प्रत्येक उत्पाद में बग होते हैं, और SQL सर्वर कोई अपवाद नहीं है। उत्पाद सुविधाओं का थोड़ा असामान्य तरीके से उपयोग करना (या अपेक्षाकृत नई सुविधाओं को एक साथ जोड़ना) उन्हें खोजने का एक शानदार तरीका है। कीड़े दिलचस्प हो सकते हैं, और शैक्षिक भी, लेकिन शायद कुछ खुशियाँ तब खो जाती हैं जब खोज के परिणामस्वरूप आपका पेजर सुबह 4 बजे बंद हो जाता है, शायद दोस्तों के साथ विशेष रूप से सामाजिक रात के बाद…
बग जो इस पोस्ट का विषय है, शायद जंगली में काफी दुर्लभ है, लेकिन यह क्लासिक एज केस नहीं है। मैं कम से कम एक सलाहकार के बारे में जानता हूं जिसने इसे उत्पादन प्रणाली में सामना किया है। पूरी तरह से असंबंधित विषय पर, मुझे इस अवसर पर ग्रम्पी ओल्ड डीबीए (ब्लॉग) को "नमस्ते" कहने का अवसर लेना चाहिए।
मैं मर्ज जॉइन पर कुछ प्रासंगिक पृष्ठभूमि के साथ शुरुआत करूंगा। यदि आप निश्चित हैं कि आप पहले से ही सब कुछ जानते हैं जो मर्ज जॉइन के बारे में जानना है, या बस पीछा करना चाहते हैं, तो बेझिझक नीचे "द बग" शीर्षक वाले अनुभाग तक स्क्रॉल करें।
मर्ज करें
मर्ज जॉइन बहुत जटिल बात नहीं है, और सही परिस्थितियों में बहुत कुशल हो सकती है। इसके लिए आवश्यक है कि इसके इनपुट को जॉइन कीज़ पर सॉर्ट किया जाए, और वन-टू-मैनी मोड में सबसे अच्छा प्रदर्शन किया जाए (जहाँ कम से कम इसके इनपुट जॉइन कीज़ पर अद्वितीय हों)। मध्यम आकार के एक-से-अनेक जॉइन के लिए, सीरियल मर्ज जॉइन बिल्कुल भी बुरा विकल्प नहीं है, बशर्ते इनपुट सॉर्टिंग आवश्यकताओं को स्पष्ट सॉर्ट किए बिना पूरा किया जा सके।
किसी अनुक्रमणिका द्वारा प्रदान किए गए क्रम का शोषण करके किसी प्रकार से बचना सबसे अधिक प्राप्त होता है। मर्ज जॉइन पहले के, अपरिहार्य सॉर्ट से संरक्षित सॉर्ट ऑर्डर का भी लाभ उठा सकता है। मर्ज जॉइन के बारे में एक अच्छी बात यह है कि जैसे ही इनपुट पंक्तियों से बाहर हो जाता है, यह इनपुट पंक्तियों को संसाधित करना बंद कर सकता है। एक आखिरी बात:मर्ज जॉइन परवाह नहीं है कि इनपुट सॉर्ट ऑर्डर आरोही या अवरोही है (हालांकि दोनों इनपुट समान होना चाहिए)। निम्न उदाहरण ऊपर दिए गए अधिकांश बिंदुओं को स्पष्ट करने के लिए एक मानक संख्या तालिका का उपयोग करता है:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
ध्यान दें कि उन दो तालिकाओं पर प्राथमिक कुंजियों को लागू करने वाले अनुक्रमित को अवरोही के रूप में परिभाषित किया गया है। INSERT . के लिए क्वेरी योजना इसमें कई दिलचस्प विशेषताएं हैं:
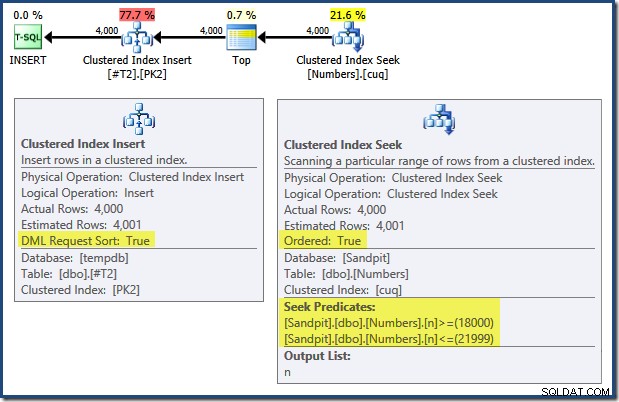
