हम सभी गलतियाँ करते हैं, और हम सभी दूसरे लोगों की गलतियों से सीख सकते हैं। इस पोस्ट में, हम खराब डेटाबेस डिज़ाइन से बचने के लिए कई ऑनलाइन संसाधनों पर एक नज़र डालेंगे, जिससे कई समस्याएं हो सकती हैं और समय और पैसा दोनों खर्च हो सकते हैं। और एक आगामी लेख में, हम आपको बताएंगे कि युक्तियाँ और सर्वोत्तम अभ्यास कहाँ से प्राप्त करें।
डेटाबेस डिज़ाइन त्रुटियों और गलतियों से बचने के लिए
डेटाबेस डिजाइनरों को सामान्य त्रुटियों और गलतियों से बचने में मदद करने के लिए कई ऑनलाइन संसाधन हैं। जाहिर है, यह लेख हर लेख की एक विस्तृत सूची नहीं है। इसके बजाय, हमने विभिन्न स्रोतों की समीक्षा की है और उन पर टिप्पणी की है ताकि आप अपने लिए सबसे उपयुक्त स्रोत ढूंढ सकें।
हमारी अनुशंसा
यदि इन संसाधनों में से केवल एक ही लेख है जिसे आप पढ़ने जा रहे हैं, तो वह 'डेटाबेस डिज़ाइन को अत्यधिक गलत कैसे प्राप्त करें' होना चाहिए। रॉबर्ट शेल्डन से
आइए DATAVERSITY ब्लॉग से शुरुआत करें जो काफी अच्छे संसाधनों का एक विस्तृत सेट प्रदान करता है:
प्राथमिक कुंजी और विदेशी कुंजी त्रुटियों से बचने के लिए
माइकल ब्लाहा द्वारा | डेटावर्सिटी ब्लॉग | 2 सितंबर 2015
अधिक डेटाबेस डिज़ाइन त्रुटियाँ - अनेक-से-अनेक संबंधों के साथ भ्रम
माइकल ब्लाहा द्वारा | डेटावर्सिटी ब्लॉग | 30 सितंबर, 2015
विविध डेटाबेस डिज़ाइन त्रुटियाँ
माइकल ब्लाहा द्वारा | डेटावर्सिटी ब्लॉग | 26 अक्टूबर 2015
माइकल ब्लाहा ने तीन लेखों का एक अच्छा सेट दिया है। प्रत्येक लेख डेटाबेस मॉडलिंग और भौतिक डिजाइन के विभिन्न नुकसानों को संबोधित करता है; विषयों में कुंजियाँ, संबंध और सामान्य त्रुटियाँ शामिल हैं। इसके अलावा कुछ बिंदुओं को लेकर माइकल से भी बातचीत चल रही है। यदि आप चाबियों और रिश्तों के आसपास के नुकसान की तलाश कर रहे हैं, तो यह शुरू करने के लिए एक अच्छी जगह होगी।
श्री ब्लाहा कहते हैं कि "लगभग 20% डेटाबेस प्राथमिक कुंजी नियमों का उल्लंघन करते हैं"। बहुत खूब! इसका मतलब है कि लगभग 20% डेटाबेस डेवलपर्स ने प्राथमिक कुंजी को ठीक से नहीं बनाया। यदि यह आँकड़ा सत्य है, तो यह वास्तव में डेटा मॉडलिंग टूल के महत्व को दर्शाता है जो दृढ़ता से "प्रोत्साहित" करते हैं या यहां तक कि प्राथमिक कुंजी को परिभाषित करने के लिए मॉडलर की आवश्यकता होती है।
श्री ब्लाहा यह अनुमान भी साझा करते हैं कि "लगभग 50% डेटाबेस" में विदेशी प्रमुख समस्याएं हैं (उनके द्वारा अध्ययन किए गए विरासत डेटाबेस के साथ उनके अनुभव के अनुसार)। वह हमें याद दिलाता है कि विदेशी कुंजी का उपयोग करने के बजाय एक तालिका से दूसरी तालिका में मान को एम्बेड करके तालिकाओं के बीच अनौपचारिक संबंध से बचने के लिए।
मैंने यह समस्या कई बार देखी है। मैं मानता हूं कि क्रियान्वित होने वाली कार्यक्षमता के लिए अनौपचारिक जुड़ाव की आवश्यकता हो सकती है, लेकिन अधिक बार यह साधारण आलस्य के कारण होता है। उदाहरण के लिए, हम किसी ऐसे व्यक्ति की उपयोगकर्ता आईडी दिखाना चाह सकते हैं जिसने कुछ संशोधित किया है, इसलिए हम उपयोगकर्ता आईडी को सीधे तालिका में संग्रहीत करते हैं। लेकिन क्या होगा यदि वह उपयोगकर्ता अपनी उपयोगकर्ता आईडी बदल देता है? फिर यह अनौपचारिक कड़ी टूट जाती है। यह अक्सर खराब डिज़ाइन और मॉडलिंग के कारण होता है।
