यह 2ndQuadrant के repmgr पर दो-भाग वाली श्रृंखला की दूसरी किस्त है, जो PostgreSQL के लिए एक ओपन-सोर्स उच्च-उपलब्धता टूल है।
पहले भाग में, हमने "गवाह" नोड के साथ तीन-नोड PostgreSQL 12 क्लस्टर स्थापित किया। क्लस्टर में एक प्राथमिक नोड और दो स्टैंडबाय नोड शामिल थे। क्लस्टर और विटनेस नोड को Amazon Web Service Virtual Private Cloud (VPC) में होस्ट किया गया था। पोस्टग्रेज इंस्टेंस को होस्ट करने वाले ईसी2 सर्वर को अलग-अलग उपलब्धता क्षेत्रों (एजेड) में सबनेट में रखा गया था, जैसा कि नीचे दिखाया गया है:
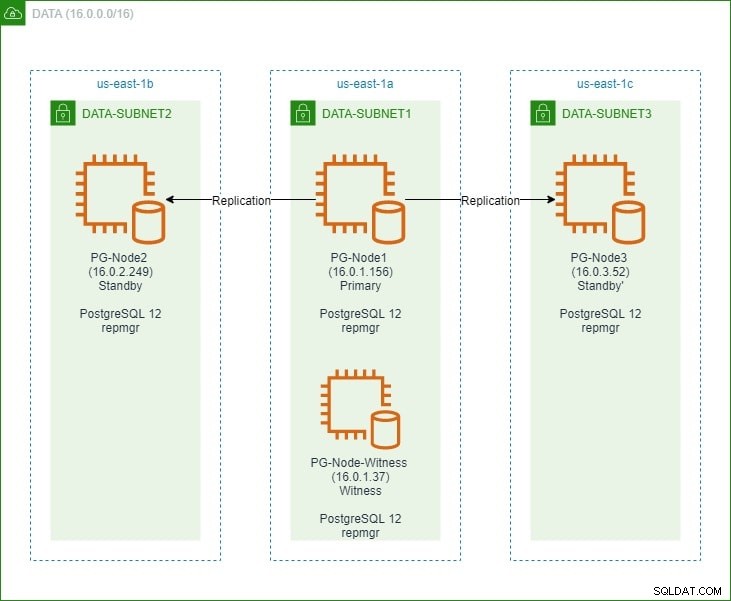
हम नोड नामों और उनके आईपी पतों का व्यापक संदर्भ देंगे, इसलिए यहां फिर से नोड्स के विवरण के साथ तालिका दी गई है:
| नोड नाम | आईपी पता | भूमिका | ऐप्लिकेशन चल रहे हैं |
| PG-Node1 | 16.0.1.156 | प्राथमिक | PostgreSQL 12 और repmgr |
| PG-Node2 | 16.0.2.249 | स्टैंडबाय 1 | PostgreSQL 12 और repmgr |
| PG-Node3 | 16.0.3.52 | स्टैंडबाय 2 | PostgreSQL 12 और repmgr |
| PG-नोड-गवाह | 16.0.1.37 | गवाह | PostgreSQL 12 और repmgr |
हमने प्राथमिक और स्टैंडबाय नोड्स में repmgr स्थापित किया और फिर प्राथमिक नोड को repmgr के साथ पंजीकृत किया। फिर हमने दोनों स्टैंडबाय नोड्स को प्राइमरी से क्लोन किया और उन्हें शुरू किया। दोनों स्टैंडबाय नोड्स को भी repmgr के साथ पंजीकृत किया गया था। "repmgr क्लस्टर शो" कमांड ने हमें दिखाया कि सब कुछ उम्मीद के मुताबिक चल रहा था:

वर्तमान समस्या
Repmgr के साथ स्ट्रीमिंग प्रतिकृति सेट करना बहुत आसान है। आगे हमें यह सुनिश्चित करने की आवश्यकता है कि प्राथमिक अनुपलब्ध होने पर भी क्लस्टर कार्य करेगा। यही हम इस लेख में शामिल करेंगे।
PostgreSQL प्रतिकृति में, कुछ कारणों से प्राथमिक अनुपलब्ध हो सकता है। उदाहरण के लिए:
- प्राथमिक नोड का ऑपरेटिंग सिस्टम क्रैश हो सकता है, या अनुत्तरदायी हो सकता है
- प्राथमिक नोड अपना नेटवर्क कनेक्टिविट खो सकता है
- प्राथमिक नोड में PostgreSQL सेवा अनपेक्षित रूप से क्रैश, रुक सकती है या अनुपलब्ध हो सकती है
- प्राथमिक नोड में PostgreSQL सेवा को जानबूझकर या गलती से रोका जा सकता है
जब भी कोई प्राथमिक अनुपलब्ध हो जाता है, एक स्टैंडबाय नहीं . करता है स्वचालित रूप से प्राथमिक भूमिका के लिए खुद को बढ़ावा देता है। एक स्टैंडबाय अभी भी केवल-पढ़ने के लिए प्रश्नों की सेवा जारी रखता है - हालांकि डेटा प्राथमिक से प्राप्त अंतिम एलएसएन तक चालू रहेगा। लिखने की कार्रवाई का कोई भी प्रयास विफल हो जाएगा।
इसे कम करने के दो तरीके हैं:
- स्टैंडबाय मैन्युअल रूप से है प्राथमिक भूमिका में अपग्रेड किया गया। यह आमतौर पर नियोजित विफलता या "स्विचओवर" के मामले में होता है
- स्टैंडबाय स्वचालित रूप से है प्राथमिक भूमिका में पदोन्नत किया गया। यह गैर-देशी उपकरणों के मामले में है जो लगातार प्रतिकृति की निगरानी करते हैं और प्राथमिक अनुपलब्ध होने पर पुनर्प्राप्ति कार्रवाई करते हैं। repmgr ऐसा ही एक टूल है।
हम यहां दूसरे परिदृश्य पर विचार करेंगे। हालांकि इस स्थिति में कुछ अतिरिक्त चुनौतियाँ हैं:
- यदि एक से अधिक स्टैंडबाय हैं, तो टूल (या स्टैंडबाय) कैसे तय करता है कि किसे प्राथमिक के रूप में प्रचारित किया जाना है? कोरम और प्रचार प्रक्रिया कैसे काम करती है?
