डैन होम्स द्वारा पोस्ट, जो sql.dnhlms.com पर ब्लॉग करते हैं।
SQL सर्वर बुक्स ऑनलाइन (बीओएल), श्वेतपत्र, और कई अन्य स्रोत आपको दिखाएंगे कि आप किसी तालिका या अनुक्रमणिका पर आंकड़े कैसे और क्यों अपडेट करना चाहते हैं। हालाँकि, आपको उन मानों को आकार देने का केवल एक ही तरीका मिलता है। मैं आपको दिखाऊंगा कि कैसे आप उपलब्ध 200 चरणों की सीमा के भीतर ठीक वैसे ही आंकड़े बना सकते हैं जैसे आप चाहते हैं।
अस्वीकरण :यह मेरे लिए काम करता है क्योंकि मैं अपने एप्लिकेशन, अपने डेटाबेस और अपने उपयोगकर्ता के नियमित वर्कफ़्लो और एप्लिकेशन उपयोग पैटर्न को जानता हूं। हालाँकि, यह अनिर्दिष्ट आदेशों का उपयोग करता है और यदि गलत तरीके से उपयोग किया जाता है, तो यह आपके एप्लिकेशन के प्रदर्शन को काफी खराब कर सकता है।हमारे आवेदन में, शेड्यूलिंग उपयोगकर्ता नियमित रूप से डेटा पढ़ और लिख रहा है जो कल और अगले कुछ दिनों की घटनाओं का प्रतिनिधित्व करता है। आज और पहले के डेटा का उपयोग शेड्यूलर द्वारा नहीं किया जाता है। सुबह सबसे पहले, कल के लिए सेट किया गया डेटा कुछ सौ पंक्तियों से शुरू होता है और दोपहर तक 1400 और अधिक हो सकता है। निम्नलिखित चार्ट पंक्ति गणनाओं का वर्णन करेगा। यह डेटा बुधवार 18 नवंबर, 2015 की सुबह एकत्र किया गया था। ऐतिहासिक रूप से, आप देख सकते हैं कि सप्ताहांत के दिनों और अगले दिन को छोड़कर नियमित पंक्तियों की संख्या लगभग 1,400 है।
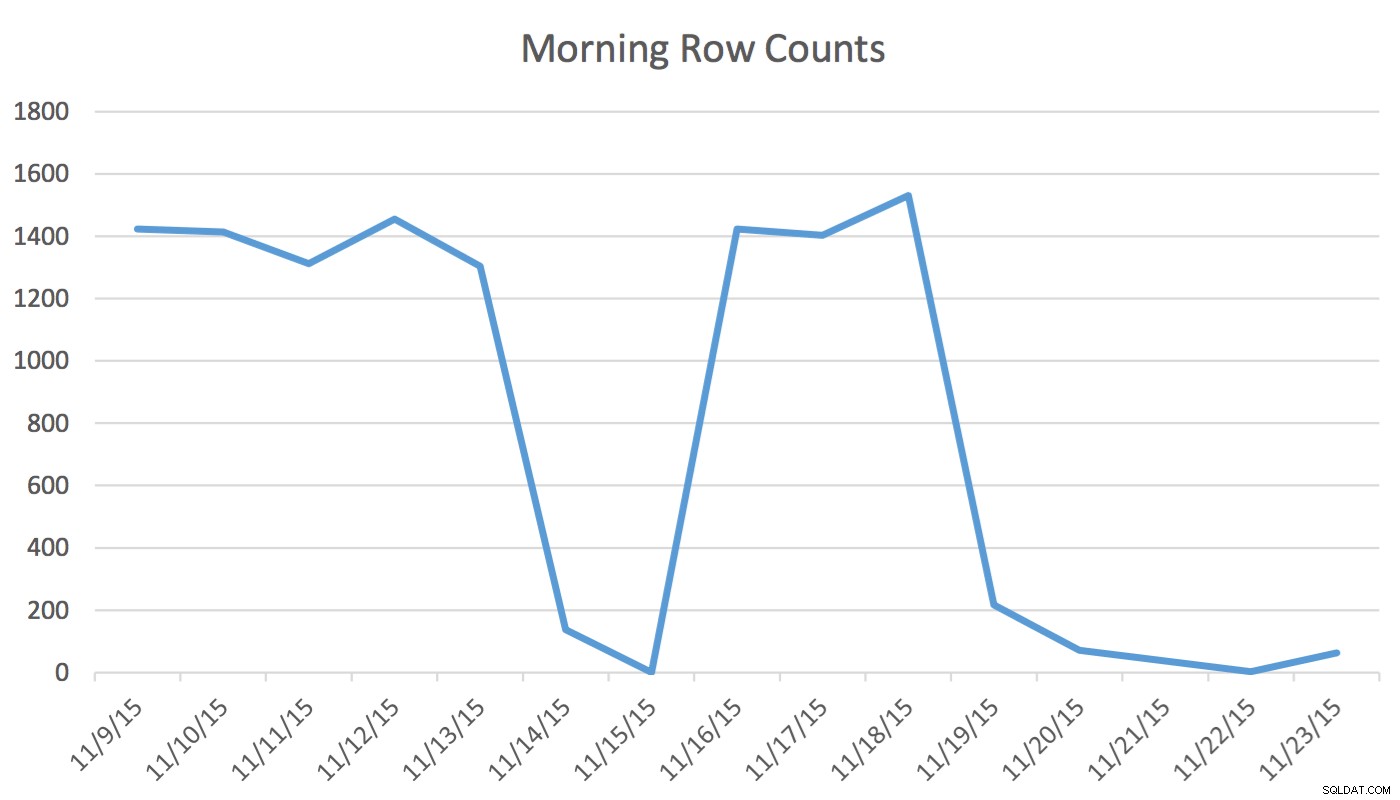
शेड्यूलर के लिए अगले कुछ दिनों में एकमात्र प्रासंगिक डेटा है। आज क्या हो रहा है और कल क्या हुआ उसकी गतिविधि के लिए प्रासंगिक नहीं है। तो यह समस्या कैसे पैदा करता है? इस तालिका में 2,259,205 पंक्तियाँ हैं, जिसका अर्थ है कि सुबह से दोपहर तक पंक्तियों की संख्या में परिवर्तन SQL सर्वर द्वारा शुरू किए गए आँकड़े अद्यतन को ट्रिगर करने के लिए पर्याप्त नहीं होगा। इसके अलावा, मैन्युअल रूप से शेड्यूल किया गया कार्य जो UPDATE STATISTICS . का उपयोग करके आंकड़े बनाता है तालिका में सभी डेटा के नमूने के साथ हिस्टोग्राम को पॉप्युलेट करता है लेकिन प्रासंगिक जानकारी शामिल नहीं कर सकता है। यह पंक्ति गणना डेल्टा योजना को बदलने के लिए पर्याप्त है। हालांकि, आंकड़ों के अद्यतन और सटीक हिस्टोग्राम के बिना, डेटा में परिवर्तन के रूप में योजना बेहतर के लिए नहीं बदलेगी।
