यह लेख 2UDA के साथ मशीन लर्निंग क्षमताओं का उपयोग करने के लिए चरण-दर-चरण मार्गदर्शिका देता है। लेख में, हम यह अनुमान लगाने के लिए जानवरों के उदाहरण का उपयोग करेंगे कि क्या वे स्तनधारी, पक्षी, मछली या कीड़े हैं।
सॉफ़्टवेयर संस्करण
हम मशीन लर्निंग मॉडल को लागू करने के लिए 2UDA संस्करण 11.6-1 का उपयोग करने जा रहे हैं। 2UDA संस्करण 11.6-1 जोड़ती है:
- पोस्टग्रेएसक्यूएल 11.6
- नारंगी 3.23.0
आप 2UDA का नवीनतम संस्करण यहां पा सकते हैं।
चरण 1:प्रशिक्षण डेटासेट को PostgreSQL में लोड करें
हमारे मॉडल को प्रशिक्षित करने के लिए उपयोग किया जाने वाला नमूना डेटासेट आधिकारिक ऑरेंज गिटहब भंडार यहां उपलब्ध है।
प्रशिक्षण डेटा को PostgreSQL तालिकाओं में लोड करने के लिए इन चरणों का पालन करें:
- psql, OmniDB या किसी अन्य टूल से PostgreSQL से कनेक्ट करें जिससे आप परिचित हैं।
- हमारे प्रशिक्षण डेटा को संग्रहीत करने के लिए एक तालिका बनाएं . यहां इसे ट्रेनिंग_डेटा नाम दिया गया है।
