अपडेट करें:Q2'16 :नीचे वर्णित आईआरआई वर्कबेंच में डेटा डिस्कवरी मेनू समूह में डेटाबेस प्रोफाइलिंग विज़ार्ड के अतिरिक्त, आईआरआई ने मजबूत डेटा वर्गीकरण पेश किया है जो डेटा क्लास लाइब्रेरी के माध्यम से बहु-स्रोत डेटा परिवर्तन और सुरक्षा के लिए फ़ील्ड नियमों के अनुप्रयोग को सक्षम बनाता है। Q2'18 अपडेट करें :IRI ने एक साथ कई तालिकाओं में PII मिलान करने वाले RegEx या शाब्दिक मानों को खोजने के लिए एक स्कीमा-वाइड पैटर्न खोज विज़ार्ड भी पेश किया है। Q2'19 अपडेट करें :IRI अब इंटर/इंट्रा-स्कीमा डेटा क्लास सर्चिंग भी प्रदान करता है और उपयोगकर्ताओं के लिए मास्किंग IRI FieldShield या Voracity. और, IRI ने इस लेख को सिर्फ यह दिखाने के लिए प्रकाशित किया है कि नीचे दिए गए DB प्रोफाइलिंग परिणाम स्प्लंक में कैसे प्रदर्शित होते हैं।
आज व्यवसाय के अधिक पहलुओं से अधिक डेटा प्राप्त होने के साथ, इन संग्रहों की गुणवत्ता, मात्रा और सुरक्षा सुनिश्चित करने के लिए इसकी सामग्री और प्रकृति के बारे में आसान जागरूकता महत्वपूर्ण है। डेटा प्रोफाइलिंग एक आवश्यक खोज प्रक्रिया है जो आपके रिपॉजिटरी में डेटा का विश्लेषण करने, वर्गीकृत करने, शुद्ध करने, एकीकृत करने, मास्क करने और रिपोर्ट करने में आपकी सहायता करती है।
डार्क और स्ट्रक्चर्ड डेटा डिस्कवरी (और मेटाडेटा डेफिनिशन) विजार्ड के अलावा, एक्लिप्स में क्रॉस-डीबी ई-आर डायग्रामिंग के साथ, आईआरआई वर्कबेंच में नया क्रॉस-डीबी प्रोफाइलिंग टूल उपयोगकर्ताओं को डेटाबेस डेटा की संरचना और पूर्णता की जांच करने की अनुमति देता है, और यह सत्यापित करता है कि उचित डेटा सही स्थानों पर संग्रहीत किया जा रहा है। इस लेख में, हम इस टूल की जांच करेंगे, और दिखाएंगे कि यह तालिका-मूल्य खोज परिणाम और सांख्यिकीय मेटाडेटा कैसे वितरित करता है।
डेटाबेस प्रोफाइलर तक पहुंचने के लिए, उस तालिका पर नेविगेट करें जिसे आप डेटा स्रोत एक्सप्लोरर में एक्सेस करना चाहते हैं। टेबल पर राइट-क्लिक करें और आईआरआई विकल्प पर माउस ले जाएं। दिखाई देने वाले मेनू पर, नई डेटाबेस प्रोफ़ाइल चुनें ।
पहले विज़ार्ड पृष्ठ पर, कार्य का स्थान और गंतव्य सेट करें, और प्रोफ़ाइल रिपोर्ट के आउटपुट को .csv या .txt फ़ाइल, या दोनों के रूप में चुनें।
- .csv प्रारूप नई तालिकाओं और डेटाबेस में आयात करने के लिए उपयोगी है, जबकि
- .txt प्रारूप एक पूर्व-प्रारूपित रिपोर्ट है, जो परिणामों की शीघ्रता से समीक्षा करने के लिए उपयोगी है।
सांख्यिकीय रूपरेखा जानकारी
विज़ार्ड का अगला भाग दो तालिकाओं के साथ दिखाई देगा:
- शीर्ष तालिका डेटाबेस में सभी तालिकाओं की एक सूची है, जिसमें तालिका डिफ़ॉल्ट रूप से हाइलाइट किए गए विज़ार्ड को लॉन्च करती है।
