हालांकि वे कई प्रतिबंधों और कुछ महत्वपूर्ण कार्यान्वयन चेतावनियों के साथ आते हैं, सही परिस्थितियों में सही ढंग से नियोजित होने पर अनुक्रमित विचार अभी भी एक बहुत शक्तिशाली SQL सर्वर सुविधा है। एक सामान्य उपयोग अंतर्निहित डेटा का एक पूर्व-एकत्रित दृश्य प्रदान करना है, जिससे उपयोगकर्ताओं को हर बार किसी क्वेरी के निष्पादित होने पर अंतर्निहित जॉइन, फ़िल्टर और एग्रीगेट को संसाधित करने की लागत के बिना सीधे परिणामों को क्वेरी करने की क्षमता मिलती है।
हालांकि कॉलमर स्टोरेज और बैच मोड प्रोसेसिंग जैसी नई एंटरप्राइज़ संस्करण सुविधाओं ने इस प्रकार के कई बड़े प्रश्नों की प्रदर्शन विशेषताओं को बदल दिया है, फिर भी परिणाम प्राप्त करने का कोई तेज़ तरीका नहीं है, सभी अंतर्निहित प्रसंस्करण से पूरी तरह से बचने के लिए, चाहे वह प्रसंस्करण कितना भी कुशल क्यों न हो हो सकता है।
उत्पाद में अनुक्रमित दृश्य (और उनके अधिक सीमित चचेरे भाई, गणना किए गए कॉलम) जोड़े जाने से पहले, डेटाबेस पेशेवर कभी-कभी वास्तविक तालिका में एक महत्वपूर्ण क्वेरी के परिणाम प्रस्तुत करने के लिए जटिल मल्टी-ट्रिगर कोड लिखते थे। इस तरह की व्यवस्था सभी परिस्थितियों में ठीक होना बेहद मुश्किल है, खासकर जहां अंतर्निहित डेटा में समवर्ती परिवर्तन अक्सर होते हैं।
अनुक्रमित दृश्य सुविधा यह सब बहुत आसान बनाती है, जहां इसे समझदारी से और सही तरीके से लागू किया जाता है। डेटाबेस इंजन यह सुनिश्चित करने के लिए आवश्यक हर चीज का ख्याल रखता है कि अनुक्रमित दृश्य से पढ़ा गया डेटा हर समय अंतर्निहित क्वेरी और तालिका डेटा से मेल खाता है।
वृद्धिशील रखरखाव
SQL सर्वर अनुक्रमित दृश्य डेटा को अंतर्निहित क्वेरी के साथ सिंक्रनाइज़ करता रहता है, जब भी आधार तालिका में डेटा में परिवर्तन होता है, तो दृश्य अनुक्रमणिका को स्वचालित रूप से उचित रूप से अद्यतन करता है। इस रखरखाव गतिविधि की लागत आधार डेटा को बदलने की प्रक्रिया द्वारा वहन की जाती है। दृश्य अनुक्रमणिका को बनाए रखने के लिए आवश्यक अतिरिक्त संचालन को मूल सम्मिलित करने, अद्यतन करने, हटाने या मर्ज करने के लिए निष्पादन योजना में चुपचाप जोड़ा जाता है। पृष्ठभूमि में, SQL सर्वर लेनदेन अलगाव से संबंधित अधिक सूक्ष्म मुद्दों का भी ध्यान रखता है, उदाहरण के लिए स्नैपशॉट के तहत चल रहे लेनदेन के लिए सही हैंडलिंग सुनिश्चित करना या प्रतिबद्ध स्नैपशॉट अलगाव पढ़ना।
व्यू इंडेक्स को सही ढंग से बनाए रखने के लिए आवश्यक अतिरिक्त निष्पादन योजना संचालन का निर्माण करना कोई मामूली बात नहीं है, क्योंकि जिसने भी "ट्रिगर कोड द्वारा बनाए गए सारांश तालिका" कार्यान्वयन का प्रयास किया है, उसे पता चल जाएगा। कार्य की जटिलता एक कारण है कि अनुक्रमित विचारों में इतने सारे प्रतिबंध हैं। समर्थित सतह क्षेत्र को आंतरिक जुड़ाव, अनुमानों, चयनों (फ़िल्टर), और SUM और COUNT_BIG समुच्चय तक सीमित करने से कार्यान्वयन जटिलता काफी कम हो जाती है।
