माध्यिका की एक सरल परिभाषा है:
माध्यिका संख्याओं की क्रमबद्ध सूची में मध्य मान हैइसे थोड़ा दूर करने के लिए, हम निम्नलिखित प्रक्रिया का उपयोग करके संख्याओं की सूची का माध्यिका ज्ञात कर सकते हैं:
- संख्याओं को क्रमबद्ध करें (आरोही या अवरोही क्रम में, इससे कोई फर्क नहीं पड़ता)।
- क्रमबद्ध सूची में मध्य संख्या (स्थिति के अनुसार) माध्यिका होती है।
- यदि दो "समान रूप से मध्य" संख्याएँ हैं, तो माध्यिका दो मध्य मानों का औसत है।
आरोन बर्ट्रेंड ने पहले SQL सर्वर में माध्यिका की गणना करने के कई तरीकों का प्रदर्शन-परीक्षण किया है:
- माध्यिका की गणना करने का सबसे तेज़ तरीका क्या है?
- समूहीकृत माध्यिका के लिए सर्वोत्तम दृष्टिकोण
रॉब फ़ार्ले ने हाल ही में 2012 से पहले की स्थापनाओं के उद्देश्य से एक और दृष्टिकोण जोड़ा:
- मीडियन प्री-एसक्यूएल 2012
यह लेख डायनेमिक कर्सर का उपयोग करके एक नई विधि का परिचय देता है।
2012 ऑफ़सेट-फ़ेच विधि
हम पीटर लार्सन द्वारा बनाए गए सर्वोत्तम प्रदर्शन करने वाले कार्यान्वयन को देखकर शुरू करेंगे। यह SQL सर्वर 2012 का उपयोग करता है OFFSET ORDER BY . का विस्तार माध्यिका की गणना के लिए आवश्यक एक या दो मध्य पंक्तियों को कुशलतापूर्वक खोजने के लिए खंड।
ऑफसेट सिंगल मेडियन
हारून के पहले लेख ने दस मिलियन पंक्ति तालिका से अधिक एकल माध्यिका की गणना का परीक्षण किया:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); पर अद्वितीय क्लस्टर इंडेक्स cx बनाएं
OFFSET . का उपयोग करके पीटर लार्सन का समाधान एक्सटेंशन है:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); उपरोक्त कोड तालिका में पंक्तियों की गिनती के परिणाम को हार्ड-कोड करता है। माध्यिका की गणना के लिए सभी परीक्षण विधियों को माध्यिका पंक्ति संख्याओं की गणना करने के लिए इस गणना की आवश्यकता होती है, इसलिए यह एक स्थिर लागत है। पंक्ति-गणना संचालन को समय से बाहर छोड़ने से भिन्नता के एक संभावित स्रोत से बचा जा सकता है।
OFFSET . के लिए निष्पादन योजना समाधान नीचे दिखाया गया है:

शीर्ष ऑपरेटर जल्दी से अनावश्यक पंक्तियों को छोड़ देता है, स्ट्रीम एग्रीगेट पर माध्यिका की गणना करने के लिए आवश्यक केवल एक या दो पंक्तियों को पास करता है। वार्म कैश और निष्पादन योजना संग्रह के साथ चलने पर, यह क्वेरी 910 ms के लिए चलती है मेरे लैपटॉप पर औसतन। यह एक मशीन है जिसमें Intel i7 740QM प्रोसेसर है जो 1.73 GHz पर चल रहा है और टर्बो अक्षम (संगति के लिए) है।
ऑफसेट समूहीकृत माध्यिका
हारून के दूसरे लेख ने प्रति समूह एक माध्यिका की गणना के प्रदर्शन का परीक्षण किया, जिसमें एक लाख पंक्ति बिक्री तालिका का उपयोग किया गया था जिसमें एक सौ बिक्री वाले लोगों में से प्रत्येक के लिए दस हजार प्रविष्टियां थीं:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
फिर से, सबसे अच्छा प्रदर्शन करने वाला समाधान OFFSET . का उपयोग करता है :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); निष्पादन योजना का महत्वपूर्ण भाग नीचे दिखाया गया है:

योजना की शीर्ष पंक्ति प्रत्येक बिक्री व्यक्ति के लिए समूह पंक्ति गणना खोजने से संबंधित है। निचली पंक्ति प्रत्येक बिक्री व्यक्ति के लिए माध्यिका की गणना करने के लिए एकल-समूह माध्यिका समाधान के लिए देखे गए समान योजना तत्वों का उपयोग करती है। जब एक गर्म कैश के साथ चलाया जाता है और निष्पादन योजना बंद हो जाती है, तो यह क्वेरी 320 ms . में निष्पादित होती है मेरे लैपटॉप पर औसतन।
