पिछले साल, मैंने एंटरप्राइज़ संस्करण में निवेश किए बिना उपलब्धता समूह पठनीय सेकेंडरी को अनुकरण करने के लिए एक समाधान प्रस्तुत किया था। लोगों को एंटरप्राइज़ संस्करण खरीदने से रोकने के लिए नहीं, क्योंकि एजी के बाहर बहुत सारे लाभ हैं, लेकिन उन लोगों के लिए और भी अधिक जिनके पास पहले स्थान पर एंटरप्राइज़ संस्करण होने का कोई मौका नहीं है:
- बजट पर पठनीय सेकेंडरी
मैं मानक संस्करण ग्राहक के लिए एक अथक अधिवक्ता बनने की कोशिश करता हूं; यह लगभग एक चल रहा मजाक है कि निश्चित रूप से - प्रत्येक नई रिलीज में इसे मिलने वाली सुविधाओं की संख्या को देखते हुए - वह संस्करण समग्र रूप से बहिष्करण पथ पर है। Microsoft के साथ निजी बैठकों में मैंने सुविधाओं को मानक संस्करण में शामिल करने पर जोर दिया है, विशेष रूप से ऐसी सुविधाओं के साथ जो असीमित हार्डवेयर बजट वाले व्यवसायों की तुलना में छोटे व्यवसायों के लिए अधिक फायदेमंद हैं।
एंटरप्राइज़ संस्करण ग्राहक तालिका विभाजन द्वारा प्रदान की जाने वाली प्रबंधनीयता और प्रदर्शन लाभों का आनंद लेते हैं, लेकिन यह सुविधा मानक संस्करण में उपलब्ध नहीं है। हाल ही में मुझे एक विचार आया कि किसी भी संस्करण पर कम से कम विभाजन के कुछ लाभ प्राप्त करने का एक तरीका है, और इसमें विभाजित विचार शामिल नहीं हैं। यह कहना नहीं है कि विभाजित विचार विचार करने लायक व्यवहार्य विकल्प नहीं हैं; इन्हें अन्य लोगों द्वारा अच्छी तरह से वर्णित किया गया है, जिनमें डेनियल हटमाकर (टेबल विभाजन पर विभाजित विचार) और किम्बर्ली ट्रिप (विभाजित टेबल बनाम विभाजित दृश्य-वे अभी भी आसपास क्यों हैं?) मेरे विचार को लागू करना थोड़ा आसान है।
आपका नया हीरो:फ़िल्टर किए गए इंडेक्स
अब, मुझे पता है, यह विशेषता कुछ लोगों के लिए चार अक्षरों वाला शब्द है; इससे पहले कि आप आगे बढ़ें, आपको फ़िल्टर्ड इंडेक्स के साथ खुशी से सहज होना चाहिए, या कम से कम उनकी सीमाओं से अवगत होना चाहिए। इससे पहले कि मैं आपको उन पर बेचने की कोशिश करूं, आपको कुछ उचित संतुलन देने के लिए कुछ पढ़ना:
- मैं कई कमियों के बारे में बात करता हूं कि कैसे फ़िल्टर किए गए इंडेक्स एक अधिक शक्तिशाली विशेषता हो सकते हैं, और आपके लिए वोट करने के लिए बहुत सारे कनेक्ट आइटम इंगित करते हैं;
- पॉल व्हाइट (@SQL_Kiwi) फ़िल्टर किए गए इंडेक्स के साथ ऑप्टिमाइज़र सीमाओं में ट्यूनिंग समस्याओं और फ़िल्टर किए गए इंडेक्स को जोड़ने के एक अप्रत्याशित दुष्प्रभाव के बारे में बात करता है; और,
- जेस बोरलैंड (@grrl_geek) हमें बताता है कि आप फ़िल्टर किए गए इंडेक्स के साथ क्या कर सकते हैं (और नहीं कर सकते)।
वो सब पढ़ें? और तुम अभी भी यहाँ हो? बढ़िया।
इसका टीएल; डीआर यह है कि आप अपने सभी "हॉट डेटा" को एक अलग भौतिक संरचना में रखने के लिए फ़िल्टर्ड इंडेक्स का उपयोग कर सकते हैं, और यहां तक कि अलग अंतर्निहित हार्डवेयर पर भी (आपके पास एक तेज़ एसएसडी या पीसीआई ड्राइव उपलब्ध हो सकता है, लेकिन यह ' टी पूरी मेज पकड़ो)।
एक त्वरित उदाहरण
ऐसे कई उपयोग के मामले हैं जहां डेटा के एक हिस्से को बाकी की तुलना में बहुत अधिक बार पूछताछ की जाती है - खुदरा स्टोर प्रबंधन ऑर्डर, बेकरी शेड्यूलिंग वेडिंग केक डिलीवरी, या फुटबॉल स्टेडियम में उपस्थिति और रियायत डेटा को मापने के बारे में सोचें। इन मामलों में, अधिकांश या सभी रोज़मर्रा की क्वेरी गतिविधि "वर्तमान" डेटा से संबंधित होती है।