अपना डेटाबेस डिजाइन करना:शीर्ष 5 गलतियों से बचना चाहिए
हेनरिक नेट्ज़का द्वारा | डेटावर्सिटी ब्लॉग | 2 नवंबर, 2015
मैं इस लेख से थोड़ा निराश था, क्योंकि इसमें कुछ विशिष्ट आइटम थे (एक सीएलओबी में प्रोटोकॉल भंडारण) और कुछ बहुत ही सामान्य (स्थानीयकरण के बारे में सोचें)। कुल मिलाकर, लेख ठीक है, लेकिन क्या वाकई इन शीर्ष 5 गलतियों से बचा जाना चाहिए? मेरी राय में, कई अन्य सामान्य गलतियाँ हैं जिन्हें सूची बनानी चाहिए।
हालांकि, एक सकारात्मक नोट पर, यह उन कुछ लेखों में से एक है जो किसी भी सार्थक तरीके से वैश्वीकरण और स्थानीयकरण का उल्लेख करते हैं। मैं एक बहुत ही बहुभाषी वातावरण में काम करता हूं और मैंने स्थानीयकरण के कई भयानक कार्यान्वयन देखे हैं, इसलिए इस मुद्दे का उल्लेख पाकर मुझे खुशी हुई। भाषा स्तंभ और समय क्षेत्र स्तंभ स्पष्ट लग सकते हैं, लेकिन वे डेटाबेस मॉडल में बहुत कम दिखाई देते हैं।
ऐसा कहा जा रहा है, मैंने सोचा कि अनुवाद सहित एक मॉडल बनाना दिलचस्प होगा जिसे अंतिम उपयोगकर्ताओं द्वारा बदला जा सकता है (संसाधन बंडलों का उपयोग करने के विपरीत)। कुछ समय पहले, मैंने एक ऑनलाइन सर्वेक्षण डेटाबेस के लिए एक मॉडल के बारे में लिखा था। यहाँ मैंने प्रश्नों और प्रतिक्रिया विकल्पों का सरलीकृत अनुवाद तैयार किया है:
यह मानते हुए कि हमें अंतिम उपयोगकर्ताओं को अनुवादों को बनाए रखने की अनुमति देनी चाहिए, पसंदीदा तरीका प्रश्नों और प्रतिक्रियाओं के लिए अनुवाद तालिकाएँ जोड़ना होगा:
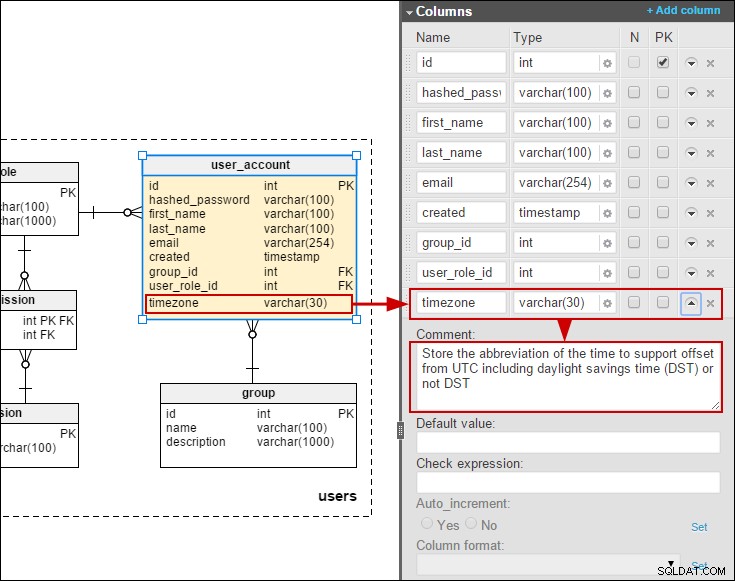
मैंने user_account तालिका ताकि हम उपयोगकर्ताओं के स्थानीय समय में दिनांक/समय संग्रहीत कर सकें:
7 सामान्य डेटाबेस डिज़ाइन त्रुटियाँ
ग्रेज़गोर्ज़ काज़ोर द्वारा | वर्टाबेलो ब्लॉग | जुलाई 17, 2015
मैं यहां थोड़ा आत्म-प्रचार करूंगा। हम यहां नियमित रूप से दिलचस्प और आकर्षक लेख पोस्ट करने का प्रयास करते हैं।
यह विशेष लेख चिंता के कई महत्वपूर्ण क्षेत्रों को इंगित करता है, जैसे नामकरण, अनुक्रमण, मात्रा संबंधी विचार और ऑडिट ट्रेल्स। लेख विशिष्ट DBM सिस्टम से संबंधित मुद्दों पर भी जाता है, जैसे तालिका नामों पर Oracle सीमाएँ। मुझे वास्तव में अच्छे स्पष्ट उदाहरण पसंद हैं, भले ही वे यह बता रहे हों कि डिज़ाइनर कैसे गलतियाँ और त्रुटियाँ करते हैं।
स्पष्ट रूप से प्रत्येक डिज़ाइन त्रुटि को सूचीबद्ध करना संभव नहीं है, और जो सूचीबद्ध हैं वे आपकी . नहीं हो सकते हैं सबसे आम त्रुटियां। जब हम सामान्य गलतियों के बारे में लिखते हैं, तो यह वही है जो हमने किया है या दूसरों के काम में पाया है जिसे हम आकर्षित कर रहे हैं। त्रुटियों की एक पूरी सूची, आवृत्ति के संदर्भ में क्रमबद्ध, एक व्यक्ति के लिए संकलित करना असंभव होगा। फिर भी, मुझे लगता है कि यह लेख संभावित नुकसान के बारे में कई उपयोगी अंतर्दृष्टि प्रदान करता है। यह कुल मिलाकर एक अच्छा ठोस संसाधन है।
