पंक्ति में शामिल होने के विकल्पों के लिए बिल्ड-साइड अनुमानित लागत 31,465 पंक्तियों के लिए गणना की गई इनपुट लागत का उपयोग करती है। यह आपको थोड़ा अजीब लगेगा।
एक अनुस्मारक के रूप में, एक-पंक्ति लागत की गणना CuNewJoinEstimate . द्वारा की जाती है इस प्रकार थे:
- एक पंक्ति
- हैश की कीमत 0.999027422729
- लागत लागू करें 0.547927305023
आप देख सकते हैं कि कुल लागू लागत (~0.54793) पर 0.54456 . का प्रभुत्व है बिल्ड-साइड सबट्री लागत, सिंगल इनर-साइड सीक के लिए एक छोटी अतिरिक्त राशि के साथ, जॉइन के भीतर परिणामी पंक्तियों की छोटी संख्या को संसाधित करना, और उन्हें मूल ऑपरेटर को पास करना।
अनुमानित एक-पंक्ति हैश जॉइन लागत अधिक है क्योंकि योजना के जांच पक्ष में एक पूर्ण इंडेक्स स्कैन होता है, जहां सभी परिणामी पंक्तियों को शामिल होने से गुजरना होगा। एक-पंक्ति हैश जॉइन की कुल लागत 31,465-पंक्ति उदाहरण के लिए मूल 1.05095 लागत से थोड़ी कम है क्योंकि हैश तालिका में अब केवल एक पंक्ति है।
प्रभाव
ड्राइविंग जॉइन इनपुट में एक पंक्ति देने की लागत पर, आंशिक रूप से, एक-पंक्ति में शामिल होने का अनुमान आधारित होने की उम्मीद होगी। जैसा कि हमने देखा, यह एक अनुकूली जुड़ाव के मामले में नहीं है:दोनों लागू और हैश विकल्प 31,465 पंक्तियों के लिए पूर्ण अनुमानित लागत के साथ दुखी हैं। बाकी जॉइन पर काफी खर्च होता है क्योंकि एक-पंक्ति बिल्ड इनपुट की अपेक्षा की जाती है।
यह सहज रूप से अजीब व्यवस्था है कि गणना की गई लागतों को प्रतिबिंबित करने वाली निष्पादन योजना को दिखाना मुश्किल (शायद असंभव) है। हमें ऊपरी जॉइन इनपुट में 31,465 पंक्तियों को वितरित करने वाली एक योजना बनाने की आवश्यकता है, लेकिन इसमें शामिल होने और इसके आंतरिक इनपुट की लागत केवल एक पंक्ति मौजूद थी। एक कठिन प्रश्न।
इस सबका प्रभाव हमारे प्रतिच्छेदन-रेखाओं के आरेख पर सबसे बाएं बिंदु को y-अक्ष तक उठाना है। यह रेखा के ढलान और इसलिए चौराहे के बिंदु को प्रभावित करता है।
एक और व्यावहारिक प्रभाव यह है कि गणना की गई अनुकूली जुड़ाव सीमा अब हैश बिल्ड इनपुट पर मूल कार्डिनैलिटी अनुमान पर निर्भर करती है, जैसा कि जो ओबिश ने अपने 2017 ब्लॉग पोस्ट में बताया है। उदाहरण के लिए, अगर हम WHERE . बदलते हैं परीक्षण क्वेरी में खंड SOH.SalesOrderID <= 55000 , अनुकूली सीमा घटती है 1502.07 से 1259.8 तक क्वेरी प्लान हैश को बदले बिना। वही योजना, अलग सीमा।
ऐसा इसलिए होता है क्योंकि, जैसा कि हमने देखा, आंतरिक एक-पंक्ति लागत अनुमान बिल्ड इनपुट लागत पर निर्भर करता है मूल कार्डिनैलिटी अनुमान के लिए। इसका मतलब है कि अलग-अलग प्रारंभिक बिल्ड-साइड अनुमान एक-पंक्ति अनुमान के लिए एक अलग y-अक्ष "बूस्ट" देंगे। बदले में, रेखा का एक अलग ढलान और एक अलग चौराहा बिंदु होगा।
अंतर्ज्ञान सुझाव देगा कि एक ही शामिल होने के लिए एक-पंक्ति अनुमान को हमेशा समान मूल्य देना चाहिए, भले ही लाइन पर अन्य कार्डिनैलिटी अनुमानों की परवाह किए बिना (समान गुणों के साथ सटीक समान जुड़ाव दिया गया हो और पंक्ति आकार में ड्राइविंग के बीच एक करीबी-से-रैखिक संबंध हो) पंक्तियाँ और लागत)। अनुकूली जुड़ाव के मामले में ऐसा नहीं है।
डिज़ाइन द्वारा?