दिनांक 11/4/2015 के बैकअप से इस तालिका के लिए हिस्टोग्राम का एक प्रासंगिक चयन इस तरह दिख सकता है:
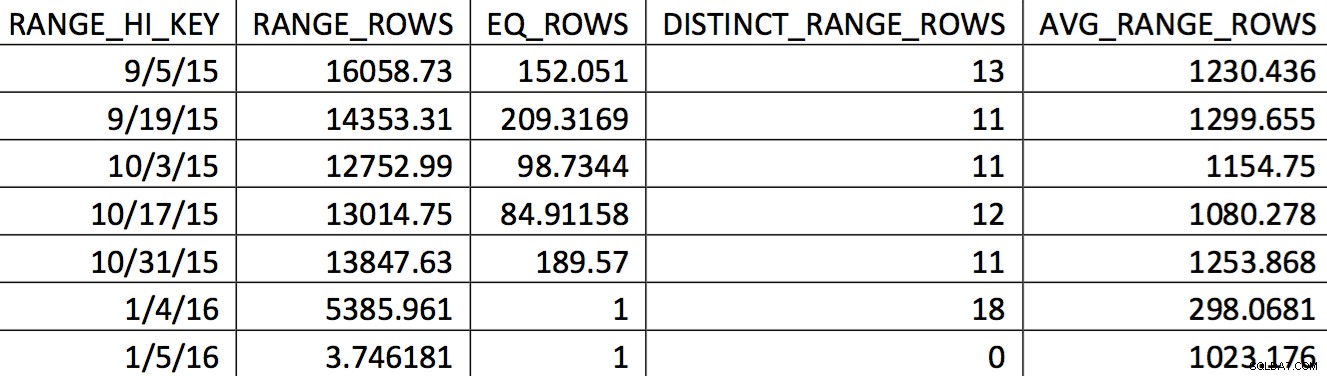
ब्याज के मूल्य हिस्टोग्राम में सटीक रूप से परिलक्षित नहीं होते हैं। 11/5/2015 की तारीख के लिए जो उपयोग किया जाएगा वह उच्च मूल्य 1/4/2016 होगा। ग्राफ़ के आधार पर, यह हिस्टोग्राम स्पष्ट रूप से रुचि की तारीख के लिए अनुकूलक के लिए जानकारी का एक अच्छा स्रोत नहीं है। हिस्टोग्राम में उपयोग के मूल्यों को लागू करना विश्वसनीय नहीं है, तो आप ऐसा कैसे कर सकते हैं? मेरा पहला प्रयास बार-बार WITH SAMPLE . का उपयोग करना था UPDATE STATISTICS . का विकल्प और हिस्टोग्राम को तब तक क्वेरी करें जब तक मुझे आवश्यक मान हिस्टोग्राम में न हों (एक प्रयास विस्तृत यहां )। अंततः, वह दृष्टिकोण अविश्वसनीय साबित हुआ।
यह हिस्टोग्राम इस प्रकार के व्यवहार के साथ एक योजना को जन्म दे सकता है। पंक्तियों का कम आंकना एक नेस्टेड लूप जॉइन और एक इंडेक्स सीक पैदा करता है। इस योजना की पसंद के कारण बाद में पढ़ने की तुलना में अधिक होना चाहिए। यह कथन की अवधि पर भी प्रभाव डालेगा।
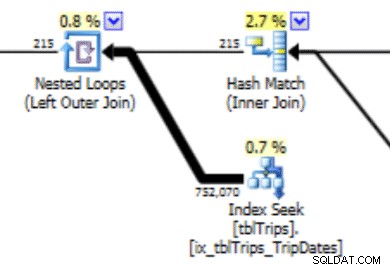
डेटा को ठीक उसी तरह से तैयार करना जो आप चाहते हैं, और यहां यह कैसे करना है, यह बेहतर काम करेगा।
UPDATE STATISTICS . का एक असमर्थित विकल्प है :STATS_STREAM . इसका उपयोग Microsoft ग्राहक सहायता द्वारा आँकड़ों को निर्यात और आयात करने के लिए किया जाता है ताकि वे तालिका में सभी डेटा के बिना एक ऑप्टिमाइज़र रीक्रिएट प्राप्त कर सकें। हम उस सुविधा का उपयोग कर सकते हैं। विचार एक तालिका बनाने का है जो उस आंकड़े के डीडीएल की नकल करता है जिसे हम अनुकूलित करना चाहते हैं। प्रासंगिक डेटा तालिका में जोड़ा जाता है। आंकड़े निर्यात और मूल तालिका में आयात किए जाते हैं।