बाएं से दाएं पढ़ना (जैसा कि केवल समझदार है!) क्लस्टर्ड इंडेक्स इंसर्ट में "डीएमएल रिक्वेस्ट सॉर्ट" प्रॉपर्टी सेट है। इसका मतलब है कि ऑपरेटर को क्लस्टर्ड इंडेक्स कुंजी क्रम में पंक्तियों की आवश्यकता होती है। संकुल सूचकांक (इस मामले में प्राथमिक कुंजी को लागू करना) को DESC . के रूप में परिभाषित किया गया है , इसलिए उच्च मान वाली पंक्तियों को पहले आना आवश्यक है। मेरी Numbers तालिका पर संकुल अनुक्रमणिका ASC है , इसलिए क्वेरी ऑप्टिमाइज़र पहले नंबर तालिका (21,999) में उच्चतम मिलान की तलाश करके एक स्पष्ट सॉर्ट से बचता है, फिर रिवर्स इंडेक्स ऑर्डर में सबसे कम मैच (18,000) की ओर स्कैन करता है। SQL संतरी योजना एक्सप्लोरर में "प्लान ट्री" दृश्य रिवर्स (पिछड़े) स्कैन को स्पष्ट रूप से दिखाता है:
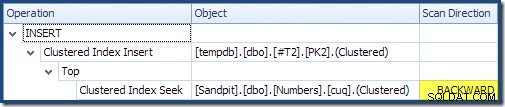
बैकवर्ड स्कैनिंग इंडेक्स के प्राकृतिक क्रम को उलट देती है। ASC . का बैकवर्ड स्कैन अनुक्रमणिका कुंजी अवरोही कुंजी क्रम में पंक्तियों को लौटाती है; DESC . का बैकवर्ड स्कैन अनुक्रमणिका कुंजी आरोही कुंजी क्रम में पंक्तियों को लौटाती है। "स्कैन दिशा" अपने आप लौटाए गए कुंजी क्रम को इंगित नहीं करता है - आपको यह जानना होगा कि क्या सूचकांक ASC है या DESC यह दृढ़ संकल्प करने के लिए।
इन परीक्षण तालिकाओं और डेटा का उपयोग करना (T1 10,000 पंक्तियों की संख्या 10,000 से 19,999 तक है; T2 4,000 पंक्तियाँ 18,000 से 21,999 तक हैं) निम्न क्वेरी दो तालिकाओं को एक साथ जोड़ती है और दोनों कुंजियों के अवरोही क्रम में परिणाम लौटाती है:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; क्वेरी सही मिलान 2,000 पंक्तियों को लौटाती है जैसा आप उम्मीद करेंगे। निष्पादन के बाद की योजना इस प्रकार है:
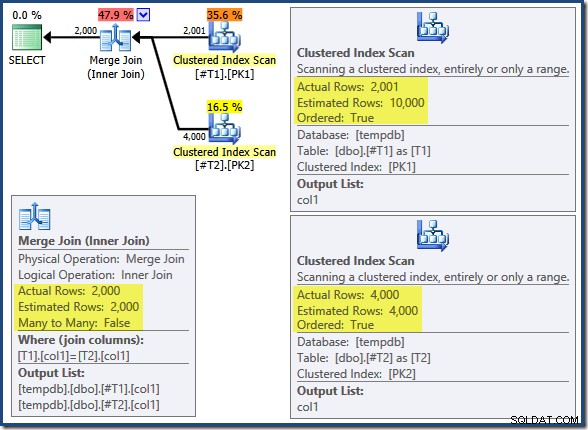
मर्ज जॉइन कई-से-अनेक मोड में नहीं चल रहा है (शीर्ष इनपुट जॉइन कीज़ पर अद्वितीय है) और 2,000 पंक्ति कार्डिनैलिटी अनुमान बिल्कुल सही है। तालिका का क्लस्टर्ड इंडेक्स स्कैन T2 आदेश दिया गया है (हालांकि हमें यह पता लगाने के लिए एक पल इंतजार करना होगा कि वह आदेश आगे है या पीछे) और 4,000 पंक्तियों का कार्डिनैलिटी अनुमान भी बिल्कुल सही है। तालिका का क्लस्टर्ड इंडेक्स स्कैन T1 भी आदेश दिया गया है, लेकिन केवल 2,001 पंक्तियों को पढ़ा गया जबकि 10,000 का अनुमान लगाया गया था। प्लान ट्री व्यू से पता चलता है कि क्लस्टर्ड इंडेक्स स्कैन दोनों को आगे ऑर्डर किया गया है:
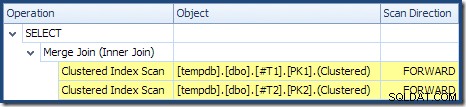
याद रखें कि DESC reading पढ़ना इंडेक्स FORWARD रिवर्स कुंजी क्रम में पंक्तियों का उत्पादन करेगा। ORDER BY T1.col DESC, T2.col1 DESC द्वारा ठीक यही आवश्यक है खंड, इसलिए कोई स्पष्ट प्रकार आवश्यक नहीं है। एक-से-कई मर्ज जॉइन के लिए छद्म कोड (क्रेग फ्रीडमैन के मर्ज ज्वाइन ब्लॉग से पुन:प्रस्तुत) है:

T1 . का अवरोही क्रम स्कैन 19,999 से शुरू होने वाली पंक्तियों को लौटाता है और 10,000 की ओर काम करता है। T2 . का अवरोही क्रम स्कैन 21,999 से शुरू होने वाली पंक्तियों को लौटाता है और 18,000 की ओर काम करता है। T2 . में सभी 4,000 पंक्तियां अंततः पढ़ा जाता है, लेकिन जब कुंजी मान 17,999 T1 से पढ़ा जाता है, तो पुनरावृत्ति मर्ज प्रक्रिया रुक जाती है , क्योंकि T2 पंक्तियों से बाहर चला जाता है। इसलिए मर्ज प्रोसेसिंग T1 . को पूरी तरह पढ़े बिना ही पूरी हो जाती है . यह पंक्तियों को 19,999 से नीचे 17,999 तक पढ़ता है; कुल 2,001 पंक्तियाँ जैसा कि ऊपर निष्पादन योजना में दिखाया गया है।
ASC . के साथ बेझिझक परीक्षण फिर से चलाएँ इसके बजाय अनुक्रमणिका, ORDER BY को भी बदल रहा है DESC . से क्लॉज करने के लिए ASC . उत्पादित निष्पादन योजना बहुत समान होगी, और किसी प्रकार की आवश्यकता नहीं होगी।
उन बिंदुओं को संक्षेप में प्रस्तुत करने के लिए जो एक पल में महत्वपूर्ण होंगे, मर्ज जॉइन के लिए जॉइन-की सॉर्ट किए गए इनपुट की आवश्यकता होती है, लेकिन इससे कोई फर्क नहीं पड़ता कि कुंजियों को आरोही या अवरोही क्रम में रखा गया है।
बग
बग को पुन:उत्पन्न करने के लिए, हमारी कम से कम एक तालिका को विभाजित करने की आवश्यकता है। परिणामों को प्रबंधनीय बनाए रखने के लिए, यह उदाहरण केवल कुछ पंक्तियों का उपयोग करेगा, इसलिए विभाजन फ़ंक्शन को भी छोटी सीमाओं की आवश्यकता होती है:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
पहली तालिका में दो स्तंभ हैं, और प्राथमिक कुंजी पर विभाजित है:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
दूसरी तालिका विभाजित नहीं है। इसमें एक प्राथमिक कुंजी और एक कॉलम होता है जो पहली तालिका में शामिल होगा:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); नमूना डेटा
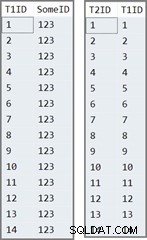
पहली तालिका में 14 पंक्तियाँ हैं, सभी का मान SomeID . में समान है कॉलम। SQL सर्वर IDENTITY असाइन करता है स्तंभ मान, क्रमांकित 1 से 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
दूसरी तालिका केवल IDENTITY से भर जाती है तालिका एक से मान:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
दो तालिकाओं में डेटा इस तरह दिखता है:
परीक्षा क्वेरी
पहली क्वेरी बस दोनों तालिकाओं में शामिल हो जाती है, एक WHERE क्लॉज विधेय को लागू करते हुए (जो इस बहुत सरल उदाहरण में सभी पंक्तियों से मेल खाने के लिए होता है):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; परिणाम में अपेक्षित सभी 14 पंक्तियाँ हैं:

पंक्तियों की छोटी संख्या के कारण, ऑप्टिमाइज़र इस क्वेरी के लिए एक नेस्टेड लूप जॉइन प्लान चुनता है:
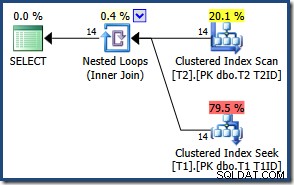
यदि हम किसी हैश या मर्ज में शामिल होने के लिए बाध्य करते हैं तो परिणाम समान (और अभी भी सही) होते हैं:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