डायनामिक कर्सर का उपयोग करना
माध्यिका की गणना के लिए कर्सर का उपयोग करने के बारे में सोचना भी पागल लग सकता है। धीमी और अक्षम होने के लिए ट्रांजैक्ट एसक्यूएल कर्सर की (ज्यादातर अच्छी तरह से योग्य) प्रतिष्ठा है। यह भी अक्सर सोचा जाता है कि गतिशील कर्सर सबसे खराब प्रकार के कर्सर होते हैं। ये बिंदु कुछ परिस्थितियों में मान्य हैं, लेकिन हमेशा नहीं।
ट्रांजैक्ट एसक्यूएल कर्सर एक समय में एक पंक्ति को संसाधित करने तक सीमित हैं, इसलिए यदि कई पंक्तियों को लाने और संसाधित करने की आवश्यकता है तो वे वास्तव में धीमे हो सकते हैं। हालांकि माध्यिका गणना के लिए ऐसा नहीं है:हमें केवल एक या दो मध्य मानों का पता लगाने और उन्हें लाने की जरूरत है कुशलतापूर्वक . जैसा कि हम देखेंगे, एक गतिशील कर्सर इस कार्य के लिए बहुत उपयुक्त है।
एकल माध्य डायनामिक कर्सर
एकल माध्य गणना के लिए गतिशील कर्सर समाधान में निम्नलिखित चरण होते हैं:
- आइटम की ऑर्डर की गई सूची पर एक गतिशील स्क्रॉल करने योग्य कर्सर बनाएं।
- पहली माध्यिका पंक्ति की स्थिति की गणना करें।
FETCH RELATIVE. का उपयोग करके कर्सर की स्थिति बदलें .- यह तय करें कि माध्यिका की गणना के लिए दूसरी पंक्ति की आवश्यकता है या नहीं।
- यदि नहीं, तो एकल माध्य मान तुरंत लौटाएं।
- अन्यथा,
FETCH NEXT. का उपयोग करके दूसरा मान प्राप्त करें . - दो मानों के औसत की गणना करें और वापसी करें।
ध्यान दें कि यह सूची इस लेख के प्रारंभ में दी गई माध्यिका ज्ञात करने की सरल प्रक्रिया को कितनी बारीकी से दर्शाती है। एक पूर्ण Transact SQL कोड कार्यान्वयन नीचे दिखाया गया है:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
FETCH RELATIVE . के लिए निष्पादन योजना स्टेटमेंट दिखाता है कि डायनेमिक कर्सर कुशलतापूर्वक पहली पंक्ति में मध्यिका गणना के लिए आवश्यक है:
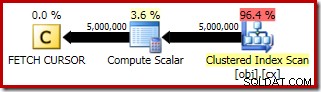
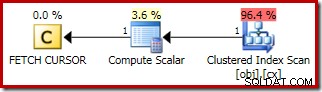
FETCH NEXT . के लिए योजना (केवल तभी आवश्यक है जब कोई दूसरी मध्य पंक्ति हो, जैसा कि इन परीक्षणों में है) कर्सर की सहेजी गई स्थिति से एक एकल पंक्ति प्राप्त करना है:
यहाँ एक गतिशील कर्सर का उपयोग करने के लाभ हैं:
- यह पूरे सेट को पार करने से बचता है (माध्यिका पंक्तियों के मिलने के बाद पढ़ना बंद हो जाता है); और
- डेटा की कोई अस्थायी प्रतिलिपि tempdb में नहीं बनाई गई है , जैसा कि यह एक स्थिर या कीसेट कर्सर के लिए होगा।
ध्यान दें कि हम FAST_FORWARD निर्दिष्ट नहीं कर सकते हैं यहां कर्सर (स्थैतिक या गतिशील-जैसी योजना के विकल्प को छोड़कर) क्योंकि FETCH RELATIVE का समर्थन करने के लिए कर्सर को स्क्रॉल करने योग्य होना चाहिए . वैसे भी यहां डायनामिक सबसे अच्छा विकल्प है।
वार्म कैश और निष्पादन योजना संग्रह के साथ चलने पर, यह क्वेरी 930 ms तक चलती है मेरी परीक्षण मशीन पर औसतन। यह 910 ms . से थोड़ा धीमा है OFFSET . के लिए समाधान, लेकिन डायनेमिक कर्सर हारून और रॉब द्वारा परीक्षण किए गए अन्य तरीकों की तुलना में काफी तेज है, और इसके लिए SQL Server 2012 (या बाद में) की आवश्यकता नहीं है।
मैं यहां 2012 से पहले के अन्य तरीकों के परीक्षण को दोहराने नहीं जा रहा हूं, लेकिन प्रदर्शन अंतराल के आकार के उदाहरण के रूप में, निम्न पंक्ति-क्रमांकन समाधान में 1550 ms लगता है। औसतन (70% धीमा):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

समूहीकृत माध्य गतिशील कर्सर परीक्षण
