यह आलेख डेटा को समूहीकृत करने और एकत्र करने के लिए ऑप्टिमाइज़ेशन थ्रेशोल्ड के बारे में श्रृंखला में तीसरा है। भाग 1 में मैंने पहले से ऑर्डर किए गए स्ट्रीम एग्रीगेट एल्गोरिथम को कवर किया। भाग 2 में मैंने गैर-आदेशित सॉर्ट + स्ट्रीम एग्रीगेट एल्गोरिथम को कवर किया। इस भाग में मैं हैश मैच (एग्रीगेट) एल्गोरिथम को कवर करता हूं, जिसे मैं केवल हैश एग्रीगेट के रूप में संदर्भित करूंगा। मैं भाग 1, भाग 2 और भाग 3 में शामिल एल्गोरिदम के बीच एक सारांश और तुलना भी प्रदान करता हूं।
मैं उसी नमूना डेटाबेस का उपयोग करूँगा जिसे PerformanceV3 कहा जाता है, जिसका उपयोग मैंने श्रृंखला के पिछले लेखों में किया था। बस यह सुनिश्चित करें कि लेख में उदाहरण चलाने से पहले, आप पहले कुछ अनावश्यक अनुक्रमणिका छोड़ने के लिए निम्न कोड चलाएँ:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
इस टेबल पर केवल दो इंडेक्स छोड़े जाने चाहिए idx_cl_od (कुंजी के रूप में ऑर्डरडेट के साथ क्लस्टर) और PK_Orders (कुंजी के रूप में ऑर्डरिड के साथ गैर-क्लस्टर)।
हैश एग्रीगेट
हैश एग्रीगेट एल्गोरिथ्म कुछ आंतरिक रूप से चुने गए हैश फ़ंक्शन के आधार पर समूहों को हैश तालिका में व्यवस्थित करता है। स्ट्रीम एग्रीगेट एल्गोरिथ्म के विपरीत, इसे समूह क्रम में पंक्तियों का उपभोग करने की आवश्यकता नहीं है। एक उदाहरण के रूप में निम्नलिखित प्रश्न पर विचार करें (हम इसे प्रश्न 1 कहेंगे):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
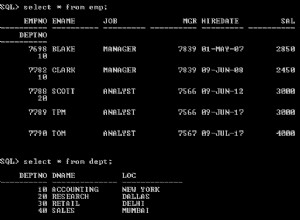
चित्र 1 प्रश्न 1 की योजना दिखाता है।
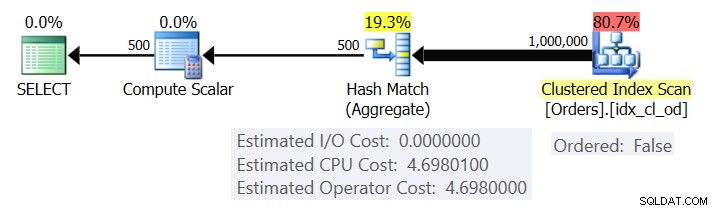
चित्र 1:प्रश्न 1 के लिए योजना
योजना एक आदेशित:झूठी संपत्ति का उपयोग करके संकुल सूचकांक से पंक्तियों को स्कैन करती है (सूचकांक कुंजी द्वारा आदेशित पंक्तियों को वितरित करने के लिए स्कैन की आवश्यकता नहीं है)। आमतौर पर, ऑप्टिमाइज़र सबसे संकीर्ण कवरिंग इंडेक्स को स्कैन करना पसंद करेगा, जो हमारे मामले में क्लस्टर इंडेक्स होता है। योजना समूहीकृत स्तंभों और समुच्चय के साथ एक हैश तालिका बनाती है। हमारी क्वेरी एक INT-टाइप किए गए COUNT समुच्चय का अनुरोध करती है। योजना वास्तव में इसे एक BIGINT- टाइप किए गए मान के रूप में गणना करती है, इसलिए कंप्यूट स्केलर ऑपरेटर, INT में निहित रूपांतरण लागू करता है।
