क्या आपके SQL सर्वर डेटा प्रकारों की पसंद और उनके आकार मायने रखते हैं?
उत्तर आपको मिले परिणाम में निहित है। क्या आपका डेटाबेस कम समय में गुब्बारा हो गया? क्या आपके प्रश्न धीमे हैं? क्या आपके पास गलत परिणाम थे? इंसर्ट और अपडेट के दौरान रनटाइम त्रुटियों के बारे में क्या?
यदि आप जानते हैं कि आप क्या कर रहे हैं तो यह इतना कठिन काम नहीं है। आज, आप इन डेटा प्रकारों के साथ 5 सबसे खराब विकल्प सीखेंगे। अगर वे आपकी आदत बन गए हैं, तो यह वह चीज है जिसे हमें आपके और आपके उपयोगकर्ताओं के लिए ठीक करना चाहिए।
एसक्यूएल में ढेर सारे डेटा टाइप, ढेर सारे कन्फ्यूजन
जब मैंने पहली बार SQL सर्वर डेटा प्रकारों के बारे में सीखा, तो विकल्प भारी थे। मेरे दिमाग में सभी प्रकार मिश्रित हैं जैसे चित्र 1 में यह शब्द क्लाउड:

हालांकि, हम इसे श्रेणियों में व्यवस्थित कर सकते हैं:
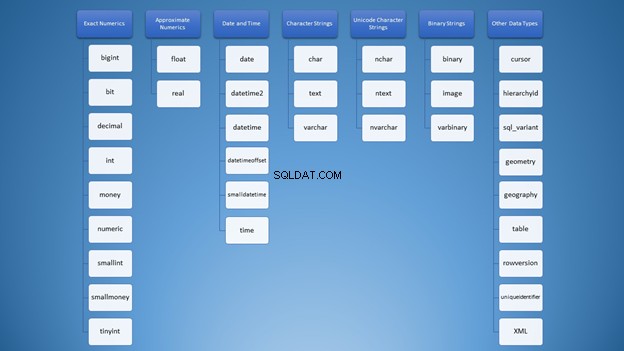
फिर भी, स्ट्रिंग्स का उपयोग करने के लिए, आपके पास बहुत सारे विकल्प हैं जो गलत उपयोग का कारण बन सकते हैं। पहले तो मुझे लगा कि varchar और नवरचर बस वही थे। इसके अलावा, वे दोनों वर्ण स्ट्रिंग प्रकार हैं। संख्याओं का उपयोग करना अलग नहीं है। डेवलपर्स के रूप में, हमें यह जानना होगा कि विभिन्न स्थितियों में किस प्रकार का उपयोग करना है।
लेकिन आपको आश्चर्य हो सकता है कि अगर मैं गलत चुनाव करता हूं तो सबसे बुरी चीज क्या हो सकती है? मैं आपको बता दूं!
1. गलत SQL डेटा प्रकार चुनना
यह आइटम बिंदु को साबित करने के लिए स्ट्रिंग्स और पूर्ण संख्याओं का उपयोग करेगा।
गलत वर्ण स्ट्रिंग SQL डेटा प्रकार का उपयोग करना
सबसे पहले, आइए स्ट्रिंग्स पर वापस जाएं। यूनिकोड और गैर-यूनिकोड स्ट्रिंग्स नामक यह चीज़ है। दोनों के अलग-अलग स्टोरेज साइज हैं। आप अक्सर इसे कॉलम और वेरिएबल डिक्लेरेशन पर परिभाषित करते हैं।
सिंटैक्स या तो varchar . है (एन)/चार (एन) या नवरचर (एन)/नचार (एन) जहां n आकार है।
ध्यान दें कि n वर्णों की संख्या नहीं बल्कि बाइट्स की संख्या है। यह एक आम ग़लतफ़हमी है जो इसलिए होती है, क्योंकि varchar . में , वर्णों की संख्या बाइट्स में आकार के समान है। लेकिन nvarchar . में नहीं ।
इस तथ्य को साबित करने के लिए, आइए 2 टेबल बनाएं और उनमें कुछ डेटा डालें।
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
अब DATALENGTH का उपयोग करके उनकी पंक्ति के आकार की जांच करते हैं।
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
चित्रा 3 से पता चलता है कि अंतर दो गुना है। इसे नीचे देखें।
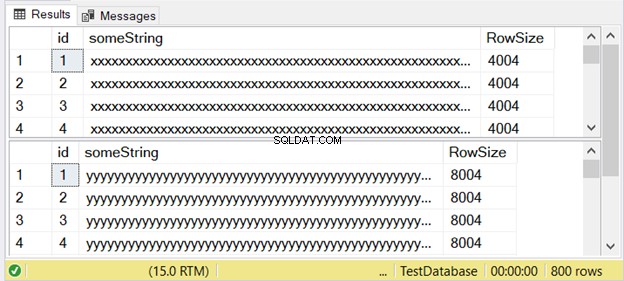