- एकाधिक स्टैंडबाय के लिए, यदि एक को प्राथमिक बना दिया जाता है, तो अन्य नोड नए प्राथमिक के रूप में "इसका अनुसरण" कैसे शुरू करते हैं?
- क्या होगा यदि प्राथमिक कार्य कर रहा है, लेकिन किसी कारण से नेटवर्क से अस्थायी रूप से अलग हो गया है? यदि स्टैंडबाय में से एक को प्राथमिक में पदोन्नत किया जाता है और फिर मूल प्राथमिक ऑनलाइन वापस आ जाता है, तो "विभाजित मस्तिष्क" स्थिति से कैसे बचा जा सकता है?
remgr का उत्तर:विटनेस नोड और repmgr डेमॉन
इन सवालों के जवाब देने के लिए, repmgr गवाह नोड . नामक किसी चीज़ का उपयोग करता है . जब प्राथमिक अनुपलब्ध हो - स्टैंडबाय को कोरम तक पहुँचने में मदद करना गवाह नोड का काम है यदि उनमें से एक को प्राथमिक भूमिका में पदोन्नत किया जाना चाहिए। स्टैंडबाय इस कोरम तक पहुँचते हैं यह निर्धारित करके कि प्राथमिक नोड वास्तव में ऑफ़लाइन है या केवल अस्थायी रूप से अनुपलब्ध है। विटनेस नोड प्राथमिक नोड के समान डेटा सेंटर/नेटवर्क सेगमेंट/सबनेट में स्थित होना चाहिए, लेकिन प्राथमिक नोड के समान भौतिक होस्ट पर कभी नहीं चलना चाहिए।
याद रखें कि इस श्रृंखला के पहले भाग में, हमने समान उपलब्धता क्षेत्र और सबनेट में प्राथमिक नोड के रूप में एक विटनेस नोड को रोल आउट किया था। हमने इसे पीजी-नोड-विटनेस नाम दिया और वहां एक पोस्टग्रेएसक्यूएल 12 इंस्टेंस स्थापित किया। इस पोस्ट में, हम वहां भी repmgr इंस्टॉल करेंगे, लेकिन उस पर और बाद में।
समाधान का दूसरा घटक है repmgr डेमॉन (repmgrd) क्लस्टर और विटनेस नोड के सभी नोड्स में चल रहा है। फिर से, हमने इस डेमॉन को इस श्रृंखला के पहले भाग में शुरू नहीं किया था, लेकिन हम यहां ऐसा करेंगे। डेमॉन repmgr पैकेज के हिस्से के रूप में आता है - सक्षम होने पर, यह एक नियमित सेवा के रूप में चलता है और क्लस्टर के स्वास्थ्य की लगातार निगरानी करता है। जब प्राथमिक के ऑफ़लाइन होने के बारे में कोरम पूरा हो जाता है, तो यह एक विफलता आरंभ करता है। न केवल यह स्वचालित रूप से एक स्टैंडबाय को बढ़ावा दे सकता है, यह नए प्राथमिक का पालन करने के लिए एक बहु-नोड क्लस्टर में अन्य स्टैंडबाय को भी फिर से शुरू कर सकता है ।
कोरम प्रक्रिया
जब एक स्टैंडबाय को पता चलता है कि वह प्राथमिक को नहीं देख सकता है, तो वह अन्य स्टैंडबाय के साथ परामर्श करता है। क्लस्टर में चल रहे सभी स्टैंडबाय चेक की एक श्रृंखला का उपयोग करके एक नया प्राथमिक चुनने के लिए कोरम तक पहुंचते हैं:
- प्रत्येक स्टैंडबाय अन्य स्टैंडबाय से उस समय के बारे में पूछताछ करता है जब उसने प्राथमिक को "देखा" था। यदि स्टैंडबाय का अंतिम प्रतिरूपित एलएसएन या प्राथमिक के साथ अंतिम संचार का समय वर्तमान नोड के अंतिम प्रतिरूपित एलएसएन या अंतिम संचार के समय से अधिक हाल का है, तो नोड कुछ भी नहीं करता है और प्राथमिक के साथ संचार के बहाल होने की प्रतीक्षा करता है
- यदि कोई भी स्टैंडबाय प्राथमिक को नहीं देख सकता है, तो वे जांचते हैं कि क्या विटनेस नोड उपलब्ध है। यदि गवाह नोड तक नहीं पहुंचा जा सकता है, तो स्टैंडबाय मान लेते हैं कि प्राथमिक पक्ष पर एक नेटवर्क आउटेज है और एक नया प्राथमिक चुनने के लिए आगे नहीं बढ़ें
- यदि गवाह तक पहुंचा जा सकता है, तो स्टैंडबाय मान लेते हैं कि प्राथमिक बंद है और प्राथमिक चुनने के लिए आगे बढ़ें
- जिस नोड को "पसंदीदा" प्राथमिक के रूप में कॉन्फ़िगर किया गया था, उसे तब प्रचारित किया जाएगा। नए प्राथमिक का पालन करने के लिए प्रत्येक स्टैंडबाय की प्रतिकृति को पुन:प्रारंभ किया जाएगा।
स्वचालित विफलता के लिए क्लस्टर कॉन्फ़िगर करना
अब हम स्वचालित विफलता के लिए क्लस्टर और विटनेस नोड को कॉन्फ़िगर करेंगे।
चरण 1:गवाह में repmgr स्थापित और कॉन्फ़िगर करें
हमने अपने पिछले लेख में पहले ही देखा था कि repmgr पैकेज कैसे स्थापित करें। हम इसे विटनेस नोड में भी करते हैं:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
और फिर:
# yum install repmgr12 -y
इसके बाद, हम निम्नलिखित पंक्तियों को विटनेस नोड की postgresql.conf फ़ाइल में जोड़ते हैं:
listen_addresses ='*'shared_preload_libraries ='repmgr'
हम विटनेस नोड में pg_hba.conf फ़ाइल में निम्न पंक्तियाँ भी जोड़ते हैं। ध्यान दें कि हम अलग-अलग IP पतों को निर्दिष्ट करने के बजाय क्लस्टर की CIDR श्रेणी का उपयोग कैसे कर रहे हैं।
स्थानीय प्रतिकृति repmgr trusthost प्रतिकृति repmgr 127.0.0.1/32 trusthost प्रतिकृति repmgr 16.0.0.0/16 ट्रस्टलोकल रेपमग्र रेपमग्रग ट्रस्टथोस्ट रेपमग्रग 127.0.0.0.0.1/32 ट्रूथोस्टोस्ट रेपमग्रेग 16.0.0.0.0/16नोट