Microsoft उनके द्वारा उपयोग किए जाने वाले हैश एल्गोरिदम को सार्वजनिक रूप से साझा नहीं करता है। यह बहुत ही मालिकाना तकनीक है। फिर भी, अवधारणा को स्पष्ट करने के लिए, मान लीजिए कि SQL सर्वर ऊपर हमारी क्वेरी के लिए% 250 (मॉड्यूलो 250) हैश फ़ंक्शन का उपयोग करता है। किसी भी पंक्ति को संसाधित करने से पहले, हमारी हैश तालिका में 250 बकेट हैं जो हैश फ़ंक्शन के 250 संभावित परिणामों (0 से 249) का प्रतिनिधित्व करते हैं। चूंकि SQL सर्वर प्रत्येक पंक्ति को संसाधित करता है, यह हैश फ़ंक्शन
orderid empid ------- ----- 320 3 30 5 660 253 820 3 850 1 1000 255 700 3 1240 253 350 4 400 255
चित्र 2 हैश तालिका की तीन अवस्थाओं को दिखाता है:किसी भी पंक्ति को संसाधित करने से पहले, पहली 5 पंक्तियों को संसाधित करने के बाद, और पहली 10 पंक्तियों को संसाधित करने के बाद। लिंक की गई सूची में प्रत्येक आइटम में टपल (एम्पिड, COUNT(*)) होता है।
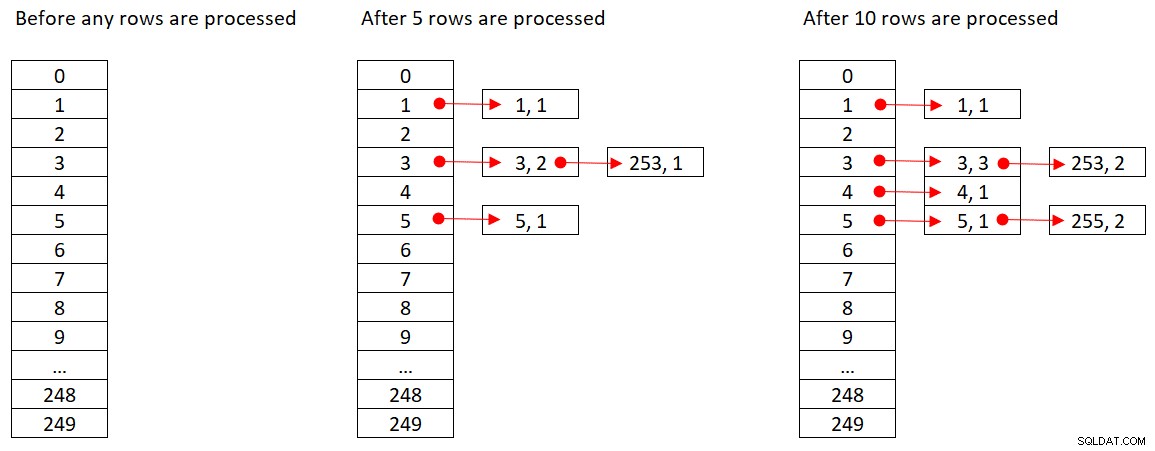
चित्र 2:हैश तालिका की स्थिति
एक बार जब हैश एग्रीगेट ऑपरेटर सभी इनपुट पंक्तियों का उपभोग कर लेता है, तो हैश तालिका में कुल की अंतिम स्थिति वाले सभी समूह होते हैं।
सॉर्ट ऑपरेटर की तरह, हैश एग्रीगेट ऑपरेटर को मेमोरी ग्रांट की आवश्यकता होती है, और यदि यह मेमोरी से बाहर हो जाता है, तो इसे tempdb पर फैलाने की आवश्यकता होती है; हालाँकि, जबकि सॉर्टिंग के लिए मेमोरी ग्रांट की आवश्यकता होती है जो सॉर्ट की जाने वाली पंक्तियों की संख्या के समानुपाती होती है, हैशिंग को मेमोरी ग्रांट की आवश्यकता होती है जो समूहों की संख्या के समानुपाती होती है। इसलिए विशेष रूप से जब ग्रुपिंग सेट में उच्च घनत्व (समूहों की छोटी संख्या) होता है, तो इस एल्गोरिथम को स्पष्ट छँटाई की आवश्यकता की तुलना में काफी कम मेमोरी की आवश्यकता होती है।
निम्नलिखित दो प्रश्नों पर विचार करें (उन्हें प्रश्न 1 और प्रश्न 2 कहें):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
चित्र 3 इन प्रश्नों के लिए स्मृति अनुदान की तुलना करता है।

