आपके डेटाबेस में संदर्भ तालिकाएँ होना कोई बड़ी बात नहीं है, है ना? आपको बस प्रत्येक संदर्भ प्रकार के विवरण के साथ एक कोड या आईडी टाई करने की आवश्यकता है। लेकिन क्या होगा यदि आपके पास सचमुच दर्जनों और दर्जनों संदर्भ तालिकाएं हैं? क्या एक-टेबल-प्रति-प्रकार दृष्टिकोण का कोई विकल्प है? सामान्य और एक्स्टेंसिबल . खोजने के लिए आगे पढ़ें आपके सभी संदर्भ डेटा को संभालने के लिए डेटाबेस डिज़ाइन।
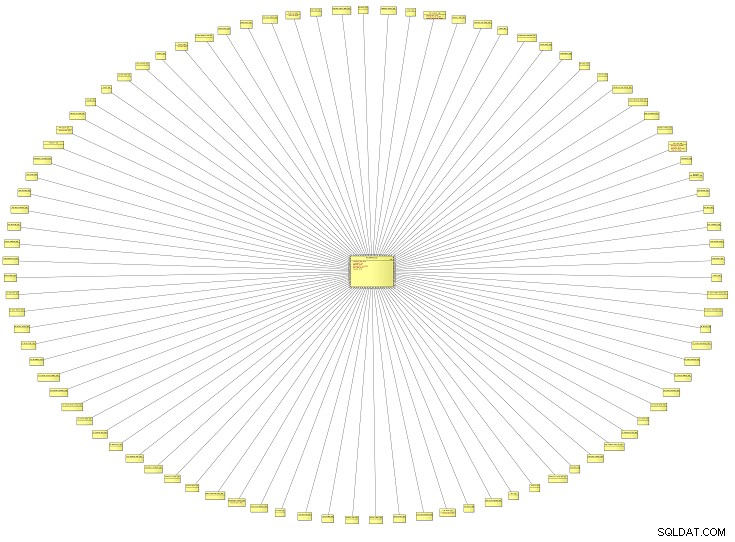
यह असामान्य दिखने वाला आरेख एक तार्किक डेटा मॉडल (एलडीएम) का एक विहंगम दृश्य है जिसमें एंटरप्राइज़ सिस्टम के लिए सभी संदर्भ प्रकार शामिल हैं। यह एक शैक्षणिक संस्थान से है, लेकिन यह किसी भी प्रकार के संगठन के डेटा मॉडल पर लागू हो सकता है। मॉडल जितना बड़ा होगा, उतने अधिक संदर्भ प्रकार आपके सामने आने की संभावना है।
संदर्भ प्रकारों से मेरा मतलब संदर्भ डेटा, या लुकअप मान, या - यदि आप फ़्लैश होना चाहते हैं - टैक्सोनॉमी . आमतौर पर, यहां परिभाषित मान आपके एप्लिकेशन के यूजर इंटरफेस में ड्रॉप-डाउन सूचियों में उपयोग किए जाते हैं। वे किसी रिपोर्ट के शीर्षक के रूप में भी दिखाई दे सकते हैं।
इस विशेष डेटा मॉडल में लगभग 100 संदर्भ प्रकार थे। आइए ज़ूम इन करें और उनमें से केवल दो को देखें।
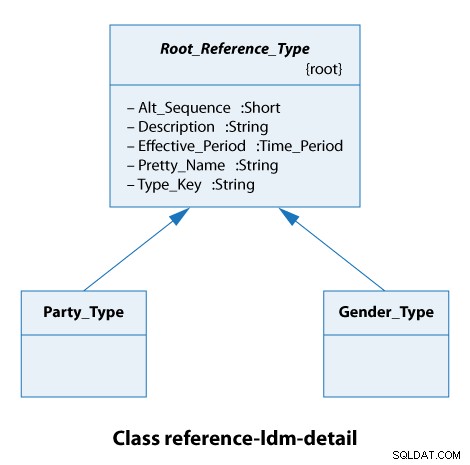
इस वर्ग आरेख से, हम देखते हैं कि सभी संदर्भ प्रकार Root_Reference_Type . व्यवहार में, इसका सीधा सा मतलब है कि हमारे सभी संदर्भ प्रकारों में Alt_Sequence से समान विशेषताएं हैं Type_Key . के माध्यम से समावेशी, जैसा कि नीचे दिखाया गया है।
| विशेषता | विवरण |
|---|---|
Alt_Sequence | एक गैर-वर्णमाला क्रम की आवश्यकता होने पर एक वैकल्पिक अनुक्रम को परिभाषित करने के लिए उपयोग किया जाता है। |
Description | प्रकार का विवरण। |
Effective_Period | प्रभावी रूप से परिभाषित करता है कि संदर्भ प्रविष्टि सक्षम है या नहीं। एक बार किसी संदर्भ का उपयोग हो जाने के बाद उसे संदर्भात्मक बाधाओं के कारण हटाया नहीं जा सकता है; इसे केवल अक्षम किया जा सकता है। |
| प्रकार के लिए सुंदर नाम। उपयोगकर्ता स्क्रीन पर यही देखता है। |
Type_Key | प्रकार के लिए अद्वितीय आंतरिक कुंजी। यह उपयोगकर्ता से छिपा हुआ है लेकिन एप्लिकेशन डेवलपर अपने SQL में इसका व्यापक उपयोग कर सकते हैं। |
यहां पार्टी का प्रकार या तो एक संगठन या एक व्यक्ति है। लिंग के प्रकार नर और मादा हैं। तो ये वास्तव में साधारण मामले हैं।
पारंपरिक संदर्भ तालिका समाधान
तो हम वास्तविक डेटाबेस की भौतिक दुनिया में तार्किक मॉडल को कैसे लागू करने जा रहे हैं?