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- कॉपी क्वेरी के माध्यम से तालिका में प्रशिक्षण डेटा डालें। COPY क्वेरी निष्पादित करने से पहले सुनिश्चित करें कि PostgreSQL को डेटा फ़ाइल पर पढ़ने की अनुमति की आवश्यकता है अन्यथा COPY ऑपरेशन विफल हो जाएगा।
नोट: कृपया सुनिश्चित करें कि आप एक टैब type टाइप करते हैं सीमांकक . के बाद सिंगल कोट्स के बीच की जगह कीवर्ड।
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
कृपया नीचे दिए गए प्रशिक्षण डेटासेट का स्क्रीनशॉट देखें
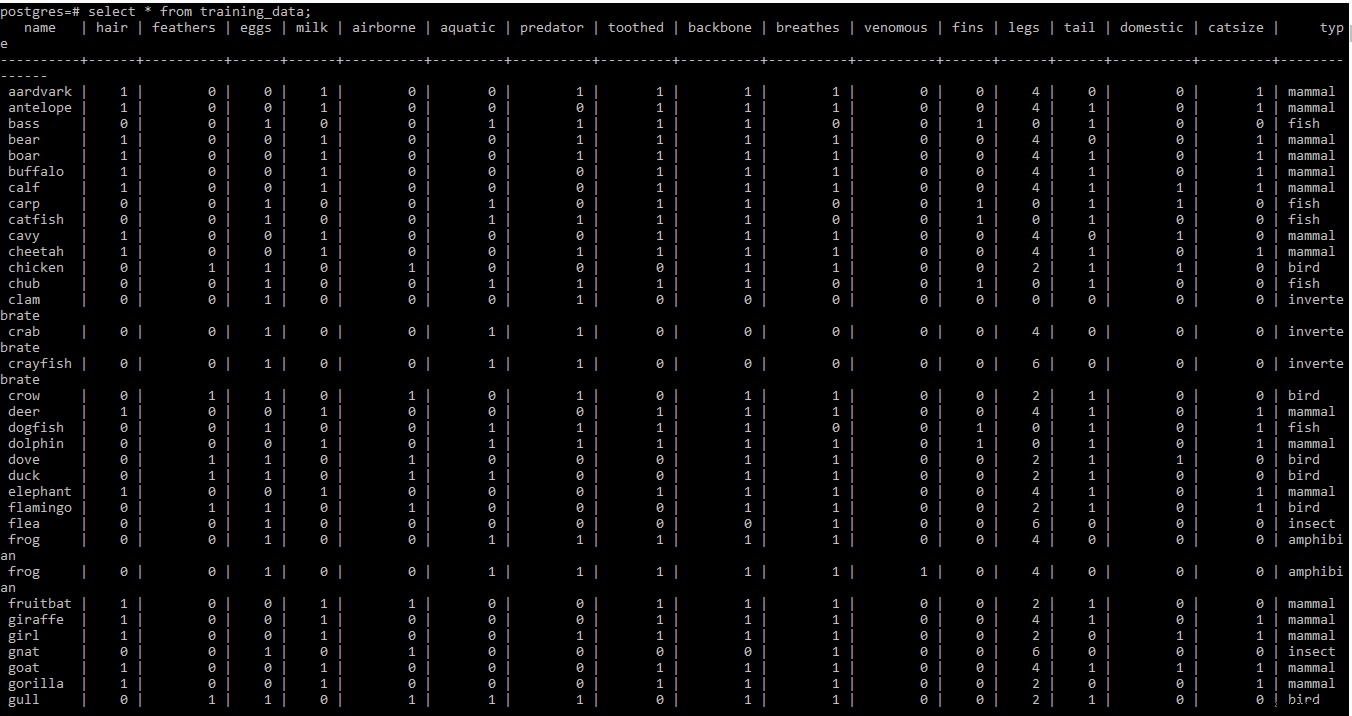
ध्यान दें: .टैब . में प्रशिक्षण डेटासेट की दो और तीन पंक्तियाँ फ़ाइल में कुछ मेटा जानकारी होती है। चूंकि इस समय इसकी आवश्यकता नहीं है, इसलिए इसे फ़ाइल से हटा दिया गया है।
चरण 2:ऑरेंज के साथ वर्कफ़्लो बनाएं
- डेस्कटॉप पर जाएं और ऑरेंज आइकन पर डबल क्लिक करें।
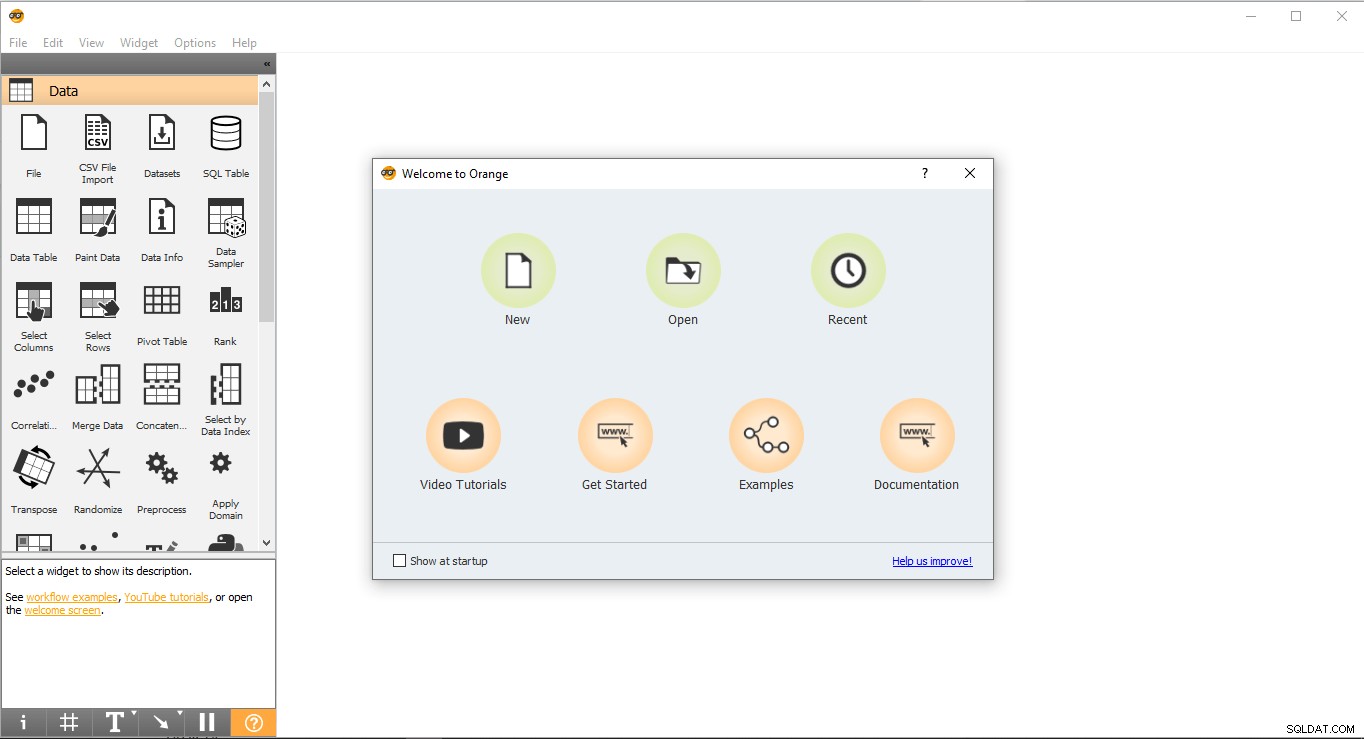
- स्टार्ट-अप पेज इस तरह दिखता है। नया Select चुनें विकल्प और यह एक रिक्त प्रोजेक्ट बनाएगा।