SQL सर्वर क्या करता है . मैं आपको पूरे विश्वास के साथ बता सकता हूं अनुकूली जुड़ने की दहलीज की गणना करते समय। मुझे इस बारे में कोई विशेष जानकारी नहीं है क्यों यह इसे इस तरह से करता है।
फिर भी, यह सोचने के कुछ कारण हैं कि यह व्यवस्था जानबूझकर की गई है और परीक्षण से उचित विचार और प्रतिक्रिया के बाद आई है। इस खंड के शेष भाग में इस पहलू पर मेरे कुछ विचार शामिल हैं।
एक सामान्य लागू और बैच मोड हैश जॉइन के बीच एक अनुकूली जुड़ाव एक सीधा विकल्प नहीं है। एक अनुकूली जुड़ाव हमेशा हैश तालिका को पूरी तरह से भरकर शुरू होता है। केवल एक बार यह कार्य पूरा हो जाने पर लागू कार्यान्वयन पर स्विच करने का निर्णय लिया जाता है या नहीं।
इस समय तक, हम पहले से ही हैश जॉइन को मेमोरी में पॉप्युलेट और विभाजित करके संभावित रूप से महत्वपूर्ण लागत वहन कर चुके हैं। यह एक-पंक्ति के मामले के लिए ज्यादा मायने नहीं रखता है, लेकिन कार्डिनैलिटी बढ़ने के साथ यह उत्तरोत्तर अधिक महत्वपूर्ण हो जाता है। अप्रत्याशित "बूस्ट" एक उचित गणना लागत को बनाए रखते हुए इन वास्तविकताओं को गणना में शामिल करने का एक तरीका हो सकता है।
SQL सर्वर लागत मॉडल लंबे समय से नेस्टेड लूप में शामिल होने के खिलाफ थोड़ा पक्षपाती रहा है, यकीनन कुछ औचित्य के साथ। यहां तक कि आदर्श अनुक्रमित लागू मामला भी व्यवहार में धीमा हो सकता है यदि आवश्यक डेटा पहले से ही स्मृति में नहीं है, और I/O सबसिस्टम फ्लैश नहीं है, विशेष रूप से कुछ हद तक यादृच्छिक अभिगम पैटर्न के साथ। उदाहरण के लिए, सीमित मात्रा में मेमोरी और सुस्त I/O निम्न-स्तरीय क्लाउड-आधारित डेटाबेस इंजन के उपयोगकर्ताओं के लिए पूरी तरह से अपरिचित नहीं होंगे।
इस तरह के वातावरण में संभव व्यावहारिक परीक्षण से पता चला है कि एक सहज लागत वाली अनुकूली जुड़ाव एक आवेदन के लिए संक्रमण के लिए बहुत जल्दी था। सिद्धांत कभी-कभी केवल सिद्धांत में ही महान होता है।
फिर भी, वर्तमान स्थिति आदर्श नहीं है; असामान्य रूप से कम कार्डिनैलिटी अनुमान के आधार पर एक योजना को कैशिंग करने से एक अनुकूली जुड़ाव पैदा होगा जो एक बड़े प्रारंभिक अनुमान के मुकाबले एक आवेदन पर स्विच करने के लिए अधिक अनिच्छुक होगा। यह पैरामीटर-संवेदनशीलता समस्या की एक किस्म है, लेकिन हम में से कई लोगों के लिए यह इस प्रकार का एक नया विचार होगा।
