यह पांच-भाग श्रृंखला का दूसरा भाग है जो SQL सर्वर पंक्ति मोड समानांतर योजनाओं के शुरू होने के तरीके में गहरा गोता लगाता है। पहले भाग के अंत तक, हमने निष्पादन प्रसंग शून्य . बना लिया था मूल कार्य के लिए। इस संदर्भ में निष्पादन योग्य ऑपरेटरों का पूरा पेड़ है, लेकिन वे अभी तक क्वेरी प्रोसेसिंग इंजन के पुनरावृत्त निष्पादन मॉडल के लिए तैयार नहीं हैं।
पुनरावृत्तीय निष्पादन
SQL सर्वर क्वेरी स्कैन . नामक प्रक्रिया के माध्यम से एक क्वेरी निष्पादित करता है . Open . को कॉल करने वाले क्वेरी प्रोसेसर द्वारा योजना का प्रारंभ रूट पर प्रारंभ होता है रूट नोड पर। Open कॉल इटरेटर्स के ट्री को ट्रैवर्स करती है और Open . को रिकर्सिवली कॉल करती है प्रत्येक बच्चे पर जब तक कि पूरा पेड़ न खुल जाए।
परिणाम पंक्तियों को वापस करने की प्रक्रिया भी पुनरावर्ती होती है, जिसे GetRow . कॉल करने वाले क्वेरी प्रोसेसर द्वारा ट्रिगर किया जाता है जड़ में। प्रत्येक रूट कॉल एक बार में एक पंक्ति देता है। क्वेरी प्रोसेसर GetRow को कॉल करना जारी रखता है रूट नोड पर जब तक कोई और पंक्तियाँ उपलब्ध न हों। अंतिम पुनरावर्ती Close . के साथ निष्पादन बंद हो जाता है बुलाना। यह व्यवस्था क्वेरी प्रोसेसर को रूट पर समान इंटरफ़ेस विधियों को कॉल करके किसी भी मनमानी योजना को प्रारंभ करने, निष्पादित करने और बंद करने की अनुमति देती है।
निष्पादन योग्य ऑपरेटरों के पेड़ को पंक्ति-दर-पंक्ति प्रसंस्करण के लिए उपयुक्त में बदलने के लिए, SQL सर्वर एक क्वेरी स्कैन जोड़ता है प्रत्येक ऑपरेटर के लिए रैपर। क्वेरी स्कैन ऑब्जेक्ट Open प्रदान करता है , GetRow , और Close पुनरावृत्त निष्पादन के लिए आवश्यक विधियाँ।
क्वेरी स्कैन ऑब्जेक्ट राज्य की जानकारी को भी बनाए रखता है, और निष्पादन के दौरान आवश्यक अन्य ऑपरेटर-विशिष्ट विधियों को उजागर करता है। उदाहरण के लिए, स्टार्ट-अप फ़िल्टर ऑपरेटर के लिए क्वेरी स्कैन ऑब्जेक्ट (CQScanStartupFilterNew ) निम्नलिखित विधियों को उजागर करता है:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