हम यह विचार कर सकते हैं कि प्रत्येक संदर्भ प्रकार अपनी तालिका में मैप करेगा। आप इसे अधिक पारंपरिक एक-टेबल-प्रति-वर्ग . के रूप में संदर्भित कर सकते हैं उपाय। यह काफी आसान है, और कुछ इस तरह दिखाई देगा:
इसका नकारात्मक पक्ष यह है कि इनमें से दर्जनों और दर्जनों टेबल हो सकती हैं, सभी में एक ही कॉलम हैं, सभी बहुत कुछ एक ही काम कर रहे हैं।
इसके अलावा, हम बहुत अधिक विकास कार्य कर रहे हैं . यदि प्रशासकों को मूल्यों को बनाए रखने के लिए प्रत्येक प्रकार के लिए एक यूआई की आवश्यकता होती है, तो काम की मात्रा जल्दी से कई गुना बढ़ जाती है। इसके लिए कोई सख्त नियम नहीं हैं - यह वास्तव में आपके विकास के माहौल पर निर्भर करता है - इसलिए आपको अपने डेवलपर्स से बात करनी होगी यह समझने के लिए कि इसका क्या प्रभाव पड़ता है।
लेकिन यह देखते हुए कि हमारे सभी संदर्भ प्रकारों में समान विशेषताएँ या कॉलम हैं, क्या हमारे तार्किक डेटा मॉडल को लागू करने का एक अधिक सामान्य तरीका है? हाँ वहाँ है! और इसके लिए केवल दो तालिकाओं की आवश्यकता है ।
दो-तालिका समाधान
इस विषय पर मेरी पहली चर्चा 90 के दशक के मध्य में हुई थी, जब मैं लंदन मार्केट बीमा कंपनी के लिए काम कर रहा था। इसके बाद, हम सीधे भौतिक डिजाइन पर गए और ज्यादातर प्राकृतिक/व्यावसायिक कुंजियों का उपयोग किया, आईडी का नहीं। जहां संदर्भ डेटा मौजूद था, हमने प्रति प्रकार एक तालिका रखने का निर्णय लिया जो एक अद्वितीय कोड (VARCHAR PK) और एक विवरण से बना था। वास्तव में, तब बहुत कम संदर्भ तालिकाएँ थीं। अधिकतर, व्यवसाय कोड के एक प्रतिबंधित सेट का उपयोग एक कॉलम में किया जाएगा, संभवतः एक डेटाबेस चेक बाधा परिभाषित के साथ; कोई संदर्भ तालिका बिल्कुल नहीं होगी।
लेकिन तब से खेल आगे बढ़ गया है। यह एक दो-तालिका समाधान . है ऐसा लग सकता है:
जैसा कि आप देख सकते हैं कि यह भौतिक डेटा मॉडल बहुत सरल है। लेकिन यह तार्किक मॉडल से काफी अलग है, और इसलिए नहीं कि कुछ नाशपाती के आकार का हो गया है। ऐसा इसलिए है क्योंकि भौतिक डिज़ाइन . के हिस्से के रूप में कई चीज़ें की गई हैं ।
reference_type तालिका एलडीएम से प्रत्येक व्यक्तिगत संदर्भ वर्ग का प्रतिनिधित्व करती है। इसलिए यदि आपके एलडीएम में 20 संदर्भ प्रकार हैं, तो आपके पास तालिका में मेटा-डेटा की 20 पंक्तियाँ होंगी। reference_value तालिका में सभी . के लिए अनुमत मान शामिल हैं संदर्भ प्रकार।
इस परियोजना के समय, डेवलपर्स के बीच कुछ काफी जीवंत चर्चाएँ हुईं। कुछ ने दो-तालिका समाधान का समर्थन किया और अन्य ने एक-तालिका-प्रति-प्रकार . को प्राथमिकता दी तरीका।
प्रत्येक समाधान के पक्ष और विपक्ष हैं। जैसा कि आप अनुमान लगा सकते हैं, डेवलपर्स ज्यादातर यूआई के काम की मात्रा से चिंतित थे। कुछ ने सोचा कि प्रत्येक तालिका के लिए एक व्यवस्थापक UI को एक साथ दस्तक देना बहुत तेज़ होगा। अन्य लोगों ने सोचा कि एकल व्यवस्थापक UI बनाना अधिक जटिल होगा, लेकिन अंततः इसका लाभ मिलेगा।