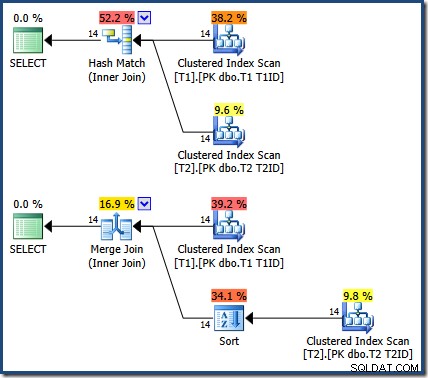
मर्ज जॉइन T1ID . पर एक स्पष्ट प्रकार के साथ एक से कई हैं, तालिका के लिए आवश्यक T2 ।
अवरोही सूचकांक समस्या
एक दिन तक सब ठीक है (अच्छे कारणों से जिनकी हमें यहां चिंता करने की आवश्यकता नहीं है) दूसरा व्यवस्थापक SomeID पर एक अवरोही अनुक्रमणिका जोड़ता है तालिका 1 का कॉलम:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
जब ऑप्टिमाइज़र नेस्टेड लूप्स या हैश जॉइन को चुनता है तो हमारी क्वेरी सही परिणाम देती रहती है, लेकिन जब मर्ज जॉइन का उपयोग किया जाता है तो यह एक अलग कहानी होती है। निम्नलिखित अभी भी मर्ज जॉइन को बाध्य करने के लिए एक क्वेरी संकेत का उपयोग करता है, लेकिन यह उदाहरण में कम पंक्ति गणना का परिणाम है। अनुकूलक स्वाभाविक रूप से अलग-अलग तालिका डेटा के साथ एक ही मर्ज जॉइन योजना का चयन करेगा।
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); निष्पादन योजना है:
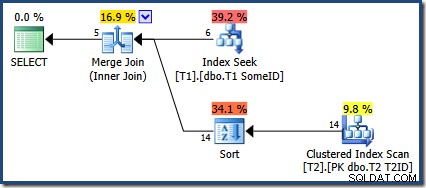
अनुकूलक ने नई अनुक्रमणिका का उपयोग करना चुना है, लेकिन क्वेरी अब आउटपुट की केवल पांच पंक्तियां उत्पन्न करती है:

अन्य 9 पंक्तियों का क्या हुआ? स्पष्ट होने के लिए, यह परिणाम गलत है। डेटा नहीं बदला है, इसलिए सभी 14 पंक्तियों को वापस कर दिया जाना चाहिए (क्योंकि वे अभी भी नेस्टेड लूप्स या हैश जॉइन योजना के साथ हैं)।
कारण और स्पष्टीकरण
SomeID . पर नई गैर-संकुल अनुक्रमणिका अद्वितीय के रूप में घोषित नहीं किया गया है, इसलिए संकुल सूचकांक कुंजी चुपचाप सभी गैर-संकुल सूचकांक स्तरों में जोड़ दी जाती है। SQL सर्वर T1ID जोड़ता है कॉलम (क्लस्टर की) को गैर-क्लस्टर इंडेक्स में ठीक वैसे ही जैसे हमने इंडेक्स को इस तरह बनाया था:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
एक DESC की कमी पर ध्यान दें चुपचाप जोड़े गए T1ID . पर क्वालीफायर चाबी। अनुक्रमणिका कुंजियाँ हैं ASC डिफ़ॉल्ट रूप से। यह अपने आप में कोई समस्या नहीं है (हालांकि यह योगदान देता है)। दूसरी चीज जो हमारे इंडेक्स के साथ अपने आप होती है वह यह है कि इसे उसी तरह से विभाजित किया जाता है जैसे बेस टेबल है। तो, पूर्ण अनुक्रमणिका विनिर्देश, यदि हम इसे स्पष्ट रूप से लिखें, तो यह होगा:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
यह अब काफी जटिल संरचना है, जिसमें सभी प्रकार के विभिन्न क्रमों में चाबियां हैं। इंडेक्स द्वारा प्रदान किए गए सॉर्ट ऑर्डर के बारे में तर्क करते समय क्वेरी ऑप्टिमाइज़र के लिए यह गलत होना काफी जटिल है। उदाहरण के लिए, निम्नलिखित सरल प्रश्न पर विचार करें:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