इस पुनरावर्तक के लिए अतिरिक्त विधियां अधिकतर कर्सर योजनाओं में नियोजित होती हैं।
क्वेरी स्कैन प्रारंभ करना
रैपिंग प्रक्रिया को क्वेरी स्कैन आरंभ करना . कहा जाता है . यह क्वेरी प्रोसेसर से CQueryScan::InitQScanRoot पर कॉल करके किया जाता है . मूल कार्य इस प्रक्रिया को संपूर्ण योजना . के लिए निष्पादित करता है (निष्पादन संदर्भ शून्य के भीतर निहित)। अनुवाद की प्रक्रिया अपने आप में पुनरावर्ती प्रकृति की है, जड़ से शुरू होकर पेड़ के नीचे अपना काम करती है।
इस प्रक्रिया के दौरान, प्रत्येक ऑपरेटर अपने स्वयं के डेटा को प्रारंभ करने और कोई भी रनटाइम संसाधन . बनाने के लिए ज़िम्मेदार होता है इसकी जरूरत है। इसमें क्वेरी प्रोसेसर के बाहर अतिरिक्त ऑब्जेक्ट बनाना शामिल हो सकता है, उदाहरण के लिए लगातार स्टोरेज से डेटा लाने के लिए स्टोरेज इंजन के साथ संचार करने के लिए आवश्यक संरचनाएं।
निष्पादन योजना का एक अनुस्मारक, नोड संख्या के साथ जोड़ा गया (विस्तार करने के लिए क्लिक करें):
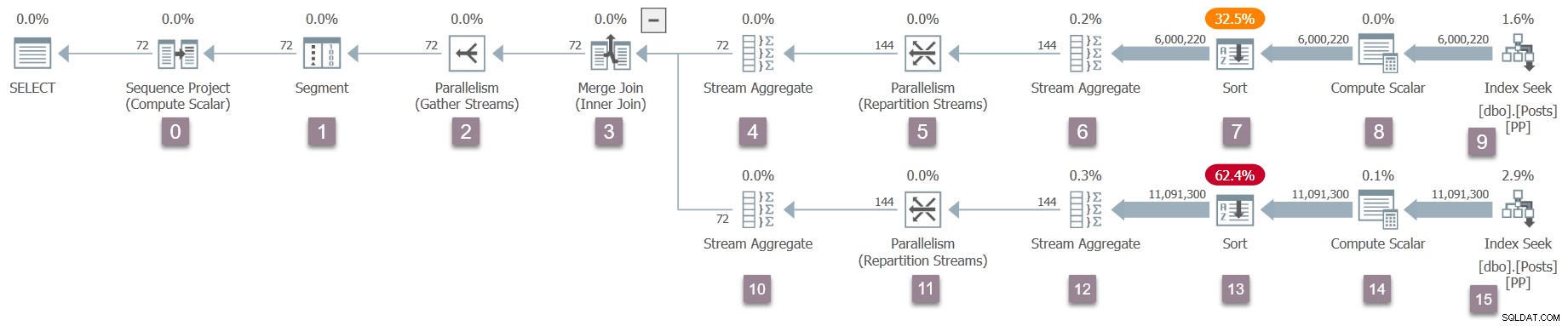
रूट . पर संचालिका (नोड 0) एक्ज़ीक्यूटेबल प्लान ट्री का अनुक्रम प्रोजेक्ट . है . इसे CXteSeqProject . नामक वर्ग द्वारा दर्शाया जाता है . हमेशा की तरह, यहीं से पुनरावर्ती रूपांतरण शुरू होता है।
क्वेरी स्कैन रैपर
जैसा कि बताया गया है, CXteSeqProject ऑब्जेक्ट पुनरावृत्त क्वेरी स्कैन . में भाग लेने के लिए सुसज्जित नहीं है प्रक्रिया — इसमें आवश्यक Open नहीं है , GetRow , और Close तरीके। क्वेरी प्रोसेसर को उस इंटरफ़ेस को प्रदान करने के लिए निष्पादन योग्य ऑपरेटर के चारों ओर एक रैपर की आवश्यकता होती है।
उस क्वेरी स्कैन रैपर को प्राप्त करने के लिए, मूल कार्य CXteSeqProject::QScanGet को कॉल करता है CQScanSeqProjectNew . प्रकार की वस्तु वापस करने के लिए . लिंक किया गया नक्शा पहले बनाए गए ऑपरेटरों के नए क्वेरी स्कैन ऑब्जेक्ट को संदर्भित करने के लिए अद्यतन किया जाता है, और इसके पुनरावर्तक तरीके योजना की जड़ से जुड़े होते हैं।
