यह लेख ऑप्टिमाइज़ेशन थ्रेशोल्ड के बारे में श्रृंखला में चौथा है। श्रृंखला में समूहीकरण और एकत्रीकरण डेटा शामिल है, जो SQL सर्वर द्वारा उपयोग किए जा सकने वाले विभिन्न एल्गोरिदम की व्याख्या करता है, और लागत मॉडल जो इसे एल्गोरिदम के बीच चयन करने में मदद करता है। इस लेख में मैं समानतावाद के विचारों पर ध्यान केंद्रित करता हूं। मैं विभिन्न समानांतरवाद रणनीतियों को कवर करता हूं जो SQL सर्वर उपयोग कर सकता है, एक सीरियल और एक समानांतर योजना के बीच चयन करने के लिए थ्रेसहोल्ड, और लागत तर्क जो SQL सर्वर एक अवधारणा का उपयोग करके लागू होता है जिसे कॉस्टिंग के लिए समानांतरवाद की डिग्री कहा जाता है। (लागत के लिए डीओपी)।
मैं अपने उदाहरणों में PerformanceV3 नमूना डेटाबेस में dbo.Orders तालिका का उपयोग जारी रखूंगा। इस आलेख में उदाहरणों को चलाने से पहले, कुछ अनावश्यक अनुक्रमणिकाओं को छोड़ने के लिए निम्न कोड चलाएँ:
DROP INDEX IF EXISTS idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX IF EXISTS idx_unc_od_oid_i_cid_eid ON dbo.Orders;
इस टेबल पर केवल दो इंडेक्स छोड़े जाने चाहिए idx_cl_od (कुंजी के रूप में ऑर्डरडेट के साथ क्लस्टर) और PK_Orders (कुंजी के रूप में ऑर्डरिड के साथ गैर-क्लस्टर)।
समानांतरता रणनीतियां
विभिन्न ग्रुपिंग और एग्रीगेशन रणनीतियों (पहले से ऑर्डर की गई स्ट्रीम एग्रीगेट, सॉर्ट + स्ट्रीम एग्रीगेट, हैश एग्रीगेट) के बीच चयन करने की आवश्यकता के अलावा, SQL सर्वर को यह भी चुनने की आवश्यकता है कि एक सीरियल या समानांतर योजना के साथ जाना है या नहीं। वास्तव में, यह कई अलग-अलग समांतरता रणनीतियों के बीच चयन कर सकता है। SQL सर्वर कॉस्टिंग लॉजिक का उपयोग करता है जिसके परिणामस्वरूप ऑप्टिमाइज़ेशन थ्रेसहोल्ड होता है जो विभिन्न परिस्थितियों में एक रणनीति को दूसरों के लिए पसंद करता है। हमने पहले ही उस लागत तर्क के बारे में गहराई से चर्चा की है जो SQL सर्वर श्रृंखला के पिछले भागों में धारावाहिक योजनाओं में उपयोग करता है। इस खंड में मैं कई समानांतर रणनीतियों का परिचय दूंगा जिनका उपयोग SQL सर्वर समूहीकरण और एकत्रीकरण को संभालने के लिए कर सकता है। प्रारंभ में, मैं लागत तर्क के विवरण में नहीं जाऊंगा, बल्कि केवल उपलब्ध विकल्पों का वर्णन करूंगा। बाद में लेख में मैं समझाऊंगा कि लागत सूत्र कैसे काम करते हैं, और उन सूत्रों में एक महत्वपूर्ण कारक लागत के लिए डीओपी कहा जाता है।
जैसा कि आप बाद में सीखेंगे, SQL सर्वर समानांतर योजनाओं के लिए अपने लागत सूत्र में मशीन में तार्किक CPU की संख्या को ध्यान में रखता है। मेरे उदाहरणों में, जब तक मैं अन्यथा नहीं कहता, मुझे लगता है कि लक्ष्य प्रणाली में 8 तार्किक सीपीयू हैं। यदि आप मेरे द्वारा प्रदान किए जाने वाले उदाहरणों को आज़माना चाहते हैं, तो मेरे जैसे ही प्लान और लागत मूल्य प्राप्त करने के लिए, आपको 8 लॉजिकल सीपीयू वाली मशीन पर भी कोड चलाने की आवश्यकता है। यदि आपके पास मशीन में सीपीयू की एक अलग संख्या है, तो आप 8 सीपीयू के साथ एक मशीन का अनुकरण कर सकते हैं—लागत के उद्देश्यों के लिए—जैसे:
DBCC OPTIMIZER_WHATIF(CPUs, 8);
भले ही यह टूल आधिकारिक तौर पर प्रलेखित और समर्थित नहीं है, लेकिन यह शोध और सीखने के उद्देश्यों के लिए काफी सुविधाजनक है।
हमारे नमूना डेटाबेस में ऑर्डर तालिका में 1 से 1,000,000 की सीमा में ऑर्डर आईडी के साथ 1,000,000 पंक्तियां हैं। समूहीकरण और एकत्रीकरण के लिए तीन अलग-अलग समानांतरवाद रणनीतियों को प्रदर्शित करने के लिए, मैं उन आदेशों को फ़िल्टर करूँगा जहाँ ऑर्डर आईडी 300001 (700,000 मिलान) से अधिक या उसके बराबर है, और डेटा को तीन अलग-अलग तरीकों से समूहित करता है (कस्टिड द्वारा [फ़िल्टर करने से पहले 20,000 समूह], एम्पिड द्वारा [500 समूह], और शिपरिड [5 समूह]), और प्रति समूह आदेशों की संख्या की गणना करें।