जबकि मिस्टर काज़ोर ने अपने लेख में कई दिलचस्प बातें कही हैं, मुझे "संभावित मात्रा या ट्रैफ़िक पर विचार न करने" के बारे में उनकी टिप्पणियाँ काफी दिलचस्प लगीं। विशेष रूप से, ऐतिहासिक डेटा से अक्सर उपयोग किए जाने वाले डेटा को अलग करने की सिफारिश विशेष रूप से प्रासंगिक है। यह एक ऐसा समाधान है जिसका उपयोग हम अपने संदेश सेवा अनुप्रयोगों में अक्सर करते हैं; हमारे पास सभी संदेशों का खोजने योग्य इतिहास होना चाहिए, लेकिन जिन संदेशों तक पहुंचने की सबसे अधिक संभावना है, वे पिछले कुछ दिनों में पोस्ट किए गए हैं। इसलिए "सक्रिय" या हाल के डेटा को विभाजित करना, जिसे लंबे समय तक ऐतिहासिक डेटा (डेटा का बड़ा द्रव्यमान) से अक्सर एक्सेस किया जाता है (डेटा की एक बहुत छोटी मात्रा) आम तौर पर एक बहुत अच्छी तकनीक है।
आम डेटाबेस डिजाइन गलतियाँ
ट्रॉय ब्लेक द्वारा | वरिष्ठ डीबीए ब्लॉग | 11 जुलाई 2015
ट्रॉय ब्लेक का लेख एक और अच्छा संसाधन है, हालाँकि मैंने इस लेख का नाम बदलकर "सामान्य SQL सर्वर डिज़ाइन गलतियाँ" कर दिया होगा।
उदाहरण के लिए, हमारे पास टिप्पणी है:"जब SQL सर्वर का प्रभावी ढंग से उपयोग करने की बात आती है तो संग्रहीत प्रक्रियाएं आपकी सबसे अच्छी दोस्त होती हैं"। यह ठीक है, लेकिन क्या यह एक सामान्य सामान्य गलती है, या यह SQL सर्वर के लिए अधिक विशिष्ट है? मुझे इसे थोड़ा SQL सर्वर-विशिष्ट होने का विकल्प चुनना होगा, क्योंकि संग्रहीत प्रक्रियाओं का उपयोग करने के नुकसान हैं, जैसे विक्रेता-विशिष्ट संग्रहीत प्रक्रियाओं के साथ समाप्त होना और इस प्रकार विक्रेता लॉक-इन। इसलिए मैं इस सूची में "संग्रहीत प्रक्रियाओं का उपयोग नहीं" शामिल करने का प्रशंसक नहीं हूं।
हालांकि, सकारात्मक पक्ष पर, मुझे लगता है कि लेखक ने कुछ बहुत ही सामान्य गलतियों की पहचान की, जैसे खराब योजना, घटिया सिस्टम डिज़ाइन, सीमित दस्तावेज़ीकरण, कमजोर नामकरण मानकों और परीक्षण की कमी।
इसलिए मैं इसे SQL सर्वर प्रैक्टिशनर्स के लिए एक बहुत ही उपयोगी संदर्भ और दूसरों के लिए एक उपयोगी संदर्भ के रूप में वर्गीकृत करूंगा।
सात डेटा मॉडलिंग गलतियाँ
कर्ट कैगल द्वारा | लिंक्डइन | 12 जून, 2015
मुझे मिस्टर कैगल की डेटाबेस मॉडलिंग गलतियों की सूची पढ़ने में बहुत मज़ा आया। ये डेटाबेस आर्किटेक्ट के चीजों के दृष्टिकोण से हैं; वह स्पष्ट रूप से उच्च-स्तरीय मॉडलिंग गलतियों की पहचान करता है जिनसे बचा जाना चाहिए। इस बड़े चित्र दृश्य के साथ, आप संभावित मॉडलिंग गड़बड़ी को समाप्त कर सकते हैं।
लेख में उल्लिखित कुछ प्रकार कहीं और पाए जा सकते हैं, लेकिन इनमें से कुछ अद्वितीय हैं:बहुत जल्दी सार प्राप्त करना या वैचारिक, तार्किक और भौतिक मॉडल को मिलाना। उनका उल्लेख अक्सर अन्य लेखकों द्वारा नहीं किया जाता है, शायद इसलिए कि वे बड़े सिस्टम व्यू के बजाय डेटा मॉडलिंग प्रक्रिया पर ध्यान केंद्रित कर रहे हैं।
विशेष रूप से, "गेटिंग टू एब्सट्रैक्ट टू अर्ली" का उदाहरण कुछ नमूना "कहानियां" बनाने की एक दिलचस्प विचार प्रक्रिया का वर्णन करता है और परीक्षण करता है कि इस डोमेन में कौन से रिश्ते महत्वपूर्ण हैं। यह मॉडलिंग की जा रही वस्तुओं के बीच संबंधों पर सोच को केंद्रित करता है। इसके परिणामस्वरूप इस डोमेन में महत्वपूर्ण संबंध क्या हैं . जैसे प्रश्न आते हैं ?