अनुक्रमित दृश्य वृद्धिशील रूप से बनाए रखा जाता है . इसका अर्थ है कि क्वेरी प्रोसेसर दृश्य पर आधार तालिका परिवर्तनों के शुद्ध प्रभाव को निर्धारित करता है, और दृश्य को अद्यतित करने के लिए आवश्यक केवल उन परिवर्तनों को लागू करता है। साधारण मामलों में, यह केवल आधार तालिका परिवर्तन और वर्तमान में दृश्य में संग्रहीत डेटा से आवश्यक डेल्टा की गणना कर सकता है। जहां दृश्य परिभाषा में शामिल होते हैं, निष्पादन योजना के अनुक्रमित दृश्य रखरखाव भाग को भी सम्मिलित तालिकाओं तक पहुंचने की आवश्यकता होगी, लेकिन यह आमतौर पर उपयुक्त आधार तालिका अनुक्रमणिका को देखते हुए कुशलतापूर्वक किया जा सकता है।
कार्यान्वयन को और सरल बनाने के लिए, अनुक्रमित दृश्य रखरखाव कार्यों को लागू करने के लिए SQL सर्वर हमेशा एक ही मूल योजना आकार (प्रारंभिक बिंदु के रूप में) का उपयोग करता है। क्वेरी ऑप्टिमाइज़र द्वारा प्रदान की जाने वाली सामान्य सुविधाओं को उपयुक्त मानक रखरखाव आकार को सरल और अनुकूलित करने के लिए नियोजित किया जाता है। इन अवधारणाओं को एक साथ लाने में मदद के लिए अब हम एक उदाहरण की ओर रुख करेंगे।
उदाहरण 1 - सिंगल रो इंसर्ट
मान लीजिए कि हमारे पास निम्न सरल तालिका और अनुक्रमित दृश्य है:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); उस स्क्रिप्ट के चलने के बाद, नमूना तालिका में डेटा इस तरह दिखता है:

और अनुक्रमित दृश्य में शामिल हैं:

इस सेटअप के लिए अनुक्रमित दृश्य रखरखाव योजना का सबसे सरल उदाहरण तब होता है जब हम आधार तालिका में एक पंक्ति जोड़ते हैं:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); इस इंसर्ट की निष्पादन योजना नीचे दिखाई गई है:
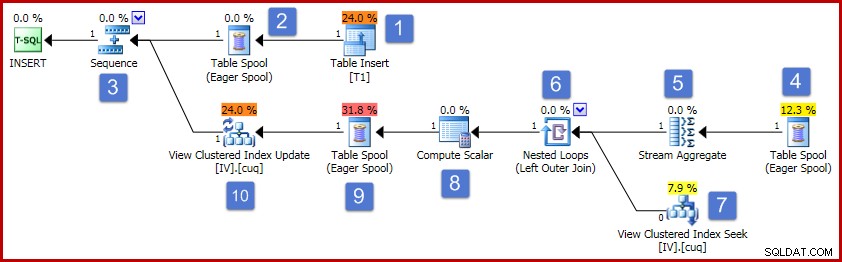
आरेख में संख्याओं के बाद, इस निष्पादन योजना का संचालन निम्नानुसार आगे बढ़ता है:
- टेबल इंसर्ट ऑपरेटर नई पंक्ति को बेस टेबल में जोड़ता है। बेस टेबल इंसर्ट से जुड़ा यह एकमात्र प्लान ऑपरेटर है; सभी शेष ऑपरेटर अनुक्रमित दृश्य के रखरखाव से संबंधित हैं।
- ईगर टेबल स्पूल सम्मिलित पंक्ति डेटा को अस्थायी संग्रहण में सहेजता है।
- अनुक्रम ऑपरेटर यह सुनिश्चित करता है कि अनुक्रम में अगली शाखा सक्रिय होने से पहले योजना की शीर्ष शाखा पूरी हो जाए। इस विशेष मामले में (एक पंक्ति सम्मिलित करते हुए), यह अनुक्रम (और स्थिति 2 और 4 पर स्पूल) को हटाने के लिए मान्य होगा, सीधे स्ट्रीम एग्रीगेट इनपुट को टेबल इंसर्ट के आउटपुट से जोड़ना। यह संभावित अनुकूलन लागू नहीं किया गया है, इसलिए अनुक्रम और स्पूल बने रहते हैं।