8004 के पंक्ति आकार के साथ सेट किए गए दूसरे परिणाम पर ध्यान दें। यह nvarchar . का उपयोग करता है डेटा प्रकार। यह पहले परिणाम सेट के पंक्ति आकार से भी लगभग दोगुना बड़ा है। और यह varchar . का उपयोग करता है डेटा प्रकार।
आप भंडारण और I/O पर प्रभाव देखते हैं। चित्र 4 2 प्रश्नों के तार्किक पठन को दर्शाता है।
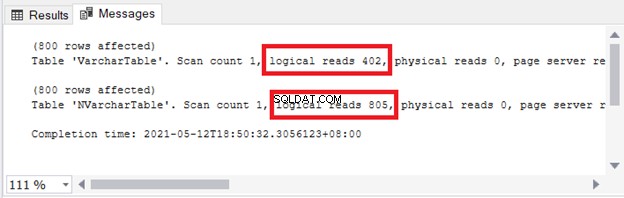
देखो? nvarchar . का उपयोग करते समय तार्किक पठन भी दो गुना होता है वर्चर . की तुलना में ।
तो, आप केवल एक दूसरे का परस्पर उपयोग नहीं कर सकते। यदि आपको बहुभाषी स्टोर करने की आवश्यकता है वर्ण, nvarchar . का उपयोग करें . अन्यथा, varchar . का उपयोग करें ।
इसका मतलब है कि अगर आप nvarchar . का इस्तेमाल करते हैं केवल सिंगल-बाइट वर्णों के लिए (अंग्रेज़ी की तरह), संग्रहण आकार अधिक है . क्वेरी का प्रदर्शन उच्च तार्किक पढ़ने के साथ धीमा भी है।
SQL सर्वर 2019 (और उच्चतर) में, आप varchar का उपयोग करके यूनिकोड वर्ण डेटा की पूरी श्रृंखला संग्रहीत कर सकते हैं या चार UTF-8 संयोजन विकल्पों में से किसी के साथ।
गलत संख्यात्मक डेटा प्रकार SQL का उपयोग करना
bigint . के साथ भी यही अवधारणा लागू होती है बनाम int - उनके आकार का मतलब रात और दिन हो सकता है। जैसे nvarchar और वर्चर , बिगिंट int . के आकार से दोगुना है (बिगिंट . के लिए 8 बाइट्स और int . के लिए 4 बाइट्स )।
फिर भी, एक और समस्या संभव है। यदि आप उनके आकार पर ध्यान नहीं देते हैं, तो त्रुटियां हो सकती हैं। यदि आप int . का उपयोग करते हैं 2,147,483,647 से बड़ी संख्या को कॉलम और स्टोर करें, एक अंकगणितीय अतिप्रवाह होगा:
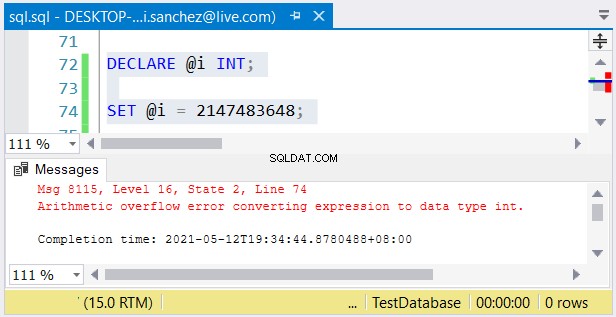
पूर्ण संख्या प्रकार चुनते समय, सुनिश्चित करें कि अधिकतम मान वाला डेटा फिट होगा . उदाहरण के लिए, हो सकता है कि आप ऐतिहासिक डेटा वाली तालिका डिज़ाइन कर रहे हों। आप प्राथमिक कुंजी मान के रूप में पूर्ण संख्याओं का उपयोग करने की योजना बना रहे हैं। क्या आपको लगता है कि यह 2,147,483,647 पंक्तियों तक नहीं पहुंचेगा? फिर int . का उपयोग करें बिगिन्ट . के बजाय प्राथमिक कुंजी कॉलम प्रकार के रूप में।
सबसे बुरी चीज जो हो सकती है
गलत डेटा प्रकार चुनने से क्वेरी प्रदर्शन प्रभावित हो सकता है या रनटाइम त्रुटियाँ हो सकती हैं। इस प्रकार, डेटा के लिए सही डेटा प्रकार चुनें।
2. SQL के लिए बड़े डेटा प्रकारों का उपयोग करके बड़ी तालिका पंक्तियाँ बनाना
हमारा अगला आइटम पहले वाले से संबंधित है, लेकिन यह उदाहरणों के साथ बिंदु को और भी विस्तृत करेगा। साथ ही, इसका पृष्ठों और बड़े आकार के varchar . से कुछ लेना-देना है या नवरचर कॉलम।
पेज और रो साइज में क्या है?