- यह चेक बॉक्स आपको अपने डेटाबेस में प्रत्येक तालिका और पंक्ति को स्कैन करने के लिए एक-क्लिक विकल्प की अनुमति देता है।

- नीचे की तालिका प्रोफाइलिंग विकल्पों को दिखाती है, उसके बाद हाइलाइट की गई तालिका के कॉलम जिसमें आप विकल्पों को निष्पादित करना चुनते हैं।

सूची में किसी भी तालिका पर क्लिक करें जिसे आप देखना और प्रोफाइल करना चाहते हैं। विकल्प मैट्रिक्स स्वचालित रूप से चयनित तालिका के स्तंभों का प्रतिनिधित्व करने के लिए बदल जाएगा। देखने के विकल्पों को संभालने के कई तरीके हैं:
- सभी विकल्पों के लिए, तालिका में शीर्ष चेक बॉक्स पर क्लिक करें, जिसे सभी लेबल किया गया है, और सभी मेटाडेटा रिपोर्ट किए जाएंगे।
- केवल बुनियादी विकल्पों के लिए (गिनती और मान), मूलभूत लेबल वाले चेक बॉक्स का चयन करें।
- केवल लंबाई के विकल्पों (मान लंबाई) के लिए, लंबाई लेबल वाला चेक बॉक्स चुनें।
यदि आपकी तालिका में कई कॉलम हैं और उन सभी के लिए एक ही विकल्प चुनना चाहते हैं, तो विकल्प नाम पर ही क्लिक करें, और सभी कॉलम में वह विकल्प चयनित होगा। आप विकल्प में कॉलम को अचयनित कर सकते हैं।
सब कुछ सेट हो जाने पर, समाप्त करें . क्लिक करें और फिर आपके लिए प्रोफ़ाइल तैयार की जाएगी।
अभिव्यक्ति खोज
विकल्प तालिका में एक अद्वितीय विकल्प -अभिव्यक्ति खोज- है। यह विकल्प आपको विभिन्न प्रकार के खोज विकल्पों में कॉलम खोजने की अनुमति देता है। ये विकल्प हैं:
- रेगुलर एक्सप्रेशन (पैटर्न खोज)। यह पता लगाता है और गणना करता है कि कोई मान किसी खोज पैटर्न के प्रारूप से कितनी बार मेल खाता है।
- फजी स्ट्रिंग। यह विकल्प आपको आपके द्वारा दर्ज की गई स्ट्रिंग के समान खोजने और खोज शर्तों को चुनने या निर्दिष्ट करने की अनुमति देता है।
- मान फ़ाइल। यह विकल्प आपको एक सेट फ़ाइल में प्रत्येक स्ट्रिंग के लिए एक स्ट्रिंग की तुलना करने देता है और प्रत्येक स्ट्रिंग की गणना करता है जिसमें एक मिलान होता है।
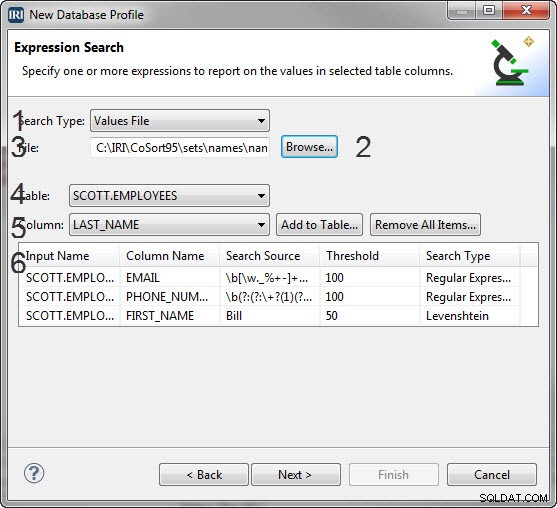
अभिव्यक्ति खोज पृष्ठ में 6 महत्वपूर्ण खंड हैं
- खोज के प्रकार का चयन करने के लिए एक खोज प्रकार कॉम्बो बॉक्स।
- विकल्प समूह जो चयनित खोज प्रकार के आधार पर बदलता है
- रेगुलर एक्सप्रेशन:इसमें दो बटन होते हैं; ब्राउज़ करें जो मौजूदा रेगुलर एक्सप्रेशन को ब्राउज़ करता है, और क्रिएट… जो नए रेगुलर एक्सप्रेशन बनाने की अनुमति देता है।
- फ़ज़ी स्ट्रिंग:में एक काउंटिंग बॉक्स होता है जो फ़ज़ी सर्च की दहलीज को निर्दिष्ट करता है (स्ट्रिंग्स को एक मैच के रूप में कितना करीब माना जाना चाहिए), और उपयोग करने के लिए फ़ज़ी सर्च एल्गोरिथम का चयन करने के लिए एक कॉम्बो बॉक्स।
- मान फ़ाइल:एक बटन है ब्राउज़ करें... जो आपको मूल्य खोज के लिए उपयोग करने के लिए सेट फ़ाइल की खोज करने देता है।