समूहीकृत प्रश्नों का समर्थन करने के लिए अनुक्रमणिका बनाने के लिए निम्न कोड का उपयोग करें:
डीबीओ पर इंडेक्स idx_oid_i_eid बनाएं। ऑर्डर (ऑर्डरिड) शामिल हैं (एम्पिड); डीबीओ पर इंडेक्स आईडीएक्स_ओआईडी_आई_सिड बनाएं। ऑर्डर (ऑर्डरिड) शामिल करें (शिपरिड); इंडेक्स बनाएं (idx_oid_i_cid ON (ऑर्डर आईडी); पूर्व>निम्नलिखित प्रश्न उपरोक्त फ़िल्टरिंग और समूहीकरण को लागू करते हैं:
-- क्वेरी 1:सीरियल सेलेक्ट कस्टिड, काउंट (*) डीबीओ से नंबरों के रूप में। ऑर्डर जहां ऑर्डर होता है> =300001 ग्रुप बाय कस्टिडऑप्शन (मैक्सडॉप 1); -- क्वेरी 2:समानांतर, स्थानीय/वैश्विक चयन कस्टिड नहीं, COUNT(*) के रूप में dbo.OrdersWHERE ऑर्डरिड>=300001GROUP BY custid; -- क्वेरी 3:स्थानीय समानांतर वैश्विक समानांतर सेलेक्ट एम्पिड, काउंट (*) डीबीओ से numorders के रूप में। ऑर्डर जहां ऑर्डरिड> =300001ग्रुप बाय एम्पीड; -- क्वेरी 4:स्थानीय समानांतर वैश्विक सीरियल सेलेक्ट शिपरिड, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY Shipperid;ध्यान दें कि क्वेरी 1 और क्वेरी 2 समान हैं (दोनों समूह कस्टिड द्वारा), केवल पूर्व एक सीरियल प्लान को बाध्य करता है और बाद वाले को 8 सीपीयू वाली मशीन पर समानांतर योजना मिलती है। मैं एक ही क्वेरी के लिए सीरियल और समानांतर रणनीतियों की तुलना करने के लिए इन दो उदाहरणों का उपयोग करता हूं।
चित्र 1 सभी चार प्रश्नों के लिए अनुमानित योजनाएँ दिखाता है:
चित्र 1:समानांतरवाद रणनीतियाँ
अभी के लिए, आंकड़े में दिखाए गए लागत मूल्यों और लागत के लिए डीओपी शब्द के उल्लेख के बारे में चिंता न करें। मैं बाद में उनसे मिलूंगा। सबसे पहले, रणनीतियों और उनके बीच के अंतर को समझने पर ध्यान दें।
प्रश्न 1 के लिए धारावाहिक योजना में उपयोग की जाने वाली रणनीति आपको श्रृंखला के पिछले भागों से परिचित होनी चाहिए। आपके द्वारा पहले बनाए गए कवरिंग इंडेक्स में सीक का उपयोग करके योजना प्रासंगिक ऑर्डर को फ़िल्टर करती है। फिर, पंक्तियों की अनुमानित संख्या को समूहीकृत और एकत्रित करने के साथ, ऑप्टिमाइज़र सॉर्ट + स्ट्रीम एग्रीगेट रणनीति के लिए हैश एग्रीगेट रणनीति को प्राथमिकता देता है।
क्वेरी 2 के लिए योजना एक साधारण समांतरता रणनीति का उपयोग करती है जो केवल एक समग्र ऑपरेटर को नियोजित करती है। एक समानांतर इंडेक्स सीक ऑपरेटर राउंड-रॉबिन फैशन में अलग-अलग थ्रेड्स में पंक्तियों के पैकेट वितरित करता है। पंक्तियों के प्रत्येक पैकेट में कई अलग-अलग ग्राहक आईडी हो सकते हैं। एक एकल कुल ऑपरेटर के लिए सही अंतिम समूह गणना की गणना करने में सक्षम होने के लिए, एक ही समूह से संबंधित सभी पंक्तियों को एक ही थ्रेड द्वारा नियंत्रित किया जाना चाहिए। इस कारण से, समूहीकरण सेट (कस्टिड) द्वारा धाराओं को पुन:विभाजित करने के लिए एक समानांतरवाद (पुनर्विभाजन स्ट्रीम) एक्सचेंज ऑपरेटर का उपयोग किया जाता है। अंत में, एक समानांतरवाद (धाराओं को इकट्ठा करें) एक्सचेंज ऑपरेटर का उपयोग कई थ्रेड्स से स्ट्रीम को परिणाम पंक्तियों की एकल स्ट्रीम में इकट्ठा करने के लिए किया जाता है।