SQL सर्वर में पृष्ठों की अवधारणा की तुलना सर्पिल नोटबुक के पृष्ठों से की जा सकती है। नोटबुक के प्रत्येक पृष्ठ का भौतिक आकार समान होता है। आप शब्द लिखते हैं और उन पर चित्र बनाते हैं। यदि कोई पृष्ठ अनुच्छेदों और चित्रों के एक सेट के लिए पर्याप्त नहीं है, तो आप अगले पृष्ठ पर जारी रखते हैं। कभी-कभी, आप एक पन्ने को फाड़ भी देते हैं और फिर से शुरू कर देते हैं।
इसी तरह, SQL सर्वर में तालिका डेटा, अनुक्रमणिका प्रविष्टियाँ और चित्र पृष्ठों में संग्रहीत किए जाते हैं।
एक पृष्ठ का आकार समान 8 KB है। यदि डेटा की एक पंक्ति बहुत बड़ी है, तो वह 8 KB पृष्ठ में फ़िट नहीं होगी। ROW_OVERFLOW_DATA आवंटन इकाई के अंतर्गत दूसरे पृष्ठ पर एक या अधिक कॉलम लिखे जाएंगे। इसमें IN_ROW_DATA आवंटन इकाई के अंतर्गत पृष्ठ पर मूल पंक्ति के लिए एक सूचक होता है।
इसके आधार पर, आप डेटाबेस डिज़ाइन के दौरान तालिका में बहुत सारे कॉलम फिट नहीं कर सकते। I/O पर परिणाम होंगे। साथ ही, यदि आप इन पंक्ति-ओवरफ़्लो डेटा पर बहुत अधिक क्वेरी करते हैं, तो निष्पादन समय धीमा होता है . यह एक बुरा सपना हो सकता है।
एक समस्या तब उत्पन्न होती है जब आप सभी भिन्न-आकार के स्तंभों को अधिकतम करते हैं। फिर, डेटा अगले पृष्ठ पर ROW_OVERFLOW_DATA के अंतर्गत फैल जाएगा। कॉलम को छोटे आकार के डेटा के साथ अपडेट करें, और इसे उस पृष्ठ पर निकालने की आवश्यकता है। नई छोटी डेटा पंक्ति अन्य स्तंभों के साथ IN_ROW_DATA के अंतर्गत पृष्ठ पर लिखी जाएगी। कल्पना कीजिए कि I/O यहां शामिल है।
बड़ी पंक्ति का उदाहरण
आइए पहले अपना डेटा तैयार करें। हम बड़े आकार वाले वर्ण स्ट्रिंग डेटा प्रकारों का उपयोग करेंगे।
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
पंक्ति का आकार प्राप्त करना
जेनरेट किए गए डेटा से, DATALENGTH के आधार पर उनकी पंक्ति के आकार का निरीक्षण करें।
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
पहले 300 रिकॉर्ड IN_ROW_DATA पृष्ठों में फिट होंगे क्योंकि प्रत्येक पंक्ति में 8060 बाइट्स या 8 केबी से कम है। लेकिन अंतिम 100 पंक्तियाँ बहुत बड़ी हैं। चित्र 6 में निर्धारित परिणाम देखें।
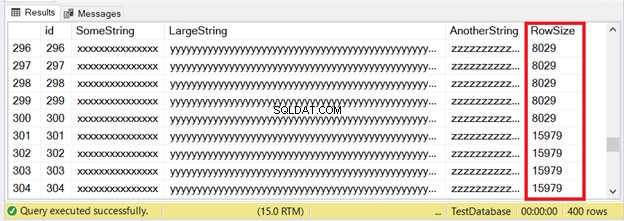
आप पहली 300 पंक्तियों का हिस्सा देखते हैं। अगले 100 पृष्ठ आकार सीमा से अधिक हैं। हमें कैसे पता चलेगा कि अंतिम 100 पंक्तियाँ ROW_OVERFLOW_DATA आवंटन इकाई में हैं?