अनुक्रम प्रोजेक्ट का चाइल्ड एक सेगमेंट . है ऑपरेटर (नोड 1)। कॉलिंग CXteSegment::QScanGet CQScanSegmentNew . प्रकार का क्वेरी स्कैन रैपर ऑब्जेक्ट देता है . लिंक किए गए मानचित्र को फिर से अपडेट किया जाता है, और इटरेटर फ़ंक्शन पॉइंटर्स को पैरेंट अनुक्रम प्रोजेक्ट क्वेरी स्कैन से जोड़ा जाता है।
आधा एक्सचेंज
अगला ऑपरेटर संग्रह स्ट्रीम है एक्सचेंज (नोड 2)। कॉलिंग CXteExchange::QScanGet एक CQScanExchangeNew देता है जैसा कि आप अब तक उम्मीद कर रहे होंगे।
यह पेड़ में पहला ऑपरेटर है जिसे महत्वपूर्ण अतिरिक्त आरंभीकरण करने की आवश्यकता है। यह उपभोक्ता पक्ष . बनाता है एक्सचेंज के CXTransport::CreateConsumerPart . के माध्यम से . यह पोर्ट बनाता है (CXPort ) — साझा स्मृति में एक डेटा संरचना जिसका उपयोग सिंक्रनाइज़ेशन और डेटा विनिमय के लिए किया जाता है — और एक पाइप (CXPipe ) पैकेट परिवहन के लिए। ध्यान दें कि निर्माता एक्सचेंज का पक्ष बनाया नहीं गया . है इस समय। हमारे पास केवल आधा एक्सचेंज है!
अधिक रैपिंग
क्वेरी प्रोसेसर स्कैन को सेट करने की प्रक्रिया मर्ज जॉइन . के साथ जारी रहती है (नोड 3)। मैं हमेशा QScanGet को नहीं दोहराऊंगा और CQScan* इस बिंदु से कॉल, लेकिन वे स्थापित पैटर्न का पालन करते हैं।
मर्ज जॉइन के दो बच्चे हैं। बाहरी (शीर्ष) इनपुट के साथ क्वेरी स्कैन सेटअप पहले की तरह जारी है — एक स्ट्रीम एग्रीगेट (नोड 4), फिर एक पुनर्विभाजन स्ट्रीम एक्सचेंज (नोड 5)। पुनर्विभाजन धाराएँ फिर से एक्सचेंज का केवल उपभोक्ता पक्ष बनाती हैं, लेकिन इस बार दो पाइप बनाए गए हैं क्योंकि डीओपी दो है। इस प्रकार के एक्सचेंज के उपभोक्ता पक्ष के पास अपने मूल ऑपरेटर (एक प्रति थ्रेड) के लिए डीओपी कनेक्शन हैं।
आगे हमारे पास एक और स्ट्रीम एग्रीगेट . है (नोड 6) और एक सॉर्ट (नोड 7)। सॉर्ट में एक बच्चा निष्पादन योजनाओं में दिखाई नहीं देता है - एक स्टोरेज इंजन रोसेट जिसका उपयोग स्पिलिंग को tempdb पर लागू करने के लिए किया जाता है। . अपेक्षित CQScanSortNew इसलिए एक बच्चे के साथ है CQScanRowsetNew आंतरिक वृक्ष में। यह शोप्लान आउटपुट में दिखाई नहीं देता है।