प्रश्न 3 और प्रश्न 4 की योजनाएँ अधिक जटिल समानांतरवाद रणनीति का उपयोग करती हैं। योजनाएं क्वेरी 2 की योजना के समान शुरू होती हैं जहां एक समानांतर इंडेक्स सीक ऑपरेटर पंक्तियों के पैकेट को अलग-अलग थ्रेड्स में वितरित करता है। फिर एग्रीगेशन का काम दो चरणों में किया जाता है:एक एग्रीगेट ऑपरेटर स्थानीय रूप से ग्रुप करता है और मौजूदा थ्रेड की पंक्तियों को इकट्ठा करता है (पार्टिकलैग 1004 रिजल्ट मेंबर को नोटिस करें), और दूसरा एग्रीगेट ऑपरेटर ग्लोबली ग्रुप्स और एग्रीगेट्स लोकल एग्रीगेट्स (ग्लोबलैग 1005 पर ध्यान दें) परिणाम सदस्य)। दो समग्र चरणों में से प्रत्येक-स्थानीय और वैश्विक-श्रृंखला में पहले वर्णित किसी भी कुल एल्गोरिदम का उपयोग कर सकते हैं। क्वेरी 3 और क्वेरी 4 के लिए दोनों योजनाएं स्थानीय हैश एग्रीगेट से शुरू होती हैं और वैश्विक सॉर्ट + स्ट्रीम एग्रीगेट के साथ आगे बढ़ती हैं। दोनों के बीच का अंतर यह है कि पूर्व दोनों चरणों में समानता का उपयोग करता है (इसलिए एक पुनर्विभाजन स्ट्रीम एक्सचेंज का उपयोग दोनों के बीच किया जाता है और ग्लोबल एग्रीगेट के बाद एक गैदर स्ट्रीम एक्सचेंज का उपयोग किया जाता है), और बाद में एक समानांतर क्षेत्र और वैश्विक में स्थानीय समुच्चय को संभालता है। एक सीरियल ज़ोन में कुल (इसलिए दोनों के बीच एक गैदर स्ट्रीम एक्सचेंज का उपयोग किया जाता है)।
सामान्य रूप से क्वेरी ऑप्टिमाइज़ेशन और विशेष रूप से समानता के बारे में अपना शोध करते समय, ऐसे टूल से परिचित होना अच्छा होता है जो आपको उनके प्रभावों को देखने के लिए विभिन्न ऑप्टिमाइज़ेशन पहलुओं को नियंत्रित करने में सक्षम बनाते हैं। आप पहले से ही जानते हैं कि सीरियल प्लान (MAXDOP 1 संकेत के साथ) को कैसे लागू किया जाए, और ऐसे वातावरण का अनुकरण कैसे किया जाए, जिसमें लागत उद्देश्यों के लिए, निश्चित संख्या में तार्किक CPU (DBCC OPTIMIZER_WHATIF, CPUs विकल्प के साथ) हों। एक अन्य उपयोगी उपकरण क्वेरी संकेत ENABLE_PARALLEL_PLAN_PREFERENCE (SQL Server 2016 SP1 CU2 में प्रस्तुत किया गया है), जो समांतरता को अधिकतम करता है। इससे मेरा तात्पर्य यह है कि यदि क्वेरी के लिए समानांतर योजना का समर्थन किया जाता है, तो योजना के सभी हिस्सों में समानता को प्राथमिकता दी जाएगी, जिसे समानांतर में संभाला जा सकता है, जैसे कि यह मुफ़्त था। उदाहरण के लिए, चित्र 1 में देखें कि डिफ़ॉल्ट रूप से क्वेरी 4 की योजना एक सीरियल ज़ोन में स्थानीय समुच्चय और समानांतर क्षेत्र में वैश्विक समुच्चय को संभालती है। यहां वही क्वेरी है, केवल इस बार ENABLE_PARALLEL_PLAN_PREFERENCE क्वेरी संकेत लागू होने के साथ (हम इसे क्वेरी 5 कहेंगे):
शिपरिड का चयन करें, COUNT(*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड>=300001GROUP BY ShipperidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));प्रश्न 5 की योजना चित्र 2 में दिखाई गई है:
चित्र 2:समानता को अधिकतम करना
ध्यान दें कि इस बार स्थानीय और वैश्विक दोनों समुच्चय समानांतर क्षेत्रों में संभाले जाते हैं।
सीरियल/समानांतर योजना विकल्प
याद रखें कि क्वेरी ऑप्टिमाइज़ेशन के दौरान, SQL सर्वर कई उम्मीदवार योजनाएँ बनाता है और सबसे कम लागत वाले को चुनता है। शब्द लागत एक मिथ्या नाम है क्योंकि सबसे कम लागत वाली उम्मीदवार योजना को, अनुमानों के अनुसार, सबसे कम रन टाइम वाला माना जाता है, न कि समग्र रूप से उपयोग किए जाने वाले संसाधनों की सबसे कम राशि वाला। उदाहरण के लिए, एक सीरियल उम्मीदवार योजना और एक ही क्वेरी के लिए उत्पादित समानांतर योजना के बीच, समानांतर योजना अधिक संसाधनों का उपयोग करेगी, क्योंकि इसे एक्सचेंज ऑपरेटरों का उपयोग करने की आवश्यकता होती है जो थ्रेड्स को सिंक्रनाइज़ करते हैं (वितरित, पुनर्विभाजन और स्ट्रीम इकट्ठा करते हैं)। हालांकि, समानांतर योजना के लिए सीरियल प्लान की तुलना में चलने में कम समय की आवश्यकता होती है, कई थ्रेड्स के साथ काम करने से प्राप्त बचत को एक्सचेंज ऑपरेटरों द्वारा किए गए अतिरिक्त काम से अधिक की आवश्यकता होती है। और इसे समांतरता शामिल होने पर SQL सर्वर द्वारा उपयोग किए जाने वाले लागत फ़ार्मुलों द्वारा प्रतिबिंबित करने की आवश्यकता होती है। सटीक रूप से करना आसान काम नहीं है!