ROW_OVERFLOW_DATA का निरीक्षण करना
हम sys.dm_db_index_physical_stats . का उपयोग करेंगे . यह तालिका और अनुक्रमणिका प्रविष्टियों के बारे में पृष्ठ जानकारी देता है।
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
परिणाम सेट चित्र 7 में है।

वहाँ है। चित्र 7 ROW_OVERFLOW_DATA के अंतर्गत 100 पंक्तियाँ दिखाता है। यह चित्र 6 के अनुरूप है जब 301 से 400 पंक्तियों से शुरू होने वाली बड़ी पंक्तियाँ मौजूद होती हैं।
अगला सवाल यह है कि जब हम इन 100 पंक्तियों को क्वेरी करते हैं तो हमें कितने लॉजिकल रीड मिलते हैं। आइए कोशिश करते हैं।
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

हम LargeTable . के 102 लॉजिकल रीड और 100 लॉब लॉजिकल रीड्स देखते हैं . इन नंबरों को अभी के लिए छोड़ दें - हम बाद में इनकी तुलना करेंगे।
अब, देखते हैं कि अगर हम 100 पंक्तियों को छोटे डेटा के साथ अपडेट करते हैं तो क्या होता है।
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
यह अपडेट स्टेटमेंट उसी लॉजिकल रीड्स और लॉब लॉजिकल रीड्स का उपयोग करता है जैसा कि चित्र 8 में है। इससे, हम जानते हैं कि 100 पृष्ठों के लोब लॉजिकल रीड्स के कारण कुछ बड़ा हुआ।
लेकिन यह सुनिश्चित करने के लिए, आइए इसे sys.dm_db_index_physical_stats से देखें। जैसा कि हमने पहले किया था। चित्र 9 परिणाम दिखाता है:

चला गया! 100 पंक्तियों को छोटे डेटा के साथ अपडेट करने के बाद ROW_OVERFLOW_DATA के पृष्ठ और पंक्तियाँ शून्य हो गईं। अब हम जानते हैं कि ROW_OVERFLOW_DATA से IN_ROW_DATA तक डेटा की आवाजाही तब होती है जब बड़ी पंक्तियाँ सिकुड़ जाती हैं। कल्पना कीजिए कि यह हजारों या लाखों रिकॉर्ड के लिए बहुत कुछ होता है। पागल, है ना?
चित्र 8 में, हमने 100 लोब लॉजिकल रीड्स देखे। अब, क्वेरी को फिर से चलाने के बाद चित्र 10 देखें:

यह शून्य हो गया!
सबसे बुरी चीज जो हो सकती है
धीमी क्वेरी प्रदर्शन पंक्ति-ओवरफ़्लो डेटा का उप-उत्पाद है। इससे बचने के लिए बड़े आकार के कॉलम को दूसरी टेबल पर ले जाने पर विचार करें। या, यदि लागू हो, varchar . का आकार कम करें या नवरचर कॉलम।
3. अंतर्निहित रूपांतरण का अंधाधुंध उपयोग
SQL हमें प्रकार निर्दिष्ट किए बिना डेटा का उपयोग करने की अनुमति नहीं देता है। लेकिन अगर हम गलत चुनाव करते हैं तो यह क्षमाशील है। यह मान को उस प्रकार में बदलने की कोशिश करता है जिसकी वह अपेक्षा करता है, लेकिन एक दंड के साथ। यह WHERE क्लॉज या JOIN में हो सकता है।
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