आइए इसे सरल रखें; हम एक बहुत ही संकीर्ण आदेश तालिका के साथ एक डेटाबेस बनाएंगे:
CREATE DATABASE PoorManPartition; GO USE PoorManPartition; GO CREATE TABLE dbo.Orders ( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, ...other columns... );
अब, मान लें कि आपके पास एक महीने का डेटा रखने के लिए आपके तेज़ संग्रहण पर पर्याप्त स्थान है (मौसम के हिसाब से और भविष्य के विकास के लिए पर्याप्त हेडरूम के साथ)। हम एक नया फ़ाइल समूह जोड़ सकते हैं, और एक डेटा फ़ाइल को तेज़ ड्राइव पर रख सकते हैं।
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData; GO ALTER DATABASE PoorManPartition ADD FILE ( Name = N'HotData', FileName = N'Z:\folder\HotData.mdf', Size = 100MB, FileGrowth = 25MB ) TO FILEGROUP HotData;
अब, हमारे HotData फ़ाइलग्रुप पर एक फ़िल्टर्ड इंडेक्स बनाते हैं, जहां फ़िल्टर में नवंबर 2015 की शुरुआत से सब कुछ शामिल है, और समय-आधारित प्रश्नों में शामिल सामान्य कॉलम कुंजी या सूची में शामिल हैं:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151101'
AND OrderDate < '20151201'
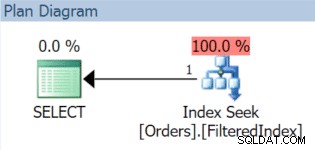
ON HotData; हम कुछ पंक्तियाँ सम्मिलित कर सकते हैं और यह सुनिश्चित करने के लिए निष्पादन योजना की जाँच कर सकते हैं कि कवर किए गए प्रश्न वास्तव में, सूचकांक का उपयोग कर सकते हैं:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 3
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106'; परिणामी निष्पादन योजना, निश्चित रूप से पर्याप्त, फ़िल्टर किए गए अनुक्रमणिका का उपयोग करती है (भले ही क्वेरी में फ़िल्टर विधेय अनुक्रमणिका परिभाषा से बिल्कुल मेल नहीं खाता):
अब, 1 दिसंबर शुरू हो गया है, और यह हमारे नवंबर के डेटा को स्वैप करने और इसे दिसंबर से बदलने का समय है। हम फ़िल्टर किए गए अनुक्रमणिका को नए फ़िल्टर विधेय के साथ फिर से बना सकते हैं, और DROP_EXISTING का उपयोग कर सकते हैं विकल्प:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151201'
AND OrderDate < '20160101'
WITH (DROP_EXISTING = ON)
ON HotData; अब, हम कुछ और पंक्तियाँ जोड़ सकते हैं, विभाजन के आँकड़ों की जाँच कर सकते हैं, और हमारी पिछली क्वेरी चला सकते हैं और उपयोग की गई अनुक्रमणिका की जाँच करने के लिए एक नई क्वेरी चला सकते हैं:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 5
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106';
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151202'
AND OrderDate < '20151204'; इस मामले में हमें नवंबर क्वेरी के साथ एक क्लस्टर इंडेक्स स्कैन मिलता है:
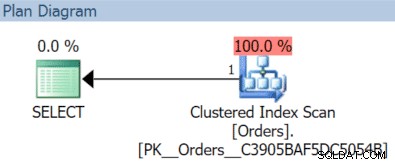
(लेकिन यह अलग होगा अगर हमारे पास ऑर्डरडेट के साथ एक अलग, गैर-फ़िल्टर्ड इंडेक्स कुंजी के रूप में था।)
और मैं इसे फिर से नहीं दिखाऊंगा, लेकिन दिसंबर क्वेरी के साथ, हमें पहले की तरह ही फ़िल्टर्ड इंडेक्स सीक मिलता है।