अब आप डेटासेट पर मशीन लर्निंग मॉडल लागू करने के लिए तैयार हैं।
चरण 3:डेटा को प्रशिक्षित करने के लिए मशीन लर्निंग मॉडल चुनें
इस लेख के लिए, k-निकटतम पड़ोसी (केएनएन) मशीन लर्निंग मॉडल का उपयोग डेटा को प्रशिक्षित करने के लिए किया जाता है। एक बार डेटा प्रशिक्षण प्रक्रिया पूरी हो जाने के बाद, अगले चरण में परीक्षण डेटा भविष्यवाणी . को पास कर दिया जाता है पूर्वानुमानों की सटीकता की जांच करने के लिए विजेट।
चरण 4:PostgreSQL से ऑरेंज में प्रशिक्षण डेटा आयात करें
इस प्रशिक्षण डेटासेट का उपयोग मशीन लर्निंग मॉडल को प्रशिक्षित करने के लिए किया जाएगा।
- खींचें और छोड़ें SQL तालिका डेटा . से विजेट मेन्यू।
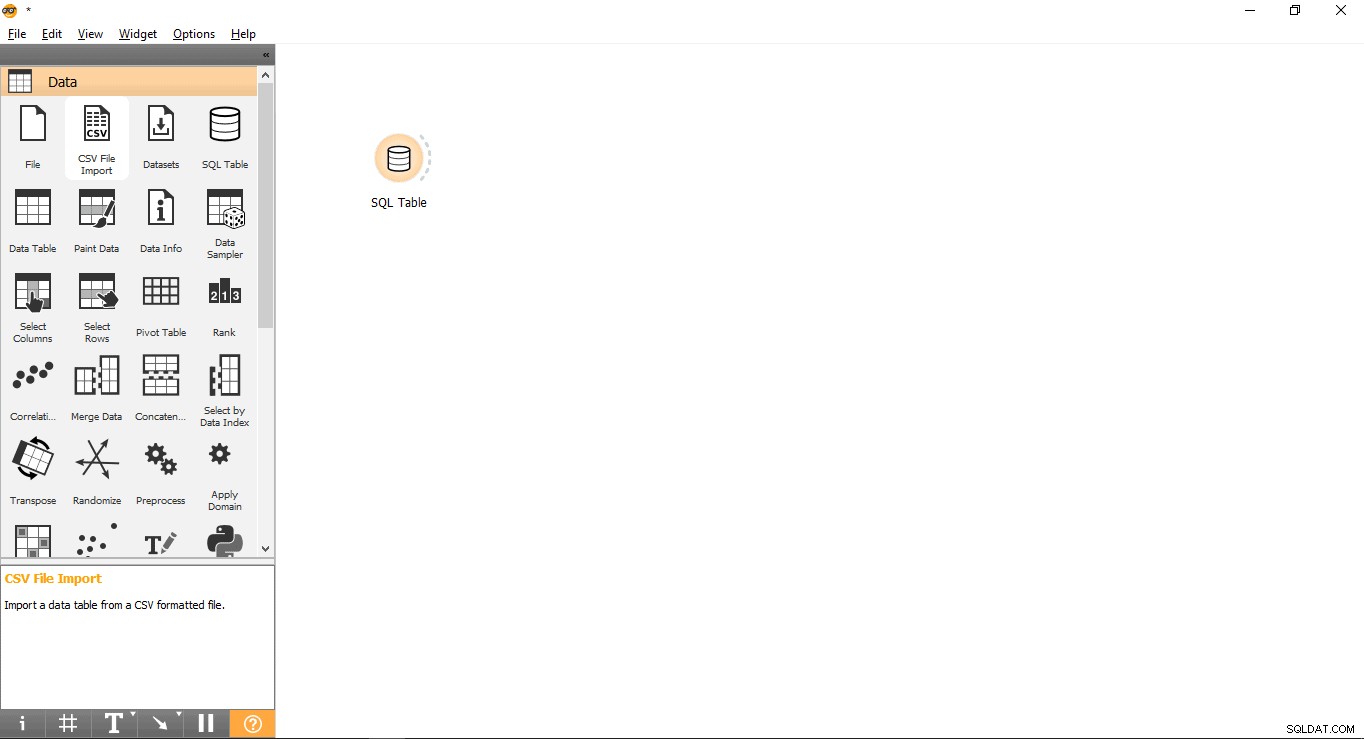
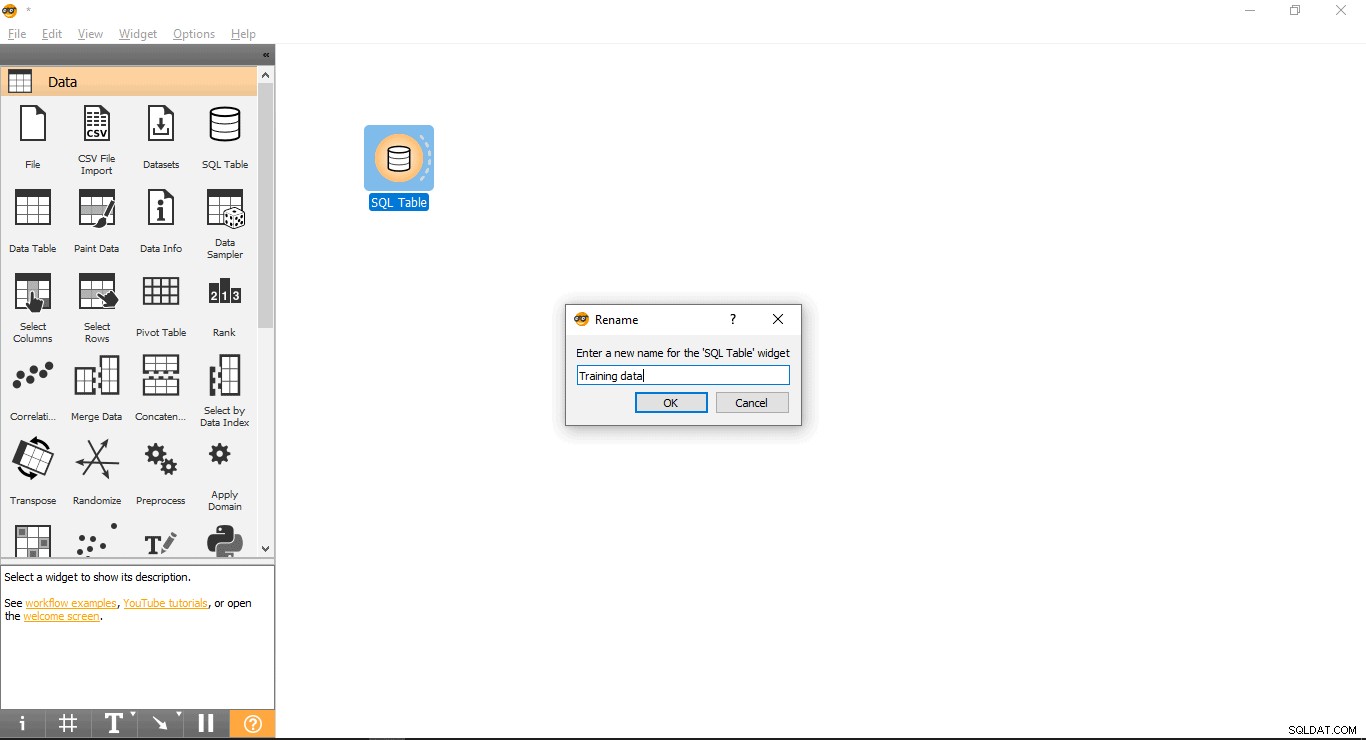
- विजेट का नाम बदलें (वैकल्पिक)
- SQL तालिका पर राइट-क्लिक करें विजेट.
- नाम बदलें चुनें .
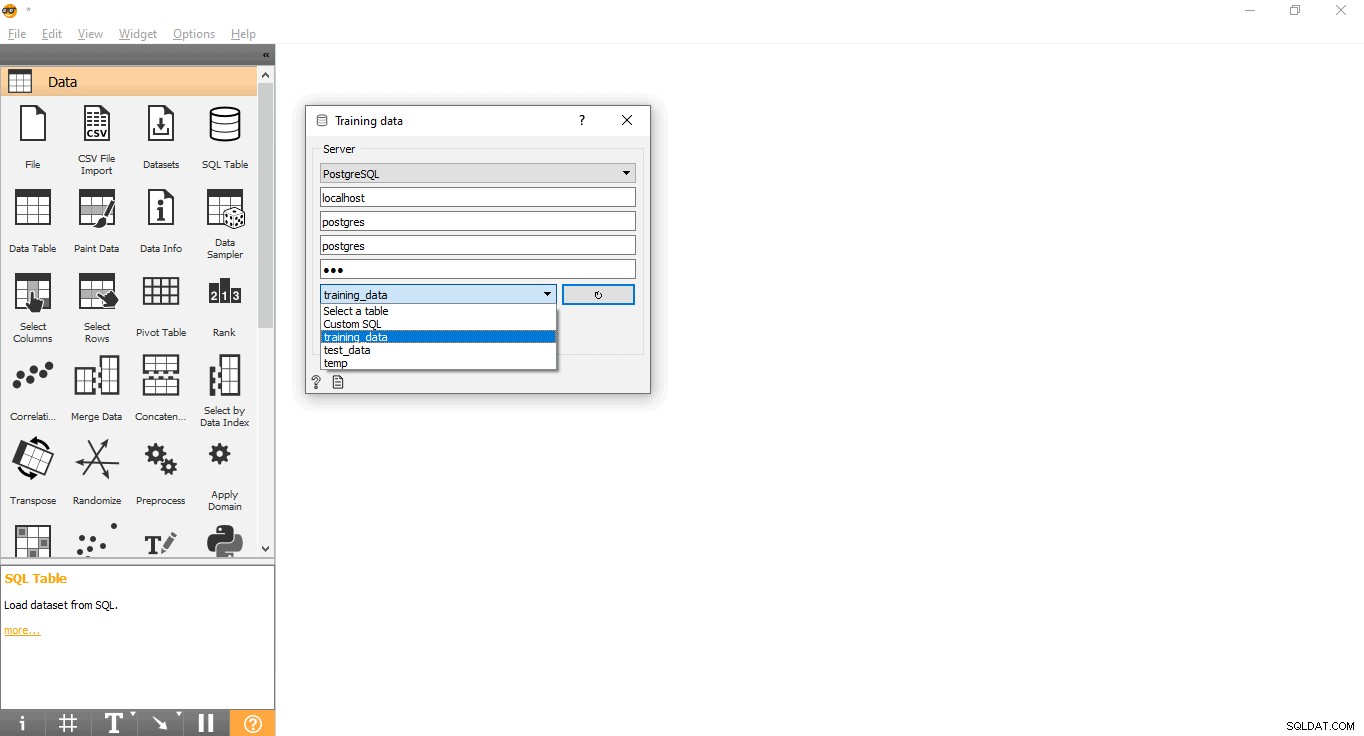
- प्रशिक्षण डेटासेट लोड करने के लिए PostgreSQL से कनेक्ट करें:
- प्रशिक्षण डेटा पर डबल क्लिक करें विजेट.