I/O प्रोफाइलिंग और आस्थगित संचालन
सॉर्ट ऑपरेटर भी पहला है जिसे हमने अब तक आरंभ किया है जो I/O . के लिए जिम्मेदार हो सकता है . यह मानते हुए कि निष्पादन ने I/O प्रोफाइलिंग डेटा का अनुरोध किया है (उदाहरण के लिए एक 'वास्तविक' योजना का अनुरोध करके) सॉर्ट इस रनटाइम प्रोफाइलिंग डेटा को रिकॉर्ड करने के लिए एक ऑब्जेक्ट बनाता है। CProfileInfo::AllocProfileIO . के माध्यम से ।
अगला ऑपरेटर एक गणना अदिश है (नोड 8), जिसे प्रोजेक्ट . कहा जाता है आंतरिक रूप से। क्वेरी स्कैन सेटअप CXteProject::QScanGet पर कॉल करें नहीं . करता है एक क्वेरी स्कैन ऑब्जेक्ट लौटाएं, क्योंकि इस गणना स्केलर द्वारा किए गए परिकलन स्थगित . हैं परिणाम की आवश्यकता वाले पहले मूल ऑपरेटर को। इस योजना में, वह ऑपरेटर प्रकार है। सॉर्ट कंप्यूट स्केलर को सौंपे गए सभी कार्य करेगा, इसलिए नोड 8 पर प्रोजेक्ट क्वेरी स्कैन ट्री का हिस्सा नहीं बनता है। गणना स्केलर वास्तव में रनटाइम पर निष्पादित नहीं होता है। आस्थगित कंप्यूट स्केलर्स के बारे में अधिक जानकारी के लिए, कंप्यूट स्केलर्स, एक्सप्रेशन और एक्ज़ीक्यूशन प्लान परफॉर्मेंस देखें।
समानांतर स्कैन
योजना की इस शाखा पर कंप्यूट स्केलर के बाद अंतिम ऑपरेटर एक इंडेक्स सीक . है (CXteRange ) नोड 9 पर। यह अपेक्षित क्वेरी स्कैन ऑपरेटर उत्पन्न करता है (CQScanRangeNew ), लेकिन इसे स्टोरेज इंजन से कनेक्ट करने और इंडेक्स के समानांतर स्कैन की सुविधा के लिए इनिशियलाइज़ेशन के एक जटिल अनुक्रम की भी आवश्यकता होती है।
केवल हाइलाइट्स को कवर करते हुए, इंडेक्स सीक को इनिशियलाइज़ करना:
- एक प्रोफाइलिंग ऑब्जेक्ट बनाता है I/O के लिए (
CProfileInfo::AllocProfileIO)। - एक समानांतर पंक्ति बनाता है क्वेरी स्कैन (
CQScanRowsetNew::ParallelGetRowset)। - एक सिंक्रनाइज़ेशन सेट करता है रनटाइम समानांतर रेंज स्कैन को समन्वित करने के लिए ऑब्जेक्ट (
CQScanRangeNew::GetSyncInfo)। - स्टोरेज इंजन बनाता है टेबल कर्सर और केवल पढ़ने के लिए लेन-देन विवरणक ।