चित्र 3:प्रश्न 1 और प्रश्न 2 के लिए योजनाएं
दो मामलों में स्मृति अनुदान के बीच बड़े अंतर पर ध्यान दें।
हैश एग्रीगेट ऑपरेटर की लागत के लिए, चित्र 1 पर वापस जाने पर ध्यान दें कि कोई I/O लागत नहीं है, बल्कि केवल एक CPU लागत है। इसके बाद, सीपीयू लागत सूत्र को उसी तरह की तकनीकों का उपयोग करके इंजीनियर करने का प्रयास करें, जिन्हें मैंने श्रृंखला में पिछले भागों में कवर किया था। कारक जो संभावित रूप से ऑपरेटर की लागत को प्रभावित कर सकते हैं, वे हैं इनपुट पंक्तियों की संख्या, आउटपुट समूहों की संख्या, उपयोग किए गए कुल फ़ंक्शन, और आपके द्वारा समूहीकृत (समूहीकरण सेट की कार्डिनैलिटी, उपयोग किए गए डेटा प्रकार)।
आप उम्मीद करते हैं कि हैश टेबल बनाने की तैयारी में इस ऑपरेटर की स्टार्टअप लागत होगी। आप यह भी अपेक्षा करते हैं कि यह पंक्तियों और समूहों की संख्या के संबंध में रैखिक रूप से स्केल करे। वास्तव में मैंने यही पाया। हालाँकि, जबकि स्ट्रीम एग्रीगेट और सॉर्ट ऑपरेटर दोनों की लागत आपके द्वारा समूहित किए जाने से प्रभावित नहीं होती है, ऐसा लगता है कि हैश एग्रीगेट ऑपरेटर की लागत है- दोनों ग्रुपिंग सेट की कार्डिनैलिटी और उपयोग किए गए डेटा प्रकारों के संदर्भ में।
यह देखने के लिए कि ग्रुपिंग सेट की कार्डिनैलिटी ऑपरेटर की लागत को प्रभावित करती है, निम्नलिखित प्रश्नों के लिए योजनाओं में हैश एग्रीगेट ऑपरेटरों की सीपीयू लागत की जांच करें (उन्हें क्वेरी 3 और क्वेरी 4 कहते हैं):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1);
बेशक, आप यह सुनिश्चित करना चाहते हैं कि इनपुट पंक्तियों और आउटपुट समूहों की अनुमानित संख्या दोनों मामलों में समान है। इन प्रश्नों के लिए अनुमानित योजनाएं चित्र 4 में दिखाई गई हैं।
चित्र 4:प्रश्न 3 और प्रश्न 4 की योजनाएँ
जैसा कि आप देख सकते हैं, हैश एग्रीगेट ऑपरेटर की सीपीयू लागत 0.16903 है जब एक पूर्णांक कॉलम द्वारा समूहीकृत किया जाता है, और 0.174016 जब दो पूर्णांक कॉलम द्वारा समूहित किया जाता है, तो बाकी सभी समान होते हैं। इसका मतलब यह है कि ग्रुपिंग सेट कार्डिनैलिटी वास्तव में लागत को प्रभावित करती है।