- यह उत्सुक टेबल स्पूल स्पूल के साथ स्थिति 2 पर जुड़ा हुआ है (इसमें एक प्राथमिक नोड आईडी संपत्ति है जो स्पष्ट रूप से यह लिंक प्रदान करती है)। स्पूल प्राथमिक स्पूल द्वारा लिखे गए उसी अस्थायी भंडारण से पंक्तियों (वर्तमान मामले में एक पंक्ति) को फिर से चलाता है। जैसा कि ऊपर उल्लेख किया गया है, स्पूल और स्थिति 2 और 4 अनावश्यक हैं, और केवल इसलिए प्रदर्शित होते हैं क्योंकि वे अनुक्रमित दृश्य रखरखाव के लिए सामान्य टेम्पलेट में मौजूद हैं।
- स्ट्रीम एग्रीगेट सम्मिलित सेट में मान कॉलम डेटा के योग की गणना करता है, और प्रति दृश्य-कुंजी समूह में मौजूद पंक्तियों की संख्या की गणना करता है। आउटपुट वृद्धिशील डेटा है जो दृश्य को आधार डेटा के साथ सिंक्रनाइज़ रखने के लिए आवश्यक है। ध्यान दें, स्ट्रीम एग्रीगेट में समूह द्वारा तत्व नहीं है क्योंकि क्वेरी ऑप्टिमाइज़र जानता है कि केवल एक मान संसाधित किया जा रहा है। हालांकि, ऑप्टिमाइज़र अनुमानों के साथ समुच्चय को बदलने के लिए समान तर्क लागू नहीं करता है (एकल मान का योग केवल मान ही है, और गणना हमेशा एक पंक्ति डालने के लिए एक होगी)। डेटा की एक पंक्ति के लिए योग और गणना समुच्चय की गणना करना एक महंगा ऑपरेशन नहीं है, इसलिए इस छूटे हुए अनुकूलन के बारे में चिंतित होने की कोई बात नहीं है।
- जॉइन प्रत्येक परिकलित वृद्धिशील परिवर्तन को अनुक्रमित दृश्य में मौजूदा कुंजी से संबंधित करता है। शामिल होना एक बाहरी जुड़ाव है क्योंकि नया डाला गया डेटा दृश्य में मौजूद किसी भी मौजूदा डेटा के अनुरूप नहीं हो सकता है।
- यह ऑपरेटर दृश्य में संशोधित की जाने वाली पंक्ति का पता लगाता है।
- कम्प्यूट स्केलर की दो महत्वपूर्ण जिम्मेदारियां हैं। सबसे पहले, यह निर्धारित करता है कि क्या प्रत्येक वृद्धिशील परिवर्तन दृश्य में मौजूदा पंक्ति को प्रभावित करेगा, या एक नई पंक्ति बनानी होगी या नहीं। यह यह देखने के लिए जांच करता है कि बाहरी जुड़ाव शामिल होने के दृश्य पक्ष से शून्य उत्पन्न करता है या नहीं। हमारा नमूना सम्मिलन समूह 3 के लिए है, जो वर्तमान में दृश्य में मौजूद नहीं है, इसलिए एक नई पंक्ति बनाई जाएगी। कंप्यूट स्केलर का दूसरा कार्य व्यू कॉलम के लिए नए मानों की गणना करना है। यदि दृश्य में एक नई पंक्ति जोड़ी जानी है, तो यह केवल स्ट्रीम एग्रीगेट से वृद्धिशील योग का परिणाम है। यदि दृश्य में मौजूदा पंक्ति को अद्यतन किया जाना है, तो नया मान दृश्य पंक्ति में मौजूदा मान और स्ट्रीम एग्रीगेट से वृद्धिशील योग है।
- यह उत्सुक टेबल स्पूल हैलोवीन सुरक्षा के लिए है। यह शुद्धता के लिए आवश्यक है जब एक सम्मिलित ऑपरेशन एक तालिका को प्रभावित करता है जिसे क्वेरी के डेटा एक्सेस पक्ष पर भी संदर्भित किया जाता है। यह तकनीकी रूप से आवश्यक नहीं है यदि एकल-पंक्ति रखरखाव ऑपरेशन के परिणामस्वरूप मौजूदा दृश्य पंक्ति में अपडेट होता है, लेकिन यह वैसे भी योजना में बना रहता है।