- एक टेक्स्ट बॉक्स जहां आप अपनी खोज के लिए डेटा दर्ज करेंगे।
- तालिकाओं की एक ड्रॉप-डाउन सूची जिसमें आप व्यंजक खोज लागू कर सकते हैं।
- स्तंभों की एक ड्रॉप-डाउन सूची जिसमें आप अभिव्यक्ति खोज लागू कर सकते हैं।
- एक तालिका जो आपके द्वारा बनाई गई खोजों को सूचीबद्ध करती है जो प्रोफाइलर द्वारा की जाएंगी।
रेगुलर एक्सप्रेशन फ़िल्टर बनाने के लिए:
- खोज प्रकार कॉम्बो से, रेगुलर एक्सप्रेशन select चुनें ।
- ब्राउज़ करें क्लिक करें को (सहेजे गए भावों की आपकी लाइब्रेरी), या बनाएं . पर क्लिक करें स्तंभ मानों की खोज में उपयोग करने के लिए एक नियमित अभिव्यक्ति निर्दिष्ट करने के लिए।
- तालिका मेनू में, उस तालिका का चयन करें जिसमें फ़िल्टर करने के लिए स्तंभ है।
- कॉलम मेनू में, उस कॉलम का चयन करें जिस पर रेगुलर एक्सप्रेशन लागू किया जाना चाहिए।
- तालिका में जोड़ेंक्लिक करें , और नीचे दी गई तालिका में एक आइटम दिखाई देगा जिसमें फ़ाइल का नाम, स्तंभ का नाम, खोज स्रोत, सीमा, और रेगुलर एक्सप्रेशन लेबल शामिल है जो फ़िल्टर बनाते हैं।
- इस प्रक्रिया को प्रत्येक कॉलम के लिए दोहराएं जिसमें आप एक फ़िल्टर जोड़ना चाहते हैं। यदि इस प्रक्रिया को व्यावहारिक बनाने के लिए आपके पास बहुत अधिक स्तंभ हैं, तो भी आप इसके बजाय इस विज़ार्ड का उपयोग करके — एक संपूर्ण डेटाबेस स्कीमा में अपने पैटर्न से मिलान करने वाले डेटा के लिए — स्वचालित रूप से एकाधिक स्तंभों और तालिकाओं को स्कैन कर सकते हैं।
फ़ज़ी स्ट्रिंग खोज बनाने के लिए:
- खोज प्रकार कॉम्बो से, फ़ज़ी स्ट्रिंग चुनें ।
- खोज के लिए उपयोग करने के लिए स्ट्रिंग टाइप करें।
- लौटने के लिए परिणामों की संख्या का चयन करें (यह विकल्प फ़ज़ी सर्च का चयन करने पर दिखाई देगा)।
- उपयोग करने के लिए फ़ज़ी खोज प्रकार चुनें (फ़ज़ी स्ट्रिंग चयनित होने पर यह विकल्प दिखाई देगा)।
- तालिका मेनू में, फ़ाइल का चयन करें जिसमें अस्पष्ट खोज के लिए स्तंभ शामिल है।
- कॉलम मेनू में, उस कॉलम का चयन करें जिस पर फ़ज़ी खोज की जानी चाहिए।
- तालिका में जोड़ेंक्लिक करें , और नीचे दी गई तालिका में एक आइटम दिखाई देगा जिसमें फ़ाइल का नाम, कॉलम का नाम, खोज स्रोत, थ्रेशोल्ड और निष्पादित की जाने वाली फ़ज़ी खोज का खोज प्रकार शामिल है।
- इस प्रक्रिया को प्रत्येक कॉलम के लिए दोहराएं जहां आप एक अस्पष्ट स्ट्रिंग खोज करना चाहते हैं।
मान फ़ाइल खोज बनाने के लिए:
- खोज प्रकार कॉम्बो से, मान फ़ाइल select चुनें ।
- ब्राउज़ करें क्लिक करें एक सेट फ़ाइल का चयन करने के लिए जिसके खिलाफ कॉलम की जांच की जाएगी।
- तालिका मेनू में, उस तालिका का चयन करें जिसमें फ़िल्टर करने के लिए स्तंभ है।
- कॉलम मेन्यू में, वह कॉलम चुनें जिस पर रेगुलर एक्सप्रेशन लागू किया जाना चाहिए.