[यहां वर्णित चरण केवल प्रदर्शन के उद्देश्य से हैं। यहां हमारा उदाहरण नोड्स के लिए बाहरी रूप से पहुंच योग्य आईपी का उपयोग कर रहा है। इसलिए pg_hba के "ट्रस्ट" सुरक्षा तंत्र के साथ सुनो_एड्रेस ='*' का उपयोग करना सुरक्षा जोखिम पैदा करता है, और उत्पादन परिदृश्यों में इसका उपयोग नहीं किया जाना चाहिए। एक उत्पादन प्रणाली में, सभी नोड्स एक या अधिक निजी सबनेट के अंदर होंगे, जो जम्पहोस्ट से निजी आईपी के माध्यम से उपलब्ध होंगे।]
Postgresql.conf और pg_hba.conf परिवर्तनों के साथ, हम गवाह में repmgr उपयोगकर्ता और repmgr डेटाबेस बनाते हैं, और repmgr उपयोगकर्ता के डिफ़ॉल्ट खोज पथ को बदलते हैं:
[example@sqldat.comitness ~]$ createuser --superuser repmgr[example@sqldat.com ~]$ createb --owner=repmgr repmgr[example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"अंत में, हम निम्नलिखित पंक्तियों को /etc/repmgr/12/
के अंतर्गत स्थित repmgr.conf फ़ाइल में जोड़ते हैं।नोड_आईडी =4नोड_नाम ='PG-नोड-गवाह'conninfo ='होस्ट=16.0.1.37 उपयोगकर्ता=repmgr dbname=repmgr Connect_timeout=2'data_directory ='/var/lib/pgsql/12/डेटा'एक बार कॉन्फ़िगरेशन पैरामीटर सेट हो जाने के बाद, हम विटनेस नोड में PostgreSQL सेवा को पुनः आरंभ करते हैं:
# systemctl postgresql-12.service को पुनरारंभ करेंनोड repmgr को देखने के लिए कनेक्टिविटी का परीक्षण करने के लिए, हम इस कमांड को प्राथमिक नोड से चला सकते हैं:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgrconnect_timeout=2'इसके बाद, हम पोस्टग्रेज उपयोगकर्ता के रूप में "repmgr गवाह रजिस्टर" कमांड चलाकर गवाह नोड को repmgr के साथ पंजीकृत करते हैं। ध्यान दें कि हम प्राथमिक . के पते का उपयोग कैसे कर रहे हैं नोड, और नीचे दिए गए कमांड में विटनेस नोड नहीं:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf गवाह रजिस्टर -h 16.0.1.156ऐसा इसलिए है क्योंकि "repmgr गवाह रजिस्टर" कमांड गवाह नोड के मेटाडेटा को प्राथमिक नोड के repmgr डेटाबेस में जोड़ता है, और यदि आवश्यक हो, तो repmgr एक्सटेंशन इंस्टॉल करके और repmgr मेटाडेटा को साक्षी नोड में कॉपी करके गवाह नोड को प्रारंभ करता है।
आउटपुट इस तरह दिखेगा:
जानकारी:विटनेस नोड "पीजी-नोड-विटनेस" से कनेक्ट करना (आईडी:4)जानकारी:प्राथमिक नोड से कनेक्ट करनासूचना:एक्सटेंशन "repmgr"स्थापित करने का प्रयास सूचना:"repmgr" एक्सटेंशन सफलतापूर्वक स्थापितजानकारी:गवाह पंजीकरण पूर्ण सूचना:गवाह नोड "पीजी-नोड-गवाह" (आईडी:4) सफलतापूर्वक पंजीकृतअंत में, हम किसी भी नोड से समग्र सेटअप की स्थिति की जांच करते हैं:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf क्लस्टर शो --कॉम्पैक्टआउटपुट इस तरह दिखता है:
चरण 2:sudoers फ़ाइल को संशोधित करना
क्लस्टर और विटनेस के चलने के साथ, हम क्लस्टर के प्रत्येक नोड और विटनेस नोड में sudoers फ़ाइल में निम्न पंक्तियाँ जोड़ते हैं:
डिफ़ॉल्ट:पोस्टग्रेज !requirettypostgres ALL =NOPASSWD:/usr/bin/systemctl स्टॉप पोस्टग्रेस्क्ल-12.सर्विस, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl पुनरारंभ postgresql-12.service , /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.serviceचरण 3:repmgrd पैरामीटर कॉन्फ़िगर करना
हम पहले ही प्रत्येक नोड में repmgr.conf फ़ाइल में चार पैरामीटर जोड़ चुके हैं। जोड़े गए पैरामीटर रेपमग्र ऑपरेशन के लिए आवश्यक बुनियादी हैं। repmgr डेमॉन और स्वचालित विफलता को सक्षम करने के लिए, कई अन्य मापदंडों को सक्षम/जोड़ने की आवश्यकता है। निम्नलिखित उपखंडों में, हम प्रत्येक पैरामीटर और प्रत्येक नोड में उनके द्वारा निर्धारित किए जाने वाले मान का वर्णन करेंगे।
विफलता
विफलता पैरामीटर repmgr डेमॉन के लिए अनिवार्य मापदंडों में से एक है। यह पैरामीटर डेमॉन को बताता है कि क्या विफलता की स्थिति का पता चलने पर उसे स्वचालित विफलता शुरू करनी चाहिए। इसके दो मान हो सकते हैं:"मैनुअल" या "स्वचालित"। हम इसे प्रत्येक नोड में स्वचालित रूप से सेट करेंगे:
विफलता ='स्वचालित'promote_command
यह repmgr डेमॉन के लिए एक और अनिवार्य पैरामीटर है। यह पैरामीटर repmgr डेमॉन को बताता है कि स्टैंडबाय को बढ़ावा देने के लिए उसे कौन सी कमांड चलानी चाहिए। इस पैरामीटर का मान आम तौर पर "repmgr स्टैंडबाय प्रमोशन" कमांड या शेल स्क्रिप्ट का पथ होगा जो कमांड को कॉल करता है। हमारे उपयोग के मामले में, हम इसे प्रत्येक नोड में निम्नलिखित पर सेट करते हैं:
promote_command ='/usr/pgsql-12/bin/repmgr स्टैंडबाय प्रमोशन -f /etc/repmgr/12/repmgr.conf --log-to-file'follow_command
यह repmgr डेमॉन के लिए तीसरा अनिवार्य पैरामीटर है। यह पैरामीटर एक स्टैंडबाय नोड को नए प्राथमिक का पालन करने के लिए कहता है। repmgr डेमॉन रन टाइम पर %n प्लेसहोल्डर को नए प्राइमरी के नोड आईडी से बदल देता है:
follow_command ='/usr/pgsql-12/bin/repmgr स्टैंडबाय फॉलो -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'प्राथमिकता
प्राथमिकता पैरामीटर प्राथमिक बनने के लिए नोड की योग्यता में वजन जोड़ता है। इस पैरामीटर को उच्च मान पर सेट करने से नोड को प्राथमिक नोड बनने के लिए अधिक योग्यता मिलती है। साथ ही, किसी नोड के लिए इस मान को शून्य पर सेट करने से यह सुनिश्चित होगा कि नोड को कभी भी प्राथमिक के रूप में प्रचारित नहीं किया जाएगा।
हमारे उपयोग के मामले में, हमारे पास दो स्टैंडबाय हैं:PG-Node2 और PG-Node3। हम PG-Node2 को नए प्राथमिक के रूप में बढ़ावा देना चाहते हैं जब PG-Node1 ऑफ़लाइन हो जाता है, और PG-Node3 अपने नए प्राथमिक के रूप में PG-Node2 का अनुसरण करता है। हम दो स्टैंडबाय नोड्स में निम्नलिखित मानों के लिए पैरामीटर सेट करते हैं:

| नोड नाम | पैरामीटर सेटिंग |
| PG-Node2 | प्राथमिकता =60 |
| PG-Node3 | प्राथमिकता =40 |
monitor_interval_secs
यह पैरामीटर repmgr डेमॉन को बताता है कि उसे कितनी बार (सेकंड की संख्या में) अपस्ट्रीम नोड की उपलब्धता की जांच करनी चाहिए। हमारे मामले में, केवल एक अपस्ट्रीम नोड है:प्राथमिक नोड। डिफ़ॉल्ट मान 2 सेकंड है, लेकिन हम इसे प्रत्येक नोड में किसी भी तरह स्पष्ट रूप से सेट करेंगे:
monitor_interval_secs =2
connection_check_type
कनेक्शन_चेक_टाइप पैरामीटर उस प्रोटोकॉल को निर्धारित करता है जिसका उपयोग रेपमग्र डेमॉन अपस्ट्रीम नोड तक पहुंचने के लिए करेगा। यह पैरामीटर तीन मान ले सकता है:
- पिंग :repmgr PQPing() विधि का उपयोग करता है
- कनेक्शन :repmgr अपस्ट्रीम नोड से एक नया कनेक्शन बनाने की कोशिश करता है
- क्वेरी :repmgr मौजूदा कनेक्शन का उपयोग करके अपस्ट्रीम नोड पर SQL क्वेरी चलाने का प्रयास करता है
फिर से, हम इस पैरामीटर को प्रत्येक नोड में पिंग के डिफ़ॉल्ट मान पर सेट करेंगे:
connection_check_type ='पिंग'
reconnect_attempts and reconnect_interval
जब प्राथमिक अनुपलब्ध हो जाता है, तो स्टैंडबाय नोड्स में repmgr डेमॉन reconnect_attempts समय के लिए प्राथमिक से पुन:कनेक्ट करने का प्रयास करेगा। इस पैरामीटर के लिए डिफ़ॉल्ट मान 6 है। प्रत्येक पुन:कनेक्ट करने के प्रयास के बीच, यह reconnect_interval सेकंड के लिए प्रतीक्षा करेगा, जिसका डिफ़ॉल्ट मान 10 है। प्रदर्शन उद्देश्यों के लिए, हम एक छोटे अंतराल और कम पुन:कनेक्ट प्रयासों का उपयोग करेंगे। हम इस पैरामीटर को हर नोड में सेट करते हैं:
reconnect_attempts =4reconnect_interval =8
प्राथमिक_दृश्यता_सहमति
जब प्राथमिक एक बहु-नोड क्लस्टर में अनुपलब्ध हो जाता है, तो स्टैंडबाय विफलता के बारे में कोरम बनाने के लिए एक दूसरे से परामर्श कर सकते हैं। यह प्रत्येक स्टैंडबाय से उस समय के बारे में पूछकर किया जाता है जब उसने पिछली बार प्राथमिक देखा था। यदि किसी नोड का अंतिम संचार बहुत हाल ही में हुआ था और स्थानीय नोड द्वारा प्राथमिक देखे जाने के बाद के समय में, स्थानीय नोड मानता है कि प्राथमिक अभी भी उपलब्ध है, और एक विफलता निर्णय के साथ आगे नहीं बढ़ता है।
इस आम सहमति मॉडल को सक्षम करने के लिए, प्राथमिक_दृश्यता_सहमति पैरामीटर को गवाह सहित - प्रत्येक नोड में "सत्य" पर सेट करने की आवश्यकता है:
प्राथमिक_दृश्यता_सहमति =सत्य
standby_disconnect_on_failover
जब स्टैंडबाय_डिसकनेक्ट_ऑन_फेलओवर पैरामीटर को स्टैंडबाय नोड में "सत्य" पर सेट किया जाता है, तो repmgr डेमॉन सुनिश्चित करेगा कि उसका वाल रिसीवर प्राथमिक से डिस्कनेक्ट हो गया है और कोई भी वाल सेगमेंट प्राप्त नहीं कर रहा है। यह फ़ेलओवर निर्णय लेने से पहले अन्य स्टैंडबाय नोड्स के WAL रिसीवर्स के रुकने का भी इंतज़ार करेगा। यह पैरामीटर प्रत्येक नोड में समान मान पर सेट किया जाना चाहिए। हम इसे "सत्य" पर सेट कर रहे हैं।
standby_disconnect_on_failover =सत्य
इस पैरामीटर को सही पर सेट करने का मतलब है कि प्रत्येक स्टैंडबाय नोड ने प्राथमिक से डेटा प्राप्त करना बंद कर दिया है क्योंकि विफलता होती है। प्रक्रिया में 5 सेकंड की देरी होगी और साथ ही एक विफलता निर्णय लेने से पहले वाल रिसीवर को रुकने में लगने वाला समय। डिफ़ॉल्ट रूप से, repmgr डेमॉन यह पुष्टि करने के लिए 30 सेकंड तक प्रतीक्षा करेगा कि सभी सिबलिंग नोड्स ने विफलता होने से पहले WAL सेगमेंट प्राप्त करना बंद कर दिया है।