अतिरिक्त कॉलम हमें दिखाएगा कि वर्तमान पंक्ति किस विभाजन से संबंधित है। अन्यथा, यह केवल एक साधारण क्वेरी है जो T1ID लौटाती है आरोही क्रम में मान, WHERE SomeID = 123 . दुर्भाग्य से, परिणाम वे नहीं हैं जो क्वेरी द्वारा निर्दिष्ट किए गए हैं:
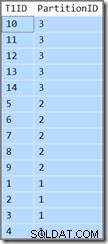
क्वेरी के लिए आवश्यक है कि T1ID मूल्यों को आरोही क्रम में वापस किया जाना चाहिए, लेकिन वह नहीं है जो हमें मिलता है। हमें प्रति विभाजन . आरोही क्रम में मान मिलते हैं , लेकिन विभाजन स्वयं उल्टे क्रम में वापस आ जाते हैं! यदि विभाजन आरोही क्रम में लौटाए गए थे (और T1ID दिखाए गए अनुसार प्रत्येक विभाजन के भीतर मूल्यों को क्रमबद्ध किया गया) परिणाम सही होगा।
क्वेरी योजना से पता चलता है कि अनुकूलक अग्रणी DESC . द्वारा भ्रमित था सूचकांक की कुंजी, और सोचा कि सही परिणामों के लिए विभाजनों को उल्टे क्रम में पढ़ने की जरूरत है:
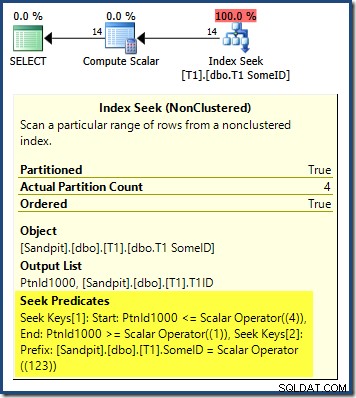
पार्टीशन सीक सबसे दाईं ओर वाले पार्टिशन (4) से शुरू होता है और पीछे की ओर पार्टिशन 1 तक जाता है। आप सोच सकते हैं कि हम पार्टिशन नंबर ASC पर स्पष्ट रूप से सॉर्ट करके समस्या को ठीक कर सकते हैं। ORDER BY . में खंड:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; यह क्वेरी समान परिणाम लौटाती है (यह गलत प्रिंट या कॉपी/पेस्ट त्रुटि नहीं है):
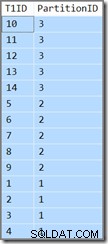
विभाजन आईडी अभी भी अवरोही में है क्रम (आरोही नहीं, जैसा कि निर्दिष्ट है) और T1ID केवल प्रत्येक विभाजन के भीतर आरोही क्रमबद्ध किया जाता है। यह ऑप्टिमाइज़र का भ्रम है, यह वास्तव में सोचता है (अब एक गहरी सांस लें) कि विभाजित अग्रणी-अवरोही-कुंजी अनुक्रमणिका को आगे की दिशा में स्कैन करना, लेकिन विभाजन उलट के साथ, परिणाम क्वेरी द्वारा निर्दिष्ट क्रम में होगा।
मैं इसे स्पष्टवादी होने के लिए दोष नहीं देता, विभिन्न प्रकार के क्रम के विचार मेरे सिर को भी चोट पहुँचाते हैं।
अंतिम उदाहरण के रूप में, इस पर विचार करें:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; परिणाम हैं:

फिर से, T1ID क्रमबद्ध क्रम प्रत्येक विभाजन के भीतर सही ढंग से अवरोही है, लेकिन विभाजन स्वयं पिछड़े सूचीबद्ध हैं (वे 1 से 3 पंक्तियों में नीचे जाते हैं)। यदि विभाजन उल्टे क्रम में लौटाए गए थे, तो परिणाम सही होंगे 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 ।
मर्ज जॉइन पर वापस जाएं
मर्ज जॉइन क्वेरी के साथ गलत परिणामों का कारण अब स्पष्ट है:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
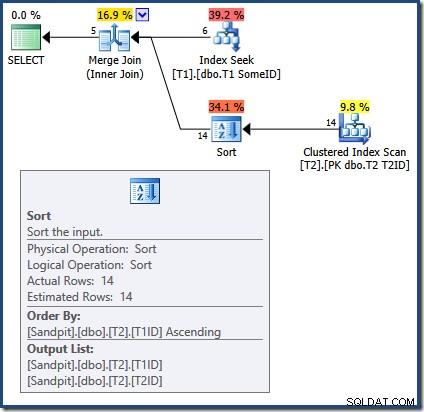
