बड़ी डेटा समस्या
बड़े डेटा की मात्रा तेजी से बढ़ रही है। यह घटना वर्षों से हो रही है, लेकिन 2012 से इसकी गति नाटकीय रूप से तेज हो गई है। बिग डेटा के उद्भव और उससे संबंधित चुनौतियों पर समान दृष्टिकोण के लिए सीएससी से बिग डेटा जस्ट बिगिनिंग टू एक्सप्लोड नामक इस ब्लॉग को देखें।
1970 के दशक के अंत में कंपनी की स्थापना के बाद से IRI इस प्रवृत्ति से अवगत है। इसका प्रमुख CoSort पैकेज सॉफ़्टवेयर एल्गोरिदम और डिज़ाइन, "पोर्टेबल" हार्डवेयर शोषण तकनीकों, और कार्य समेकन (जैसे सॉर्ट-जॉइन-एग्रीगेट-एन्क्रिप्ट-रिपोर्ट) में दक्षता के माध्यम से बढ़ते डेटा वॉल्यूम को संभालने के लिए डिज़ाइन किया गया है। यह लेख "मशीनों के उदय" को देखते हुए एक दृष्टिकोण का प्रश्न उठाता है।
 इसे हल करने में हार्डवेयर की सीमा
इसे हल करने में हार्डवेयर की सीमा
निश्चित रूप से दशकों से कंप्यूटर का प्रदर्शन हर मामले में तेजी से बढ़ रहा है। और कई लोगों के लिए, बड़ी डेटा समस्या पर हार्डवेयर फेंकना केवल दूसरी प्रकृति है। हालाँकि, समस्या इससे भी बड़ी हो सकती है। मूर के नियम पर विचार करें, जिसमें CPU शक्ति केवल दोगुनी है हर 18 महीने में सबसे अच्छा, और अंतर्निहित अप्रचलन, रखरखाव के मुद्दे, और हार्डवेयर-केंद्रित रणनीति की शुद्ध लागत।
विचार करने के लिए कुछ नया भी एक उम्मीद है कि बड़े डेटा के लिए यह प्रदर्शन प्रतिमान समाप्त हो सकता है। गेरी मेनेगाज़ के अनुसार, उनका आधार यह है कि मूर के नियम का अंत निकट है। टाइम मैगज़ीन ने मई 2012 में इसी तरह की कहानी चलाई जिसका शीर्षक था कोलैप्स ऑफ़ मूर्स लॉ: भौतिक विज्ञानी सेज़ इट्स ऑलरेडी हैपनिंग। टाइम लेख के अनुसार,
<ब्लॉकक्वॉट>इसे देखते हुए, काकू का कहना है कि जब मूर का नियम आखिरकार अगले दशक के अंत तक ध्वस्त हो जाएगा, तो हम "तीन आयामों में चिप जैसे कंप्यूटरों के साथ बस [इसे] थोड़ा बदल देंगे।" इसके अलावा, वे कहते हैं, "हमें आणविक कंप्यूटरों और शायद 21वीं सदी के क्वांटम कंप्यूटरों में जाना पड़ सकता है।"
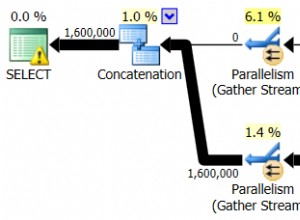
अधिकांश उपयोगकर्ताओं के लिए, हालांकि, उनके हार्डवेयर को संभालने के लिए खरीदा जाता है, और कुछ हद तक, बड़ी डेटा प्रोसेसिंग चुनौतियों का सामना करने के लिए जो वे सामना करते हैं या देखते हैं। लेकिन उस पर चलने वाला सॉफ्टवेयर जितना कम कुशलता से प्रदर्शन करता है, अक्षमता पर काबू पाने के लिए उतने ही अधिक हार्डवेयर संसाधनों को खर्च करना पड़ता है। हमारी दुनिया में एक उदाहरण आईबीएम p595 को /bin/sort चलाने के लिए खरीदना हो सकता है जब एक मशीन एक तिहाई आकार और लागत पर चलने वाली CoSort एक ही परिणाम उत्पन्न करेगी।
इस बीच, हार्डवेयर के आसपास निर्मित Exadata और Netezza जैसे DB और ELT उपकरणों को पहले से ही 6-7 फिगर निवेश की आवश्यकता होती है। और जब वे बड़े भार को उठाने के लिए स्केल कर सकते हैं, तो आमतौर पर इसकी एक सीमा होती है कि वे कितना स्केल कर सकते हैं (निश्चित रूप से तेजी से नहीं), स्केलिंग को बनाए रखने के प्रयास पर कितना पैसा खर्च किया जा सकता है, और लोग इस पर भरोसा करने के लिए कितने इच्छुक हैं। प्रत्येक मिशन के लिए एकल विक्रेता अपने कार्यभार के महत्वपूर्ण पहलू। और, क्या इसके बजाय भंडारण और पुनर्प्राप्ति (क्वेरी) अनुकूलन के लिए डिज़ाइन किए गए डेटाबेस में बड़े डेटा परिवर्तन के ऊपरी हिस्से को थोपना एक अच्छा विचार है?