इस बात के लिए कि क्या समूहीकृत तत्व का डेटा प्रकार लागत को प्रभावित करता है, मैंने इसे जांचने के लिए निम्नलिखित प्रश्नों का उपयोग किया (उन्हें प्रश्न 5, प्रश्न 6 और प्रश्न 7 कहें):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT)
OPTION(HASH GROUP, MAXDOP 1);
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY orderid % 1000
OPTION(HASH GROUP, MAXDOP 1);
SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT)
OPTION(HASH GROUP, MAXDOP 1); सभी तीन प्रश्नों की योजनाओं में इनपुट पंक्तियों और आउटपुट समूहों की अनुमानित संख्या समान है, फिर भी वे सभी अलग-अलग अनुमानित CPU लागत प्राप्त करते हैं (0.121766, 0.16903 और 0.171716), इसलिए उपयोग किया जाने वाला डेटा प्रकार लागत को प्रभावित करता है।
कुल कार्य के प्रकार का भी लागत पर प्रभाव पड़ता है। उदाहरण के लिए, निम्नलिखित दो प्रश्नों पर विचार करें (उन्हें प्रश्न 8 और प्रश्न 9 कहें):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
क्वेरी 8 की योजना में हैश एग्रीगेट के लिए अनुमानित CPU लागत 0.166344 है, और क्वेरी 9 में 0.16903 है।
यह एक दिलचस्प अभ्यास हो सकता है कि यह पता लगाने की कोशिश की जाए कि किस तरह से समूहीकरण सेट की कार्डिनैलिटी, डेटा प्रकार और उपयोग किए गए कुल फ़ंक्शन लागत को प्रभावित करते हैं; मैंने लागत के इस पहलू का पीछा नहीं किया। इसलिए, अपनी क्वेरी के लिए ग्रुपिंग सेट और एग्रीगेट फंक्शन का चुनाव करने के बाद, आप कॉस्टिंग फॉर्मूला को रिवर्स इंजीनियर कर सकते हैं। उदाहरण के लिए, एक पूर्णांक कॉलम द्वारा समूहीकृत करते समय और MAX (ऑर्डरडेट) कुल लौटाते समय हैश एग्रीगेट ऑपरेटर के लिए सीपीयू लागत सूत्र को रिवर्स इंजीनियर करें। सूत्र होना चाहिए:
ऑपरेटर CPU लागत =<स्टार्टअप लागत> + @numrows * <लागत प्रति पंक्ति> + @numgroups * <लागत प्रति समूह>श्रृंखला के पिछले लेखों में मैंने जिन तकनीकों का प्रदर्शन किया, उनका उपयोग करते हुए, मुझे निम्नलिखित रिवर्स इंजीनियर फॉर्मूला मिला:
ऑपरेटर CPU लागत =0.017749 + @numrows * 0.00000667857 + @numgroups * 0.0000177087आप निम्न प्रश्नों का उपयोग करके सूत्र की सटीकता की जांच कर सकते हैं:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