- तालिका में जोड़ेंक्लिक करें , और नीचे दी गई तालिका में एक आइटम दिखाई देगा जिसमें फ़ाइल का नाम, स्तंभ नाम, खोज स्रोत, सीमा और मान सूची खोज लेबल शामिल है जो फ़िल्टर बनाते हैं।
संदर्भात्मक सत्यनिष्ठा जांच
विकल्प तालिका में एक अन्य विकल्प है -चेक रेफ़रेंशियल इंटीग्रिटी-। यह विकल्प प्रोफाइलर को एक या अधिक कॉलम की तुलना दूसरे कॉलम से करने की अनुमति देता है, और यह निर्धारित करता है कि कॉलम में संदर्भात्मक अखंडता है या नहीं। इस फ़ंक्शन का उपयोग करने के लिए, संदर्भात्मक अखंडता की तुलना करने के लिए कॉलम पर -चेक रेफ़रेंशियल इंटीग्रिटी- बॉक्स चेक करें। अगला बटन सक्रिय होगा और आपको संदर्भात्मक अखंडता जांच के लिए पैरामीटर निर्दिष्ट करने की अनुमति देगा (विवरण के लिए नीचे देखें)।
यदि आपने अपने किसी भी कॉलम के लिए रेफरेंशियल इंटिग्रिटी चेक करें विकल्प चुना है, तो अगला . पर क्लिक करें रेफ़रेंशियल इंटिग्रिटी चेक पेज पर जाने के लिए। इस पृष्ठ में निम्नलिखित विशेषताएं हैं:
- दो कॉम्बो बॉक्स, एक प्राथमिक कुंजी वाली तालिका का चयन करने के लिए, दूसरा प्राथमिक कुंजी कॉलम निर्दिष्ट करने के लिए है।
- दो कॉम्बो बॉक्स, एक तालिका का चयन करने के लिए जिसमें विदेशी कुंजी है, दूसरा विदेशी कुंजी कॉलम निर्दिष्ट करने के लिए। प्राथमिक कुंजी की तुलना में विदेशी कुंजी की सूची में विदेशी कुंजी जोड़ने के लिए एक बटन भी है।
- नीचे दी गई सूची में प्राथमिक और विदेशी कॉलम जोड़ने के लिए एक सत्यनिष्ठा जांच बनाएं बटन।
- एक सूची जो प्रोफाइलर द्वारा की जाने वाली सभी संदर्भात्मक अखंडता जांचों को संग्रहीत करती है।

रेफरेंशियल अखंडता जांच बनाने के लिए:
- प्राथमिक कुंजी कॉलम के अंतर्गत तालिका कॉम्बो बॉक्स में, उस तालिका का चयन करें जिसमें प्राथमिक कुंजी है।
- प्राथमिक कुंजी कॉलम के अंतर्गत कॉलम कॉम्बो बॉक्स में, प्राथमिक कुंजी का चयन करें।
- विदेशी कुंजी कॉलम के अंतर्गत तालिका कॉम्बो बॉक्स में, वह तालिका चुनें जिसमें विदेशी कुंजी है।
- विदेशी कुंजी कॉलम के अंतर्गत कॉलम कॉम्बो बॉक्स में, विदेशी कुंजी चुनें।
- विदेशी कुंजी सूची में जोड़ें बटन पर क्लिक करें…
- प्राथमिक कुंजी के विरुद्ध प्रत्येक विदेशी कुंजी की जांच के लिए चरण 3-5 दोहराएं
- अखंडता जांच बनाएं बटन पर क्लिक करें...
- उपरोक्त प्रक्रियाओं को प्रत्येक संदर्भित अखंडता जांच के लिए दोहराएं।
नमूना प्रोफ़ाइल आउटपुट

.csv लिब्रे ऑफिस में प्रदर्शित / .txt एडिटपैड लाइट में प्रदर्शित