repmgrd_service_start_command और repmgrd_service_stop_command
ये दो पैरामीटर निर्दिष्ट करते हैं कि "repmgr daemon start" और "repmgr daemon stop" कमांड का उपयोग करके repmgr डेमॉन को कैसे शुरू और बंद किया जाए।
मूल रूप से, ये दो कमांड सेवा शुरू करने/बंद करने के लिए ऑपरेटिंग सिस्टम कमांड के चारों ओर रैपर हैं। दो पैरामीटर मान इन आदेशों को उनके ओएस-विशिष्ट संस्करणों में मैप करते हैं। हम इन मापदंडों को प्रत्येक नोड में निम्नलिखित मानों पर सेट करते हैं:
repmgrd_service_start_command ='sudo /usr/bin/systemctl start repmgr12.service'repmgrd_service_stop_command ='sudo /usr/bin/systemctl stop repmgr12.service'
PostgreSQL सर्विस स्टार्ट/स्टॉप/रिस्टार्ट कमांड्स
इसके संचालन के भाग के रूप में, repmgr डेमॉन को अक्सर PostgreSQL सेवा को रोकने, प्रारंभ करने या पुनरारंभ करने की आवश्यकता होगी। यह सुनिश्चित करने के लिए कि यह सुचारू रूप से होता है, संबंधित ऑपरेटिंग सिस्टम कमांड को repmgr.conf फ़ाइल में पैरामीटर मान के रूप में निर्दिष्ट करना सबसे अच्छा है। हम इस उद्देश्य के लिए प्रत्येक नोड में चार पैरामीटर सेट करेंगे:
service_start_command ='sudo /usr/bin/systemctl start postgresql-12.service'service_stop_command ='sudo /usr/bin/systemctl stop postgresql-12.service'service_restart_command ='sudo /usr/bin/systemctl postgresql-12.service' को पुनरारंभ करेंservice_reload_command ='sudo /usr/bin/systemctl reload postgresql-12.service'
निगरानी_इतिहास
मॉनिटरिंग_हिस्ट्री पैरामीटर को "हां" पर सेट करने से यह सुनिश्चित होगा कि repmgr अपने क्लस्टर मॉनिटरिंग डेटा को सहेज रहा है। हम इसे प्रत्येक नोड में "हां" पर सेट करते हैं:
निगरानी_इतिहास =हाँ
log_status_interval
हम यह निर्दिष्ट करने के लिए प्रत्येक नोड में पैरामीटर सेट करते हैं कि repmgr डेमॉन कितनी बार स्थिति संदेश लॉग करेगा। इस मामले में, हम इसे हर 60 सेकंड में सेट कर रहे हैं:
log_status_interval =60
चरण 4:repmgr डेमॉन प्रारंभ करना
अब क्लस्टर और विटनेस नोड में सेट किए गए मापदंडों के साथ, हम repmgr डेमॉन को शुरू करने के लिए कमांड के ड्राई रन को निष्पादित करते हैं। हम पहले प्राथमिक नोड में इसका परीक्षण करते हैं, और फिर दो स्टैंडबाय नोड्स, उसके बाद गवाह नोड में। कमांड को पोस्टग्रेज यूजर के रूप में निष्पादित किया जाना है:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf डेमन स्टार्ट --ड्राई-रन
आउटपुट इस तरह दिखना चाहिए:
जानकारी:repmgrd मुलाकात शुरू करने के लिए आवश्यक शर्तें विवरण:निम्न आदेश निष्पादित किया जाएगा: sudo /usr/bin/systemctl start repmgr12.service
इसके बाद, हम चारों नोड्स में डेमॉन शुरू करते हैं:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf डेमन स्टार्ट
प्रत्येक नोड में आउटपुट दिखाना चाहिए कि डेमॉन शुरू हो गया है:
सूचना:क्रियान्वित:"sudo /usr/bin/systemctl start repmgr12.service"सूचना:repmgrd सफलतापूर्वक प्रारंभ किया गया था
हम प्राथमिक या स्टैंडबाय नोड्स से भी सर्विस स्टार्टअप इवेंट की जांच कर सकते हैं:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf क्लस्टर इवेंट --event=repmgrd_start
आउटपुट को दिखाना चाहिए कि डेमॉन कनेक्शन की निगरानी कर रहा है:
नोड आईडी | नाम | घटना | ठीक | टाइमस्टैम्प | विवरण----------- ------------------------+---------------------------- ------------------------------------- 4 | पीजी-नोड-गवाह | repmgrd_start | टी | 2020-02-05 11:37:31 | प्राइमरी नोड "PG-Node1" (ID:1) से मॉनिटरिंग कनेक्शन देखें 3 | पीजी-नोड3 | repmgrd_start | टी | 2020-02-05 11:37:24 | अपस्ट्रीम नोड "PG-Node1" (ID:1) से कनेक्शन की निगरानी करना 2 | पीजी-नोड2 | repmgrd_start | टी | 2020-02-05 11:37:19 | अपस्ट्रीम नोड "PG-Node1" (ID:1) से कनेक्शन की निगरानी करना 1 | पीजी-नोड1 | repmgrd_start | टी | 2020-02-05 11:37:14 | निगरानी क्लस्टर प्राथमिक "पीजी-नोड1" (आईडी:1)
अंत में, हम किसी भी स्टैंडबाय में syslog से डेमॉन आउटपुट की जांच कर सकते हैं:
# बिल्ली /var/log/messages | grep repmgr | कम
यहाँ PG-Node3 से आउटपुट है:
फरवरी 5 11:37:24 पीजी-नोड3 repmgrd[2014]:[2020-02-05 11:37:24] [नोटिस] प्रदान की गई कॉन्फ़िगरेशन फ़ाइल का उपयोग करके "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [नोटिस] repmgrd (repmgrd 5.0.0) स्टार्ट अप फ़रवरी 5 11:37:24 पीजी-नोड3 प्रतिनिधि [2014]:[2020-02-05 11:37:24] [सूचना] डेटाबेस से जुड़ रहा है "होस्ट =16.0.3.52 उपयोगकर्ता =रेपमग्र डीबीनाम =रेपमग्र कनेक्ट_टाइमआउट =2" फरवरी 5 11:37:24 PG-Node3 systemd[1]:repmgr12.service:प्रारंभ के बाद PID फ़ाइल /run/repmgr/repmgrd-12.pid (अभी तक?) नहीं खोल सकता:ऐसी कोई फ़ाइल या निर्देशिका नहीं फ़रवरी 5 11:37 :24 PG-Node3 repmgrd[2014]:जानकारी: set_repmgrd_pid():बशर्ते pidfile /run/repmgr/repmgrd-12.pid हो फ़रवरी 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [नोटिस] नोड "PG-Node3" (आईडी:3) की निगरानी शुरू कर रहा है फ़रवरी 5 11:37:24 पीजी-नोड3 प्रतिनिधि[2014]:[2020-02-05 11:37:24] [जानकारी] "कनेक्शन_चेक_टाइप" "पिंग" पर सेट है फ़रवरी 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [जानकारी] अपस्ट्रीम नोड "PG-Node1" (आईडी:1) से निगरानी कनेक्शन बी> फ़रवरी 5 11:38:25 पीजी-नोड3 प्रतिनिधि[2014]:[2020-02-05 11:38:25] [जानकारी] नोड "पीजी-नोड3" (आईडी:3) अपस्ट्रीम नोड की निगरानी "पीजी- Node1" (आईडी:1) सामान्य अवस्था में है फ़रवरी 5 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [DETAIL] अंतिम निगरानी आंकड़े अपडेट 2 सेकंड पहले हुआ था फ़रवरी 5 11:39:26 पीजी-नोड3 प्रतिनिधि[2014]:[2020-02-05 11:39:26] [जानकारी] नोड "पीजी-नोड3" (आईडी:3) अपस्ट्रीम नोड की निगरानी "पीजी- Node1" (आईडी:1) सामान्य अवस्था में है … …
प्राथमिक नोड में syslog की जाँच करना एक अलग प्रकार का आउटपुट दिखाता है:
फरवरी 5 11:37:14 पीजी-नोड1 repmgrd[2017]:[2020-02-05 11:37:14] [नोटिस] प्रदान की गई कॉन्फ़िगरेशन फ़ाइल का उपयोग करके "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [नोटिस] repmgrd (repmgrd 5.0.0) स्टार्ट अप फ़रवरी 5 11:37:14 पीजी-नोड1 प्रतिनिधि [2017]:[2020-02-05 11:37:14] [सूचना] डेटाबेस से जुड़ रहा है "होस्ट =16.0.1.156 उपयोगकर्ता =रेपमग्र डीबीनाम =रेपमग्र कनेक्ट_टाइमआउट =2" फरवरी 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [नोटिस] नोड "PG-Node1" (ID:1) की निगरानी शुरू कर रहा है फ़रवरी 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] "connection_check_type" को "पिंग" पर सेट किया गया फ़रवरी 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [नोटिस] मॉनिटरिंग क्लस्टर प्राइमरी "PG-Node1" (ID:1) फ़रवरी 5 11:37:14 पीजी-नोड1 प्रतिनिधि [2017]:[2020-02-05 11:37:14] [सूचना] चाइल्ड नोड "पीजी-नोड-गवाह" (आईडी:4) अभी तक संलग्न नहीं हैफरवरी 5 11 :37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] चाइल्ड नोड "PG-Node3" (ID:3) संलग्न है फ़रवरी 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] चाइल्ड नोड "PG-Node2" (ID:2) संलग्न है फ़रवरी 5 11:37:32 पीजी-नोड1 प्रतिनिधि[2017]:[2020-02-05 11:37:32] [नोटिस] नया गवाह "पीजी-नोड-गवाह" (आईडी:4) जुड़ा हुआ है फ़रवरी 5 11:38:14 पीजी-नोड1 प्रतिनिधि[2017]:[2020-02-05 11:38:14] [सूचना] सामान्य स्थिति में प्राथमिक नोड "पीजी-नोड1" (आईडी:1) की निगरानी फ़रवरी 5 11:39:15 पीजी-नोड1 प्रतिनिधि[2017]:[2020-02-05 11:39:15] [सूचना] सामान्य स्थिति में प्राथमिक नोड "पीजी-नोड1" (आईडी:1) की निगरानी … …
चरण 5:विफल प्राथमिक का अनुकरण करना
अब हम प्राथमिक नोड (PG-Node1) को रोककर एक असफल प्राथमिक का अनुकरण करेंगे। नोड के शेल प्रांप्ट से, हम निम्न कमांड चलाते हैं:
# systemctl stop postgresql-12.service
विफलता प्रक्रिया
एक बार प्रक्रिया रुकने के बाद, हम लगभग एक या दो मिनट तक प्रतीक्षा करते हैं, और फिर PG-Node2 की syslog फ़ाइल की जाँच करते हैं। निम्नलिखित संदेश दिखाए गए हैं। स्पष्टता और सरलता के लिए, हमारे पास संदेशों के रंग-कोडित समूह हैं और पंक्तियों के बीच अतिरिक्त रिक्त स्थान हैं:
… फ़रवरी 5 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [चेतावनी] पिंग करने में असमर्थ "उपयोगकर्ता =repmgr Connect_timeout =2 dbname =repmgr होस्ट =16.0.1.156 फ़ॉलबैक_एप्लिकेशन_नाम =repmgr" फ़रवरी 5 11:53:36 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:53:36] [ विवरण] PQping() ने "PQPING_NO_RESPONSE" लौटाया फ़रवरी 5 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [सूचना] अगले पुन:संयोजन के प्रयास तक 8 सेकंड सो रहा है फ़रवरी 5 11:53:44 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:53:44] [जानकारी] नोड 1, 4 में से 2 प्रयासों की स्थिति की जांच फ़रवरी 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [चेतावनी] पिंग करने में असमर्थ "उपयोगकर्ता =repmgr कनेक्ट_टाइमआउट =2 dbname =repmgr होस्ट =16.0.1.156 फ़ॉलबैक_एप्लिकेशन_नाम =repmgr" फ़रवरी 5 11:53:44 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:53:44] [ विवरण] PQping() ने "PQPING_NO_RESPONSE" लौटाया फ़रवरी 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [सूचना] अगले पुन:जोड़ने के प्रयास तक 8 सेकंड सो रहा है फ़रवरी 5 11:53:52 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:53:52] [जानकारी] नोड 1, 4 में से 3 प्रयासों की स्थिति की जांच फ़रवरी 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [चेतावनी] पिंग करने में असमर्थ "उपयोगकर्ता =repmgr Connect_timeout =2 dbname =repmgr होस्ट =16.0.1.156 फ़ॉलबैक_एप्लिकेशन_नाम =repmgr" फ़रवरी 5 11:53:52 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:53:52] [ विवरण] PQping() ने "PQPING_NO_RESPONSE" लौटाया फ़रवरी 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [सूचना] अगले पुन:संयोजन के प्रयास तक 8 सेकंड सो रहा है फ़रवरी 5 11:54:00 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:54:00] [जानकारी] नोड 1 की स्थिति की जाँच, 4 में से 4 प्रयास फ़रवरी 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [चेतावनी] पिंग करने में असमर्थ "उपयोगकर्ता =repmgr कनेक्ट_टाइमआउट =2 dbname =repmgr होस्ट =16.0.1.156 फ़ॉलबैक_एप्लिकेशन_नाम =repmgr" फ़रवरी 5 11:54:00 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] [ विवरण] PQping() ने "PQPING_NO_RESPONSE" लौटाया फ़रवरी 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [चेतावनी] 4 प्रयासों के बाद नोड 1 से पुन:कनेक्ट करने में असमर्थ फ़रवरी 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [नोटिस] "wal_retrieve_retry_interval" को 86405000 मिलीसेकंड पर सेट करना फ़रवरी 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [चेतावनी] वाल रिसीवर नहीं चल रहा है फ़रवरी 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [नोटिस] WAL रिसीवर सभी सिबलिंग नोड्स पर डिस्कनेक्ट हो गया फ़रवरी 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [जानकारी] सभी 2 सिबलिंग नोड्स पर WAL रिसीवर डिस्कनेक्ट हो गया फ़रवरी 5 11:54:00 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] [जानकारी] स्थानीय नोड का अंतिम प्राप्त lsn:0/2214A000 फ़रवरी 5 11:54:00 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:54:00] [जानकारी] सिबलिंग नोड "पीजी-नोड3" (आईडी:3) की स्थिति की जांच कर रहा है। बी> फ़रवरी 5 11:54:00 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] <बी> [सूचना] नोड "पीजी-नोड 3" (आईडी:3) रिपोर्ट करता है कि इसका अपस्ट्रीम नोड 1 है , अंतिम बार 26 सेकंड पहले देखा गया फ़रवरी 5 11:54:00 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] [सूचना] नोड 3 ने अंतिम बार प्राथमिक नोड 26 सेकंड पहले देखा था फ़रवरी 5 11:54:00 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] [जानकारी] सिबलिंग नोड "पीजी-नोड 3" (आईडी:3) के लिए अंतिम बार एलएसएन प्राप्त करता है :0/2214A000 फ़रवरी 5 11:54:00 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] <बी> [सूचना] नोड "पीजी-नोड 3" (आईडी:3) में वर्तमान उम्मीदवार के समान एलएसएन है "पीजी-नोड2" (आईडी:2) फ़रवरी 5 11:54:00 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] <बी> [सूचना] नोड "पीजी-नोड 3" (आईडी:3) की प्राथमिकता कम है (40) वर्तमान उम्मीदवार "पीजी-नोड2" (आईडी:2) (60) . की तुलना में फरवरी 5 11:54:00 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] [जानकारी] सहोदर नोड "पीजी-नोड-गवाह" की स्थिति की जाँच (आईडी:4) फ़रवरी 5 11:54:00 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] <बी> [सूचना] नोड "पीजी-नोड-गवाह" (आईडी:4) इसकी अपस्ट्रीम रिपोर्ट करता है नोड 1, अंतिम बार 26 सेकंड पहले देखा गया फ़रवरी 5 11:54:00 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] [जानकारी] नोड 4 अंतिम बार प्राथमिक नोड 26 सेकंड पहले देखा गया था फ़रवरी 5 11:54:00 