- पेरेंट रोसेट को पढ़ने के लिए खोलता है (HoBt तक पहुंचना और आवश्यक लैच लेना)।
- लॉक टाइमआउट सेट करता है।
- प्रीफ़ेचिंग सेट करता है (संबंधित मेमोरी बफ़र्स सहित)।
पंक्ति मोड प्रोफाइलिंग ऑपरेटरों को जोड़ना
अब हम योजना की इस शाखा के पत्ते के स्तर पर पहुंच गए हैं (सूचकांक की तलाश में कोई संतान नहीं है)। अनुक्रमणिका खोज के लिए अभी-अभी क्वेरी स्कैन ऑब्जेक्ट बनाने के बाद, अगला चरण क्वेरी स्कैन को रैप करना है एक प्रोफाइलिंग वर्ग के साथ (यह मानते हुए कि हमने एक वास्तविक योजना का अनुरोध किया है)। यह sqlmin!PqsWrapQScan . पर कॉल करके किया जाता है . ध्यान दें कि क्वेरी स्कैन बनने के बाद प्रोफाइलर जोड़े जाते हैं, क्योंकि हम इटरेटर ट्री पर चढ़ना शुरू करते हैं।
PqsWrapQScan अभिभावक . के रूप में एक नया प्रोफाइलिंग ऑपरेटर बनाता है CProfileInfo::GetOrCreateProfileInfo . पर कॉल करके इंडेक्स की तलाश करें . प्रोफाइलिंग ऑपरेटर (CQScanProfileNew ) में सामान्य क्वेरी स्कैन इंटरफ़ेस विधियां हैं। वास्तविक योजनाओं के लिए आवश्यक डेटा एकत्र करने के साथ-साथ, प्रोफाइलिंग डेटा को DMV sys.dm_exec_query_profiles के माध्यम से भी उजागर किया जाता है। ।
वर्तमान सत्र के लिए इस सटीक समय पर डीएमवी की पूछताछ से पता चलता है कि केवल एक ही योजना ऑपरेटर (नोड 9) मौजूद है (जिसका अर्थ है कि यह केवल एक प्रोफाइलर द्वारा लपेटा गया है):

यह स्क्रीनशॉट वर्तमान समय में DMV से सेट किया गया पूरा परिणाम दिखाता है (इसे संपादित नहीं किया गया है)।
अगला, CQScanProfileNew क्वेरी प्रदर्शन काउंटर API को कॉल करता है (KERNEL32!QueryPerformanceCounterStub ) ऑपरेटिंग सिस्टम द्वारा पहला और अंतिम सक्रिय समय . रिकॉर्ड करने के लिए प्रदान किया गया प्रोफाइल ऑपरेटर की:

आखिरी सक्रिय समय हर बार उस इटरेटर के लिए क्वेरी प्रदर्शन काउंटर एपीआई का उपयोग करके अपडेट किया जाएगा।