इस विशेष परियोजना पर, दो-तालिका समाधान का समर्थन किया गया था। आइए इसे और विस्तार से देखें।
एक्स्टेंसिबल और फ्लेक्सिबल रेफरेंस डेटा पैटर्न
जैसे-जैसे आपका डेटा मॉडल समय के साथ विकसित होता है और नए संदर्भ प्रकारों की आवश्यकता होती है, आपको प्रत्येक नए संदर्भ प्रकार के लिए अपने डेटाबेस में परिवर्तन करते रहने की आवश्यकता नहीं है। आपको बस नए कॉन्फ़िगरेशन डेटा को परिभाषित करने की आवश्यकता है। ऐसा करने के लिए, आप reference_type तालिका और अनुमेय मानों की इसकी नियंत्रित सूची को reference_value टेबल।
इस समाधान में निहित एक महत्वपूर्ण अवधारणा है प्रभावी अवधियों को परिभाषित करना कुछ मूल्यों के लिए। उदाहरण के लिए, आपके संगठन को एक नया reference_value 'आईडी का प्रमाण' जो भविष्य की किसी तारीख में स्वीकार्य होगा। उस नए reference_value effective_period_from . के साथ तिथि सही ढंग से निर्धारित। यह पहले से किया जा सकता है। उस तिथि के आने तक, नई प्रविष्टि प्रदर्शित नहीं होगी आपके ऐप्लिकेशन के उपयोगकर्ताओं द्वारा देखे जाने वाले मानों की ड्रॉप-डाउन सूची में। ऐसा इसलिए है क्योंकि आपका एप्लिकेशन केवल वही मान प्रदर्शित करता है जो वर्तमान या सक्षम हैं।
दूसरी ओर, आपको उपयोगकर्ताओं को किसी विशेष reference_value . उस स्थिति में, बस इसे effective_period_to . के साथ अपडेट करें तिथि सही ढंग से निर्धारित। जब वह दिन बीत जाएगा, तो मान ड्रॉप-डाउन सूची में दिखाई नहीं देगा। वह उस बिंदु से अक्षम हो जाता है। लेकिन क्योंकि यह अभी भी तालिका में एक पंक्ति के रूप में भौतिक रूप से मौजूद है, संदर्भात्मक अखंडता को बनाए रखा जाता है उन तालिकाओं के लिए जहां इसे पहले ही संदर्भित किया जा चुका है।
अब जब हम टू-टेबल समाधान पर काम कर रहे थे, तो यह स्पष्ट हो गया कि कुछ अतिरिक्त कॉलम reference_type टेबल। ये ज्यादातर UI चिंताओं पर केंद्रित हैं।
उदाहरण के लिए, pretty_name reference_type UI में उपयोग के लिए तालिका जोड़ी गई थी। बड़ी टैक्सोनॉमी के लिए खोज फ़ंक्शन वाली विंडो का उपयोग करना सहायक होता है। फिर pretty_name खिड़की के शीर्षक के लिए इस्तेमाल किया जा सकता है।
दूसरी ओर, यदि मानों की एक ड्रॉप-डाउन सूची पर्याप्त है, pretty_name LOV प्रॉम्प्ट के लिए इस्तेमाल किया जा सकता है। इसी तरह, रोल-ओवर सहायता को पॉप्युलेट करने के लिए UI में विवरण का उपयोग किया जा सकता है।
इन तालिकाओं में जाने वाले कॉन्फ़िगरेशन या मेटा-डेटा के प्रकार पर एक नज़र डालने से चीजों को थोड़ा स्पष्ट करने में मदद मिलेगी।
यह सब कैसे प्रबंधित करें
जबकि यहां इस्तेमाल किया गया उदाहरण बहुत सरल है, एक बड़ी परियोजना के लिए संदर्भ मूल्य जल्दी से काफी जटिल हो सकते हैं। इसलिए यह सलाह दी जा सकती है कि इन सभी को एक स्प्रेडशीट में बनाए रखा जाए। यदि ऐसा है, तो आप स्ट्रिंग कॉन्सटेनेशन का उपयोग करके SQL उत्पन्न करने के लिए स्वयं स्प्रैडशीट का उपयोग कर सकते हैं। इसे स्क्रिप्ट में चिपकाया जाता है, जो लक्ष्य डेटाबेस के विरुद्ध निष्पादित होते हैं जो विकास जीवन-चक्र और उत्पादन (लाइव) डेटाबेस का समर्थन करते हैं। यह डेटाबेस को सभी आवश्यक संदर्भ डेटा के साथ सीड करता है।