इस समझ के आधार पर, हम अलग-अलग डोमेन आइटम से शुरू करने और उनके ऊपर संबंध बनाने के बजाय संबंधों के आसपास मॉडल बनाते हैं। जबकि हम में से कई लोग इस दृष्टिकोण का उपयोग कर सकते हैं, इन संसाधनों के बीच किसी अन्य लेखक ने इस पर टिप्पणी नहीं की। मुझे यह विवरण और उदाहरण काफी दिलचस्प लगे।
डेटाबेस डिज़ाइन को कैसे गलत तरीके से प्राप्त करें
रॉबर्ट शेल्डन द्वारा | साधारण बात | मार्च 6, 2015
यदि इन संसाधनों में से केवल एक ही लेख है जिसे आप पढ़ने जा रहे हैं, तो यह रॉबर्ट शेल्डन का एक लेख होना चाहिए
इस लेख के बारे में मुझे जो वास्तव में पसंद है वह यह है कि उल्लिखित प्रत्येक गलती के लिए इसे सही तरीके से करने के लिए सुझाव दिए गए हैं। इनमें से अधिकांश विफलता को ठीक करने के बजाय उससे बचने पर ध्यान केंद्रित करते हैं, लेकिन मुझे अभी भी लगता है कि वे बहुत उपयोगी हैं। यहाँ बहुत कम सिद्धांत है; डेटा मॉडलिंग करते समय गलतियों से बचने के बारे में ज्यादातर सीधे जवाब। कुछ विशिष्ट SQL सर्वर बिंदु हैं, लेकिन अधिकांश SQL सर्वर का उपयोग त्रुटि से बचने या विफलता से बाहर निकलने के तरीकों के उदाहरण प्रदान करने के लिए किया जाता है।
लेख का दायरा भी काफी व्यापक है:इसमें योजना की उपेक्षा करना, दस्तावेज़ीकरण से परेशान न होना, घटिया नामकरण परंपराओं का उपयोग करना, सामान्यीकरण में समस्याएँ (बहुत अधिक या बहुत कम), चाबियों और बाधाओं पर विफल होना, ठीक से अनुक्रमण नहीं करना और प्रदर्शन करना शामिल है। अपर्याप्त परीक्षण।
विशेष रूप से, मुझे डेटा अखंडता के बारे में व्यावहारिक सलाह पसंद आई - चेक बाधाओं का उपयोग कब करना है और विदेशी कुंजी को कब परिभाषित करना है। इसके अलावा, श्री शेल्डन उस स्थिति का भी वर्णन करते हैं जब टीम अखंडता को लागू करने के लिए आवेदन को स्थगित कर देती है। वह सीधे बिंदु पर है जब वह कहता है कि एक डेटाबेस को कई तरीकों से और कई अनुप्रयोगों द्वारा एक्सेस किया जा सकता है। उनका निष्कर्ष है कि "डेटा को संरक्षित किया जाना चाहिए जहां वह रहता है:डेटाबेस के भीतर"। यह इतना सच है कि डेटा मॉडल में अखंडता जांच को लागू करने के महत्व को समझाने के लिए इसे विकास टीमों और प्रबंधकों को दोहराया जा सकता है।
यह मेरी तरह का लेख है, और आप बता सकते हैं कि अन्य लोग इसका समर्थन करने वाली कई टिप्पणियों के आधार पर सहमत हैं। तो, यहाँ शीर्ष अंक; यह एक बहुत ही मूल्यवान संसाधन है।
दस सामान्य डेटाबेस डिज़ाइन गलतियाँ
लुई डेविडसन द्वारा | साधारण बात | फरवरी 26, 2007
मुझे यह लेख काफी अच्छा लगा, क्योंकि इसमें बहुत सी सामान्य डिजाइन गलतियों को शामिल किया गया था। विलियम शेक्सपियर और जे.आर.आर. के कुछ अर्थपूर्ण उपमाएं, उदाहरण, मॉडल और यहां तक कि कुछ क्लासिक उद्धरण भी थे। टॉल्किन।
कुछ गलतियों को दूसरों की तुलना में अधिक विस्तार से समझाया गया था, लंबे उदाहरणों और SQL अंशों के साथ जो मुझे थोड़ा बोझिल लगा। लेकिन यह स्वाद की बात है।
फिर, हमारे पास SQL सर्वर के लिए विशिष्ट कुछ विषय हैं। उदाहरण के लिए, डेटा तक पहुँचने के लिए संग्रहीत कार्यविधियों का उपयोग न करने की बात SQL के लिए अच्छी है, लेकिन जब लक्ष्य कई DBMSes पर समर्थन होता है, तो SP हमेशा एक अच्छा विचार नहीं होता है। इसके अलावा, हमें जेनेरिक टी-एसक्यूएल ऑब्जेक्ट्स को कोड करने की कोशिश करने के खिलाफ चेतावनी दी जाती है। जैसा कि मैं शायद ही कभी SQL सर्वर या Sybase के साथ काम करता हूं, मुझे यह युक्ति प्रासंगिक नहीं लगी।