समानांतर योजना लागत को प्राथमिकता देने के लिए सीरियल प्लान लागत से कम होने की आवश्यकता के अलावा, सीरियल प्लान विकल्प की लागत समानता के लिए लागत सीमा से अधिक या उसके बराबर होनी चाहिए। . यह एक सर्वर कॉन्फ़िगरेशन विकल्प है जिसे डिफ़ॉल्ट रूप से 5 पर सेट किया जाता है, जो काफी कम लागत वाले प्रश्नों को समानांतरता के साथ नियंत्रित करने से रोकता है। यहां सोच यह है कि बड़ी संख्या में छोटे प्रश्नों वाली प्रणाली को थ्रेड्स को सिंक्रनाइज़ करने पर बहुत सारे संसाधनों को बर्बाद करने के बजाय, धारावाहिक योजनाओं का उपयोग करने से अधिक लाभ होगा। मशीन के मल्टी-सीपीयू संसाधनों का कुशलतापूर्वक उपयोग करते हुए, एक ही समय में निष्पादित होने वाली सीरियल योजनाओं के साथ आपके पास अभी भी कई प्रश्न हो सकते हैं। वास्तव में, कई SQL सर्वर पेशेवर समांतरता के लिए लागत सीमा को इसके डिफ़ॉल्ट 5 से उच्च मान तक बढ़ाना पसंद करते हैं। एक साथ बहुत कम संख्या में बड़ी क्वेरी चलाने वाली प्रणाली को समानांतर योजनाओं का उपयोग करने से बहुत अधिक लाभ होगा।
पुनर्कथन करने के लिए, SQL सर्वर के लिए सीरियल विकल्प के समानांतर योजना को प्राथमिकता देने के लिए, सीरियल प्लान की लागत समानांतरता के लिए कम से कम लागत सीमा होनी चाहिए, और समानांतर योजना लागत को सीरियल प्लान लागत (संभावित रूप से लागू करना) से कम होना चाहिए। कम रन टाइम)।
इससे पहले कि मैं वास्तविक लागत फ़ार्मुलों के विवरण पर पहुँचूँ, मैं उदाहरणों के साथ विभिन्न परिदृश्यों का वर्णन करूँगा जहाँ धारावाहिक और समानांतर योजनाओं के बीच एक विकल्प बनाया जाता है। सुनिश्चित करें कि यदि आप उदाहरणों को आज़माना चाहते हैं, तो सुनिश्चित करें कि आपका सिस्टम मेरे समान क्वेरी लागत प्राप्त करने के लिए 8 तार्किक CPU ग्रहण करता है।
निम्नलिखित प्रश्नों पर विचार करें (हम उन्हें प्रश्न 6 और प्रश्न 7 कहेंगे):
-- क्वेरी 6:सीरियल सेलेक्ट एम्पिड, काउंट (*) डीबीओ से नंबरों के रूप में। ऑर्डर जहां ऑर्डर होता है> =400001 एम्पिड द्वारा ग्रुप; -- प्रश्न 7:बलपूर्वक समानांतर चयन एम्पिड, COUNT(*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड>=400001GROUP BY empidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));इन प्रश्नों की योजना चित्र 3 में दिखाई गई है।
चित्र 3:सीरियल की लागत <समानांतरता के लिए लागत सीमा, समानांतर लागत <धारावाहिक लागत
यहां, [मजबूर] समानांतर योजना लागत सीरियल योजना लागत से कम है; हालांकि, सीरियल प्लान की लागत 5 की समानांतरता के लिए डिफ़ॉल्ट लागत सीमा से कम है, इसलिए SQL सर्वर ने डिफ़ॉल्ट रूप से सीरियल प्लान को चुना।
निम्नलिखित प्रश्नों पर विचार करें (हम उन्हें प्रश्न 8 और प्रश्न 9 कहेंगे):
-- क्वेरी 8:समानांतर चयन एम्पिड, काउंट (*) डीबीओ से संख्याओं के रूप में। ऑर्डर जहां ऑर्डर होता है> =300001 एम्पिड द्वारा ग्रुप; -- प्रश्न 9:जबरन सीरियल सेलेक्ट एम्पिड, COUNT(*) के रूप में numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empidOPTION(MAXDOP 1);इन प्रश्नों की योजना चित्र 4 में दिखाई गई है।
चित्र 4:सीरियल की लागत>=समांतरता के लिए लागत सीमा, समानांतर लागत <धारावाहिक लागत
यहां, [मजबूर] सीरियल योजना लागत समांतरता के लिए लागत सीमा से अधिक या उसके बराबर है, और समानांतर योजना लागत सीरियल योजना लागत से कम है, इसलिए SQL सर्वर ने डिफ़ॉल्ट रूप से समानांतर योजना को चुना है।
निम्नलिखित प्रश्नों पर विचार करें (हम उन्हें प्रश्न 10 और प्रश्न 11 कहेंगे):
-- क्वेरी 10:सीरियल चयन * डीबीओ से। ऑर्डर जहां ऑर्डर करें> =100000; - प्रश्न 11:जबरन समानांतर चयन * डीबीओ से। आदेश जहां आदेश दिया गया> =100000 विकल्प (उपयोग संकेत ('ENABLE_PARALLEL_PLAN_PREFERENCE'));इन प्रश्नों की योजना चित्र 5 में दिखाई गई है।
चित्र 5:सीरियल की लागत>=समानता के लिए लागत सीमा, समानांतर लागत>=क्रमागत लागत