यहां दो एलडीएम प्रकारों के लिए कॉन्फ़िगरेशन डेटा है, Gender_Type और Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
reference_type Root_Reference_Type . के प्रत्येक LDM उपप्रकार के लिए . reference_type एलडीएम वर्ग विवरण से लिया गया है। Gender_Type के लिए , यह पढ़ेगा "किसी व्यक्ति के लिंग की पहचान करता है"। DML स्निपेट प्रकार और मान के बीच विवरण में अंतर दिखाते हैं, जिनका उपयोग UI या रिपोर्ट में किया जा सकता है।
आप देखेंगे कि reference_type Gender_Type called कहा जाता है इसके संबद्ध reference_value.ids . के लिए 13000000 से 13999999 की रेंज आवंटित की गई है . इस मॉडल में, प्रत्येक reference_type आईडी की एक अद्वितीय, गैर-अतिव्यापी श्रेणी आवंटित की जाती है। यह कड़ाई से आवश्यक नहीं है, लेकिन यह हमें संबंधित मूल्य आईडी को एक साथ समूहित करने की अनुमति देता है। यदि आपके पास अलग-अलग टेबल होते तो यह उस तरह की नकल करता है जो आपको मिलेगा। यह अच्छा है, लेकिन अगर आपको नहीं लगता कि इसमें कोई फायदा है तो आप इसे छोड़ सकते हैं।
पीडीएम में जोड़ा गया एक और कॉलम है admin_role . यही कारण है।
व्यवस्थापक कौन हैं
कुछ टैक्सोनॉमी में बहुत कम या बिना किसी प्रभाव के मूल्यों को जोड़ा या हटाया जा सकता है। यह तब होगा जब कोई प्रोग्राम अपने तर्क में मूल्यों का उपयोग नहीं करता है, या जब अन्य सिस्टम में प्रकार इंटरफेस नहीं किया जाता है। ऐसे मामलों में, उपयोगकर्ता व्यवस्थापकों के लिए इन्हें अद्यतित रखना सुरक्षित है।
लेकिन अन्य मामलों में, बहुत अधिक देखभाल करने की आवश्यकता है। एक नया संदर्भ मान प्रोग्राम लॉजिक या डाउनस्ट्रीम सिस्टम के लिए अनपेक्षित परिणाम उत्पन्न कर सकता है।
उदाहरण के लिए, मान लें कि हम निम्नलिखित को जेंडर टाइप टैक्सोनॉमी में जोड़ते हैं:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
यह जल्दी से एक समस्या बन जाती है यदि हमारे पास निम्न तर्क कहीं अंतर्निहित है:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
स्पष्ट रूप से, "यदि आप पुरुष नहीं हैं तो आपको महिला होना चाहिए" तर्क अब विस्तारित वर्गीकरण में लागू नहीं होता है।
यह वह जगह है जहां admin_role कॉलम खेल में आता है। यह भौतिक डिजाइन पर डेवलपर्स के साथ चर्चा से पैदा हुआ था, और यह उनके यूआई समाधान के संयोजन के साथ काम करता था। लेकिन अगर एक-टेबल-प्रति-वर्ग समाधान चुना गया था, तो reference_type अस्तित्व में नहीं होता। इसमें निहित मेटा-डेटा को एप्लिकेशन में हार्ड-कोड किया गया होगा Gender_Type टेबल - , जो न तो लचीला है और न ही एक्स्टेंसिबल।