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:54:00] [जानकारी] दृश्यमान नोड्स:3; कुल नोड्स:3; पिछले 4 सेकंड में किसी भी नोड ने प्राथमिक को नहीं देखा है ……फरवरी 5 11:54:00 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] [नोटिस] पदोन्नति उम्मीदवार "पीजी-नोड 2" (आईडी:2) है। बी> फ़रवरी 5 11:54:00 पीजी-नोड2 प्रतिनिधि[2165]:[2020-02-05 11:54:00] [नोटिस] "wal_retrieve_retry_interval" को 5000 ms पर सेट करना फ़रवरी 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [नोटिस] यह नोड विजेता है, अब खुद को बढ़ावा देगा और अन्य नोड्स को सूचित करेगा …… फरवरी 5 11:54:00 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:00] [नोटिस] प्राथमिक से स्टैंडबाय को बढ़ावा दे रहा है फ़रवरी 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [विवरण] pg_promote() का उपयोग करके सर्वर "PG-Node2" (ID:2) का प्रचार कर रहा है फ़रवरी 5 11:54:00 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:54:00] [नोटिस] पदोन्नति के पूरा होने के लिए 60 सेकंड (पैरामीटर "promote_check_timeout") तक प्रतीक्षा कर रहा है फ़रवरी 5 11:54:01 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:54:01] [नोटिस] स्टैंडबाय प्रमोशन सफल फ़रवरी 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [DETAIL] सर्वर "PG-Node2" (ID:2) को सफलतापूर्वक प्राथमिक में पदोन्नत किया गया था फ़रवरी 5 11:54:01 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:54:01] [सूचना] 2 अनुयायियों को सूचित करने के लिए फ़रवरी 5 11:54:01 पीजी-नोड 2 प्रतिनिधि [2165]:[2020-02-05 11:54:01] [नोटिस] नोड "पीजी-नोड 3" (आईडी:3) को नोड 2 का पालन करने के लिए सूचित करना फ़रवरी 5 11:54:01 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:01] [नोटिस] नोड का पालन करने के लिए नोड "पीजी-नोड-विटनेस" (आईडी:4) को सूचित करना 2 फ़रवरी 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [सूचना] प्राथमिक निगरानी मोड में स्विच करना फ़रवरी 5 11:54:01 पीजी-नोड2 repmgrd[2165]:[2020-02-05 11:54:01] [नोटिस] निगरानी क्लस्टर प्राथमिक "पीजी-नोड2" (आईडी:2) फ़रवरी 5 11:54:07 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:07] [नोटिस] नया गवाह "पीजी-नोड-गवाह" (आईडी:4) जुड़ा हुआ है फ़रवरी 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [नोटिस] नया स्टैंडबाय "PG-Node3" (ID:3) कनेक्ट हो गया है फ़रवरी 5 11:54:07 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:54:07] [सूचना] नया अतिरिक्त "पीजी-नोड3" (आईडी:3) जुड़ा हुआ हैफरवरी 5 11:55:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:55:02] [INFO] सामान्य अवस्था में प्राथमिक नोड "PG-Node2" (ID:2) की निगरानी कर रहा है फ़रवरी 5 11:56:02 पीजी-नोड2 प्रतिनिधि [2165]:[2020-02-05 11:56:02] [सूचना] सामान्य स्थिति में प्राथमिक नोड "पीजी-नोड 2" (आईडी:2) की निगरानी ……
यहां बहुत सारी जानकारी है, लेकिन आइए देखें कि घटनाएं कैसे सामने आईं। For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
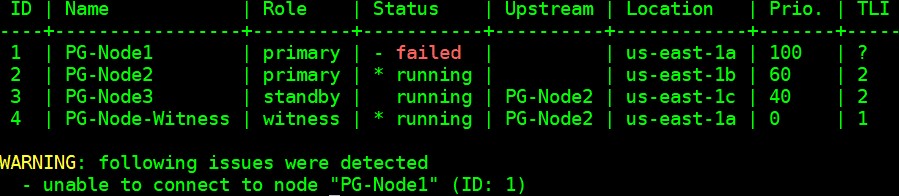
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | ठीक | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------3 | PG-Node3 | repmgrd_failover_follow | टी | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | टी | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID:2) 2 | PG-Node2 | child_node_new_connect | टी | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID:3) has connected 2 | PG-Node2 | child_node_new_connect | टी | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID:4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | टी | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID:2) 4 | PG-Node-Witness | repmgrd_failover_follow | टी | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | टी | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID:2) 2 | PG-Node2 | repmgrd_failover_promote | टी | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | टी | 2020-02-05 11:54:01 | server "PG-Node2" (ID:2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | टी | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID:4) has connected
निष्कर्ष
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1