- PostgreSQL डेटाबेस से कनेक्ट करने के लिए क्रेडेंशियल दर्ज करें।
- दिए गए डेटाबेस से सभी उपलब्ध तालिकाओं को लोड करने के लिए पुनः लोड करें बटन दबाएं।
- ड्रॉप डाउन मेनू से ट्रेनिंग_डेटा तालिका चुनें और पॉप-अप बंद करें।
चरण 5:लक्ष्य कॉलम जोड़ें
यह चरण महत्वपूर्ण है क्योंकि मशीन लर्निंग मॉडल इस लक्ष्य चर/स्तंभ के लिए डेटा की भविष्यवाणी करने का प्रयास करेगा:
- खींचें और छोड़ें कॉलम चुनें डेटा . से विजेट मेनू।
- कॉलम चुनें पर डबल क्लिक करें विजेट.
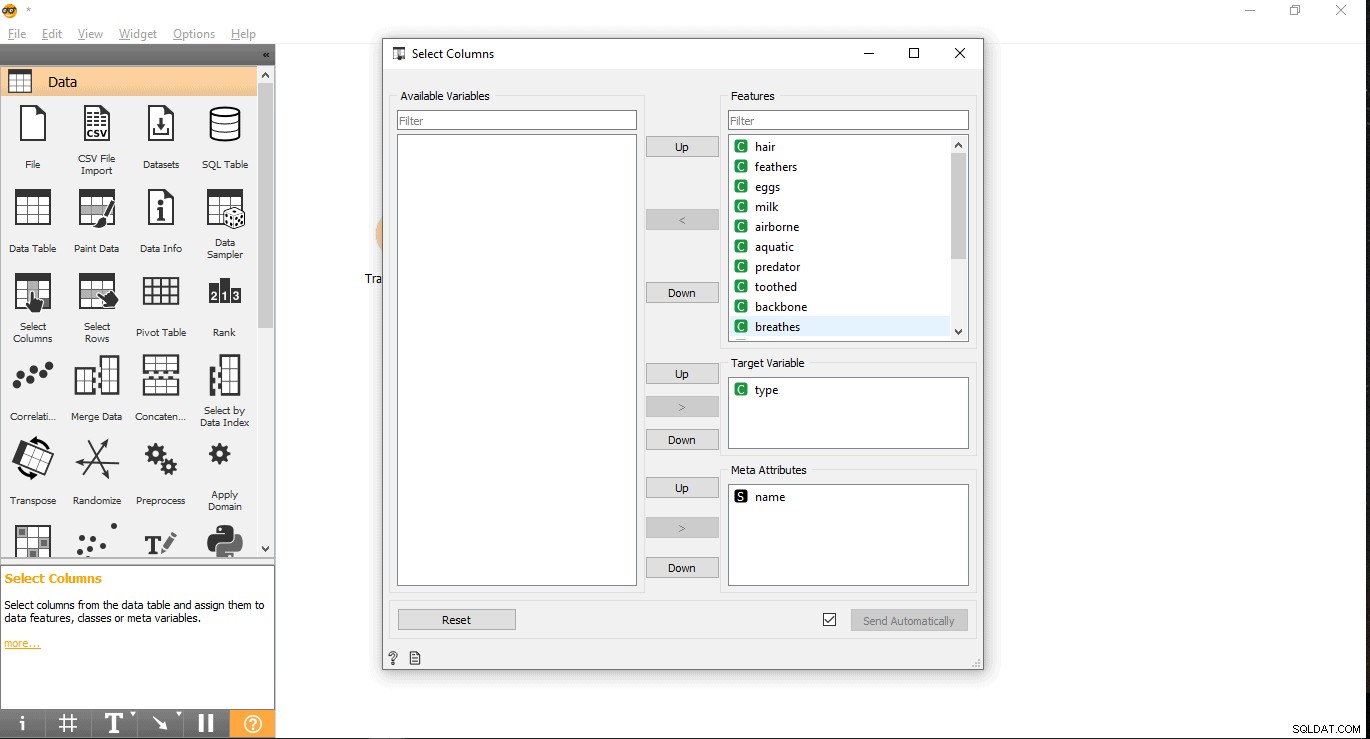
- सुविधाएँ लेबल के अंतर्गत अपना लक्ष्य स्तंभ खोजें। यहां, प्रकार का उपयोग किया जाता है लक्ष्य चर के रूप में क्योंकि हमें यह देखने की आवश्यकता है कि दिया गया जानवर किस प्रकार का है।
- इसे लक्ष्य चर के अंतर्गत खींचें और छोड़ें बॉक्स और पॉप-अप बंद करें।