मुझे निम्नलिखित परिणाम मिलते हैं:
numrows numgroups predictedcost estimatedcost ----------- ----------- -------------- -------------- 100000 1000 0.703315 0.703316 100000 2000 0.721023 0.721024 200000 3000 1.40659 1.40659 200000 6000 1.45972 1.45972 500000 5000 3.44558 3.44558 500000 10000 3.53412 3.53412
ऐसा लगता है कि सूत्र हाजिर है।
लागत सारांश और तुलना
अब हमारे पास तीन उपलब्ध रणनीतियों के लिए लागत सूत्र हैं:पहले से ऑर्डर किया गया स्ट्रीम एग्रीगेट, सॉर्ट + स्ट्रीम एग्रीगेट और हैश एग्रीगेट। निम्न तालिका तीन एल्गोरिदम की लागत विशेषताओं का सारांश और तुलना करती है:
| <टीडी> | |||
| सूत्र | @numrows * 0.0000006 + @numgroups * 0.0000005 | 0.0112613 + पंक्तियों की छोटी संख्या: 9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06 बड़ी संख्या में पंक्तियाँ: 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0.0000006 + @numgroups * 0.0000005 | 0.017749 + @numrows * 0.00000667857 + @numgroups * 0.0000177087 * एकल पूर्णांक स्तंभ के आधार पर समूहीकरण, MAX (<दिनांक स्तंभ>) लौटाते हुए |
| स्केलिंग | रैखिक | n लॉग n | रैखिक |
| स्टार्टअप I/O लागत | कोई नहीं | 0.0112613 | कोई नहीं |
| स्टार्टअप CPU लागत | कोई नहीं | ~ 0.0001 | 0.017749 |
इन फ़ार्मुलों के अनुसार, चित्र 5 एक उदाहरण के रूप में 500 के समूहों की एक निश्चित संख्या का उपयोग करते हुए, प्रत्येक रणनीति को इनपुट पंक्तियों की विभिन्न संख्याओं के लिए स्केल करने का तरीका दिखाता है।
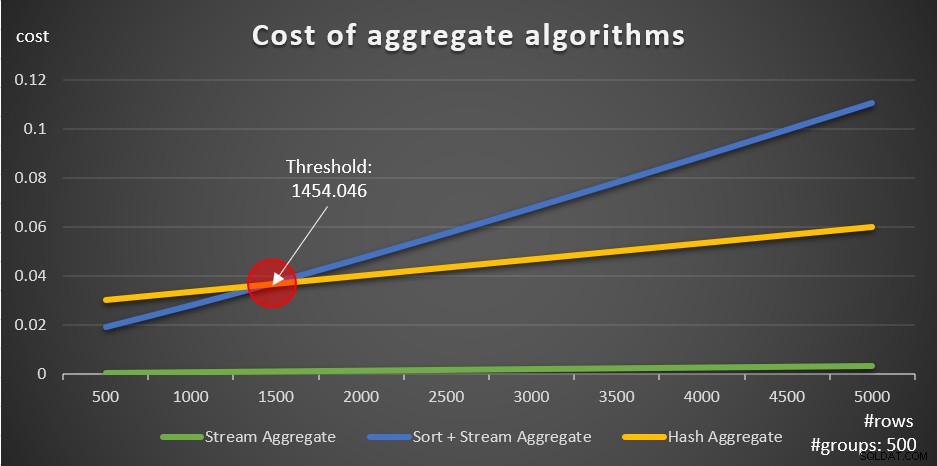
चित्र 5:समग्र एल्गोरिदम की लागत
आप स्पष्ट रूप से देख सकते हैं कि यदि डेटा प्रीऑर्डर किया गया है, उदाहरण के लिए, एक कवरिंग इंडेक्स में, पहले से ऑर्डर की गई स्ट्रीम एग्रीगेट रणनीति सबसे अच्छा विकल्प है, चाहे कितनी भी पंक्तियाँ शामिल हों। उदाहरण के लिए, मान लें कि आपको ऑर्डर तालिका को क्वेरी करने की आवश्यकता है, और प्रत्येक कर्मचारी के लिए अधिकतम ऑर्डर तिथि की गणना करें। आप निम्न कवरिंग इंडेक्स बनाते हैं:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);पर INDEX idx_eid_od बनाएं