- योजना में अंतिम ऑपरेटर को अपडेट ऑपरेटर के रूप में लेबल किया गया है, लेकिन यह नोड 8 पर कंप्यूट स्केलर द्वारा जोड़े गए "एक्शन कोड" कॉलम के मूल्य के आधार पर प्राप्त होने वाली प्रत्येक पंक्ति के लिए या तो एक इंसर्ट या अपडेट करेगा। . आम तौर पर, यह अपडेट ऑपरेटर इन्सर्ट, अपडेट और डिलीट करने में सक्षम है।
वहाँ काफी विस्तार है, इसलिए संक्षेप में:
- समुच्चय समूह डेटा दृश्य की अद्वितीय क्लस्टर कुंजी द्वारा बदलता है। यह प्रत्येक स्तंभ प्रति कुंजी पर आधार तालिका परिवर्तनों के शुद्ध प्रभाव की गणना करता है।
- बाहरी जुड़ाव प्रति-कुंजी वृद्धिशील परिवर्तनों को दृश्य में मौजूदा पंक्तियों से जोड़ता है।
- कंप्यूट स्केलर गणना करता है कि क्या दृश्य में एक नई पंक्ति जोड़ी जानी चाहिए, या एक मौजूदा पंक्ति अपडेट की गई है। यह व्यू इंसर्ट या अपडेट ऑपरेशन के लिए अंतिम कॉलम मानों की गणना करता है।
- व्यू अपडेट ऑपरेटर एक नई पंक्ति सम्मिलित करता है या एक्शन कोड द्वारा निर्देशित किसी मौजूदा को अपडेट करता है।
उदाहरण 2 - बहु-पंक्ति सम्मिलन
मानो या न मानो, ऊपर चर्चा की गई एकल-पंक्ति आधार तालिका सम्मिलित निष्पादन योजना कई सरलीकरणों के अधीन थी। हालांकि कुछ और संभावित अनुकूलन छूट गए थे (जैसा कि बताया गया है), क्वेरी ऑप्टिमाइज़र अभी भी सामान्य अनुक्रमित दृश्य रखरखाव टेम्पलेट से कुछ संचालन को निकालने में कामयाब रहा, और दूसरों की जटिलता को कम करता है।
इनमें से कई अनुकूलन की अनुमति थी क्योंकि हम केवल एक पंक्ति सम्मिलित कर रहे थे, लेकिन अन्य सक्षम थे क्योंकि अनुकूलक आधार तालिका में जोड़े जा रहे शाब्दिक मूल्यों को देखने में सक्षम था। उदाहरण के लिए, ऑप्टिमाइज़र देख सकता है कि डाला गया समूह मान दृश्य के WHERE क्लॉज़ में विधेय को पास कर देगा।
यदि हम अब स्थानीय चरों में "छिपे हुए" मानों के साथ दो पंक्तियाँ सम्मिलित करते हैं, तो हमें थोड़ी अधिक जटिल योजना मिलती है:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
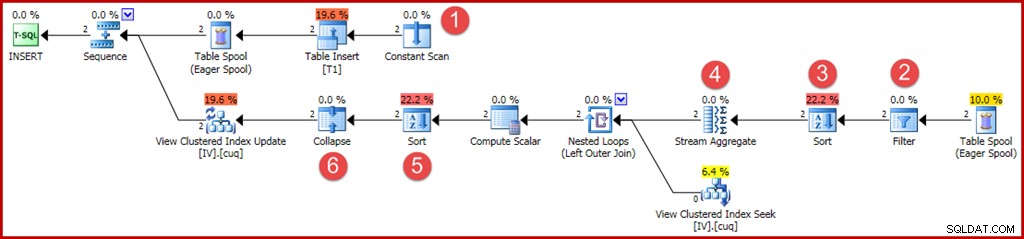
नए या बदले गए ऑपरेटरों को पहले की तरह एनोटेट किया जाता है:
- स्थिर स्कैन सम्मिलित करने के लिए मान प्रदान करता है। पहले, एकल-पंक्ति सम्मिलन के लिए एक अनुकूलन ने इस ऑपरेटर को छोड़े जाने की अनुमति दी थी।
- एक स्पष्ट फ़िल्टर ऑपरेटर को अब यह जांचने की आवश्यकता है कि आधार तालिका में सम्मिलित समूह दृश्य में WHERE क्लॉज से मेल खाते हैं या नहीं। जैसा कि होता है, दोनों नई पंक्तियाँ परीक्षण पास करेंगी, लेकिन अनुकूलक इसे पहले से जानने के लिए चर में मान नहीं देख सकता है। इसके अतिरिक्त, उस योजना को कैश करना सुरक्षित नहीं होगा जिसने इस फ़िल्टर को छोड़ दिया है क्योंकि भविष्य में योजना के पुन:उपयोग के चरों में भिन्न मान हो सकते हैं।