कार्ड नंबर कॉलम एक संख्यात्मक प्रकार नहीं है। यह nvarchar . है . तो, पहला चयन एक अंतर्निहित रूपांतरण का कारण बनता है। हालांकि, दोनों ठीक चलेंगे और समान परिणाम सेट करेंगे।
आइए चित्र 11 में निष्पादन योजना की जाँच करें।
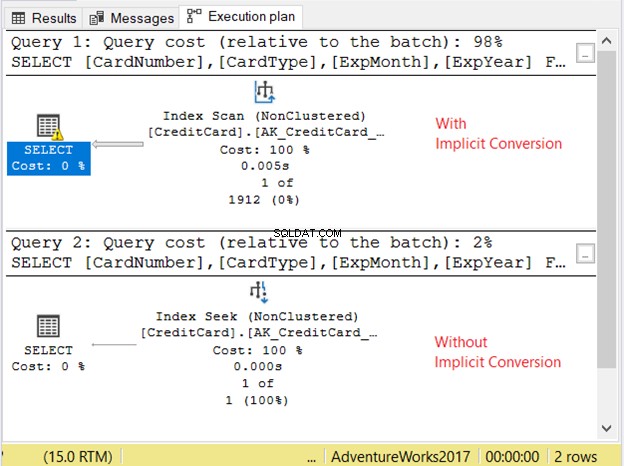
2 प्रश्न बहुत जल्दी चले। चित्र 11 में, यह शून्य सेकंड है। लेकिन 2 योजनाओं को देखें। निहित रूपांतरण वाले के पास एक इंडेक्स स्कैन था। एक चेतावनी आइकन और एक मोटा तीर भी है जो सेलेक्ट ऑपरेटर की ओर इशारा करता है। यह हमें बताता है कि यह खराब है।
लेकिन यह वहां खत्म नहीं होता है। यदि आप अपने माउस को सेलेक्ट ऑपरेटर पर मँडराते हैं, तो आपको कुछ और दिखाई देगा:

चयन ऑपरेटर में चेतावनी आइकन निहित रूपांतरण के बारे में है। लेकिन प्रभाव कितना बड़ा है? आइए तार्किक पठन की जाँच करें।
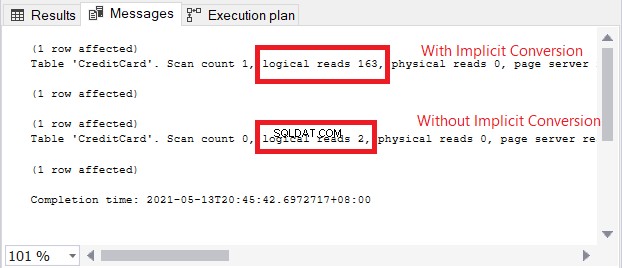
चित्र 13 में तार्किक पठन की तुलना स्वर्ग और पृथ्वी के समान है। क्रेडिट कार्ड की जानकारी के लिए पूछताछ में, निहित रूपांतरण के कारण सौ गुना से अधिक तार्किक पठन हुआ। बहुत बुरा!
सबसे बुरी चीज जो हो सकती है
यदि एक निहित रूपांतरण के कारण उच्च तार्किक पठन और एक खराब योजना होती है, तो बड़े परिणाम सेट पर धीमी क्वेरी प्रदर्शन की अपेक्षा करें। इससे बचने के लिए, WHERE क्लॉज में सटीक डेटा प्रकार का उपयोग करें और आपके द्वारा तुलना किए जाने वाले कॉलम के मिलान में जॉइन करें।
4. अनुमानित अंकों का उपयोग करना और इसे पूर्णांकित करना
चित्र 2 को फिर से देखें। अनुमानित अंकों से संबंधित SQL सर्वर डेटा प्रकार हैं फ्लोट और असली . उनसे बने कॉलम और वेरिएबल एक संख्यात्मक मान के निकट सन्निकटन को संग्रहीत करते हैं। यदि आप इन नंबरों को ऊपर या नीचे करने की योजना बनाते हैं, तो आपको एक बड़ा आश्चर्य हो सकता है। मेरे पास एक लेख है जिसने यहां इस पर विस्तार से चर्चा की है। देखें कि 1 + 1 का परिणाम 3 में कैसे होता है और आप पूर्णांकन संख्याओं से कैसे निपट सकते हैं।
सबसे बुरी चीज जो हो सकती है
एक फ्लोट को गोल करना या असली पागल परिणाम हो सकते हैं। यदि आप पूर्णांकन के बाद सटीक मान चाहते हैं, तो दशमलव . का उपयोग करें या संख्यात्मक इसके बजाय।
5. निश्चित आकार के स्ट्रिंग डेटा प्रकारों को NULL पर सेट करना
आइए अपना ध्यान निश्चित आकार के डेटा प्रकारों जैसे char . की ओर लगाएं और nchar . गद्देदार स्थानों के अलावा, उन्हें NULL पर सेट करने से अभी भी एक भंडारण आकार char के आकार के बराबर होगा कॉलम। तो, एक char . सेट करना (500) कॉलम से NULL तक का आकार 500 होगा, न कि शून्य या 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