यहां, सीरियल प्लान की लागत समांतरता के लिए लागत सीमा से अधिक या उसके बराबर है; हालाँकि, सीरियल प्लान की लागत [मजबूर] समानांतर योजना लागत से कम है, इसलिए SQL सर्वर ने डिफ़ॉल्ट रूप से सीरियल प्लान को चुना।
ENABLE_PARALLEL_PLAN_PREFERENCE संकेत के साथ समानता को अधिकतम करने के प्रयास के बारे में आपको एक और बात जानने की आवश्यकता है। SQL सर्वर के लिए समानांतर योजना का उपयोग करने में सक्षम होने के लिए, कुछ समांतरता प्रवर्तक होना चाहिए जैसे अवशिष्ट विधेय, एक प्रकार, एक समुच्चय, और इसी तरह। एक योजना जो केवल एक इंडेक्स स्कैन या इंडेक्स सीक को बिना किसी अवशिष्ट विधेय के लागू करती है, और बिना किसी अन्य समांतरता प्रवर्तक के, एक सीरियल प्लान के साथ संसाधित की जाएगी। एक उदाहरण के रूप में निम्नलिखित प्रश्नों पर विचार करें (हम उन्हें प्रश्न 12 और प्रश्न 13 कहेंगे):
-- क्वेरी 12 चुनें * डीबीओ से ऑर्डर विकल्प (उपयोग संकेत ('ENABLE_PARALLEL_PLAN_PREFERENCE')); -- क्वेरी 13 चुनें * डीबीओ से। ऑर्डर जहां ऑर्डर करें> =100000 विकल्प (उपयोग संकेत ('ENABLE_PARALLEL_PLAN_PREFERENCE'));इन प्रश्नों की योजना चित्र 6 में दिखाई गई है।
चित्र 6:समानांतरवाद सक्षम करने वाला
प्रश्न 12 को संकेत के बावजूद एक धारावाहिक योजना मिलती है क्योंकि कोई समानांतरता प्रवर्तक नहीं है। क्वेरी 13 को एक समानांतर योजना मिलती है क्योंकि इसमें एक अवशिष्ट विधेय शामिल होता है।
लागत के लिए डीओपी की गणना और परीक्षण
Microsoft को लागत फ़ार्मुलों को क्रमानुसार योजना लागत की तुलना में कम समानांतर योजना लागत के प्रयास में जांचना पड़ा, जो कम रन टाइम को दर्शाती है और इसके विपरीत। एक संभावित विचार सीरियल ऑपरेटर की सीपीयू लागत लेना था और समानांतर ऑपरेटर की सीपीयू लागत का उत्पादन करने के लिए इसे मशीन में तार्किक सीपीयू की संख्या से विभाजित करना था। मशीन में सीपीयू की तार्किक संख्या क्वेरी की समानांतरता की डिग्री निर्धारित करने वाला मुख्य कारक है, या संक्षेप में डीओपी (योजना में समानांतर क्षेत्र में उपयोग किए जा सकने वाले थ्रेड्स की संख्या)। यहाँ सरल सोच यह है कि यदि कोई ऑपरेटर एक थ्रेड का उपयोग करते समय पूरा करने के लिए T समय इकाइयाँ लेता है, और क्वेरी की समानांतरता की डिग्री D है, तो D थ्रेड का उपयोग करते समय ऑपरेटर T/D को पूरा करने में समय लगेगा। व्यवहार में, चीजें इतनी सरल नहीं हैं। उदाहरण के लिए, आमतौर पर आपके पास एक साथ चलने वाले कई प्रश्न होते हैं और केवल एक ही नहीं, ऐसे में एक ही क्वेरी को मशीन के सभी CPU संसाधन नहीं मिलेंगे। इसलिए, Microsoft लागत के लिए समानांतरवाद की डिग्री . के विचार के साथ आया (लागत के लिए डीओपी, संक्षेप में)। यह माप आम तौर पर मशीन में तार्किक सीपीयू की संख्या से कम होता है और यह कारक है कि सीरियल ऑपरेटर की सीपीयू लागत को समानांतर ऑपरेटर की सीपीयू लागत की गणना करने के लिए विभाजित किया जाता है।
आम तौर पर, लागत के लिए डीओपी की गणना पूर्णांक विभाजन का उपयोग करके 2 से विभाजित तार्किक सीपीयू की संख्या के रूप में की जाती है। हालांकि अपवाद हैं। जब CPU की संख्या 2 या 3 होती है, तो लागत के लिए DOP 2 पर सेट होता है। 4 या अधिक CPU के साथ, पूर्णांक विभाजन का उपयोग करते हुए, कॉस्टिंग के लिए DOP को #CPUs / 2 पर फिर से सेट किया जाता है। यह एक निश्चित अधिकतम तक है, जो मशीन के लिए उपलब्ध मेमोरी की मात्रा पर निर्भर करता है। 4,096 एमबी तक मेमोरी वाली मशीन में लागत के लिए अधिकतम डीओपी 8 है; 4,096 एमबी से अधिक के साथ, लागत के लिए अधिकतम डीओपी 32 है।
इस तर्क का परीक्षण करने के लिए, आप पहले से ही जानते हैं कि सीपीयू विकल्प के साथ, DBCC OPTIMIZER_WHATIF का उपयोग करके वांछित संख्या में तार्किक CPU का अनुकरण कैसे करें, जैसे:
DBCC OPTIMIZER_WHATIF(CPUs, 8);मेमोरीएमबी विकल्प के साथ समान कमांड का उपयोग करके, आप एमबी में वांछित मात्रा में मेमोरी का अनुकरण कर सकते हैं, जैसे:
DBCC OPTIMIZER_WHATIF(MemoryMBs, 16384);नकली विकल्पों की मौजूदा स्थिति की जांच के लिए निम्नलिखित कोड का प्रयोग करें:
डीबीसीसी TRACEON(3604); डीबीसीसी OPTIMIZER_WHATIF (स्थिति); डीबीसीसी ट्रेसऑफ़(3604);सभी विकल्पों को रीसेट करने के लिए निम्न कोड का उपयोग करें:
DBCC OPTIMIZER_WHATIF(ResetAll);यहां एक टी-एसक्यूएल क्वेरी है जिसका उपयोग आप तार्किक सीपीयू की इनपुट संख्या और मेमोरी की मात्रा के आधार पर लागत के लिए डीओपी की गणना करने के लिए कर सकते हैं:
DECLARE @NumCPUs AS INT =8, @MemoryMBs AS INT =16384; मामले का चयन करें जब @NumCPUs =1 तब 1 जब @NumCPUs <=3 तब 2 जब @NumCPUs> =4 तब (चुनें MIN(n) से ( VALUES(@NumCPUs / 2), (MaxDOP4C)) AS D2(n)) DOP4CFROM के रूप में समाप्त करें ( VALUES(केस जब @MemoryMBs <=4096 तब 8 ELSE 32 END)) AS D1(MaxDOP4C);निर्दिष्ट इनपुट मानों के साथ, यह क्वेरी 4 लौटाती है।
तालिका 1 आपके मशीन में सीपीयू की तार्किक संख्या और मेमोरी की मात्रा के आधार पर आपको मिलने वाली लागत के लिए डीओपी का विवरण देती है।
| #CPUs | मेमोरीएमबी के समय लागत के लिए डीओपी <=4096 | मेमोरीएमबी के समय लागत के लिए डीओपी> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
तालिका 1:लागत के लिए DOP
एक उदाहरण के रूप में, आइए पहले दिखाए गए प्रश्न 1 और प्रश्न 2 पर फिर से विचार करें:
-- क्वेरी 1:फोर्स्ड सीरियल सेलेक्ट कस्टिड, COUNT(*) के रूप में संख्या के रूप में dbo.OrdersWHERE ऑर्डरिड>=300001GROUP BY custidOPTION(MAXDOP 1); -- प्रश्न 2:स्वाभाविक रूप से समानांतर सेलेक्ट कस्टिड, COUNT(*) के रूप में dbo.OrdersWHERE ऑर्डरिड>=300001GROUP BY custid;
इन प्रश्नों की योजना चित्र 7 में दिखाई गई है।
 चित्र 7:के लिए डीओपी लागत
चित्र 7:के लिए डीओपी लागत
क्वेरी 1 एक सीरियल प्लान को बाध्य करता है, जबकि क्वेरी 2 को मेरे वातावरण में समानांतर योजना मिलती है (8 लॉजिकल सीपीयू और 16,384 एमबी मेमोरी का अनुकरण)। इसका मतलब है कि मेरे वातावरण में लागत के लिए डीओपी 4 है। जैसा कि उल्लेख किया गया है, एक समानांतर ऑपरेटर की सीपीयू लागत की गणना सीरियल ऑपरेटर की सीपीयू लागत के रूप में की जाती है, जिसे डीओपी द्वारा लागत के लिए विभाजित किया जाता है। आप देख सकते हैं कि इंडेक्स सीक और हैश एग्रीगेट ऑपरेटरों के साथ हमारी समानांतर योजना में वास्तव में ऐसा ही है जो समानांतर में निष्पादित होते हैं।
एक्सचेंज ऑपरेटरों की लागत के लिए, वे एक स्टार्टअप लागत और कुछ स्थिर लागत प्रति पंक्ति से बने होते हैं, जिसे आप आसानी से इंजीनियर को उलट सकते हैं।
ध्यान दें कि साधारण समानांतर समूहीकरण और एकत्रीकरण रणनीति में, जिसका उपयोग यहां किया गया है, सीरियल और समानांतर योजनाओं में कार्डिनैलिटी का अनुमान समान है। ऐसा इसलिए है क्योंकि केवल एक कुल ऑपरेटर कार्यरत है। बाद में आप देखेंगे कि स्थानीय/वैश्विक रणनीति का उपयोग करते समय चीजें भिन्न होती हैं।
निम्नलिखित प्रश्न तार्किक सीपीयू की संख्या और क्वेरी लागत पर शामिल पंक्तियों की संख्या के प्रभाव को स्पष्ट करने में मदद करते हैं (10 प्रश्न, 100K पंक्तियों की वृद्धि के साथ):
एम्पिड चुनें, COUNT(*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड>=900001GROUP BY empid; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में डीबीओ से। ऑर्डर जहां ऑर्डर करें> =800001 एम्पिड द्वारा ग्रुप; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में डीबीओ से। ऑर्डर जहां ऑर्डर करें> =700001 एम्पिड द्वारा ग्रुप; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में डीबीओ से। ऑर्डर जहां ऑर्डर करें> =600001 एम्पिड द्वारा ग्रुप; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड> =500001ग्रुप बाय एम्पिड; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में डीबीओ से। ऑर्डर जहां ऑर्डर करें> =400001 एम्पिड द्वारा ग्रुप; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड> =300001ग्रुप बाय एम्पिड; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में डीबीओ से। ऑर्डर जहां ऑर्डर करें> =200001 एम्पिड द्वारा ग्रुप; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड> =100001ग्रुप बाय एम्पिड; एम्पिड चुनें, COUNT(*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड>=000001ग्रुप बाय एम्पिड;