इस मामले में, यह एक तालिका है जिसमें नल तिथियों की 200 पंक्तियाँ और 1 पंक्ति है जिसमें NULL मान शामिल हैं। इसके अतिरिक्त, उस तालिका पर एक अनुक्रमणिका है जो उस अनुक्रमणिका से मेल खाती है जिसमें खराब हिस्टोग्राम मान हैं।
तालिका का नाम है tblTripsScheduled . इसमें (id, TheTripDate) . पर एक गैर-संकुल अनुक्रमणिका है और TheTripDate . पर एक संकुल अनुक्रमणिका . कुछ अन्य स्तंभ हैं, लेकिन केवल वे ही महत्वपूर्ण हैं जो अनुक्रमणिका में शामिल हैं।
एक तालिका बनाएं (यदि आप चाहें तो अस्थायी तालिका) जो तालिका और अनुक्रमणिका की नकल करती है। टेबल और इंडेक्स इस तरह दिखता है:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate); को ट्रिपडेट के लिए क्लस्टर इंडेक्स बनाएं
इसके बाद, तालिका को डेटा की 200 पंक्तियों से भरना होगा, जिस पर आंकड़े आधारित होने चाहिए। मेरी स्थिति के लिए, यह अगले साठ दिनों का दिन है। पिछले और 60 दिनों के बाद हर 10 दिनों के "यादृच्छिक" चयन के साथ भर जाता है। (cnt CTE में मान एक डिबग मान है। यह अंतिम परिणामों में कोई भूमिका नहीं निभाता है।) rn . के लिए अवरोही क्रम कॉलम सुनिश्चित करता है कि 60 दिनों को शामिल किया गया है, और फिर जितना संभव हो उतना अतीत।
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
हमारी तालिका अब प्रत्येक पंक्ति से भरी हुई है जो आज के उपयोगकर्ता के लिए मूल्यवान है और ऐतिहासिक पंक्तियों का चयन है। यदि कॉलम TheTripdate अशक्त था, इन्सर्ट में निम्नलिखित भी शामिल होंगे:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
इसके बाद, हम अपनी अस्थायी तालिका के सूचकांक पर आंकड़े अपडेट करते हैं।
फुलस्कैन के साथUPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
अब, उन आँकड़ों को एक अस्थायी तालिका में निर्यात करें। वह तालिका इस तरह दिखती है। यह DBCC SHOW_STATISTICS WITH HISTOGRAM . के आउटपुट से मेल खाता है ।