उपरोक्त कोड में, char . के आकार के आधार पर डेटा को अधिकतम किया जाता है और वर्चर स्तंभ। DATALENGTH का उपयोग करके उनकी पंक्ति के आकार की जाँच करना प्रत्येक कॉलम के आकार का योग भी दिखाएगा। अब कॉलम को NULL पर सेट करते हैं।
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
इसके बाद, हम DATALENGTH का उपयोग करके पंक्तियों को क्वेरी करते हैं:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
आपको क्या लगता है कि प्रत्येक कॉलम का डेटा आकार क्या होगा? चित्र 14 देखें।
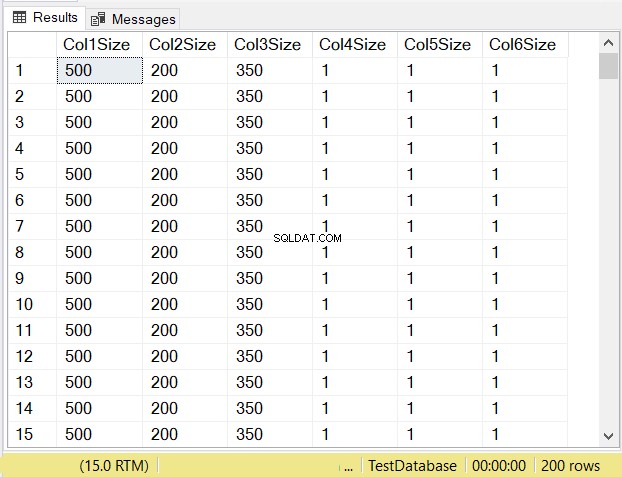
पहले 3 कॉलम के कॉलम साइज को देखें। फिर उनकी तुलना ऊपर दिए गए कोड से करें जब तालिका बनाई गई थी। NULL कॉलम का डेटा आकार कॉलम के आकार के बराबर होता है। इस बीच, varchar कॉलम जब NULL का डेटा आकार 1 होता है।
सबसे बुरी चीज जो हो सकती है
डिजाइनिंग टेबल के दौरान, अशक्त char कॉलम, जब NULL पर सेट होते हैं, तब भी उनके पास समान संग्रहण आकार होगा। वे एक ही पेज और रैम का भी उपभोग करेंगे। यदि आप पूरे कॉलम को वर्णों से नहीं भरते हैं, तो varchar . का उपयोग करने पर विचार करें इसके बजाय।
आगे क्या है?
तो, क्या SQL सर्वर डेटा प्रकारों में आपकी पसंद और उनके आकार मायने रखते हैं? यहां प्रस्तुत बिंदु एक बिंदु बनाने के लिए पर्याप्त होने चाहिए। तो, अब आप क्या कर सकते हैं?
- आपके द्वारा समर्थित डेटाबेस की समीक्षा करने के लिए समय निकालें। यदि आपकी प्लेट में कई हैं तो सबसे आसान से शुरू करें। और हाँ, समय बनाओ, समय नहीं खोजो। हमारे कार्यक्षेत्र में, समय निकालना लगभग असंभव है।
- तालिकाओं, संग्रहीत कार्यविधियों और डेटा प्रकारों से संबंधित किसी भी चीज़ की समीक्षा करें। समस्याओं की पहचान करते समय सकारात्मक प्रभाव पर ध्यान दें। आपको इसकी आवश्यकता तब होगी जब आपका बॉस पूछे कि आपको इस पर काम क्यों करना है।
- समस्या क्षेत्रों में से प्रत्येक पर हमला करने की योजना बनाएं। समस्याओं से निपटने के लिए आपकी कंपनी की जो भी कार्यप्रणाली या नीतियां हैं, उनका पालन करें।
- समस्याएं दूर होने के बाद, जश्न मनाएं।
सुनने में आसान लगता है, लेकिन हम सभी जानते हैं कि ऐसा नहीं है। हम यह भी जानते हैं कि यात्रा के अंत में एक उज्ज्वल पक्ष है। इसलिए उन्हें समस्याएं कहा जाता है - क्योंकि एक उपाय है। तो खुश हो जाइए।
क्या आपके पास इस विषय में जोड़ने के लिए कुछ और है? चलो टिप्पड़ियों के अनुभाग से पता करते हैं। और अगर इस पोस्ट ने आपको एक उज्ज्वल विचार दिया है, तो इसे अपने पसंदीदा सोशल मीडिया प्लेटफॉर्म पर साझा करें।