चित्र 8 परिणाम दिखाता है।
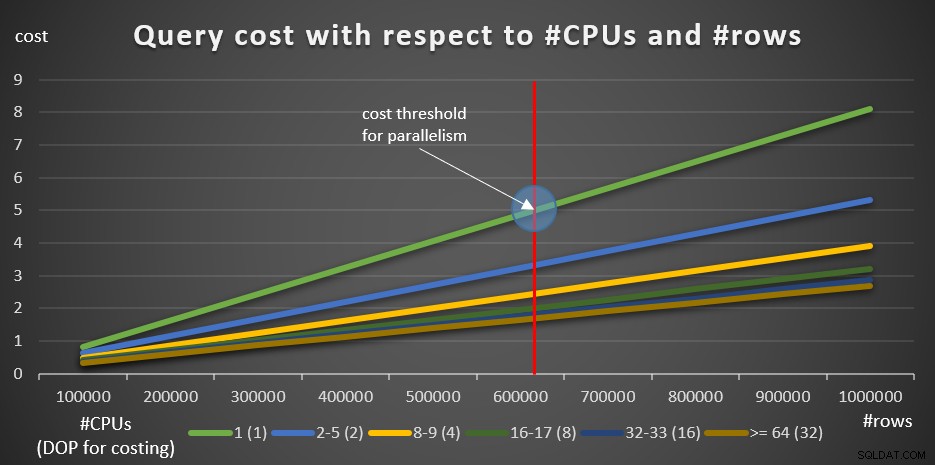
चित्र 8:क्वेरी लागत #CPU और #rows . के संबंध में
हरी रेखा एक सीरियल प्लान का उपयोग करके विभिन्न प्रश्नों (पंक्तियों की विभिन्न संख्याओं के साथ) की लागत का प्रतिनिधित्व करती है। अन्य लाइनें अलग-अलग संख्या में तार्किक सीपीयू के साथ समानांतर योजनाओं की लागत और लागत के लिए उनके संबंधित डीओपी का प्रतिनिधित्व करती हैं। लाल रेखा उस बिंदु का प्रतिनिधित्व करती है जहां सीरियल क्वेरी लागत 5 है—समानांतरता सेटिंग के लिए डिफ़ॉल्ट लागत सीमा। इस बिंदु के बाईं ओर (कुछ पंक्तियों को समूहीकृत और एकत्रित किया जाना है), सामान्य रूप से, अनुकूलक समानांतर योजना पर विचार नहीं करेगा। समांतरता के लिए लागत सीमा से नीचे समानांतर योजनाओं की लागतों पर शोध करने में सक्षम होने के लिए, आप दो चीजों में से एक कर सकते हैं। एक विकल्प क्वेरी संकेत ENABLE_PARALLEL_PLAN_PREFERENCE का उपयोग करना है, लेकिन एक अनुस्मारक के रूप में, यह विकल्प समांतरता को केवल मजबूर करने के विपरीत अधिकतम करता है। यदि यह वांछित प्रभाव नहीं है, तो आप समानता के लिए लागत सीमा को अक्षम कर सकते हैं, जैसे:
EXEC sp_configure 'उन्नत विकल्प दिखाएं', 1; पुन:कॉन्फ़िगर करें; EXEC sp_configure 'समानता के लिए लागत सीमा', 0; EXEC sp_configure 'उन्नत विकल्प दिखाएं', 0; पुन:कॉन्फ़िगर करें;
जाहिर है, यह उत्पादन प्रणाली में एक स्मार्ट कदम नहीं है, लेकिन अनुसंधान उद्देश्यों के लिए पूरी तरह उपयोगी है। चित्र 8 में चार्ट के लिए जानकारी तैयार करने के लिए मैंने यही किया।
100K पंक्तियों के साथ शुरू करना, और 100K वेतन वृद्धि जोड़ना, सभी ग्राफ़ का अर्थ यह प्रतीत होता है कि समानांतरवाद के लिए लागत सीमा एक कारक नहीं थी, एक समानांतर योजना हमेशा पसंद की जाती। वास्तव में हमारे प्रश्नों और शामिल पंक्तियों की संख्या के मामले में ऐसा ही है। हालांकि, निम्न पांच प्रश्नों का उपयोग करके 10K से शुरू होकर 10K की वृद्धि करके पंक्तियों की छोटी संख्या का प्रयास करें (फिर से, समानांतरवाद के लिए लागत सीमा को अभी के लिए अक्षम रखें):
एम्पिड चुनें, COUNT(*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड>=990001ग्रुप बाय एम्पिड; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड> =980001ग्रुप बाय एम्पीड; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में डीबीओ से। ऑर्डर जहां ऑर्डर करें> =970001 एम्पिड द्वारा ग्रुप; एम्पिड का चयन करें, काउंट (*) संख्याओं के रूप में डीबीओ से। ऑर्डर जहां ऑर्डर करें> =96001 एम्पिड द्वारा ग्रुप; एम्पिड चुनें, COUNT(*) संख्याओं के रूप में dbo.OrdersWHERE ऑर्डरिड>=950001ग्रुप बाय एम्पिड;
चित्र 9 सीरियल और समानांतर दोनों योजनाओं के साथ क्वेरी लागत दिखाता है (4 सीपीयू का अनुकरण, लागत 2 के लिए डीओपी)।
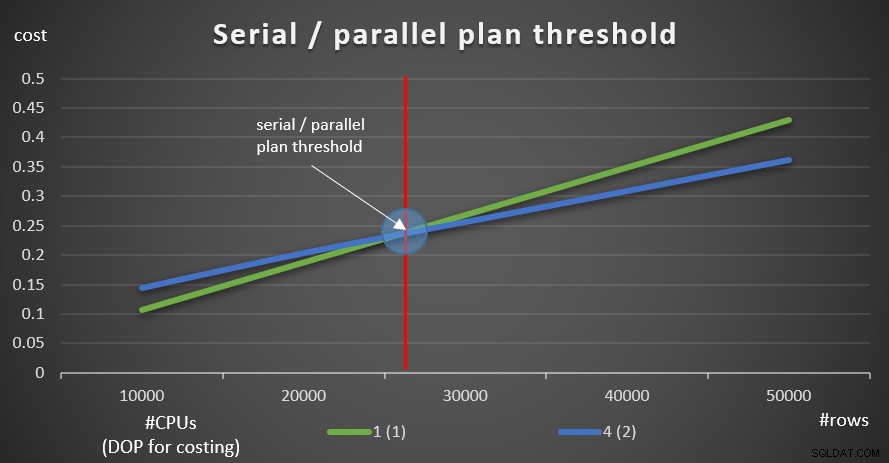 चित्र 9:सीरियल / समानांतर योजना सीमा
चित्र 9:सीरियल / समानांतर योजना सीमा
जैसा कि आप देख सकते हैं, एक अनुकूलन सीमा है जिसके लिए धारावाहिक योजना को प्राथमिकता दी जाती है, और जिसके ऊपर समानांतर योजना को प्राथमिकता दी जाती है। जैसा कि उल्लेख किया गया है, एक सामान्य प्रणाली में जहां आप समानांतरता सेटिंग के लिए लागत सीमा को 5 के डिफ़ॉल्ट मान पर रखते हैं, या इससे अधिक, प्रभावी सीमा वैसे भी इस ग्राफ़ की तुलना में अधिक होती है।
पहले मैंने उल्लेख किया था कि जब SQL सर्वर सरल समूहीकरण और एकत्रीकरण समांतरता रणनीति चुनता है, तो सीरियल और समानांतर योजनाओं के कार्डिनैलिटी अनुमान समान होते हैं। सवाल यह है कि SQL सर्वर स्थानीय/वैश्विक समानांतरवाद रणनीति के लिए कार्डिनैलिटी अनुमानों को कैसे संभालता है।