सूची काफी हद तक रॉबर्ट शेल्डन के समान है, लेकिन यदि आप मुख्य रूप से SQL सर्वर पर काम कर रहे हैं, तो आपको कुछ अतिरिक्त जानकारी मिलेगी।
पांच सरल डेटाबेस डिज़ाइन त्रुटियाँ जिनसे आपको बचना चाहिए
अनिथ सेन लार्सन द्वारा | साधारण बात | 16 अक्टूबर 2009
यह आलेख इसमें शामिल प्रत्येक साधारण डिज़ाइन त्रुटि के लिए कुछ सार्थक उदाहरण देता है। दूसरी ओर, यह समान प्रकार की त्रुटियों पर केंद्रित है:सामान्य लुकअप टेबल, एंटिटी-एट्रिब्यूट-वैल्यू टेबल, और एट्रीब्यूट स्प्लिटिंग।
अवलोकन ठीक हैं, और लेख में संदर्भ भी हैं, जो दुर्लभ हैं। फिर भी, मैं और अधिक सामान्य डेटाबेस डिज़ाइन त्रुटियाँ देखना चाहूँगा। ये त्रुटियां काफी विशिष्ट लग रही थीं, लेकिन, जैसा कि मैंने पहले ही लिखा है, हम जिन गलतियों के बारे में लिखते हैं, वे आम तौर पर वे होती हैं जिनके साथ हमारा व्यक्तिगत अनुभव होता है।
एक आइटम जो मुझे पसंद आया वह यह तय करने के लिए अंगूठे का एक विशिष्ट नियम था कि एक विदेशी कुंजी बाधा के साथ एक अलग तालिका बनाम चेक बाधा का उपयोग कब किया जाए। कई लेखक समान सिफारिशें प्रदान करते हैं, लेकिन श्री लार्सन ने उन्हें "जरूरी", "विचार" और "मजबूत मामले" में तोड़ दिया - इस स्वीकार के साथ कि "डिजाइन कला और विज्ञान का मिश्रण है और इसलिए इसमें ट्रेडऑफ़ शामिल है"। मुझे यह बहुत सच लगता है।
शीर्ष दस सबसे आम भौतिक डेटाबेस डिज़ाइन गलतियाँ
क्रेग मुलिंस द्वारा | डेटा और प्रौद्योगिकी आज | 5 अगस्त 2013
जैसा कि इसके नाम का तात्पर्य है, "टॉप टेन मोस्ट कॉमन फिजिकल डेटाबेस डिज़ाइन मिस्टेक्स" तार्किक और वैचारिक डिज़ाइन के बजाय भौतिक डिज़ाइन के लिए थोड़ा अधिक उन्मुख है। लेखक क्रेग मुलिंस ने जिन गलतियों का उल्लेख किया है उनमें से कोई भी वास्तव में बाहर खड़ा है या अद्वितीय है, इसलिए मैं इस जानकारी को भौतिक डीबीए पक्ष पर काम करने वाले लोगों को सुझाऊंगा।
इसके अलावा, विवरण थोड़े छोटे हैं, इसलिए कभी-कभी यह देखना कठिन होता है कि कोई विशेष गलती समस्या का कारण क्यों बन रही है। संक्षिप्त विवरण में स्वाभाविक रूप से कुछ भी गलत नहीं है, लेकिन वे आपको सोचने के लिए बहुत कुछ नहीं देते हैं। और कोई उदाहरण प्रस्तुत नहीं किया गया है।
डेटा साझा करने में विफलता से संबंधित एक दिलचस्प बात उठाई गई है। इस बिंदु का कभी-कभी अन्य लेखों में उल्लेख किया गया है, लेकिन एक डिजाइन गलती के रूप में नहीं। हालाँकि, मुझे यह समस्या बहुत बार दिखाई देती है, जिसमें डेटाबेस बहुत समान आवश्यकताओं के आधार पर "पुन:निर्मित" होते हैं, लेकिन एक नई टीम द्वारा या एक नए उत्पाद के लिए
.अक्सर ऐसा होता है कि उत्पाद टीम को बाद में पता चलता है कि वे उस डेटा का उपयोग करना पसंद करेंगे जो उनके वर्तमान डेटाबेस के "पिता" में पहले से मौजूद था। वास्तव में, हालांकि, उन्हें एक नई संतान पैदा करने के बजाय माता-पिता को बढ़ाना चाहिए था। एप्लिकेशन डेटा साझा करने के लिए हैं; अच्छा डिज़ाइन डेटाबेस को अधिक बार पुन:उपयोग करने की अनुमति दे सकता है।
क्या आप ये 5 डेटाबेस डिज़ाइन गलतियाँ करते हैं?