समूहीकृत माध्यिकाओं की गणना करने के लिए एकल माध्य गतिशील कर्सर समाधान का विस्तार करना आसान है। निरंतरता के लिए, मैं नेस्टेड कर्सर (हाँ, वास्तव में) का उपयोग करने जा रहा हूँ:
- बिक्री वाले लोगों और पंक्तियों की संख्या पर एक स्थिर कर्सर खोलें।
- हर बार एक नए डायनेमिक कर्सर का उपयोग करके प्रत्येक व्यक्ति के लिए माध्यिका की गणना करें।
- हर परिणाम को टेबल वेरिएबल में सेव करें जैसे हम आगे बढ़ते हैं।
कोड नीचे दिखाया गया है:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); बाहरी कर्सर जानबूझकर स्थिर है क्योंकि उस सेट की सभी पंक्तियों को स्पर्श किया जाएगा (भी, एक गतिशील कर्सर अंतर्निहित क्वेरी में ग्रुपिंग ऑपरेशन के कारण उपलब्ध नहीं है)। इस बार निष्पादन योजनाओं में देखने के लिए विशेष रूप से नया या दिलचस्प कुछ भी नहीं है।
दिलचस्प बात प्रदर्शन है। आंतरिक गतिशील कर्सर के बार-बार निर्माण और विलोपन के बावजूद, यह समाधान परीक्षण डेटा सेट पर वास्तव में अच्छा प्रदर्शन करता है। वार्म कैश और निष्पादन योजनाओं के बंद होने के साथ, कर्सर स्क्रिप्ट 330 ms . में पूरी होती है मेरी परीक्षण मशीन पर औसतन। यह 320 ms . की तुलना में फिर से थोड़ा धीमा है OFFSET . द्वारा रिकॉर्ड किया गया समूहीकृत माध्यिका, लेकिन यह आरोन और रॉब के लेखों में सूचीबद्ध अन्य मानक समाधानों को बड़े अंतर से पीछे छोड़ देता है।
फिर से, अन्य गैर-2012 विधियों के प्रदर्शन अंतराल के एक उदाहरण के रूप में, निम्न पंक्ति-क्रमांकन समाधान 485 ms के लिए चलता है मेरे परीक्षण रिग पर औसतन (50% बदतर):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

परिणाम सारांश
सिंगल मीडियन टेस्ट में डायनेमिक कर्सर 930 ms . तक चला बनाम 910 एमएस OFFSET . के लिए विधि।
समूहीकृत माध्यिका परीक्षण में, नेस्टेड कर्सर 330 ms तक चला बनाम 320 एमएस OFFSET . के लिए ।
दोनों ही मामलों में, कर्सर विधि अन्य गैर-OFFSET . की तुलना में काफी तेज थी तरीके। यदि आपको 2012 से पहले के उदाहरण पर एकल या समूहीकृत माध्यिका की गणना करने की आवश्यकता है, तो एक गतिशील कर्सर या नेस्टेड कर्सर वास्तव में इष्टतम विकल्प हो सकता है।
कोल्ड कैश प्रदर्शन
आप में से कुछ लोग कोल्ड कैश प्रदर्शन के बारे में सोच रहे होंगे। प्रत्येक परीक्षण से पहले निम्नलिखित को चलाना:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
ये एकल माध्य परीक्षण के परिणाम हैं:
OFFSET विधि:940 एमएस
गतिशील कर्सर:955 एमएस
समूहीकृत माध्यिका के लिए:
OFFSET विधि:380 एमएस
नेस्टेड कर्सर:385 ms
अंतिम विचार
डायनामिक कर्सर समाधान वास्तव में गैर-OFFSET . की तुलना में काफी तेज हैं कम से कम इन नमूना डेटा सेटों के साथ एकल और समूहीकृत माध्यिका दोनों के लिए तरीके। मैंने जानबूझकर हारून के परीक्षण डेटा का पुन:उपयोग करना चुना ताकि डेटा सेट जानबूझकर गतिशील कर्सर की ओर तिरछा न हो। वहाँ हो सकता है अन्य डेटा वितरण हो जिसके लिए डायनेमिक कर्सर एक अच्छा विकल्प नहीं है। फिर भी, यह दिखाता है कि अभी भी ऐसे समय हैं जब एक कर्सर सही प्रकार की समस्या का तेज़ और कुशल समाधान हो सकता है। यहां तक कि गतिशील और नेस्टेड कर्सर भी।
ईगल आंखों वाले पाठकों ने PAGLOCK . पर ध्यान दिया होगा OFFSET में संकेत दें समूहीकृत माध्य परीक्षण। सर्वश्रेष्ठ प्रदर्शन के लिए यह आवश्यक है, जिन कारणों से मैं अपने अगले लेख में चर्चा करूंगा। इसके बिना, 2012 का समाधान वास्तव में नेस्टेड कर्सर से एक अच्छे अंतर से हार जाता है (590ms बनाम 330ms )।