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS एक स्ट्रीम के रूप में आँकड़ों को निर्यात करने का विकल्प है। यह वह धारा है जिसे हम चाहते हैं। वह स्ट्रीम भी वही स्ट्रीम है जो UPDATE STATISTICS स्ट्रीम विकल्प का उपयोग करता है। ऐसा करने के लिए:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); अंतिम चरण SQL बनाना है जो हमारी लक्ष्य तालिका के आंकड़ों को अद्यतन करता है, और फिर इसे निष्पादित करता है।
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); इस बिंदु पर, हमने हिस्टोग्राम को हमारे कस्टम-निर्मित के साथ बदल दिया है। आप हिस्टोग्राम की जांच करके सत्यापित कर सकते हैं:
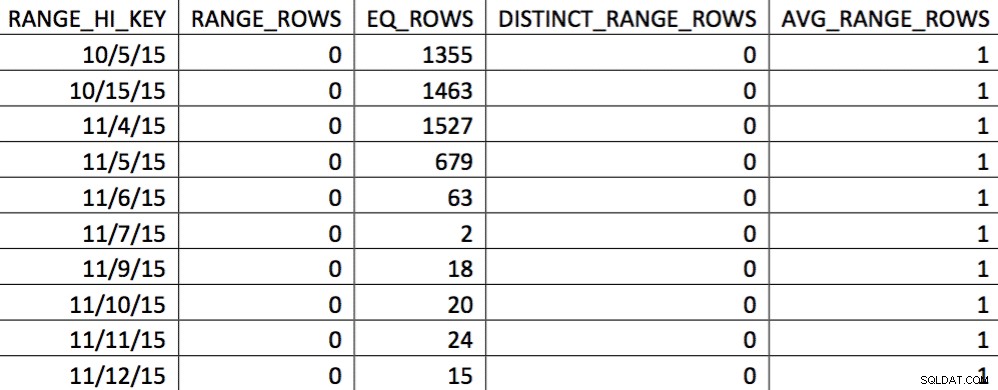
11/4 के आंकड़ों के इस चयन में, 11/4 से आगे के सभी दिनों का प्रतिनिधित्व किया जाता है, और ऐतिहासिक डेटा का प्रतिनिधित्व और सटीक होता है। पहले दिखाए गए क्वेरी प्लान के हिस्से पर दोबारा गौर करने पर, आप देख सकते हैं कि ऑप्टिमाइज़र ने सही आँकड़ों के आधार पर एक बेहतर विकल्प बनाया है:
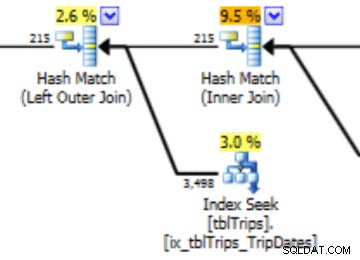
आयातित आँकड़ों के लिए एक प्रदर्शन लाभ है। आँकड़ों की गणना करने की लागत "ऑफ़लाइन" तालिका पर है। उत्पादन तालिका के लिए एकमात्र डाउनटाइम स्ट्रीम आयात की अवधि है।
यह प्रक्रिया अनिर्दिष्ट सुविधाओं का उपयोग करती है और ऐसा लगता है कि यह खतरनाक हो सकता है, लेकिन याद रखें कि एक आसान पूर्ववत है:अद्यतन सांख्यिकी विवरण। यदि कुछ गलत हो जाता है, तो मानक T-SQL का उपयोग करके आँकड़े हमेशा अद्यतन किए जा सकते हैं।
इस कोड को नियमित रूप से चलाने के लिए शेड्यूल करने से ऑप्टिमाइज़र को बेहतर योजनाएँ बनाने में मदद मिल सकती है, क्योंकि डेटा सेट टिपिंग पॉइंट पर बदलता है लेकिन आँकड़े अपडेट को ट्रिगर करने के लिए पर्याप्त नहीं है।
जब मैंने इस लेख का पहला ड्राफ्ट पूरा किया, तो पहले चार्ट में टेबल पर पंक्तियों की संख्या 217 से बदलकर 717 हो गई। यह 300% परिवर्तन है। यह अनुकूलक के व्यवहार को बदलने के लिए पर्याप्त है लेकिन आंकड़े अद्यतन को ट्रिगर करने के लिए पर्याप्त नहीं है। इस डेटा परिवर्तन ने एक खराब योजना को छोड़ दिया होगा। यहाँ वर्णित प्रक्रिया से ही यह समस्या हल हो जाती है।
संदर्भ:
- अद्यतन सांख्यिकी (पुस्तकें ऑनलाइन)
- एसक्यूएल 2008 सांख्यिकी श्वेतपत्र
- टिपिंग प्वाइंट सर्च