थॉमस लैरॉक द्वारा | थॉमस लैरॉक का ब्लॉग | 2 जनवरी 2012
थॉमस लैरॉक के प्रश्न का उत्तर देते समय आपको कुछ दिलचस्प बिंदु मिल सकते हैं:क्या आप ये 5 डेटाबेस डिज़ाइन गलतियाँ करते हैं?
यह आलेख कुछ हद तक चाबियों (विदेशी कुंजी, सरोगेट कुंजी, और जेनरेट की गई कुंजी) पर भारी भारित है। फिर भी, इसका एक महत्वपूर्ण बिंदु है:किसी को यह नहीं मानना चाहिए कि DBMS सुविधाएँ सभी प्रणालियों में समान हैं। मुझे लगता है कि यह बहुत अच्छी बात है। यह भी एक है जो अधिकांश अन्य लेखों में नहीं पाया जाता है, शायद इसलिए कि कई लेखक मुख्य रूप से एक ही डीबीएमएस पर ध्यान केंद्रित करते हैं और काम करते हैं।
डेटाबेस डिजाइन करना:7 चीजें जो आप नहीं करना चाहते हैं
थॉमस लैरॉक द्वारा | थॉमस लैरॉक का ब्लॉग | 16 जनवरी, 2013
मिस्टर लैरॉक ने "7 थिंग्स यू डोंट वॉन्ट टू डू" लिखते समय अपनी "5 डेटाबेस डिज़ाइन मिस्टेक्स" के एक जोड़े को पुनर्नवीनीकरण किया, लेकिन यहाँ अन्य अच्छे बिंदु हैं।
दिलचस्प बात यह है कि मिस्टर लैरॉक द्वारा बताए गए कुछ बिंदु कई अन्य स्रोतों में नहीं पाए जाते हैं। आपको कुछ अनोखे अवलोकन मिलते हैं, जैसे "कोई प्रदर्शन अपेक्षा नहीं होना"। यह एक गंभीर गलती है और मेरे अनुभव के आधार पर अक्सर ऐसा होता है। एप्लिकेशन कोड विकसित करते समय भी, यह अक्सर डेटा मॉडल, डेटाबेस और एप्लिकेशन के बाद ही होता है कि लोग गैर-कार्यात्मक आवश्यकताओं (जब गैर-कार्यात्मक परीक्षण बनाए जाने चाहिए) के बारे में सोचना शुरू करते हैं और प्रदर्शन अपेक्षाओं को परिभाषित करना शुरू करते हैं ।
इसके विपरीत, कुछ बिंदु हैं जिन्हें मैं अपनी शीर्ष दस सूची में शामिल नहीं करूंगा, जैसे कि "बड़ा होना, बस मामले में"। मैं बिंदु देखता हूं, लेकिन डेटा मॉडल बनाते समय यह मेरी सूची में उतना ऊंचा नहीं है। किसी विशेष DBM सिस्टम की कोई विशिष्टता नहीं है, इसलिए यह एक बोनस है।
निष्कर्ष निकालने के लिए, इनमें से कई बिंदुओं को इस बिंदु के तहत समझाया जा सकता है:"आवश्यकताओं को नहीं समझना", जो वास्तव में मेरी शीर्ष 10 गलती सूची में है।
आठ सामान्य डेटाबेस विकास गलतियों से कैसे बचें
Base36 द्वारा | 6 दिसंबर 2012
मुझे इस लेख को पढ़ने में काफी दिलचस्पी थी। हालाँकि, मैं थोड़ा निराश था। परिहार के बारे में बहुत अधिक चर्चा नहीं है, और लेख का बिंदु वास्तव में "ये सामान्य डेटाबेस गलतियाँ हैं" और "वे गलतियाँ क्यों हैं"; गलती से बचने के तरीके के विवरण कम प्रमुख हैं।
इसके अलावा, लेख की शीर्ष 8 त्रुटियों में से कुछ वास्तव में विवादित हैं। प्राथमिक कुंजी का दुरुपयोग एक उदाहरण है। बेस 36 हमें बताता है कि उन्हें सिस्टम द्वारा उत्पन्न किया जाना चाहिए और पंक्ति में एप्लिकेशन डेटा पर आधारित नहीं होना चाहिए। हालांकि मैं इस बात से एक हद तक सहमत हूं, लेकिन मुझे यकीन नहीं है कि सभी PK को हमेशा . होना चाहिए उत्पन्न होना; यह थोड़ा बहुत स्पष्ट है।
दूसरी ओर, "हार्ड डिलीट्स" की गलती दिलचस्प है और अक्सर कहीं और इसका उल्लेख नहीं किया जाता है। सॉफ्ट डिलीट अन्य मुद्दों का कारण बनता है, लेकिन यह सच है कि जब आप यह पता लगाने की कोशिश कर रहे हैं कि वह डेटा कल सिस्टम में कहां था, तो बस एक पंक्ति को निष्क्रिय के रूप में चिह्नित करने के अपने फायदे हैं। लेन-देन लॉग के माध्यम से खोजना मेरे लिए एक दिन बिताने का एक सुखद तरीका नहीं है।