चरण 6:कॉलम रैंकिंग
आप लक्ष्य कॉलम के साथ उनके सहसंबंध के अनुसार प्रशिक्षण चर/स्तंभों को रैंक या स्कोर कर सकते हैं।
- खींचें और छोड़ें रैंक डेटा . से विजेट मेनू।
- कॉलम चुनें . से एक लिंक लाइन बनाएं विजेट रैंक . के लिए विजेट।
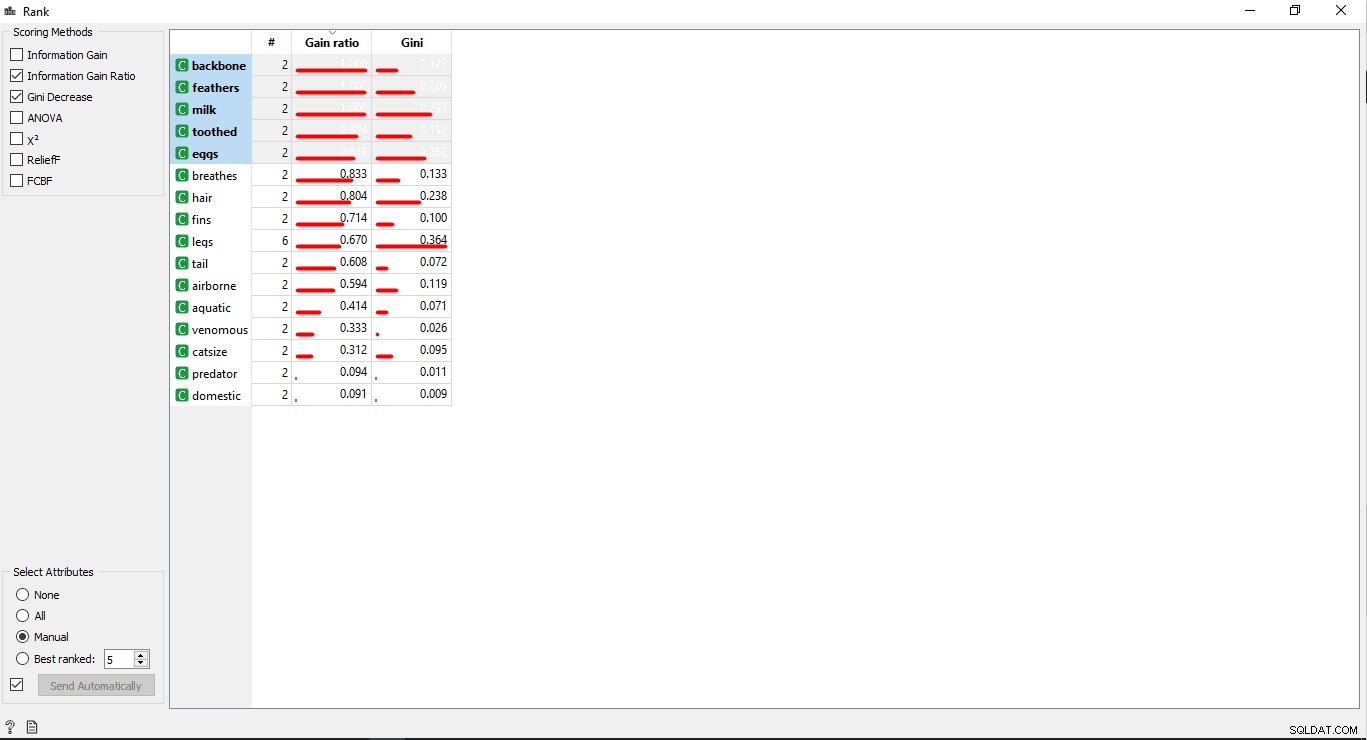
- रैंक पर डबल क्लिक करें प्रशिक्षण डेटा तालिका में सबसे अधिक संबंधित कॉलम देखने के लिए विजेट। यह डिफ़ॉल्ट रूप से शीर्ष 5 स्तंभों का चयन करेगा।
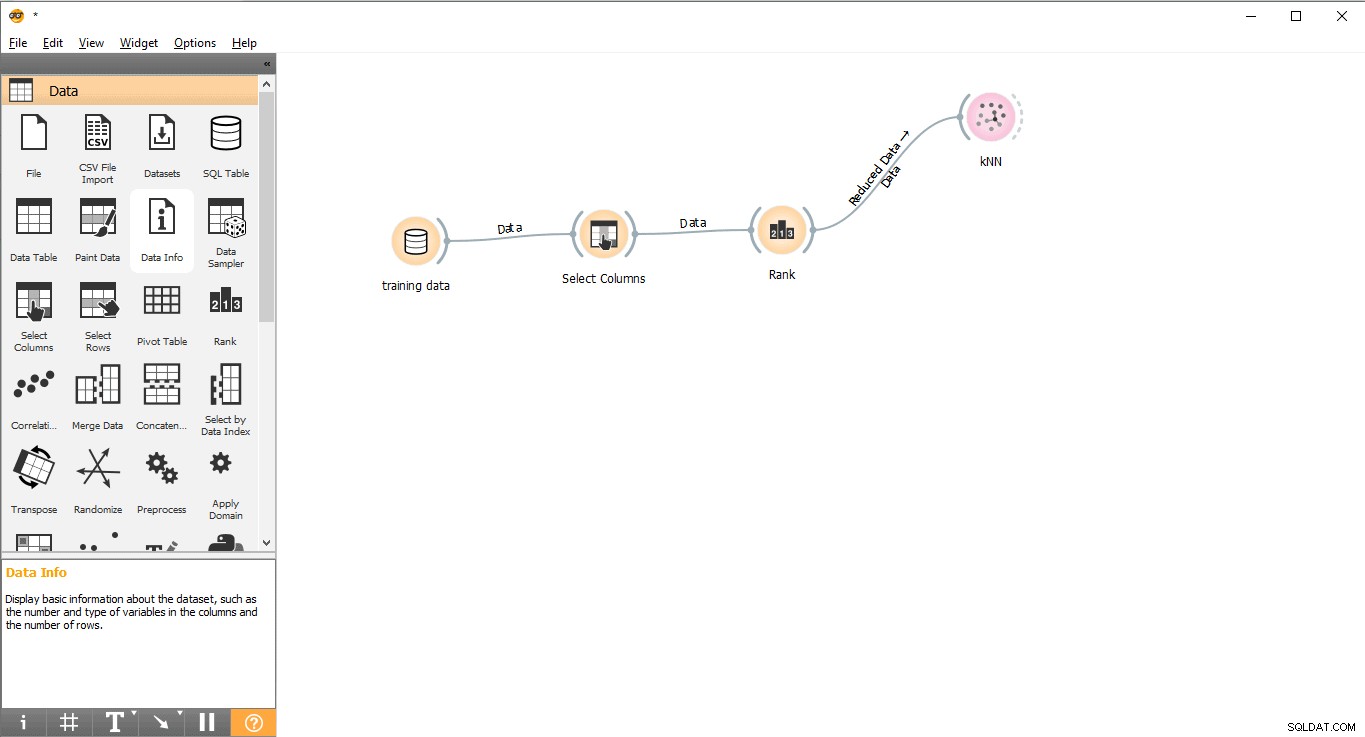
चरण 7:डेटा प्रशिक्षण
इस चरण में, मशीन लर्निंग मॉडल (केएनएन) को प्रशिक्षण डेटासेट के साथ प्रशिक्षित किया जाएगा। कृपया निम्नलिखित चरणों का पालन करें:
- खींचें और छोड़ें केएनएन मॉडल . से विजेट मेनू।
- रैंक . से एक लिंक लाइन बनाएं विजेट केएनएन . के लिए विजेट.