- समूह क्रम में स्ट्रीम एग्रीगेट पर पंक्तियों का आगमन सुनिश्चित करने के लिए अब एक सॉर्ट की आवश्यकता है। सॉर्ट को पहले हटा दिया गया था क्योंकि एक पंक्ति को सॉर्ट करना व्यर्थ है।
- स्ट्रीम एग्रीगेट में अब "ग्रुप बाय" प्रॉपर्टी है, जो व्यू की यूनिक क्लस्टर की से मेल खाती है।
- इस सॉर्ट को व्यू-की, एक्शन कोड ऑर्डर में पंक्तियों को प्रस्तुत करने की आवश्यकता है, जो कि कोलैप्स ऑपरेटर के सही संचालन के लिए आवश्यक है। सॉर्ट पूरी तरह से ब्लॉक करने वाला ऑपरेटर है इसलिए अब हैलोवीन प्रोटेक्शन के लिए ईगर टेबल स्पूल की कोई आवश्यकता नहीं है।
- नया संक्षिप्त ऑपरेटर एक ही कुंजी मान पर एक आसन्न सम्मिलन को जोड़ता है और एक ही अद्यतन ऑपरेशन में हटा देता है। यह ऑपरेटर वास्तव में आवश्यक नहीं है इस मामले में, क्योंकि कोई विलोपन क्रिया कोड उत्पन्न नहीं किया जा सकता है (केवल सम्मिलित और अद्यतन)। यह एक चूक प्रतीत होती है, या शायद सुरक्षा कारणों से कुछ बचा है। अद्यतन क्वेरी योजना के स्वचालित रूप से जेनरेट किए गए भाग अत्यंत जटिल हो सकते हैं, इसलिए निश्चित रूप से इसे जानना कठिन है।
फ़िल्टर के गुण (दृश्य के WHERE क्लॉज़ से प्राप्त) हैं:
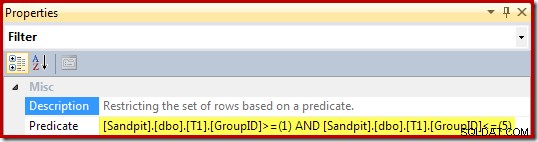
व्यू की के आधार पर स्ट्रीम एग्रीगेट ग्रुप, और हर ग्रुप के योग और काउंट एग्रीगेट की गणना करता है:
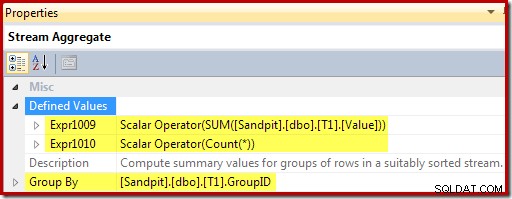
कंप्यूट स्केलर प्रति पंक्ति (इस मामले में सम्मिलित या अद्यतन) की जाने वाली कार्रवाई की पहचान करता है, और दृश्य में डालने या अद्यतन करने के लिए मान की गणना करता है:
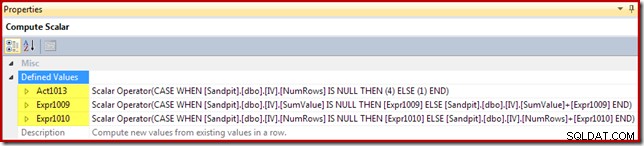
एक्शन कोड को [Act1xxx] का एक्सप्रेशन लेबल दिया गया है। मान्य मान अपडेट के लिए 1, डिलीट के लिए 3 और इंसर्ट के लिए 4 हैं। यह क्रिया अभिव्यक्ति एक सम्मिलन (कोड 4) में परिणाम देती है यदि दृश्य में कोई मिलान पंक्ति नहीं मिली (यानी बाहरी जुड़ाव ने न्यूमरो कॉलम के लिए एक शून्य लौटा दी)। यदि एक मेल खाने वाली पंक्ति पाई जाती है, तो क्रिया कोड 1 (अपडेट) होता है।
ध्यान दें कि NumRows दृश्य में आवश्यक COUNT_BIG(*) कॉलम को दिया गया नाम है। एक ऐसी योजना में जिसके परिणामस्वरूप दृश्य से विलोपन हो सकता है, कंप्यूट स्केलर यह पता लगाएगा कि यह मान कब शून्य हो जाएगा (वर्तमान समूह के लिए कोई पंक्ति नहीं) और एक डिलीट एक्शन कोड (3) उत्पन्न करेगा।
शेष भाव दृश्य में योग और गणना योग बनाए रखते हैं। ध्यान दें कि अभिव्यक्ति लेबल [Expr1009] और [Expr1010] नए नहीं हैं; वे स्ट्रीम एग्रीगेट द्वारा बनाए गए लेबल को संदर्भित करते हैं। तर्क सीधा है:यदि एक मेल खाने वाली पंक्ति नहीं मिली, तो सम्मिलित करने के लिए नया मान केवल कुल पर गणना किया गया मान है। यदि दृश्य में एक मेल खाने वाली पंक्ति पाई जाती है, तो अपडेट किया गया मान पंक्ति में वर्तमान मान और कुल द्वारा गणना की गई वृद्धि है।