विभिन्न पंक्तियों (10,000, 20,000, 30,000, 40,000 और 50,000) के साथ ऑर्डर तालिका का अनुकरण करते हुए, यहां पांच प्रश्न दिए गए हैं:
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
चित्र 6 इन प्रश्नों की योजना दिखाता है।
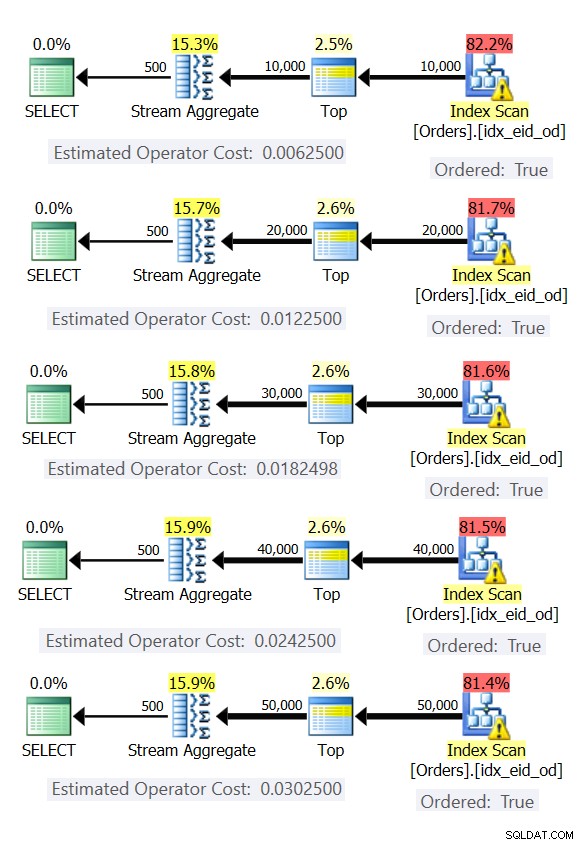
चित्र 6:पहले से ऑर्डर की गई स्ट्रीम एग्रीगेट रणनीति वाली योजनाएं
सभी मामलों में, योजनाएं कवरिंग इंडेक्स का एक क्रमबद्ध स्कैन करती हैं, और स्पष्ट सॉर्टिंग की आवश्यकता के बिना स्ट्रीम एग्रीगेट ऑपरेटर को लागू करती हैं।
इस उदाहरण के लिए आपके द्वारा बनाई गई अनुक्रमणिका को छोड़ने के लिए निम्न कोड का उपयोग करें:
DROP INDEX idx_eid_od ON dbo.Orders;
चित्र 5 में ग्राफ़ के बारे में ध्यान देने योग्य दूसरी महत्वपूर्ण बात यह है कि जब डेटा पहले से ऑर्डर नहीं किया जाता है तो क्या होता है। ऐसा तब होता है जब कोई कवरिंग इंडेक्स नहीं होता है, साथ ही जब आप आधार कॉलम के विपरीत हेरफेर किए गए अभिव्यक्तियों द्वारा समूहित करते हैं। एक अनुकूलन सीमा है—हमारे मामले में 1454.046 पंक्तियों में—जिसके नीचे सॉर्ट + स्ट्रीम एग्रीगेट रणनीति की लागत कम है, और जिस पर हैश एग्रीगेट रणनीति की लागत कम है। यह इस तथ्य से संबंधित है कि पूर्व हैश एक कम स्टार्टअप लागत है, लेकिन एक n लॉग n तरीके से स्केल करता है, जबकि बाद वाले की स्टार्टअप लागत अधिक होती है लेकिन रैखिक रूप से स्केल होती है। यह पूर्व को छोटी संख्या में इनपुट पंक्तियों के साथ पसंद करता है। यदि हमारे रिवर्स इंजीनियर सूत्र सटीक हैं, तो निम्नलिखित दो प्रश्नों (उन्हें प्रश्न 10 और प्रश्न 11 कहते हैं) को अलग-अलग योजनाएँ मिलनी चाहिए:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
इन प्रश्नों की योजना चित्र 7 में दिखाई गई है।
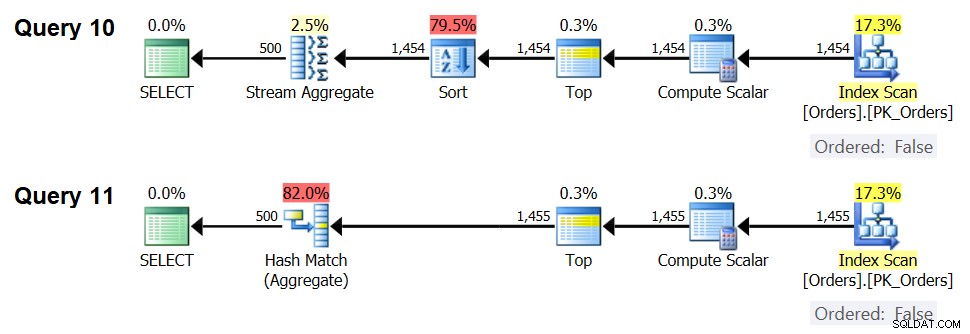
चित्र 7:प्रश्न 10 और प्रश्न 11 के लिए योजनाएं
दरअसल, 1,454 इनपुट पंक्तियों (ऑप्टिमाइज़ेशन थ्रेशोल्ड के नीचे) के साथ, ऑप्टिमाइज़र स्वाभाविक रूप से क्वेरी 10 के लिए सॉर्ट + स्ट्रीम एग्रीगेट एल्गोरिथम को प्राथमिकता देता है, और 1,455 इनपुट पंक्तियों (ऑप्टिमाइज़ेशन थ्रेशोल्ड से ऊपर) के साथ, ऑप्टिमाइज़र स्वाभाविक रूप से क्वेरी 11 के लिए हैश एग्रीगेट एल्गोरिथम को प्राथमिकता देता है। ।