इसका पता लगाने के लिए, मैं अपने पहले के उदाहरणों से क्वेरी 3 और क्वेरी 4 का उपयोग करूँगा:
-- प्रश्न 3:स्थानीय समानांतर वैश्विक समानांतर चयन empid, COUNT(*) के रूप में numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- क्वेरी 4:स्थानीय समानांतर वैश्विक सीरियल सेलेक्ट शिपरिड, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY Shipperid;
8 लॉजिकल सीपीयू और 4 के लागत मूल्य के लिए एक प्रभावी डीओपी वाले सिस्टम में, मुझे चित्र 10 में दिखाए गए प्लान मिले।
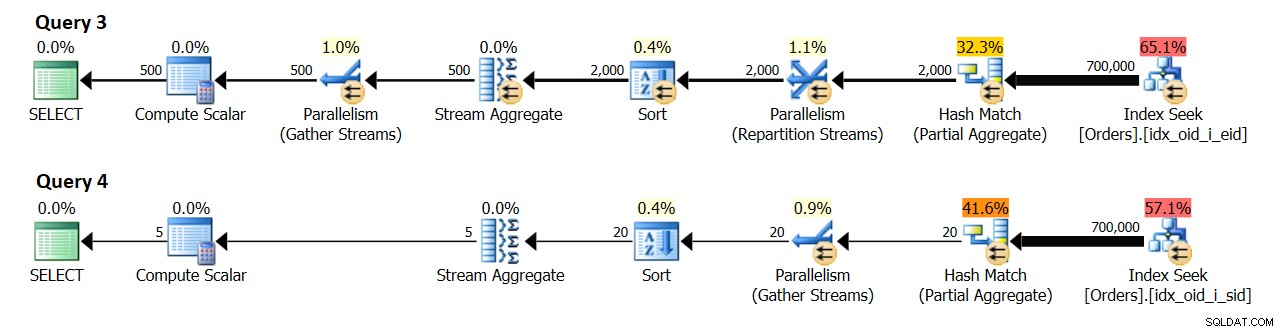 चित्र 10:कार्डिनैलिटी अनुमान
चित्र 10:कार्डिनैलिटी अनुमान
क्वेरी 3 एम्पिड द्वारा आदेशों को समूहित करती है। अंततः 500 अलग-अलग कर्मचारी समूहों की अपेक्षा की जाती है।
क्वेरी 4 ऑर्डर को शिपरिड द्वारा समूहित करती है। अंततः 5 अलग-अलग शिपर समूह अपेक्षित हैं।
उत्सुकता से, ऐसा लगता है कि स्थानीय समुच्चय द्वारा उत्पादित समूहों की संख्या के लिए कार्डिनैलिटी अनुमान {प्रत्येक थ्रेड द्वारा अपेक्षित अलग-अलग समूहों की संख्या} * {लागत के लिए डीओपी} है। व्यवहार में, आप महसूस करते हैं कि संख्या आमतौर पर दोगुने से अधिक होगी क्योंकि निष्पादन के लिए डीओपी क्या मायने रखता है (उर्फ, सिर्फ डीओपी), जो मुख्य रूप से तार्किक सीपीयू की संख्या पर आधारित है। यह हिस्सा अनुसंधान उद्देश्यों के लिए अनुकरण करने के लिए थोड़ा मुश्किल है क्योंकि सीपीयू विकल्प के साथ DBCC OPTIMIZER_WHATIF कमांड लागत के लिए DOP की गणना को प्रभावित करता है, लेकिन निष्पादन के लिए DOP तार्किक CPU की वास्तविक संख्या से अधिक नहीं होगा जो आपके SQL सर्वर इंस्टेंस को देखता है। यह संख्या अनिवार्य रूप से SQL सर्वर के साथ शुरू होने वाले शेड्यूलर की संख्या पर आधारित है। आप कर सकते हैं शेड्यूलर की संख्या को नियंत्रित करें SQL सर्वर -P{ #schedulers } स्टार्टअप पैरामीटर का उपयोग करके शुरू होता है, लेकिन यह सत्र विकल्प की तुलना में थोड़ा अधिक आक्रामक शोध उपकरण है।
किसी भी दर पर, किसी भी संसाधन का अनुकरण किए बिना, मेरी परीक्षण मशीन में 4 तार्किक सीपीयू हैं, जिसके परिणामस्वरूप डीओपी की लागत 2 है, और डीओपी निष्पादन के लिए 4 है। मेरे वातावरण में, क्वेरी 3 के लिए योजना में स्थानीय कुल 1,000 परिणाम समूहों का अनुमान दिखाता है। (500 x 2), और वास्तविक 2,000 (500 x 4)। इसी तरह, क्वेरी 4 के लिए योजना में स्थानीय योग 10 परिणाम समूहों (5 x 2) और वास्तविक 20 (5 x 4) का अनुमान दिखाता है।
जब आप प्रयोग कर लें, तो सफाई के लिए निम्न कोड चलाएँ:
-- डिफ़ॉल्ट के लिए समांतरता के लिए लागत सीमा निर्धारित करें EXEC sp_configure 'उन्नत विकल्प दिखाएं', 1; पुन:कॉन्फ़िगर करें; EXEC sp_configure 'समानता के लिए लागत सीमा', 5; EXEC sp_configure 'उन्नत विकल्प दिखाएं', 0; RECONFIGURE;GO -- Reset OPTIMIZER_WHATIF विकल्प DBCC OPTIMIZER_WHATIF(ResetAll); - ड्रॉप इंडेक्स DROP INDEX idx_oid_i_sid ON dbo.Orders;DROP INDEX idx_oid_i_eid ON dbo.Orders;DROP INDEX idx_oid_i_cid ON dbo.Orders;
निष्कर्ष
इस लेख में मैंने कई समानांतरवाद रणनीतियों का वर्णन किया है जो SQL सर्वर समूहीकरण और एकत्रीकरण को संभालने के लिए उपयोग करता है। समानांतर योजनाओं के साथ प्रश्नों के अनुकूलन में समझने के लिए एक महत्वपूर्ण अवधारणा लागत के लिए समानांतरवाद (डीओपी) की डिग्री है। मैंने कई अनुकूलन सीमाएँ दिखाईं, जिनमें धारावाहिक और समानांतर योजनाओं के बीच की सीमा, और समानता के लिए सेटिंग लागत सीमा शामिल है। यहां वर्णित अधिकांश अवधारणाएं समूहीकरण और एकत्रीकरण के लिए अद्वितीय नहीं हैं, बल्कि सामान्य रूप से SQL सर्वर में समानांतर योजना विचारों के लिए लागू होती हैं। अगले महीने मैं क्वेरी पुनर्लेखन के साथ अनुकूलन पर चर्चा करके श्रृंखला जारी रखूंगा।



