हिट-हाइलाइटिंग एक ऐसी सुविधा है जिसे बहुत से लोग चाहते हैं कि SQL सर्वर का पूर्ण-पाठ खोज मूल रूप से समर्थन करे। यह वह जगह है जहां आप पूरे दस्तावेज़ (या एक अंश) को वापस कर सकते हैं और उन शब्दों या वाक्यांशों को इंगित कर सकते हैं जो उस दस्तावेज़ को खोज से मिलाने में मदद करते हैं। कुशल और सटीक तरीके से ऐसा करना कोई आसान काम नहीं है, जैसा कि मुझे पहली बार पता चला।
हिट-हाइलाइटिंग के उदाहरण के रूप में:जब आप Google या बिंग में कोई खोज करते हैं, तो आपको शीर्षक और अंश दोनों में बोल्ड किए गए कीवर्ड मिलते हैं (विस्तार करने के लिए किसी भी छवि पर क्लिक करें):

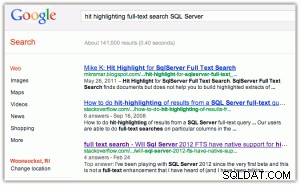
[एक तरफ के रूप में, मुझे यहां दो चीजें मनोरंजक लगती हैं:(1) कि बिंग Google की तुलना में माइक्रोसॉफ्ट की संपत्तियों का बहुत अधिक समर्थन करता है, और (2) बिंग 2.2 मिलियन परिणाम लौटाने से परेशान है, जिनमें से कई अप्रासंगिक हैं।]
इन अंशों को सामान्यतः "स्निपेट" या "क्वेरी-पक्षपाती सारांश" कहा जाता है। हम कुछ समय से SQL सर्वर में इस कार्यक्षमता के लिए पूछ रहे हैं, लेकिन अभी तक Microsoft से कोई अच्छी खबर नहीं मिली है:
- कनेक्ट #295100 :पूर्ण-पाठ खोज सारांश (हिट-हाइलाइटिंग)
- कनेक्ट #722324 :अच्छा होगा यदि SQL पूर्ण पाठ खोज स्निपेट/हाइलाइटिंग समर्थन प्रदान करे
यह प्रश्न समय-समय पर स्टैक ओवरफ़्लो पर भी पॉप अप होता है:
- SQL सर्वर पूर्ण-पाठ क्वेरी से परिणामों की हिट-हाइलाइटिंग कैसे करें
- क्या Sql Server 2012 FTS में हिट हाइलाइटिंग के लिए मूल समर्थन होगा?
कुछ आंशिक समाधान हैं। उदाहरण के लिए, माइक क्रैमर की यह स्क्रिप्ट हिट-हाइलाइट किए गए उद्धरण का उत्पादन करेगी, लेकिन दस्तावेज़ में समान तर्क (जैसे भाषा-विशिष्ट शब्द ब्रेकर) को लागू नहीं करती है। यह एक पूर्ण वर्ण गणना का भी उपयोग करता है, इसलिए अंश आंशिक शब्दों के साथ शुरू और समाप्त हो सकता है (जैसा कि मैं जल्द ही प्रदर्शित करूंगा)। उत्तरार्द्ध को ठीक करना बहुत आसान है, लेकिन एक और मुद्दा यह है कि यह किसी भी प्रकार की स्ट्रीमिंग करने के बजाय पूरे दस्तावेज़ को मेमोरी में लोड करता है। मुझे संदेह है कि बड़े दस्तावेज़ आकारों वाले पूर्ण-पाठ अनुक्रमणिका में, यह एक उल्लेखनीय प्रदर्शन हिट होगा। अभी के लिए मैं अपेक्षाकृत छोटे औसत दस्तावेज़ आकार (35 KB) पर ध्यान केंद्रित करूंगा।
एक साधारण उदाहरण
तो मान लें कि हमारे पास एक बहुत ही सरल तालिका है, जिसमें एक पूर्ण-पाठ अनुक्रमणिका परिभाषित है:
पूर्ण टेक्स्ट कैटलॉग बनाएं [एफटीएसडीमो]; टेबल बनाएं [डीबीओ]। , [शीर्षक] NVARCHAR (200) नॉट न्यूल, [सामग्री] NVARCHAR (MAX) न्यूल नहीं, सीमित PK_DOCUMENT प्राथमिक कुंजी (आईडी)); [डीबीओ] पर पूर्ण टेक्स्ट इंडेक्स बनाएं। [दस्तावेज़] ( [सामग्री] भाषा [अंग्रेज़ी] , [शीर्षक] भाषा [अंग्रेज़ी])कुंजी सूचकांक [PK_Document] चालू ([FTSDemo]);
यह तालिका कुछ दस्तावेजों (विशेष रूप से, 7) से भरी हुई है, जैसे कि स्वतंत्रता की घोषणा, और नेल्सन मंडेला का "मैं मरने के लिए तैयार हूं" भाषण। इस तालिका के विरुद्ध एक सामान्य पूर्ण-पाठ खोज हो सकती है:
चुनें डी.शीर्षक, डी.[सामग्री]डीबीओ से। [रैंक] डीईएससी द्वारा आदेश;
परिणाम 7 में से 4 पंक्तियाँ लौटाता है:

अब माइक क्रेमर जैसे UDF फ़ंक्शन का उपयोग कर रहे हैं:
चुनें d.Title, अंश =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)dbo से।[दस्तावेज़] डिनर के रूप में शामिल हों (dbo.[दस्तावेज़ ], *, N'states') AS tON d.ID =t.[KEY]ORDER by [RANK] DESC;
परिणाम दिखाते हैं कि अंश कैसे काम करता है:a <SPAN> टैग को पहले कीवर्ड में इंजेक्ट किया जाता है, और उस स्थिति से ऑफसेट के आधार पर अंश तैयार किया जाता है (पूरे शब्दों का उपयोग करने के लिए कोई विचार नहीं):

(फिर से, यह कुछ ऐसा है जिसे ठीक किया जा सकता है, लेकिन मैं यह सुनिश्चित करना चाहता हूं कि मैं ठीक से प्रतिनिधित्व करता हूं कि अब वहां क्या है।)
थिंकहाइलाइट
इंटरएक्टिव थॉट्स के एरन मेयुचास ने एक घटक विकसित किया है जो इनमें से कई मुद्दों को हल करता है। थिंकहाइलाइट को दो सीएलआर स्केलर-मूल्यवान कार्यों के साथ एक सीएलआर असेंबली के रूप में लागू किया गया है:
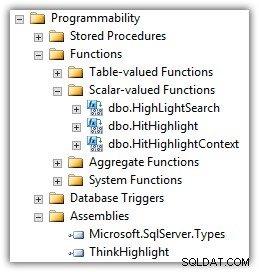
(आप कार्यों की सूची में माइक क्रेमर का यूडीएफ भी देखेंगे।)
अब, आपके सिस्टम पर असेंबली को स्थापित करने और सक्रिय करने के बारे में सभी विवरणों में शामिल हुए बिना, यहां बताया गया है कि उपरोक्त क्वेरी को थिंकहाइलाइट के साथ कैसे दर्शाया जाएगा:
चुनें d.Title, अंश =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID) from dbo. [दस्तावेज़] डिनर के रूप में शामिल हों (dbo.[Document], *, N'states') AS tON d.ID =t।
परिणाम दिखाते हैं कि सबसे अधिक प्रासंगिक कीवर्ड कैसे हाइलाइट किए जाते हैं, और एक अंश पूर्ण शब्दों और हाइलाइट किए जा रहे शब्द से एक ऑफसेट के आधार पर प्राप्त किया जाता है:

कुछ अतिरिक्त लाभ जिन्हें मैंने यहां प्रदर्शित नहीं किया है, उनमें अलग-अलग सारांश रणनीतियों को चुनने की क्षमता शामिल है, अद्वितीय सीएसएस का उपयोग करके प्रत्येक कीवर्ड (सभी के बजाय) की प्रस्तुति को नियंत्रित करने के साथ-साथ कई भाषाओं और यहां तक कि बाइनरी प्रारूप में दस्तावेज़ों के लिए समर्थन (अधिकांश IFilters) समर्थित हैं)।
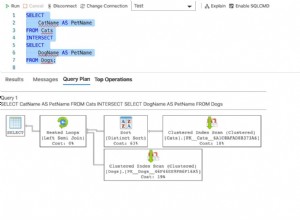
प्रदर्शन परिणाम
प्रारंभ में मैंने 7-पंक्ति तालिका के विरुद्ध SQL संतरी योजना एक्सप्लोरर का उपयोग करते हुए तीन प्रश्नों के लिए रनटाइम मेट्रिक्स का परीक्षण किया। परिणाम थे:

आगे मैं देखना चाहता था कि वे एक बड़े डेटा आकार की तुलना कैसे करेंगे। जब तक मैं 4,000 पंक्तियों में नहीं था, तब तक मैंने तालिका को स्वयं में सम्मिलित किया, फिर निम्न क्वेरी चलाई:
सेट स्टैटिस्टिक्स टाइम ऑन; GO SELECT /* FTS */ d.Title, d.[Content] from dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS टन डी.आईडी =टी। [कुंजी] [रैंक] डीईएससी द्वारा आदेश; चयन करें / * यूडीएफ * / डी। शीर्षक, अंश =डीबीओ। हाईलाइटसर्च (डी। [सामग्री], एन 'स्टेट्स', 'फ़ॉन्ट-वेट:बोल्ड', 100) डीबीओ से। [दस्तावेज़] डिनर के रूप में शामिल हों (डीबीओ। [दस्तावेज़], *, एन 'स्टेट्स') एएस टन डी.आईडी =टी। [कुंजी] [रैंक] डीईएससी द्वारा ऑर्डर करें; चयन करें / * ThinkHighlight */ d.Title, अंश =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID) from dbo. [दस्तावेज़] डिनर के रूप में शामिल हों (dbo.[दस्तावेज़], *, N'states') AS tON d.ID =t. [कुंजी] t द्वारा ऑर्डर करें। [रैंक] डीईएससी; सेट सांख्यिकी समय बंद करें; जाओ
मैंने sys.dm_exec_memory_grants की भी निगरानी की, जबकि क्वेरी चल रही थी, मेमोरी ग्रांट में किसी भी तरह की विसंगतियों को लेने के लिए। 10 रन से अधिक के औसत परिणाम:
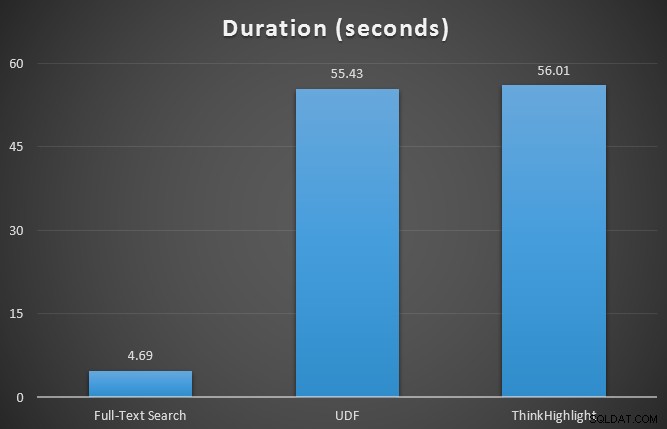
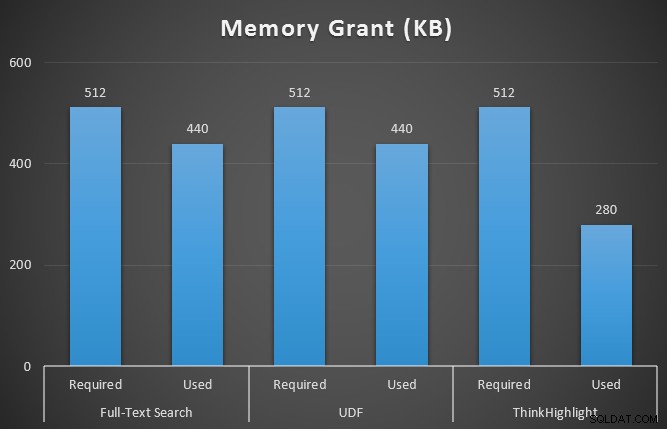
जबकि दोनों हिट-हाइलाइटिंग विकल्पों में हाइलाइट न करने पर एक महत्वपूर्ण जुर्माना लगता है, थिंकहाइलाइट समाधान - अधिक लचीले विकल्पों के साथ - अवधि (~ 1%) के संदर्भ में बहुत मामूली वृद्धिशील लागत का प्रतिनिधित्व करता है, जबकि काफी कम मेमोरी (36%) का उपयोग करता है। यूडीएफ संस्करण की तुलना में।
निष्कर्ष
यह आश्चर्य के रूप में नहीं आना चाहिए कि हिट-हाइलाइटिंग एक महंगा ऑपरेशन है, और जो समर्थन किया जाना है उसकी जटिलता के आधार पर (कई भाषाओं को सोचें), कि बहुत कम समाधान मौजूद हैं। मुझे लगता है कि माइक क्रैमर ने बेसलाइन यूडीएफ का निर्माण करते हुए एक उत्कृष्ट काम किया है जो आपको समस्या को हल करने का एक अच्छा तरीका देता है, लेकिन मुझे एक अधिक मजबूत वाणिज्यिक पेशकश मिलने पर सुखद आश्चर्य हुआ - और इसे बीटा रूप में भी बहुत स्थिर पाया गया। मैं दस्तावेज़ आकारों और प्रकारों की विस्तृत श्रृंखला का उपयोग करके अधिक गहन परीक्षण करने की योजना बना रहा हूं। इस बीच, यदि हिट-हाइलाइटिंग आपकी एप्लिकेशन आवश्यकताओं का एक हिस्सा है, तो आपको माइक क्रैमर का यूडीएफ आज़माना चाहिए और टेस्ट ड्राइव के लिए थिंकहाइलाइट लेने पर विचार करना चाहिए।