अडैप्टिव एग्रीगेट ऑपरेटर के लिए संभावित
ऑप्टिमाइज़ेशन थ्रेसहोल्ड के मुश्किल पहलुओं में से एक पैरामीटर-सूँघने की समस्या है जब संग्रहीत प्रक्रियाओं में पैरामीटर-संवेदनशील प्रश्नों का उपयोग किया जाता है। एक उदाहरण के रूप में निम्न संग्रहीत कार्यविधि पर विचार करें:
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INT AS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= @initialorderid GROUP BY empid; GO
संग्रहीत कार्यविधि क्वेरी का समर्थन करने के लिए आप निम्न इष्टतम अनुक्रमणिका बनाते हैं:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
आपने क्वेरी के रेंज फ़िल्टर का समर्थन करने के लिए ऑर्डरिड के साथ इंडेक्स बनाया है, और कवरेज के लिए एम्पीड शामिल किया है। यह एक ऐसी स्थिति है जहां आप वास्तव में एक इंडेक्स नहीं बना सकते हैं जो रेंज फिल्टर का समर्थन करेगा और फ़िल्टर की गई पंक्तियों को ग्रुपिंग सेट द्वारा पूर्व-आदेशित किया जाएगा। इसका मतलब है कि ऑप्टिमाइज़र को सॉर्ट + स्ट्रीम एग्रीगेट और हैश एग्रीगेट एल्गोरिदम के बीच चुनाव करना होगा। हमारे लागत फ़ार्मुलों के आधार पर, अनुकूलन सीमा 937 और 938 इनपुट पंक्तियों (मान लीजिए, 937.5 पंक्तियों) के बीच है।
मान लीजिए कि आप पहली बार एक इनपुट प्रारंभिक ऑर्डर आईडी के साथ संग्रहीत प्रक्रिया को निष्पादित करते हैं जो आपको कम संख्या में मैच (थ्रेशोल्ड के नीचे) देता है:
EXEC dbo.EmpOrders @initialorderid = 999991;
SQL सर्वर एक योजना तैयार करता है जो सॉर्ट + स्ट्रीम एग्रीगेट एल्गोरिथम का उपयोग करता है, और योजना को कैश करता है। बाद के निष्पादन कैश्ड योजना का पुन:उपयोग करते हैं, चाहे कितनी भी पंक्तियाँ शामिल हों। उदाहरण के लिए, निम्न निष्पादन में अनुकूलन सीमा से ऊपर कई मिलान हैं:
EXEC dbo.EmpOrders @initialorderid = 990001;
फिर भी, यह कैश्ड योजना का पुन:उपयोग करता है, इस तथ्य के बावजूद कि यह इस निष्पादन के लिए इष्टतम नहीं है। यह एक क्लासिक पैरामीटर सूँघने की समस्या है।