अब, यह भी संभव है प्रतिच्छेदन लागत लाइनों के सबसे बाएं बिंदु के लिए पूर्ण बिल्ड इनपुट सबट्री लागत का उपयोग करना केवल एक गलत त्रुटि या निरीक्षण है। मेरी भावना यह है कि वर्तमान कार्यान्वयन शायद एक जानबूझकर व्यावहारिक समझौता है, लेकिन आपको निश्चित रूप से जानने के लिए डिज़ाइन दस्तावेज़ों और स्रोत कोड तक पहुंच वाले किसी व्यक्ति की आवश्यकता होगी।
सारांश
एक अनुकूली जुड़ाव SQL सर्वर को हैश तालिका के पूरी तरह से भर जाने के बाद एक बैच मोड हैश जॉइन से एक आवेदन में संक्रमण की अनुमति देता है। यह हैश तालिका में पंक्तियों की संख्या की तुलना एक पूर्व-परिकलित अनुकूली सीमा के साथ करके यह निर्णय लेता है।
थ्रेशोल्ड की गणना यह अनुमान लगाकर की जाती है कि कहां लागू होता है और हैश जॉइन की लागत बराबर होती है। इस बिंदु को खोजने के लिए, SQL सर्वर एक अलग बिल्ड इनपुट कार्डिनैलिटी के लिए एक दूसरा आंतरिक जुड़ाव लागत अनुमान तैयार करता है - सामान्य रूप से, एक पंक्ति।
आश्चर्यजनक रूप से, एक-पंक्ति अनुमान के लिए अनुमानित लागत में मूल कार्डिनैलिटी अनुमान के लिए पूर्ण बिल्ड-साइड सबट्री लागत शामिल है (एक पंक्ति में स्केल नहीं)। इसका मतलब है कि थ्रेशोल्ड मान बिल्ड इनपुट पर मूल कार्डिनैलिटी अनुमान पर निर्भर करता है।
नतीजतन, एक अनुकूली जुड़ाव में अप्रत्याशित रूप से कम थ्रेशोल्ड मान हो सकता है, जिसका अर्थ है कि अनुकूली जुड़ाव हैश जॉइन से दूर संक्रमण की संभावना बहुत कम है। यह स्पष्ट नहीं है कि यह व्यवहार डिज़ाइन के अनुसार है या नहीं।
संबंधित पढ़ना
- पेश है जो सैक द्वारा बैच मोड अडैप्टिव जॉइन
- उत्पाद दस्तावेज़ीकरण में अडैप्टिव जॉइन को समझना
- दिमा पिलुगिन द्वारा अडैप्टिव जॉइन इंटर्नल्स
- बैच मोड अडैप्टिव जॉइन कैसे काम करता है? एरिक डार्लिंग द्वारा डेटाबेस एडमिनिस्ट्रेटर स्टैक एक्सचेंज पर
- जो ओबिश द्वारा एक एडेप्टिव जॉइन रिग्रेशन
- यदि आप अनुकूली जुड़ाव चाहते हैं, तो आपको व्यापक अनुक्रमणिका की आवश्यकता है और क्या बड़ा बेहतर है? एरिक डार्लिंग द्वारा
- पैरामीटर सूँघना:ब्रेंट ओज़र द्वारा अनुकूली जुड़ाव
- जो सैक द्वारा बुद्धिमान क्वेरी संसाधन प्रश्नोत्तर
परिशिष्ट
इस खंड में कुछ अनुकूली जुड़ाव पहलुओं को शामिल किया गया है जिन्हें स्वाभाविक रूप से मुख्य पाठ में शामिल करना मुश्किल था।
विस्तृत अनुकूली योजना
आप अनिर्दिष्ट ट्रेस फ्लैग 9415 का उपयोग करके आंतरिक योजना के एक दृश्य प्रतिनिधित्व को देखने का प्रयास कर सकते हैं, जैसा कि दीमा पिलुगिन द्वारा ऊपर दिए गए उनके उत्कृष्ट अनुकूली जॉइन इंटर्नल लेख में प्रदान किया गया है। इस ध्वज के सक्रिय होने के साथ, हमारे चल रहे उदाहरण के लिए अनुकूली जुड़ने की योजना निम्नलिखित बन जाती है:
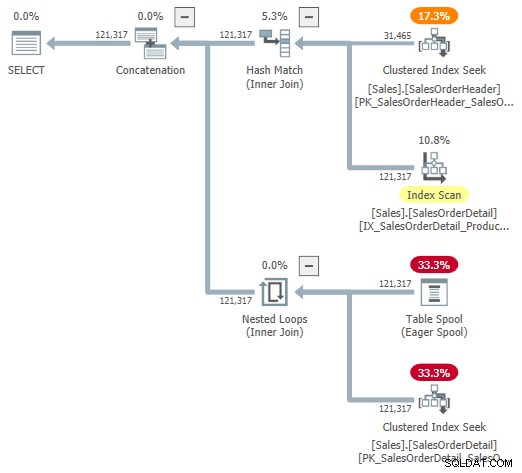
यह समझने में सहायता के लिए एक उपयोगी प्रतिनिधित्व है, लेकिन यह पूरी तरह सटीक, पूर्ण या सुसंगत नहीं है। उदाहरण के लिए, टेबल स्पूल मौजूद नहीं है—यह अनुकूली बफर रीडर के लिए एक डिफ़ॉल्ट प्रतिनिधित्व है बैच मोड हैश तालिका से सीधे पंक्तियों को पढ़ना।
ऑपरेटर गुण और कार्डिनैलिटी अनुमान भी हर जगह थोड़े हैं। अनुकूली बफर रीडर ("स्पूल") से आउटपुट 31,465 पंक्तियों का होना चाहिए, न कि 121,317। लागू करने की सबट्री लागत को पैरेंट ऑपरेटर लागत द्वारा गलत तरीके से कैप किया गया है। यह शोप्लान के लिए सामान्य है, लेकिन अनुकूली जुड़ाव के संदर्भ में इसका कोई मतलब नहीं है।
अन्य विसंगतियां भी हैं - उपयोगी रूप से सूचीबद्ध करने के लिए बहुत से - लेकिन यह अनिर्दिष्ट ट्रेस झंडे के साथ हो सकता है। ऊपर दिखाया गया विस्तारित प्लान अंतिम उपयोगकर्ताओं द्वारा उपयोग के लिए अभिप्रेत नहीं है, इसलिए शायद यह पूरी तरह से आश्चर्यजनक नहीं है। यहां संदेश इस अनिर्दिष्ट रूप में दिखाए गए नंबरों और गुणों पर बहुत अधिक भरोसा करने का नहीं है।
मुझे यह भी उल्लेख करना चाहिए कि समाप्त मानक अनुकूली जॉइन प्लान ऑपरेटर पूरी तरह से अपनी स्थिरता के मुद्दों के बिना नहीं है। ये काफी हद तक विशेष रूप से छिपे हुए विवरण से निकलते हैं।
उदाहरण के लिए, प्रदर्शित अनुकूली जुड़ाव गुण अंतर्निहित Concat . के मिश्रण से आते हैं , हैश जॉइन , और लागू करें ऑपरेटरों। आप नेस्टेड लूप जॉइन (जो असंभव है) के लिए एक अनुकूली जॉइन रिपोर्टिंग बैच मोड निष्पादन देख सकते हैं, और दिखाया गया बीता हुआ समय वास्तव में छिपे हुए Concat से कॉपी किया गया है , विशेष रूप से शामिल नहीं है जो रनटाइम पर निष्पादित होता है।
सामान्य संदिग्ध
हम कर सकते हैं ऑप्टिमाइज़र आउटपुट को देखने के लिए आमतौर पर उपयोग किए जाने वाले अनियंत्रित ट्रेस फ़्लैग के प्रकारों से कुछ उपयोगी जानकारी प्राप्त करें। उदाहरण के लिए:
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); आउटपुट (पठनीयता के लिए अत्यधिक संपादित):
*** आउटपुट ट्री:***PhyOp_ExecutionModeAdapter(BatchToRow) कार्ड=121317 लागत=1.05095
- PhyOp_Concat (बैच) कार्ड=121317 लागत=1.05325
- PhyOp_HashJoinx_jtInner (बैच) कार्ड=121317 लागत=1.05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 लागत=0.54456
- PhyOp_Filter(बैच) कार्ड=121317 लागत=0.397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 लागत=0.338953
- PhyOp_ExecutionModeAdapter(RowToBatch) कार्ड=121317 लागत=10.0798