मर्ज जॉइन के लिए सॉर्ट किए गए इनपुट की आवश्यकता होती है। T2 . से इनपुट स्पष्ट रूप से T1TD . द्वारा क्रमबद्ध किया गया है तो यह ठीक है। अनुकूलक गलत कारण बताता है कि T1 . पर अनुक्रमणिका T1ID . में पंक्तियां प्रदान कर सकते हैं गण। जैसा कि हमने देखा है, ऐसा नहीं है। इंडेक्स सीक उसी आउटपुट को उत्पन्न करता है जो हमने पहले ही देखा है:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

केवल पहली 5 पंक्तियाँ T1ID में हैं गण। अगला मान (5) निश्चित रूप से आरोही क्रम में नहीं है, और मर्ज जॉइन एक त्रुटि उत्पन्न करने के बजाय इसे एंड-ऑफ-स्ट्रीम के रूप में व्याख्या करता है (व्यक्तिगत रूप से मुझे यहां खुदरा दावा की उम्मीद है)। वैसे भी, प्रभाव यह है कि मर्ज जॉइन गलत तरीके से प्रसंस्करण को जल्दी पूरा करता है। एक अनुस्मारक के रूप में, (अपूर्ण) परिणाम हैं:

निष्कर्ष
मेरे विचार से यह एक बहुत ही गंभीर बग है। एक साधारण अनुक्रमणिका खोज ऐसे परिणाम लौटा सकती है जो ORDER BY . का सम्मान नहीं करते हैं खंड। यहां तक कि, अनुकूलक का आंतरिक तर्क पूरी तरह से टूट चुका है अवरोही अग्रणी कुंजी के साथ विभाजित गैर-अद्वितीय गैर-संकुल अनुक्रमणिका के लिए।
हाँ, यह एक थोड़ा सा है असामान्य व्यवस्था। लेकिन, जैसा कि हमने देखा है, सही परिणामों को अचानक गलत परिणामों से बदल दिया जा सकता है क्योंकि किसी ने अवरोही सूचकांक जोड़ा है। याद रखें कि जोड़ा गया सूचकांक काफी निर्दोष लग रहा था:कोई स्पष्ट ASC/DESC . नहीं मुख्य बेमेल, और कोई स्पष्ट विभाजन नहीं।
बग मर्ज जॉइन तक सीमित नहीं है। संभावित रूप से कोई भी क्वेरी जिसमें विभाजित तालिका शामिल है और जो इंडेक्स सॉर्ट ऑर्डर (स्पष्ट या निहित) पर निर्भर करती है, शिकार हो सकती है। यह बग 2008 से 2014 CTP 1 सहित SQL सर्वर के सभी संस्करणों में मौजूद है। Windows SQL Azure डेटाबेस विभाजन का समर्थन नहीं करता है, इसलिए समस्या उत्पन्न नहीं होती है। SQL सर्वर 2005 ने विभाजन के लिए एक अलग कार्यान्वयन मॉडल का उपयोग किया (APPLY के आधार पर) ) और इस समस्या से ग्रस्त नहीं है।
यदि आपके पास कुछ समय है, तो कृपया इस बग के लिए मेरे कनेक्ट आइटम पर वोट करने पर विचार करें।
संकल्प
इस समस्या का समाधान अब उपलब्ध है और नॉलेज बेस आलेख में प्रलेखित है। कृपया ध्यान दें कि फिक्स के लिए कोड अपडेट की आवश्यकता है और ट्रेस फ्लैग 4199 , जो अन्य क्वेरी प्रोसेसर परिवर्तनों की एक श्रृंखला को सक्षम बनाता है। 4199 के तहत गलत-नतीजे वाले बग को ठीक किया जाना असामान्य है। मैंने उस पर स्पष्टीकरण मांगा और प्रतिक्रिया थी:
<ब्लॉककोट>हालांकि इस समस्या में क्वेरी प्रोसेसर से जुड़े अन्य हॉटफिक्स जैसे गलत परिणाम शामिल हैं, हमने केवल SQL Server 2008, 2008 R2, और 2012 के लिए ट्रेस फ्लैग 4199 के तहत इस फिक्स को सक्षम किया है। हालाँकि, यह फिक्स "चालू" है SQL सर्वर 2014 RTM में ट्रेस ध्वज के बिना डिफ़ॉल्ट।