केवल सही विशेषाधिकार वाले उपयोगकर्ता ही वर्गीकरण का प्रबंधन कर सकते हैं। यह विषय वस्तु विशेषज्ञता पर आधारित होने की संभावना है (SME ) दूसरी ओर, कुछ टैक्सोनॉमी को आईटी द्वारा प्रशासित करने की आवश्यकता हो सकती है ताकि प्रभाव विश्लेषण, पूरी तरह से परीक्षण, और किसी भी कोड परिवर्तन को नए कॉन्फ़िगरेशन के लिए समय पर सामंजस्यपूर्ण रूप से जारी किया जा सके। (चाहे यह परिवर्तन अनुरोधों द्वारा किया जाता है या किसी अन्य तरीके से आपके संगठन पर निर्भर करता है।)
आपने ध्यान दिया होगा कि ऑडिट कॉलम created_by , created_date , updated_by , और updated_date उपरोक्त लिपि में बिल्कुल भी संदर्भित नहीं हैं। दोबारा, यदि आप इनमें रूचि नहीं रखते हैं तो आपको उनका उपयोग करने की आवश्यकता नहीं है। इस विशेष संगठन का एक मानक था जिसमें प्रत्येक टेबल पर ऑडिट कॉलम होना अनिवार्य था।
ट्रिगर:चीजों को लगातार बनाए रखना
ट्रिगर यह सुनिश्चित करते हैं कि ये ऑडिट कॉलम लगातार अपडेट किए जाते हैं, चाहे SQL का स्रोत कोई भी हो (स्क्रिप्ट, आपका एप्लिकेशन, शेड्यूल किया गया बैच अपडेट, एड-हॉक अपडेट आदि)।
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
मेरी पृष्ठभूमि ज्यादातर Oracle है और, दुर्भाग्य से, Oracle पहचानकर्ताओं को 30 बाइट्स तक सीमित करता है। इससे अधिक होने से बचने के लिए, प्रत्येक तालिका को तीन से पांच वर्णों का एक संक्षिप्त उपनाम दिया जाता है और अन्य तालिका-संबंधित कलाकृतियां उस उपनाम का उपयोग उनके नाम पर करती हैं। तो, reference_value इसका उपनाम reva है - प्रत्येक शब्द के पहले दो अक्षर। पंक्ति डालने से पहले और पंक्ति अद्यतन से पहले bri . को संक्षिप्त किया जाता है और bru क्रमश। अनुक्रम का नाम reva_seq , और आगे।
इस तरह से हैंड-कोडिंग ट्रिगर, टेबल के बाद टेबल, डेवलपर्स के लिए बहुत अधिक मनोबल गिराने वाले बॉयलर-प्लेट काम की आवश्यकता होती है। सौभाग्य से, ये ट्रिगर कोड जनरेशन के माध्यम से बनाए जा सकते हैं , लेकिन यह एक अन्य लेख का विषय है!
कुंजी का महत्व
ref_type_key और type_key कॉलम दोनों 30 बाइट्स तक सीमित हैं। यह उन्हें PIVOT-प्रकार के SQL प्रश्नों में उपयोग करने की अनुमति देता है (Oracle में। अन्य डेटाबेस में समान पहचानकर्ता लंबाई प्रतिबंध नहीं हो सकता है)।
चूंकि मुख्य विशिष्टता डेटाबेस द्वारा सुनिश्चित की जाती है और ट्रिगर यह सुनिश्चित करता है कि इसका मान सभी समय के लिए समान रहे, इन कुंजियों को क्वेरी और कोड में अधिक सुपाठ्य बनाने के लिए उपयोग किया जा सकता है - और होना चाहिए। . इससे मेरा क्या आशय है? खैर, इसके बजाय:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
आप लिखते हैं:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
मूल रूप से, कुंजी स्पष्ट रूप से बताती है कि क्वेरी क्या कर रही है ।
एलडीएम से पीडीएम तक, रूम टू ग्रो के साथ
एलडीएम से पीडीएम तक की यात्रा जरूरी नहीं कि सीधी सड़क हो। न ही यह एक से दूसरे में सीधा परिवर्तन है। यह एक अलग प्रक्रिया है जो अपने स्वयं के विचारों और अपनी चिंताओं का परिचय देती है।
आप अपने डेटाबेस में संदर्भ डेटा को कैसे मॉडल करते हैं?