आप कई इंडेक्स भी बनाए रख सकते हैं, एक चालू महीने के लिए, एक पिछले महीने के लिए, और इसी तरह, और आप उन्हें अलग से प्रबंधित कर सकते हैं (1 दिसंबर को आप अक्टूबर से इंडेक्स को छोड़ दें, और नवंबर को अकेला छोड़ दें, उदाहरण के लिए) . आप कम या अधिक समय अवधि (वर्तमान और पिछले सप्ताह, वर्तमान और पिछली तिमाही) आदि के कई सूचकांक भी बनाए रख सकते हैं। समाधान बहुत लचीला है।
फ़िल्टर्ड इंडेक्स की सीमाओं के कारण, मैं इसे एक आदर्श समाधान के रूप में आगे बढ़ाने की कोशिश नहीं करूंगा, न ही तालिका विभाजन या विभाजित दृश्यों के लिए पूर्ण प्रतिस्थापन। DROP_EXISTING के साथ एक इंडेक्स को फिर से बनाते समय, उदाहरण के लिए, एक विभाजन को स्विच करना एक मेटाडेटा ऑपरेशन है। बहुत अधिक लॉगिंग हो सकती है (और चूंकि आप एंटरप्राइज़ संस्करण पर नहीं हैं, इसलिए इसे ऑनलाइन नहीं चलाया जा सकता)। आप यह भी पा सकते हैं कि विभाजित दृश्य आपकी गति अधिक हैं - अलग-अलग भौतिक तालिकाओं को बनाए रखने और विभाजित दृश्य को संभव बनाने वाली बाधाओं के आसपास अधिक काम है, लेकिन कुछ मामलों में क्वेरी प्रदर्शन के मामले में भुगतान बेहतर हो सकता है।
स्वचालन
इंडेक्स को फिर से बनाने का कार्य एक साधारण काम का उपयोग करके काफी आसानी से स्वचालित किया जा सकता है जो महीने में एक बार ऐसा कुछ करता है (या आपकी "हॉट" विंडो का आकार जो भी हो):
DECLARE @sql NVARCHAR(MAX), @dt DATE = DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql = N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate >= ''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING = ON) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
आप कई महीने पहले ही कई इंडेक्स बना सकते हैं, जैसे कि भविष्य के विभाजन पहले से बनाना - आखिरकार, भविष्य के इंडेक्स तब तक किसी भी स्थान पर कब्जा नहीं करेंगे जब तक कि उनके विधेय के लिए प्रासंगिक डेटा न हो। और आप केवल उन इंडेक्स को छोड़ सकते हैं जो पुराने डेटा को विभाजित कर रहे थे जिन्हें अब आप ठंडा बनाना चाहते हैं।
पश्च दृष्टि
इस लेख को समाप्त करने के बाद, निश्चित रूप से, मुझे किम्बर्ली ट्रिप की एक और पोस्ट मिली, जिसे मैं यहां वकालत कर रहा हूं (और जिसे मैंने शुरू करने से पहले पढ़ा था) के साथ आगे बढ़ने से पहले आपको पढ़ना चाहिए:
- विभाजन के बजाय फ़िल्टर किए गए अनुक्रमणिका के बारे में क्या?
कई कारणों से, किम्बर्ली मानक संस्करण में विभाजन के समान कुछ लागू करने के लिए विभाजित विचारों के पक्ष में है; हालांकि, कुछ परिदृश्यों के लिए, फ़िल्टर्ड इंडेक्स का उपयोग अभी भी मुझे अपने प्रयोग को जारी रखने के लिए पर्याप्त है। उन क्षेत्रों में से एक जहां फ़िल्टर किए गए इंडेक्स फायदेमंद हो सकते हैं, जब आपके "हॉट" डेटा में कई मानदंड होते हैं - न केवल तिथि के आधार पर, बल्कि अन्य विशेषताओं द्वारा भी (हो सकता है कि आप इस महीने के सभी आदेशों के खिलाफ त्वरित क्वेरी चाहते हैं जो एक विशिष्ट स्तर के लिए हैं। ग्राहक या एक निश्चित डॉलर राशि से अधिक)।
अगला...
भविष्य की पोस्ट में, मैं इस अवधारणा के साथ एक उच्च-अंत प्रणाली पर खेलूँगा, कुछ वास्तविक दुनिया की मात्रा और कार्यभार के साथ। मैं इस समाधान, एक गैर-फ़िल्टर्ड कवरिंग इंडेक्स, एक विभाजित दृश्य और एक विभाजित तालिका के बीच प्रदर्शन अंतर खोजना चाहता हूं। लैपटॉप पर वीएम के अंदर केवल एसएसडी उपलब्ध होने से शायद बड़े पैमाने पर यथार्थवादी या निष्पक्ष परीक्षण नहीं होंगे।