SQL सर्वर 2017 अनुकूली क्वेरी प्रोसेसिंग क्षमताओं का परिचय देता है, जिन्हें क्वेरी निष्पादन के दौरान निर्धारित करके ऐसी स्थितियों से निपटने के लिए डिज़ाइन किया गया है कि किस रणनीति को नियोजित करना है। उन सुधारों में एक एडेप्टिव जॉइन ऑपरेटर है जो निष्पादन के दौरान यह निर्धारित करता है कि गणना की गई ऑप्टिमाइज़ेशन थ्रेशोल्ड के आधार पर लूप या हैश एल्गोरिथम को सक्रिय करना है या नहीं। हमारी समग्र कहानी एक समान एडेप्टिव एग्रीगेट ऑपरेटर की मांग करती है, जो निष्पादन के दौरान गणना की गई ऑप्टिमाइज़ेशन थ्रेशोल्ड के आधार पर सॉर्ट + स्ट्रीम एग्रीगेट रणनीति और हैश एग्रीगेट रणनीति के बीच चुनाव करेगा। चित्र 8 इस विचार पर आधारित एक छद्म योजना को दर्शाता है।
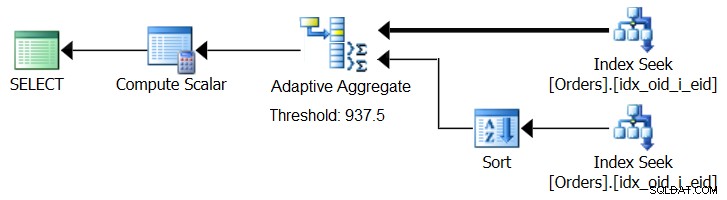
चित्र 8:अनुकूली सकल ऑपरेटर के साथ छद्म योजना
अभी के लिए, ऐसी योजना प्राप्त करने के लिए आपको Microsoft पेंट का उपयोग करने की आवश्यकता है। लेकिन चूंकि अनुकूली क्वेरी प्रोसेसिंग की अवधारणा इतनी स्मार्ट है और इतनी अच्छी तरह से काम करती है, इसलिए भविष्य में इस क्षेत्र में और सुधार देखने की उम्मीद करना ही उचित है।
इस उदाहरण के लिए आपके द्वारा बनाई गई अनुक्रमणिका को छोड़ने के लिए निम्न कोड चलाएँ:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
निष्कर्ष
इस लेख में मैंने हैश एग्रीगेट एल्गोरिदम की लागत और स्केलिंग को कवर किया और इसकी तुलना स्ट्रीम एग्रीगेट और सॉर्ट + स्ट्रीम एग्रीगेट रणनीतियों से की। मैंने सॉर्ट + स्ट्रीम एग्रीगेट और हैश एग्रीगेट रणनीतियों के बीच मौजूद ऑप्टिमाइज़ेशन थ्रेशोल्ड का वर्णन किया है। इनपुट पंक्तियों की छोटी संख्या के साथ पूर्व को प्राथमिकता दी जाती है और बड़ी संख्या के साथ बाद वाली। मैंने पैरामीटर-संवेदी प्रश्नों का उपयोग करते समय पैरामीटर-सूँघने की समस्याओं से निपटने में मदद करने के लिए, पहले से लागू एडेप्टिव जॉइन ऑपरेटर के समान एक एडेप्टिव एग्रीगेट ऑपरेटर को जोड़ने की क्षमता का भी वर्णन किया। अगले महीने मैं समांतरता के विचारों और उन मामलों को कवर करके चर्चा जारी रखूंगा जो क्वेरी को फिर से लिखने के लिए कहते हैं।