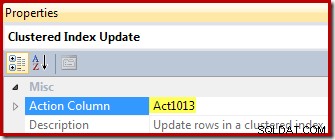
अंत में, व्यू अपडेट ऑपरेटर (एसएसएमएस में क्लस्टर्ड इंडेक्स अपडेट के रूप में दिखाया गया है) एक्शन कॉलम संदर्भ ([एक्ट 1013] कंप्यूट स्केलर द्वारा परिभाषित) दिखाता है:
उदाहरण 3 - बहु-पंक्ति अपडेट
अभी तक हमने केवल बेस टेबल के इंसर्ट को ही देखा है। विलोपन के लिए निष्पादन योजनाएँ बहुत समान हैं, विस्तृत गणनाओं में केवल कुछ मामूली अंतर हैं। इसलिए यह अगला उदाहरण बेस टेबल अपडेट के लिए रखरखाव योजना को देखने के लिए आगे बढ़ता है:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); पहले की तरह, यह क्वेरी ऑप्टिमाइज़र से शाब्दिक मूल्यों को छिपाने के लिए चर का उपयोग करती है, कुछ सरलीकरणों को लागू होने से रोकती है। दो अलग-अलग समूहों को अपडेट करने में भी सावधानी बरती जाती है, जिससे उन ऑप्टिमाइज़ेशन को रोका जा सकता है जिन्हें तब लागू किया जा सकता है जब ऑप्टिमाइज़र जानता है कि केवल एक समूह (अनुक्रमित दृश्य की एक पंक्ति) प्रभावित होगा। अद्यतन क्वेरी के लिए व्याख्या की गई निष्पादन योजना नीचे है:
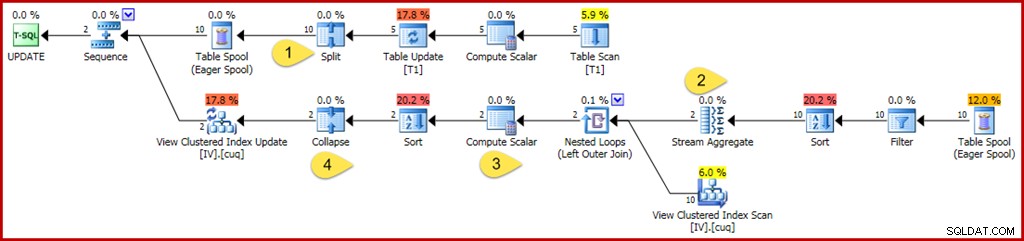
परिवर्तन और रुचि के बिंदु हैं:
- नया स्प्लिट ऑपरेटर प्रत्येक बेस टेबल रो अपडेट को एक अलग डिलीट एंड इंसर्ट ऑपरेशन में बदल देता है। प्रत्येक अद्यतन पंक्ति को दो अलग-अलग पंक्तियों में विभाजित किया जाता है, जिससे योजना में इस बिंदु के बाद पंक्तियों की संख्या दोगुनी हो जाती है। स्प्लिट गलत क्षणिक अद्वितीय कुंजी उल्लंघन त्रुटियों से बचाने के लिए आवश्यक स्प्लिट-सॉर्ट-पतन पैटर्न का हिस्सा है।
- स्ट्रीम एग्रीगेट को आने वाली पंक्तियों के हिसाब से संशोधित किया गया है जो या तो एक डिलीट या इंसर्ट निर्दिष्ट कर सकता है (स्प्लिट के कारण, और पंक्ति में एक एक्शन कोड कॉलम द्वारा निर्धारित)। एक सम्मिलित पंक्ति योग समुच्चय में मूल मान का योगदान करती है; कार्रवाई पंक्तियों को हटाने के लिए चिह्न को उलट दिया गया है। इसी तरह, यहां पंक्ति गणना कुल मिलाकर +1 के रूप में सम्मिलित पंक्तियों की गणना करती है और पंक्तियों को -1 के रूप में हटाती है।
- कंप्यूट स्केलर लॉजिक को यह दर्शाने के लिए भी संशोधित किया गया है कि प्रति समूह परिवर्तनों के शुद्ध प्रभाव के लिए भौतिक दृश्य के विरुद्ध अंतिम सम्मिलन, अद्यतन या हटाने की कार्रवाई की आवश्यकता हो सकती है। इस विशेष अद्यतन क्वेरी के परिणामस्वरूप इस दृश्य के विरुद्ध एक पंक्ति डाली या हटाई जा सकती है, लेकिन इसे निकालने के लिए आवश्यक तर्क अनुकूलक की वर्तमान तर्क क्षमताओं से परे है। थोड़ी अलग अद्यतन क्वेरी या दृश्य परिभाषा वास्तव में सम्मिलित करें, हटाएं, और दृश्य क्रियाओं को अद्यतन करें का मिश्रण हो सकती है।