यहां तक कि अगर उन सभी सवालों के आसान जवाब थे, तो कम्प्यूटेशनल समस्याएं (यहां तक कि बड़े डेटा वृद्धि को केवल रैखिक रूप से स्केल करने के साथ) कैसे हल हो जाती हैं, जिनके लिए तेजी से बड़े संसाधन खपत (जैसे सॉर्टिंग) की आवश्यकता होती है? किसी भी तरह से इसका उत्तर केवल सस्ती क्वांटम कंप्यूटिंग की प्रतीक्षा में नहीं लगेगा …
सॉफ्टवेयर की भूमिका
जैसा कि Hadoop और डेटा वेयरहाउस आर्किटेक्ट्स जानते हैं, सॉर्टिंग - और ETL में जॉइन, एग्रीगेट, और लोडिंग ऑपरेशन जो सॉर्टिंग पर निर्भर करते हैं - बड़ी डेटा प्रोसेसिंग चुनौती के केंद्र में है, और एक घातीय उपभोक्ता है कंप्यूटिंग संसाधन। जैसे-जैसे बड़ा डेटा दोगुना होता है, इसे सॉर्ट करने के लिए संसाधन की आवश्यकताएं तीन गुना हो सकती हैं। इसलिए मल्टी-प्लेटफ़ॉर्म, मल्टी-कोर सॉर्टिंग सॉफ़्टवेयर से जुड़े एल्गोरिदम, हार्डवेयर शोषण तकनीक और प्रोसेसिंग स्कीम इस समस्या को स्केलेबल, किफायती और कुशल तरीकों से प्रबंधित करने की कुंजी हैं।
CoSort का योगदान
CoSort प्रदर्शन मात्रा में रैखिक रूप से मापता है, Amdahl के नियम की तर्ज पर अधिक। जबकि CoSort कुछ दर्जन कोर के साथ सैकड़ों गीगाबाइट बड़े डेटा को मिनटों में बदल सकता है, अन्य उपकरण दोगुने से अधिक समय ले सकते हैं, लगभग उतना ही स्केल नहीं कर सकते हैं, और/या इस प्रक्रिया में अधिक मेमोरी और I/O का उपभोग कर सकते हैं। शायद अधिक महत्वपूर्ण बात यह है कि CoSort सीधे संबंधित अनुप्रयोगों में सॉर्टिंग को एकीकृत करता है, और डीबी और बीआई परत के बाहर अपने सभी भारी भारोत्तोलन करता है जहां स्टेजिंग डेटा कम कुशल होगा।
CoSort का को-रूटीन आर्किटेक्चर, सॉर्टर और प्रोग्राम जैसे SortCL (CoSort का डेटा ट्रांसफ़ॉर्मेशन, फ़िल्टरिंग, लुकअप, रिपोर्टिंग, माइग्रेशन और प्रोटेक्शन यूटिलिटी) के बीच रिकॉर्ड को मेमोरी के माध्यम से अंतःक्रियात्मक रूप से स्थानांतरित करता है। इसलिए जैसे ही अगला सॉर्ट किया गया रिकॉर्ड उपलब्ध होता है, यह एप्लिकेशन, लोड, आदि में स्थानांतरित हो सकता है। यह ऐप को लगता है कि यह एक इनपुट फ़ाइल पढ़ रहा है लेकिन वास्तव में, स्रोत का बैक एंड अभी तक निर्मित नहीं हुआ है। और नहीं, आप सॉर्टर से आगे नहीं बढ़ेंगे।
2015 के अंत में, CoSort भी IRI के आधुनिक बड़े डेटा प्रबंधन और हेरफेर प्लेटफॉर्म, Voracity के अंदर इंजन बन गया। Voracity CoSort या Hadoop दोनों इंजनों का निर्बाध रूप से लाभ उठाता है।
निष्कर्ष
बड़े डेटा को संसाधित करने की समस्या को बढ़ाने के लिए केवल भौतिक कंप्यूटिंग संसाधनों की गणना नहीं की जा सकती है। CoSort सॉफ़्टवेयर वातावरण वह है जिसमें बड़े डेटा परिवर्तन की आवश्यकता होती है और संबंधित कार्य स्टैंडअलोन प्रक्रियाओं के रूप में नहीं, बल्कि समान I/O पास के दौरान समानांतर में चलते हैं।
इसलिए, यदि आपको सॉर्ट करने के लिए केवल समय के अलावा किसी अन्य उद्देश्य के लिए तेज़ सॉर्ट की आवश्यकता है, तो आपको इस बारे में सोचना चाहिए कि सॉर्ट से डाउनस्ट्रीम क्या होता है, और ऐसी प्रक्रियाओं को एक साथ जोड़ने के सर्वोत्तम तरीके। और एक बार जब आप सर्वोत्तम रनटाइम प्रतिमान निर्धारित कर लेते हैं, तो क्या आप प्रदर्शन को अनुकूलित करने के लिए उच्च-प्रदर्शन हार्डवेयर को ऐसे सॉफ़्टवेयर के साथ जोड़ सकते हैं? उदाहरण के लिए, क्या आप Exadata के डेटाबेस सर्वर साइड में CoSort के साथ DW डेटा को स्टेज कर सकते हैं? या अपने IBM p595 को रखना और CoSort को ट्रिपल थ्रूपुट में जोड़ना अधिक समझदारी होगी? या यदि आप Hadoop का उपयोग करने का इरादा रखते हैं, तो MapReduce 2, Spark, Storm, या Tez नौकरियों को चलाने के लिए CoSort के समान सरल 4GL या Voracity की सहज ETL मैपिंग का उपयोग करने पर विचार करें।
डेटा वृद्धि से निपटने के लिए अपने बजट और अपनी कल्पना को अपना मार्गदर्शक बनने दें।