डेटाबेस डिजाइन के सात घातक पाप
जेसन टायर द्वारा | एंटरप्राइज सिस्टम्स जर्नल | फरवरी 16, 2010
जब मैंने जेसन टायर का लेख, "सेवन डेडली सिन्स ऑफ़ डेटाबेस डिज़ाइन" पढ़ना शुरू किया, तो मैं काफी आशान्वित था। इसलिए मुझे यह जानकर खुशी हुई कि इसने कई अन्य लेखों में पाई गई गलतियों को केवल रीसायकल नहीं किया। इसके विपरीत, इसने एक "पाप" की पेशकश की जो मुझे अन्य सूचियों में नहीं मिला था:सभी डेटाबेस डिज़ाइन को "सामने" करने की कोशिश करना और डेटाबेस के उत्पादन में होने के बाद मॉडल को अपडेट नहीं करना, जब डेटाबेस में परिवर्तन किए जाते हैं। (या, जैसा कि जेसन कहते हैं, "एक जीवित, सांस लेने वाले जीव की तरह डेटा मॉडल का इलाज नहीं करना")।
मैंने यह गलती कई बार देखी है। अधिकांश लोगों को अपनी त्रुटि का एहसास केवल तब होता है जब उन्हें किसी ऐसे मॉडल में अपडेट करना होता है जो अब वास्तविक डेटाबेस से मेल नहीं खाता है। बेशक, परिणाम एक बेकार मॉडल है। जैसा कि लेख में कहा गया है, "परिवर्तनों को मॉडल पर वापस जाने की आवश्यकता है।"
दूसरी ओर, जेसन की अधिकांश सूची आइटम काफी प्रसिद्ध हैं। विवरण अच्छे हैं, लेकिन बहुत अधिक उदाहरण नहीं हैं। अधिक उदाहरण और विवरण उपयोगी होंगे।
सबसे आम डेटाबेस डिजाइन गलतियाँ
ब्रायन प्रिंस द्वारा | eWeek.com | मार्च 19, 2008

"सबसे आम डेटाबेस डिजाइन गलतियाँ" लेख वास्तव में एक प्रस्तुति से स्लाइड की एक श्रृंखला है। कुछ दिलचस्प विचार हैं, लेकिन कुछ अनोखी चीजें शायद थोड़ी गूढ़ हैं। मेरे मन में "RAID के बारे में जानें" और हितधारकों की भागीदारी जैसे बिंदु हैं।
सामान्य तौर पर, मैं इसे आपकी पठन सूची में तब तक नहीं डालूंगा जब तक कि आप सामान्य मुद्दों (योजना, नामकरण, सामान्यीकरण, अनुक्रमणिका) और भौतिक विवरणों पर ध्यान केंद्रित न करें।
10 सामान्य डिज़ाइन गलतियाँ
davidm द्वारा | SQL सर्वर ब्लॉग – SQLTeam.com | 12 सितंबर, 2005
"दस आम डिजाइन गलतियों" में कुछ बिंदु दिलचस्प और अपेक्षाकृत उपन्यास हैं। हालाँकि, इनमें से कुछ गलतियाँ काफी विवादास्पद हैं, जैसे कि "NULL का उपयोग करना" और डी-नॉर्मलाइज़ करना।
मैं मानता हूं कि सभी स्तंभों को शून्य के रूप में बनाना एक गलती है, लेकिन किसी विशेष व्यावसायिक कार्य के लिए एक स्तंभ को अशक्त के रूप में परिभाषित करना आवश्यक हो सकता है। इसलिए क्या इसे एक सामान्य गलती माना जा सकता है? मुझे नहीं लगता।
एक और बिंदु जिसके साथ मैं समस्या लेता हूं वह है डी-सामान्यीकरण। यह हमेशा एक डिज़ाइन त्रुटि नहीं होती है। उदाहरण के लिए, प्रदर्शन कारणों से डी-सामान्यीकरण की आवश्यकता हो सकती है।
इस लेख में विवरण और उदाहरणों की भी काफी कमी है। डीबीए और प्रोग्रामर या मैनेजर के बीच बातचीत मनोरंजक है, लेकिन मैं इन सामान्य गलतियों के लिए अधिक ठोस उदाहरण और विस्तृत औचित्य पसंद करता।
OTLT और EAV:दो बड़ी डिज़ाइन गलतियाँ जो सभी शुरुआती करते हैं
टोनी एंड्रयूज द्वारा | Oracle और डेटाबेस पर टोनी एंड्रयूज | 21 अक्टूबर 2004