- संक्षिप्त ऑपरेटर को ऊपर उल्लिखित स्प्लिट-सॉर्ट-संक्षिप्त पैटर्न में अपनी भूमिका के लिए पूरी तरह से हाइलाइट किया गया है। ध्यान दें कि यह केवल उसी कुंजी पर हटाए गए और सम्मिलित करता है; संक्षिप्त करने के बाद बेजोड़ हटाना और सम्मिलित करना पूरी तरह से संभव है (और काफी सामान्य)।
पहले की तरह, अनुक्रमित दृश्य रखरखाव कार्य को समझने के लिए देखने के लिए प्रमुख ऑपरेटर गुण हैं फ़िल्टर, स्ट्रीम एग्रीगेट, आउटर जॉइन और कंप्यूट स्केलर।
उदाहरण 4 - जॉइन के साथ बहु-पंक्ति अपडेट
अनुक्रमित दृश्य रखरखाव निष्पादन योजनाओं के अवलोकन को पूरा करने के लिए, हमें एक नए उदाहरण दृश्य की आवश्यकता होगी जो कई तालिकाओं को एक साथ जोड़ता है, और चयन सूची में एक प्रक्षेपण शामिल करता है:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); शुद्धता सुनिश्चित करने के लिए, अनुक्रमित दृश्य आवश्यकताओं में से एक यह है कि एक योग एक अभिव्यक्ति पर काम नहीं कर सकता है जो शून्य का मूल्यांकन कर सकता है। उपरोक्त दृश्य परिभाषा उस आवश्यकता को पूरा करने के लिए ISNULL का उपयोग करती है। एक नमूना अद्यतन क्वेरी जो एक बहुत व्यापक सूचकांक रखरखाव योजना घटक का उत्पादन करती है, नीचे दी गई निष्पादन योजना के साथ दिखाई गई है:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
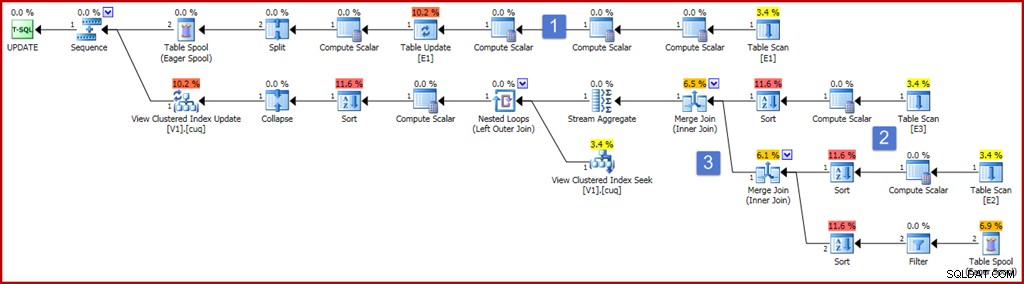
यह योजना अब काफी बड़ी और जटिल दिखती है, लेकिन अधिकांश तत्व ठीक वैसे ही हैं जैसे हम पहले ही देख चुके हैं। प्रमुख अंतर हैं:
- योजना की शीर्ष शाखा में कई अतिरिक्त कंप्यूट स्केलर ऑपरेटर शामिल हैं। इन्हें अधिक सघन रूप से व्यवस्थित किया जा सकता है, लेकिन अनिवार्य रूप से वे गैर-समूहीकरण स्तंभों के पूर्व-अद्यतन मूल्यों को पकड़ने के लिए मौजूद हैं। तालिका अद्यतन के बाईं ओर कंप्यूट स्केलर, ISNULL प्रोजेक्शन लागू होने के साथ कॉलम "a" के अद्यतन-पश्चात मान को कैप्चर करता है।
- योजना के इस क्षेत्र में नए कंप्यूट स्केलर प्रत्येक स्रोत तालिका पर ISNULL अभिव्यक्ति द्वारा उत्पादित मूल्य की गणना करते हैं। सामान्य तौर पर, दृश्य में सम्मिलित तालिकाओं पर अनुमानों को यहां कंप्यूट स्केलर्स द्वारा दर्शाया जाएगा। योजना के इस क्षेत्र में प्रकार विशुद्ध रूप से मौजूद हैं क्योंकि ऑप्टिमाइज़र ने लागत कारणों के लिए मर्ज जॉइन रणनीति को चुना है (याद रखें, मर्ज के लिए जॉइन-की सॉर्टेड इनपुट की आवश्यकता होती है)।
- दो जॉइन ऑपरेटर नए हैं, और केवल व्यू डेफिनिशन में जॉइन को लागू करते हैं। ये जॉइन हमेशा स्ट्रीम एग्रीगेट से पहले दिखाई देते हैं जो दृश्य पर परिवर्तनों के वृद्धिशील प्रभाव की गणना करता है। ध्यान दें कि आधार तालिका में परिवर्तन के परिणामस्वरूप एक पंक्ति हो सकती है जो शामिल होने के मानदंडों को पूरा करती थी और अब शामिल नहीं हो रही है, और इसके विपरीत। इन सभी संभावित जटिलताओं को स्ट्रीम एग्रीगेट द्वारा सही ढंग से संभाला जाता है (अनुक्रमित दृश्य प्रतिबंधों को देखते हुए) जॉइन किए जाने के बाद प्रति दृश्य कुंजी परिवर्तनों का सारांश तैयार करता है।