चरण 8:परीक्षण डेटासेट को PostgreSQL में लोड करें
भविष्यवाणियां करने के लिए एक अलग परीक्षण डेटासेट बनाया जाता है। कृपया परीक्षण डेटासेट को PostgreSQL तालिका में लोड करने के लिए चरणों का पालन करें।
- हमारे परीक्षण डेटा को संग्रहीत करने के लिए एक तालिका बनाएं . यहाँ इसे test_data नाम दिया गया है।
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- परीक्षण डेटा को कॉपी . के माध्यम से परीक्षण तालिका में सम्मिलित करें सवाल। निष्पादित करने से पहले कॉपी करें कृपया सुनिश्चित करें कि PostgreSQL को डेटा फ़ाइल पर पढ़ने की अनुमति की आवश्यकता है अन्यथा COPY ऑपरेशन विफल हो जाएगा।
नोट: कृपया सुनिश्चित करें कि आप एक टैब type टाइप करते हैं सीमांकक . के बाद एकल उद्धरणों के बीच का स्थान खोजशब्द। प्रश्न चिह्न जानबूझकर प्रकार . में लगाया गया है परीक्षण डेटासेट का कॉलम क्योंकि हमें अपने मशीन लर्निंग मॉडल के साथ किसी दिए गए जानवर के प्रकार का पता लगाने की आवश्यकता है।
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
कृपया परीक्षण डेटासेट का स्क्रीनशॉट नीचे देखें

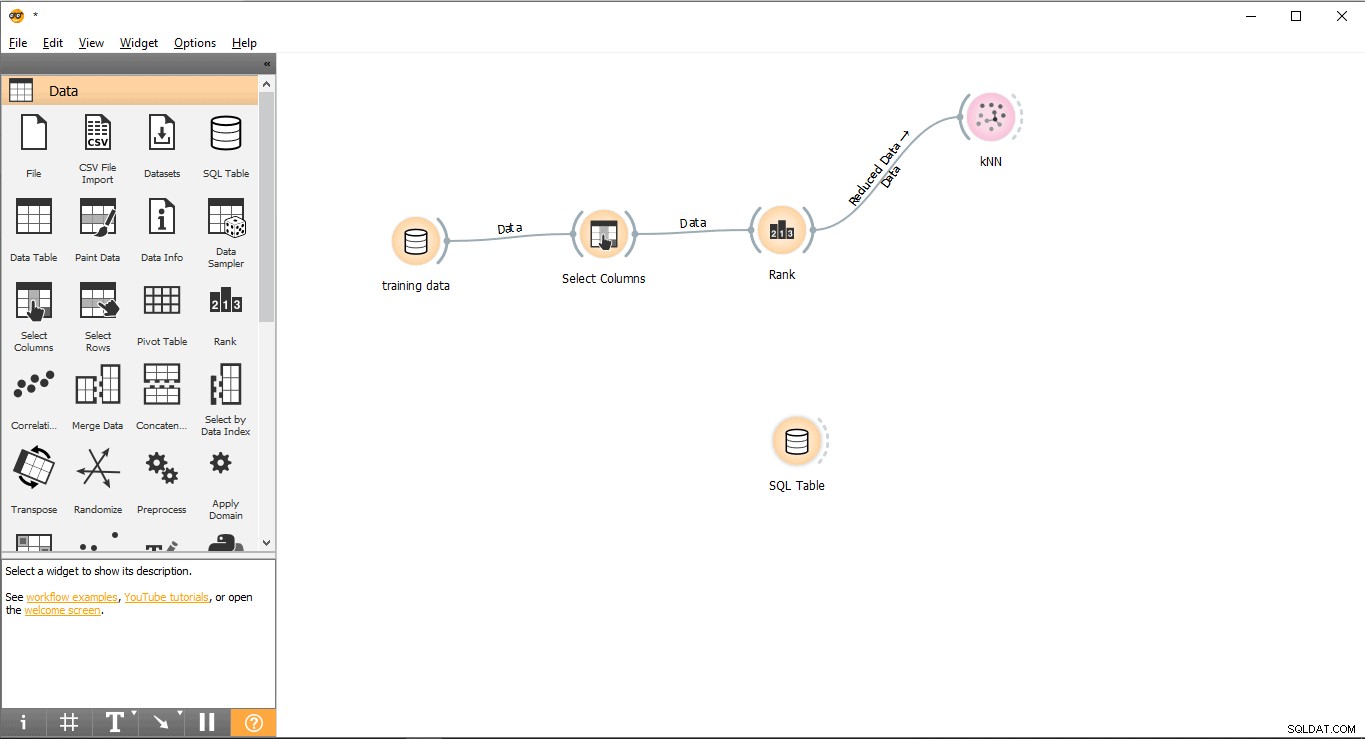
चरण 9:PostgreSQL से ऑरेंज में परीक्षण डेटा आयात करें
भविष्यवाणियों को लागू करने के लिए कृपया निम्नलिखित चरणों का पालन करें।
- खींचें और छोड़ें SQL तालिका डेटा . से विजेट मेन्यू।
- विजेट का नाम बदलें (वैकल्पिक)
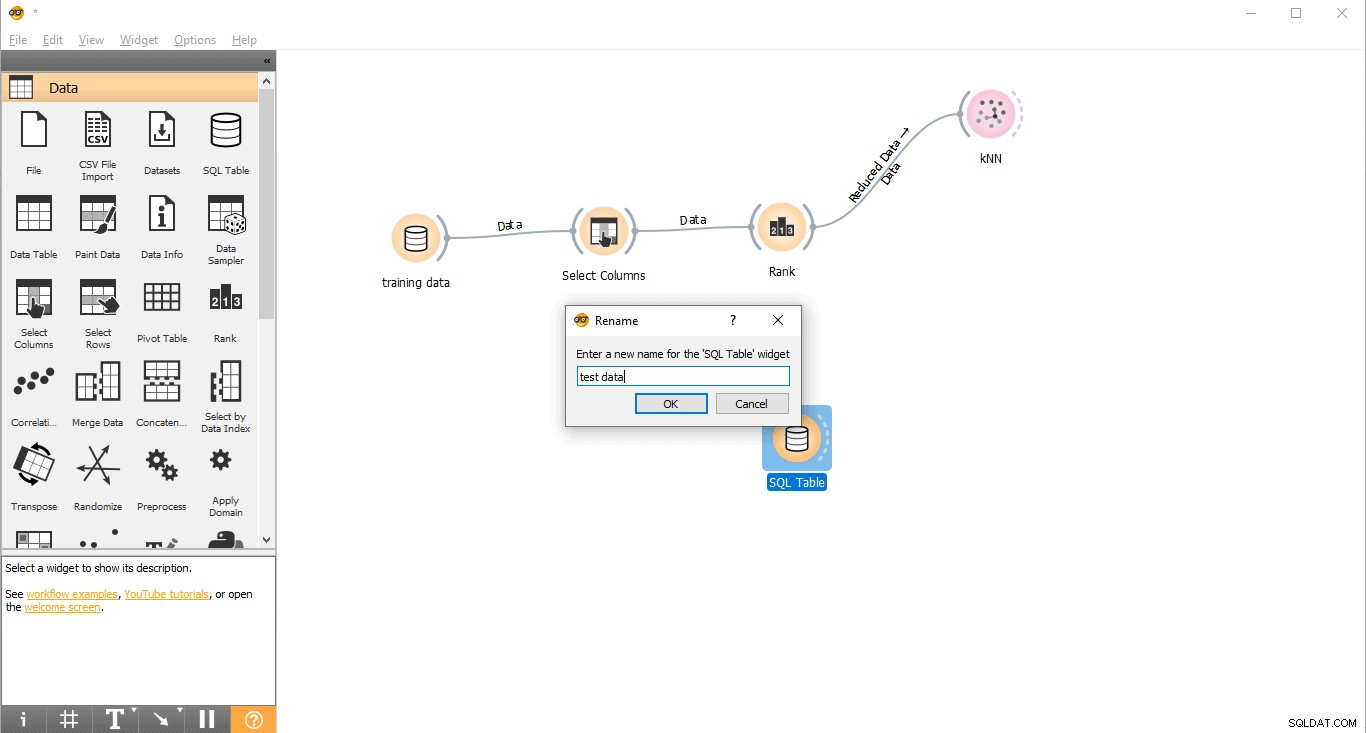
- SQL तालिका पर राइट-क्लिक करें विजेट.