प्रोफाइलर तब पंक्तियों की अनुमानित संख्या सेट करता है। इस समय योजना में (CProfileInfo::SetCardExpectedRows ), किसी भी पंक्ति लक्ष्य के लिए लेखांकन (CXte::CardGetRowGoal ) चूंकि यह एक समानांतर योजना है, यह परिणाम को थ्रेड्स की संख्या से विभाजित करती है (CXte::FGetRowGoalDefinedForOneThread ) और परिणाम को निष्पादन के संदर्भ में सहेजता है।
पंक्तियों की अनुमानित संख्या दिखाई नहीं दे रही है इस बिंदु पर DMV के माध्यम से, क्योंकि मूल कार्य इस ऑपरेटर को निष्पादित नहीं करेगा। इसके बजाय, प्रति-थ्रेड अनुमान को बाद में समानांतर निष्पादन संदर्भों (जो अभी तक नहीं बनाया गया है) में उजागर किया जाएगा। फिर भी, प्रति-थ्रेड नंबर पैरेंट टास्क के प्रोफाइलर में सहेजा जाता है — यह सिर्फ DMV के माध्यम से दिखाई नहीं देता है।
दोस्ताना नाम प्लान ऑपरेटर ("इंडेक्स सीक") को कॉल के माध्यम से CXteRange::GetPhysicalOp पर सेट किया जाता है :

इससे पहले, आपने देखा होगा कि DMV को क्वेरी करने से नाम "???" के रूप में दिखाई देता है। यह अदृश्य ऑपरेटरों (जैसे नेस्टेड लूप प्रीफेच, बैच सॉर्ट) के लिए दिखाया गया स्थायी नाम है, जिसका कोई अनुकूल नाम परिभाषित नहीं है।
अंत में, अनुक्रमणिका मेटाडेटा और वर्तमान I/O आँकड़े लपेटे गए इंडेक्स के लिए CQScanRowsetNew::GetIoCounters पर कॉल के माध्यम से तलाश को जोड़ा जाता है :

काउंटर इस समय शून्य हैं, लेकिन जैसे ही इंडेक्स सीक समाप्त योजना निष्पादन के दौरान I/O करता है, इसे अपडेट किया जाएगा।
अधिक क्वेरी स्कैन संसाधन
इंडेक्स सीक के लिए बनाए गए प्रोफाइलिंग ऑपरेटर के साथ, क्वेरी स्कैन प्रोसेसिंग ट्री को पेरेंट सॉर्ट में वापस ले जाती है (नोड 7)।
सॉर्ट निम्नलिखित आरंभीकरण कार्य करता है:
- अपने मेमोरी उपयोग को क्वेरी मेमोरी मैनेजर के साथ पंजीकृत करता है (
CQryMemManager::RegisterMemUsage) - सॉर्ट इनपुट के लिए आवश्यक मेमोरी की गणना करता है (
CQScanIndexSortNew::CbufInputMemory) और आउटपुट (CQScanSortNew::CbufOutputMemory)। - क्रमबद्ध तालिका इसके संबद्ध स्टोरेज इंजन रोसेट के साथ बनाया गया है (