- PhyOp_Apply Card=121317 लागत=10.0553
- PhyOp_ExecutionModeAdapter(BatchToRow) कार्ड=31465 लागत=0.544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 लागत=0.54456 [** 3 **]
- PhyOp_Filter Card=3.85562 लागत=9.00356
- PhyOp_Range Sales.SalesOrderDetail Card=3.85562 लागत=8.94533
- PhyOp_ExecutionModeAdapter(BatchToRow) कार्ड=31465 लागत=0.544623
- PhyOp_Apply Card=121317 लागत=10.0553
यह हैश के साथ पूर्ण-कार्डिनैलिटी मामले के लिए अनुमानित लागतों में कुछ अंतर्दृष्टि देता है और अलग-अलग प्रश्न लिखे बिना और संकेतों का उपयोग किए बिना विकल्प लागू करता है। जैसा कि मुख्य टेक्स्ट में बताया गया है, ये ट्रेस फ़्लैग CuNewJoinEstimate में प्रभावी नहीं हैं , इसलिए हम सीधे तौर पर 31,465-पंक्ति मामले के लिए दोहराए गए परिकलन या इस तरह से एक-पंक्ति अनुमान के किसी भी विवरण को नहीं देख सकते हैं।
मर्ज जॉइन और रो मोड हैश जॉइन करें
एडेप्टिव जॉइन केवल बैच मोड हैश जॉइन से रो मोड में संक्रमण की पेशकश करते हैं। पंक्ति मोड हैश जॉइन समर्थित नहीं होने के कारणों के लिए, संबंधित पठन अनुभाग में इंटेलिजेंट क्वेरी प्रोसेसिंग प्रश्नोत्तर देखें। संक्षेप में, यह सोचा गया है कि पंक्ति मोड हैश जॉइन प्रदर्शन प्रतिगमन के लिए बहुत अधिक प्रवण होगा।
एक पंक्ति मोड मर्ज ज्वाइन पर स्विच करना एक अन्य विकल्प होगा, लेकिन ऑप्टिमाइज़र वर्तमान में इस पर विचार नहीं करता है। जैसा कि मैं इसे समझता हूं, भविष्य में इस दिशा में इसके विस्तार की संभावना नहीं है।
कुछ विचार वही हैं जो वे पंक्ति मोड हैश जॉइन के लिए हैं। इसके अलावा, मर्ज जॉइन प्लान हैश जॉइन के साथ कम आसानी से विनिमेय होते हैं, भले ही हम खुद को इंडेक्सेड मर्ज जॉइन (कोई स्पष्ट सॉर्ट नहीं) तक सीमित रखते हैं।
हैश और मर्ज के बीच की तुलना में हैश और लागू के बीच बहुत अधिक अंतर है। हैश और मर्ज दोनों बड़े इनपुट के लिए उपयुक्त हैं, और लागू छोटे ड्राइविंग इनपुट के लिए बेहतर अनुकूल है। मर्ज जॉइन को हैश जॉइन के समान आसानी से समानांतर नहीं किया जाता है और थ्रेड काउंट बढ़ने के साथ-साथ स्केल भी नहीं होता है।
एडाप्टिव जॉइन की प्रेरणा को देखते हुए काफी . के साथ बेहतर तरीके से सामना करना है अलग-अलग इनपुट आकार- और केवल हैश जॉइन बैच मोड प्रोसेसिंग का समर्थन करता है- बैच हैश बनाम पंक्ति लागू का विकल्प अधिक स्वाभाविक है। अंत में, तीन अनुकूली जॉइन विकल्प होने से संभावित रूप से कम लाभ के लिए थ्रेशोल्ड गणना को काफी जटिल बना दिया जाएगा।