- नाम बदलें चुनें .
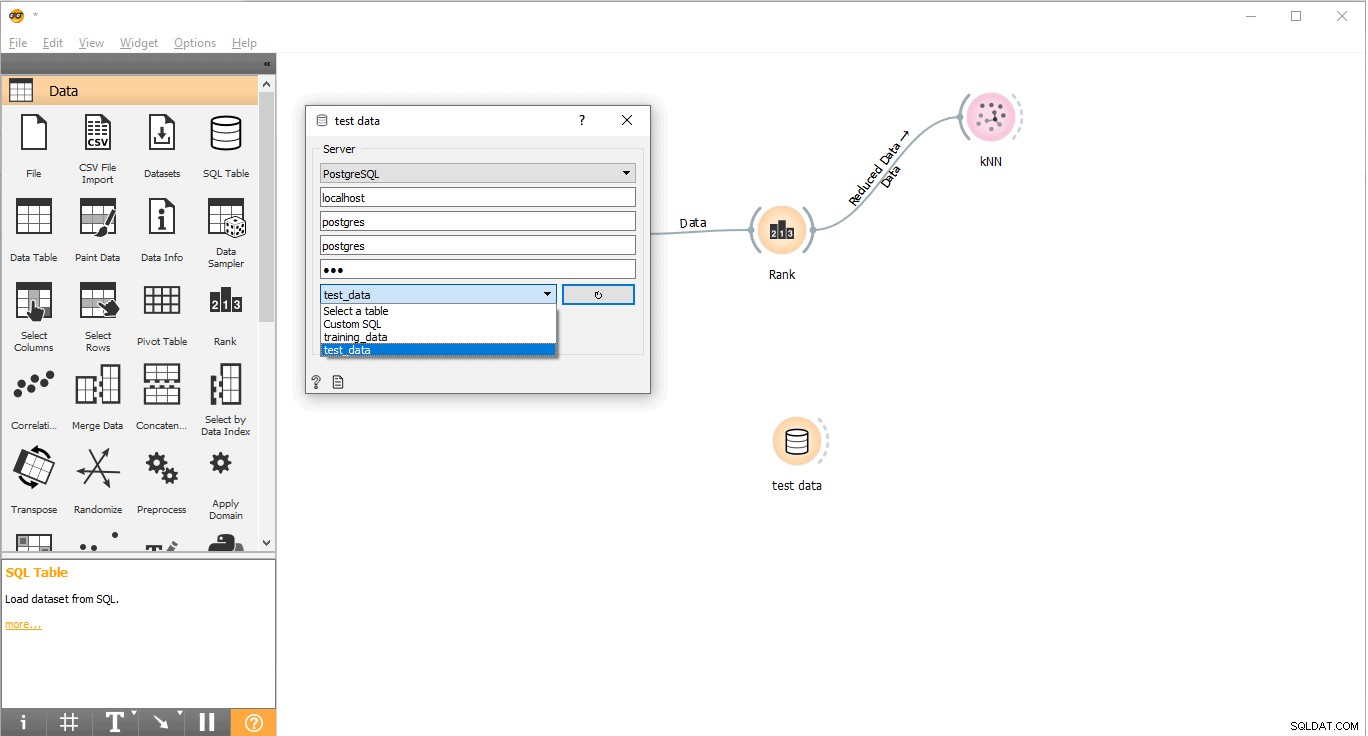
- परीक्षण डेटा लोड करने के लिए PostgreSQL से कनेक्ट करें।
- परीक्षण डेटा पर डबल क्लिक करें विजेट.
- इसे परीक्षण डेटा के साथ कनेक्ट करें PostgreSQL से तालिका।
अब हम भविष्यवाणियां करने के लिए तैयार हैं।
चरण 10:भविष्यवाणियां
भविष्यवाणी विजेट KNN . के प्रशिक्षण डेटा के आधार पर परीक्षण डेटा की भविष्यवाणी करने का प्रयास करेगा ।
- खींचें और छोड़ें भविष्यवाणी विजेट से मूल्यांकन करें मेनू।
- एक लिंक लाइन फ़ॉर्म बनाएं डेटा का परीक्षण करें भविष्यवाणी . के लिए विजेट विजेट.
- KNN . से एक लिंक लाइन बनाएं भविष्यवाणी . के लिए विजेट विजेट.
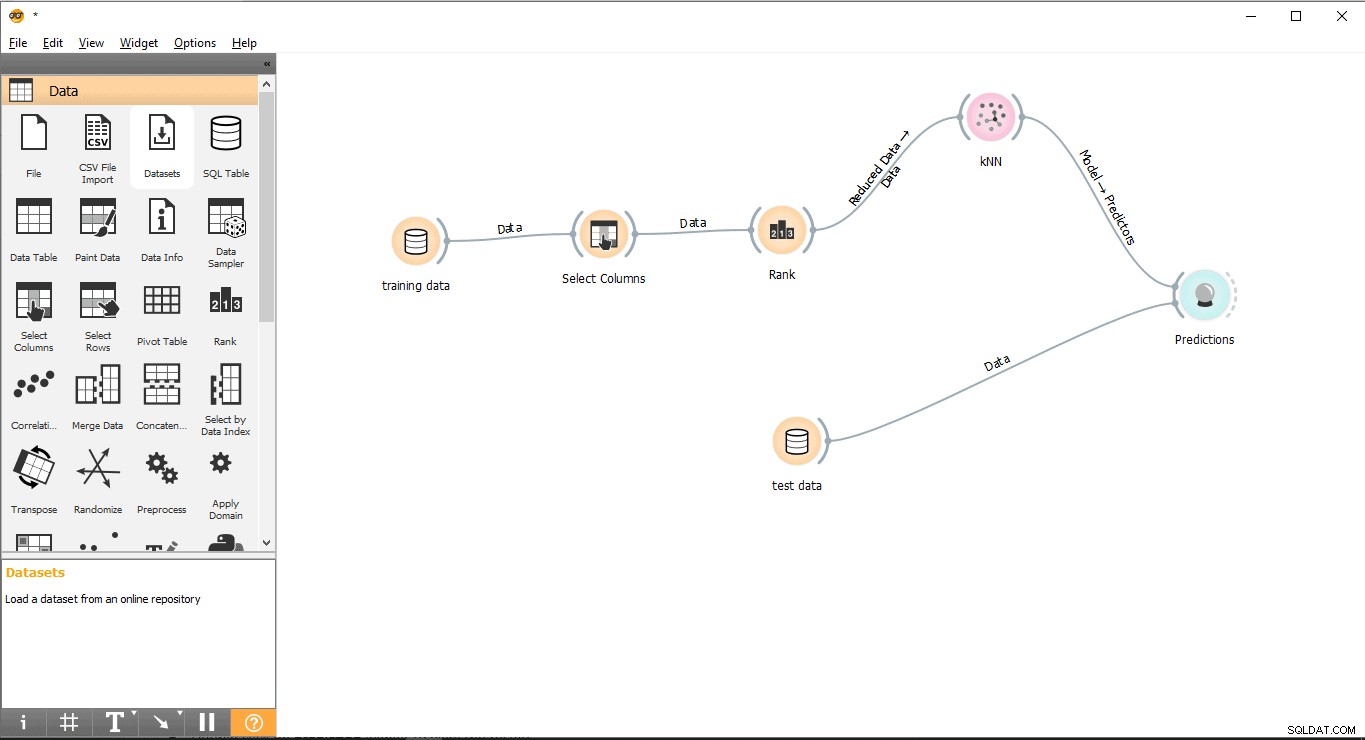
चरण 11:परिणाम
भविष्यवाणी . पर डबल क्लिक करें परिणाम देखने के लिए विजेट।
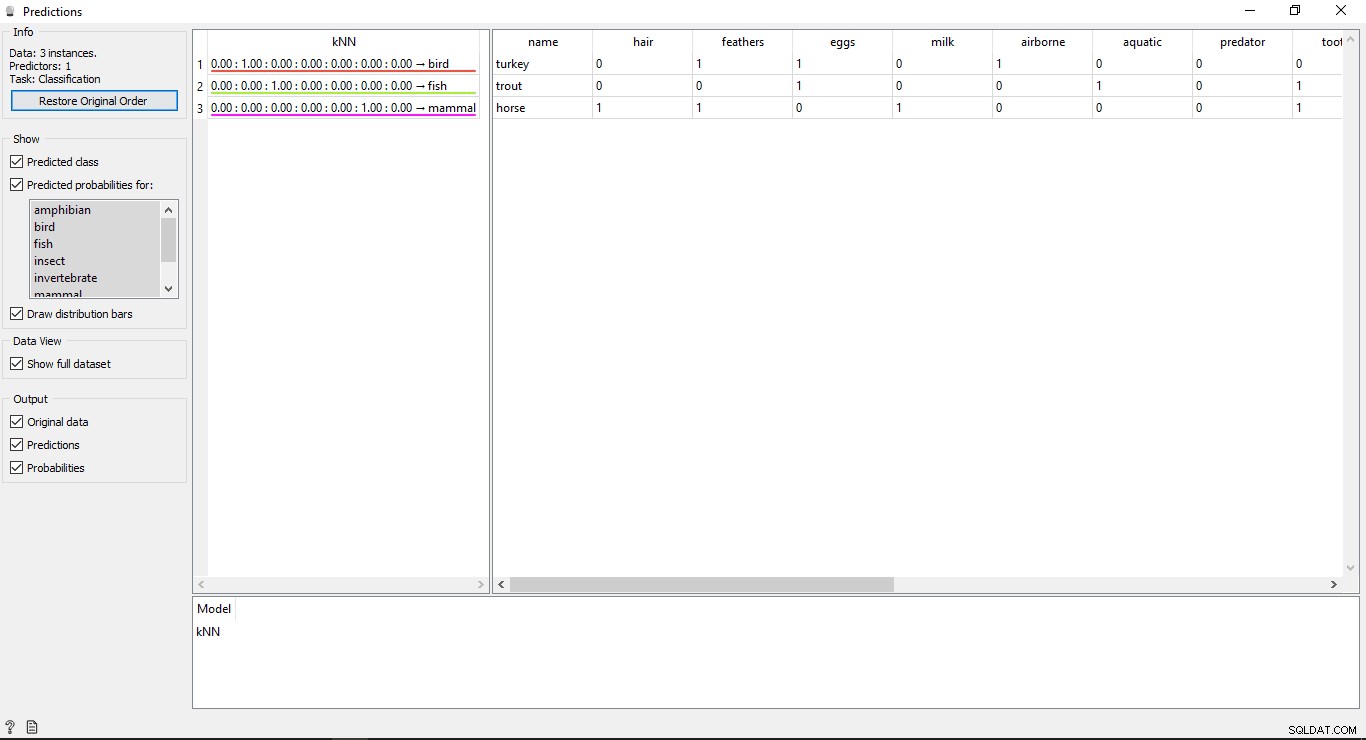
परिणामों को समझना
आपको प्रेडिक्शन विंडो में 2 मुख्य टेबल दिखाई देंगे। बाईं ओर की तालिका अनुमानित परिणाम दिखाती है, जबकि दाईं ओर तालिका मूल परीक्षण डेटा दिखाती है, जो पूर्वानुमानों के लिए प्रदान किया गया था।
चूंकि केएनएन मॉडल का उपयोग डेटा को प्रशिक्षित करने के लिए किया गया था, इसलिए आपको KNN . नामक एक कॉलम दिखाई देगा जो परिणामों को सूचीबद्ध करता है।
जैसा कि हम जानते हैं:
- घोड़ा एक स्तनपायी . है