sqlmin!RowsetSorted)। - एक स्टैंडअलोन सिस्टम लेनदेन (उपयोगकर्ता लेन-देन से बाध्य नहीं) एक नकली कार्य तालिका (
sqlmin!CreateFakeWorkTableके साथ, छँटाई डिस्क आवंटन के लिए बनाया गया है। )। - अभिव्यक्ति सेवा प्रारंभ की गई है (
sqlTsEs!CEsRuntime::Startup) सॉर्ट ऑपरेटर के लिए गणना करने के लिए स्थगित कंप्यूट स्केलर से। - प्रीफ़ेच किसी भी प्रकार के रन के लिए tempdb इसके बाद (
CPrefetchMgr::SetupPrefetch. के माध्यम से बनाया जाता है )।
अंत में, सॉर्ट क्वेरी स्कैन को एक प्रोफाइलिंग ऑपरेटर (I/O सहित) द्वारा लपेटा जाता है, जैसा कि हमने इंडेक्स सीक के लिए देखा था:

ध्यान दें कि कंप्यूट स्केलर (नोड 8) अनुपलब्ध . है डीएमवी से। ऐसा इसलिए है क्योंकि इसका काम सॉर्ट करने के लिए स्थगित है, क्वेरी स्कैन ट्री का हिस्सा नहीं है, और इसलिए इसमें कोई रैपिंग प्रोफाइलर ऑब्जेक्ट नहीं है।
स्ट्रीम एग्रीगेट ., सॉर्ट के पैरेंट तक ले जाते हुए क्वेरी स्कैन ऑपरेटर (नोड 6) इसके भाव और रनटाइम काउंटर (जैसे वर्तमान समूह पंक्ति गणना) को आरंभ करता है। स्ट्रीम एग्रीगेट को एक प्रोफाइलिंग ऑपरेटर के साथ लपेटा गया है, जो इसके शुरुआती समय को रिकॉर्ड कर रहा है:

पैरेंट पुनर्विभाजन विनिमय को स्ट्रीम करता है (नोड 5) एक प्रोफाइलर द्वारा लपेटा गया है (याद रखें कि इस एक्सचेंज का केवल उपभोक्ता पक्ष इस बिंदु पर मौजूद है):

ऐसा ही इसके पैरेंट स्ट्रीम एग्रीगेट . के लिए किया जाता है (नोड 4), जिसे पहले वर्णित के रूप में भी प्रारंभ किया गया है:

क्वेरी स्कैन प्रोसेसिंग पेरेंट मर्ज जॉइन . पर वापस आती है (नोड 3) लेकिन अभी तक इसे इनिशियलाइज़ नहीं किया है। इसके बजाय, हम मर्ज जॉइन के भीतरी (निचले) हिस्से को नीचे ले जाते हैं, उन ऑपरेटरों (नोड्स 10 से 15) के लिए समान विस्तृत कार्य करते हैं जैसा कि ऊपरी (बाहरी) शाखा के लिए किया जाता है:
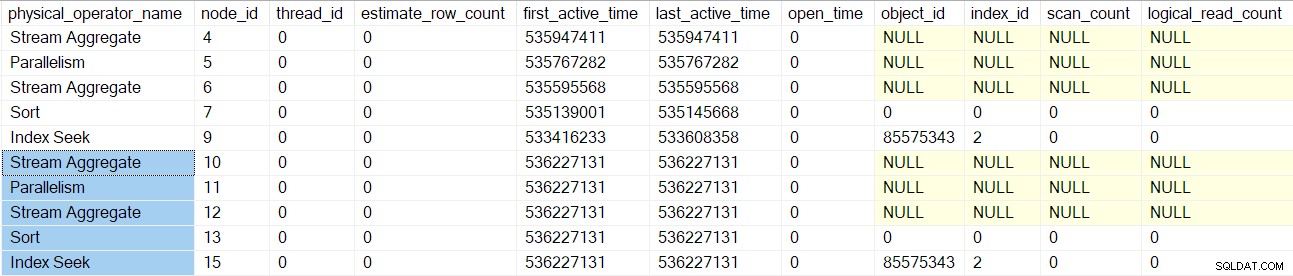
एक बार उन ऑपरेटरों के संसाधित हो जाने के बाद, मर्ज में शामिल हों क्वेरी स्कैन बनाया जाता है, आरंभ किया जाता है, और एक प्रोफाइलिंग ऑब्जेक्ट के साथ लपेटा जाता है। इसमें I/O काउंटर शामिल हैं क्योंकि कई-कई मर्ज जॉइन एक कार्य तालिका का उपयोग करते हैं (भले ही वर्तमान मर्ज जॉइन एक-अनेक है):