अंतिम विचार
वह अंतिम योजना अनुक्रमित दृश्य को बनाए रखने के लिए बहुत अधिक पूर्ण टेम्पलेट का प्रतिनिधित्व करती है, हालांकि दृश्य में गैर-अनुक्रमित अनुक्रमणिका के अतिरिक्त अतिरिक्त ऑपरेटरों को दृश्य अद्यतन ऑपरेटर के आउटपुट से अलग कर दिया जाएगा। एक अतिरिक्त स्प्लिट के अलावा (और एक क्रमबद्ध और संक्षिप्त संयोजन यदि दृश्य की गैर-अनुक्रमित अनुक्रमणिका अद्वितीय है), इस संभावना के बारे में कुछ खास नहीं है। बेस टेबल क्वेरी में आउटपुट क्लॉज जोड़ने से कुछ दिलचस्प अतिरिक्त ऑपरेटर भी बन सकते हैं, लेकिन फिर से, ये विशेष रूप से अनुक्रमित दृश्य रखरखाव के लिए विशेष नहीं हैं।
संपूर्ण समग्र रणनीति को संक्षेप में प्रस्तुत करने के लिए:
- आधार तालिका परिवर्तन सामान्य रूप से लागू होते हैं; पूर्व-अद्यतन मान कैप्चर किए जा सकते हैं।
- अपडेट को डिलीट/इन्सर्ट पेयर में बदलने के लिए स्प्लिट ऑपरेटर का इस्तेमाल किया जा सकता है।
- एक उत्सुक स्पूल आधार तालिका परिवर्तन जानकारी को अस्थायी भंडारण में सहेजता है।
- अद्यतन बेस टेबल (जिसे स्पूल से पढ़ा जाता है) को छोड़कर, व्यू में सभी टेबल एक्सेस किए जाते हैं।
- दृश्य में अनुमानों को कंप्यूट स्केलर्स द्वारा दर्शाया जाता है।
- दृश्य में फ़िल्टर लागू होते हैं। फिल्टर को स्कैन में धकेला जा सकता है या अवशिष्ट के रूप में खोजा जा सकता है।
- दृश्य में निर्दिष्ट जॉइन निष्पादित किए जाते हैं।
- क्लस्टर व्यू कुंजी द्वारा समूहीकृत शुद्ध वृद्धिशील परिवर्तनों की गणना करता है।
- वृद्धिशील परिवर्तन सेट बाहरी दृश्य से जुड़ा हुआ है।
- एक कंप्यूट स्केलर प्रत्येक परिवर्तन के लिए एक एक्शन कोड (इन्सर्ट/अपडेट/डिलीट व्यू के खिलाफ) की गणना करता है, और डालने या अपडेट करने के लिए वास्तविक मानों की गणना करता है। कम्प्यूटेशनल लॉजिक एग्रीगेट के आउटपुट और बाहरी जॉइन के परिणाम पर आधारित है।
- परिवर्तनों को दृश्य कुंजी और क्रिया कोड क्रम में क्रमबद्ध किया जाता है, और उपयुक्त के रूप में अद्यतनों के लिए संक्षिप्त किया जाता है।
- आखिरकार, वृद्धिशील परिवर्तन दृश्य पर ही लागू होते हैं।
जैसा कि हमने देखा है, क्वेरी ऑप्टिमाइज़र के लिए उपलब्ध टूल का सामान्य सेट अभी भी योजना के स्वचालित रूप से जेनरेट किए गए हिस्सों पर लागू होता है, जिसका अर्थ है कि उपरोक्त चरणों में से एक या अधिक चरणों को सरल, रूपांतरित या पूरी तरह से हटाया जा सकता है। हालांकि, योजना का मूल आकार और संचालन बरकरार है।
यदि आप कोड उदाहरणों के साथ अनुसरण कर रहे हैं, तो आप सफाई के लिए निम्न स्क्रिप्ट का उपयोग कर सकते हैं:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;