श्री एंड्रयूज का लेख हमें "वन ट्रू लुकअप टेबल" (ओटीएलटी) और एंटिटी-एट्रीब्यूट-वैल्यू (ईएवी) गलतियों की याद दिलाता है जिनका उल्लेख अन्य लेखों में किया गया है। इस प्रस्तुति के बारे में एक अच्छी बात यह है कि यह इन दो गलतियों पर केंद्रित है, इसलिए विवरण और उदाहरण सटीक हैं। इसके अलावा, कुछ डिज़ाइनर OTLT और EAV को क्यों लागू करते हैं, इसका संभावित स्पष्टीकरण दिया गया है।
आपको याद दिलाने के लिए, OTLT तालिका आमतौर पर कुछ इस तरह दिखती है, जिसमें एक ही तालिका में कई डोमेन से प्रविष्टियाँ डाली जाती हैं:
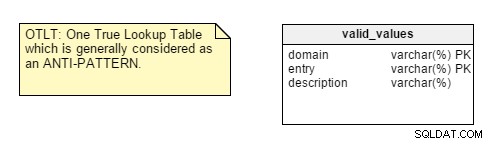
हमेशा की तरह, इस बात पर चर्चा होती है कि क्या ओटीएलटी एक व्यावहारिक समाधान और एक अच्छा डिजाइन पैटर्न है। मुझे कहना होगा कि मैं ओटीएलटी विरोधी समूह का पक्ष लेता हूं; ये तालिकाएँ कई मुद्दों का परिचय देती हैं। हम सभी संभावित स्थिरांक के सभी संभावित मूल्यों का प्रतिनिधित्व करने के लिए एक एकल गणक का उपयोग करने की सादृश्यता का उपयोग कर सकते हैं। मैंने अब तक ऐसा कभी नहीं देखा।
आम डेटाबेस गलतियाँ
जॉन पॉल एशेनफेल्टर द्वारा | डॉ. डोब की | जनवरी 01, 2002
मिस्टर एशेनफेल्टर के लेख में डेटाबेस की 15 सामान्य गलतियों की सूची है। कुछ गलतियाँ भी हैं जिनका उल्लेख अन्य लेखों में अक्सर नहीं किया जाता है। दुर्भाग्य से, विवरण अपेक्षाकृत कम हैं और कोई उदाहरण नहीं हैं। इस लेख की खूबी यह है कि सूची में बहुत सारे आधार शामिल हैं और इसे गलतियों की "चेकलिस्ट" के रूप में इस्तेमाल किया जा सकता है जिससे बचने के लिए। हालांकि मैं इन्हें सबसे महत्वपूर्ण डेटाबेस गलतियों के रूप में वर्गीकृत नहीं कर सकता, लेकिन वे निश्चित रूप से सबसे आम हैं।
एक सकारात्मक नोट पर, यह उन कुछ लेखों में से एक है जो दिनांक, मुद्रा और पते जैसे डेटा के लिए प्रारूपों के अंतर्राष्ट्रीयकरण को संभालने की आवश्यकता का उल्लेख करता है। यहां एक उदाहरण अच्छा होगा। यह इतना आसान हो सकता है कि "सुनिश्चित करें कि राज्य एक अशक्त स्तंभ है; कई देशों में, कोई राज्य किसी पते से जुड़ा नहीं है"।
इससे पहले इस लेख में, मैंने आपके डेटाबेस के वैश्वीकरण की तैयारी के लिए अन्य चिंताओं और कुछ दृष्टिकोणों का उल्लेख किया था, जैसे समय क्षेत्र और अनुवाद (स्थानीयकरण)। तथ्य यह है कि किसी अन्य लेख में मुद्रा और दिनांक स्वरूपों की चिंता का उल्लेख नहीं है, परेशान करने वाला है। क्या हमारे डेटाबेस हमारे अनुप्रयोगों के वैश्विक उपयोग के लिए तैयार हैं?
माननीय उल्लेख
जाहिर है, ऐसे अन्य लेख हैं जो सामान्य डेटाबेस डिज़ाइन गलतियों और त्रुटियों का वर्णन करते हैं, लेकिन हम आपको विभिन्न संसाधनों की व्यापक समीक्षा देना चाहते हैं। आप लेखों में अतिरिक्त जानकारी पा सकते हैं जैसे:
10 आम डेटाबेस डिजाइन गलतियाँ | एमआईएस क्लास ब्लॉग | 29 जनवरी 2012
डेटाबेस डिजाइन में 10 सामान्य गलतियाँ | आईडीजी.एसई | 24 जून 2010
ऑनलाइन संसाधन:कहां से शुरू करें? कहाँ जाना है?
जैसा कि पहले उल्लेख किया गया है, यह सूची निश्चित रूप से डेटाबेस डिज़ाइन गलतियों और त्रुटियों का वर्णन करने वाले प्रत्येक ऑनलाइन लेख की संपूर्ण परीक्षा के लिए नहीं है। इसके बजाय, हमने ऐसे कई स्रोतों की पहचान की है जो विशेष रूप से उपयोगी हैं या जिनका विशेष फोकस है जो आपको उपयोगी लग सकता है।
कृपया बेझिझक अतिरिक्त लेखों की अनुशंसा करें।