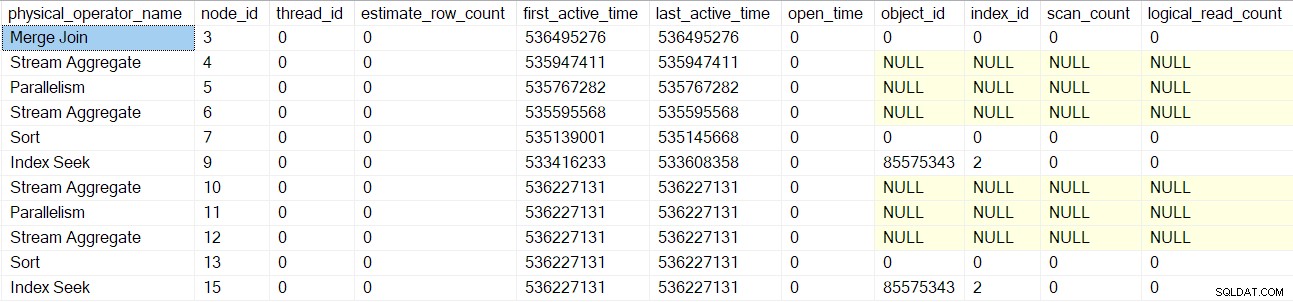
पैरेंट संग्रह स्ट्रीम एक्सचेंज . के लिए भी यही प्रक्रिया अपनाई जाती है (नोड 2) केवल उपभोक्ता पक्ष, सेगमेंट (नोड 1), और अनुक्रम प्रोजेक्ट (नोड 0) ऑपरेटर। मैं उनका विस्तार से वर्णन नहीं करूंगा।
क्वेरी प्रोफाइल DMV अब प्रोफाइलर-लिपटे क्वेरी स्कैन नोड्स के एक पूर्ण सेट की रिपोर्ट करता है:
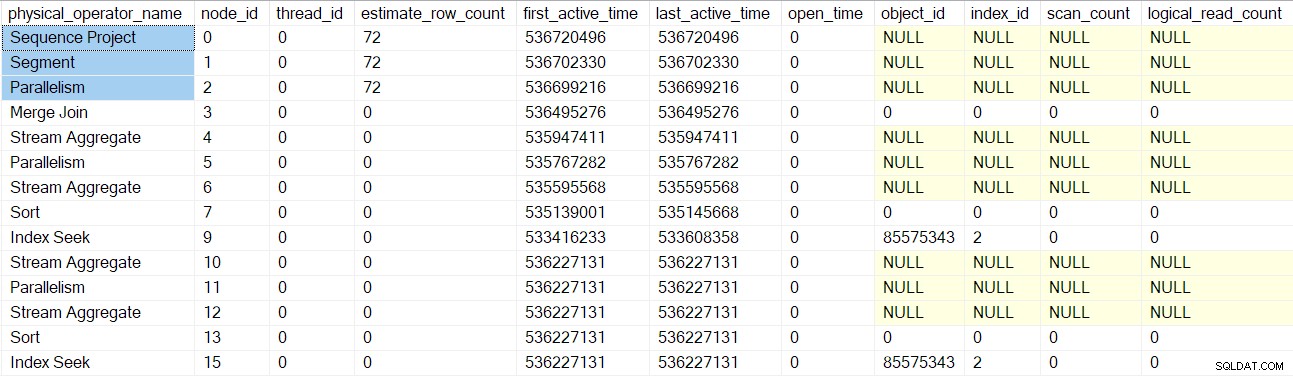
ध्यान दें कि अनुक्रम प्रोजेक्ट, सेगमेंट, और एकत्रित स्ट्रीम उपभोक्ता की अनुमानित पंक्ति गणना है क्योंकि ये ऑपरेटर पैरेंट टास्क द्वारा चलाए जाएंगे , अतिरिक्त समानांतर कार्यों द्वारा नहीं (देखें CXte::FGetRowGoalDefinedForOneThread पूर्व)। पैरेंट टास्क के पास समानांतर शाखाओं में करने के लिए कोई काम नहीं है, इसलिए अनुमानित पंक्ति गणना की अवधारणा केवल अतिरिक्त कार्यों के लिए समझ में आती है।
ऊपर दिखाए गए सक्रिय समय मान कुछ विकृत हैं क्योंकि मुझे निष्पादन को रोकने और प्रत्येक चरण में DMV स्क्रीनशॉट लेने की आवश्यकता है। एक अलग निष्पादन (डीबगर का उपयोग करके पेश किए गए कृत्रिम देरी के बिना) ने निम्नलिखित समय का उत्पादन किया:
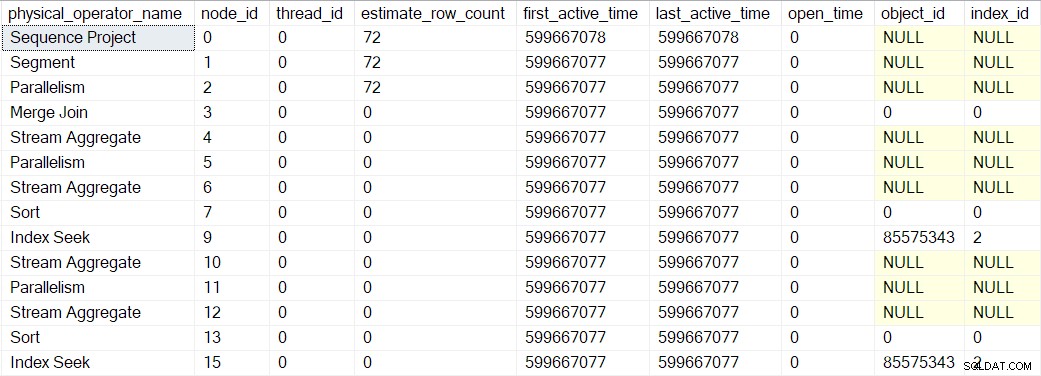
पेड़ का निर्माण उसी क्रम में किया गया है जैसा कि पहले बताया गया है, लेकिन यह प्रक्रिया इतनी तेज है कि इसमें केवल 1 माइक्रोसेकंड है। पहले लपेटे गए ऑपरेटर के सक्रिय समय (सूचकांक 9 नोड पर खोज) और अंतिम (नोड 0 पर अनुक्रम परियोजना) के बीच का अंतर।
भाग 2 का अंत
ऐसा लग सकता है कि हमने बहुत काम किया है, लेकिन याद रखें कि हमने केवल पैरेंट टास्क के लिए क्वेरी स्कैन ट्री बनाया है। , और एक्सचेंजों का केवल एक उपभोक्ता पक्ष होता है (अभी तक कोई निर्माता नहीं)। हमारी समानांतर योजना में भी केवल एक धागा है (जैसा कि अंतिम स्क्रीनशॉट में दिखाया गया है)। भाग 3 में हमारे पहले अतिरिक्त समानांतर कार्यों का निर्माण होगा।