- ट्राउट एक मछली है
- तुर्की एक पक्षी है
इसलिए KNN सभी प्रकारों को सही ढंग से निर्धारित करने में सक्षम है।
भविष्यवाणियों की सटीकता
यदि आप भविष्यवाणी विजेट के आउटपुट में बाईं ओर तालिका देखते हैं, तो इसमें अनुमानित प्रकार यानी 1.00 से पहले कुछ संख्याएं होती हैं। 0.00 ये संख्याएं अनुमानित प्रकार की सटीकता दर्शाती हैं।
हमने प्रशिक्षण डेटासेट में 7 प्रकार के जानवरों का उपयोग किया है, इसलिए यह सटीकता के साथ कुल 7 कॉलम दिखाता है, प्रत्येक कॉलम 1 प्रकार के जानवरों का प्रतिनिधित्व करेगा। आप के लिए अनुमानित संभावनाएं के अंतर्गत अपनी स्क्रीन के बाईं ओर उपलब्ध सूची को देखकर जांच सकते हैं कि कौन सा कॉलम किस प्रकार के जानवर का प्रतिनिधित्व कर रहा है लेबल। यदि आप पहली पंक्ति को देखें जो तुर्की . कहती है एक पक्षी है . हम देख सकते हैं इसकी सटीकता 1.00 . है (दूसरे कॉलम से 100%)। अन्य उदाहरणों के साथ भी ऐसा ही है ट्राउट एक मछली है और इसकी सटीकता 1.00 . है (तीसरे कॉलम से 100%)।
इस लेख में, हमने मशीन लर्निंग मॉडल को लागू करने के लिए k-निकटतम पड़ोसियों के एल्गोरिथ्म (KNN) का उपयोग किया है। अगले ब्लॉग में, हम सपोर्ट वेक्टर मशीन . का उपयोग करेंगे (एसवीएम) मॉडल।
किसी भी प्रश्न या टिप्पणी के लिए, कृपया यहां संपर्क फ़ॉर्म का उपयोग करके संपर्क करें।