विफलता एक प्रणाली की क्षमता है जो कुछ विफलता होने पर भी काम करना जारी रखती है। यह सुझाव देता है कि यदि प्राथमिक घटक विफल हो जाते हैं या यदि इसकी आवश्यकता होती है तो सिस्टम के कार्यों को द्वितीयक घटकों द्वारा ग्रहण किया जाता है। इसलिए, यदि आप इसे पोस्टग्रेएसक्यूएल मल्टी-क्लाउड वातावरण में अनुवाद करते हैं, तो इसका मतलब है कि जब आपका प्राथमिक नोड विफल हो जाता है (या एक अन्य कारण जैसा कि हम अगले भाग में उल्लेख करेंगे) आपके प्राथमिक क्लाउड प्रदाता में, आपको स्टैंडबाय नोड को बढ़ावा देने में सक्षम होना चाहिए सिस्टम को चालू रखने के लिए सेकेंडरी में।
सामान्य तौर पर, सभी क्लाउड प्रदाता आपको एक ही क्लाउड प्रदाता में एक विफलता विकल्प देते हैं, लेकिन यह संभव हो सकता है कि आपको किसी अन्य भिन्न क्लाउड प्रदाता को विफल करने की आवश्यकता हो। बेशक, आप इसे मैन्युअल रूप से कर सकते हैं, लेकिन आप इसे एक दोस्ताना और आसान तरीके से बनाने के लिए ऑटो-फेलओवर या स्लेव एक्शन को बढ़ावा देने जैसी कुछ क्लस्टर नियंत्रण सुविधाओं का भी उपयोग कर सकते हैं।
इस ब्लॉग में, आप देखेंगे कि आपको फ़ेलओवर की आवश्यकता क्यों है, इसे मैन्युअल रूप से कैसे करें, और इस कार्य के लिए ClusterControl का उपयोग कैसे करें। हम मान लेंगे कि आपके पास ClusterControl इंस्टॉलेशन चल रहा है और आपका डेटाबेस क्लस्टर पहले से ही दो अलग-अलग क्लाउड प्रदाताओं में बनाया गया है।
विफलता का उपयोग किस लिए किया जाता है?
विफलता के कई संभावित उपयोग हैं।
मास्टर विफलता
यदि आपका प्राथमिक नोड बंद है या आपके मुख्य क्लाउड प्रदाता में कुछ समस्याएं हैं, तो आपको अपने सिस्टम की उपलब्धता सुनिश्चित करने के लिए विफल होना चाहिए। इस मामले में, डाउनटाइम को कम करने के लिए ऐसा करने का एक स्वचालित तरीका आवश्यक हो सकता है।
माइग्रेशन
यदि आप अपने डाउनटाइम को कम करके अपने सिस्टम को एक क्लाउड प्रदाता से दूसरे क्लाउड प्रदाता में माइग्रेट करना चाहते हैं, तो आप फ़ेलओवर का उपयोग कर सकते हैं। आप सेकेंडरी क्लाउड प्रोवाइडर में एक रेप्लिका बना सकते हैं, और एक बार इसके सिंक्रोनाइज़ हो जाने के बाद, आपको अपने सिस्टम को सेकेंडरी क्लाउड प्रोवाइडर में नए प्राइमरी नोड की ओर इंगित करने से पहले, अपने सिस्टम को रोकना होगा, अपनी रेप्लिका और फेलओवर को बढ़ावा देना होगा।
रखरखाव
यदि आपको अपने PostgreSQL प्राथमिक नोड पर कोई रखरखाव कार्य करने की आवश्यकता है, तो आप अपनी प्रतिकृति को बढ़ावा दे सकते हैं, कार्य कर सकते हैं, और अपने पुराने प्राथमिक को एक स्टैंडबाय नोड के रूप में पुनर्निर्माण कर सकते हैं।
इसके बाद, आप पुराने प्राथमिक को बढ़ावा दे सकते हैं, और स्टैंडबाय नोड पर पुनर्निर्माण प्रक्रिया को दोहरा सकते हैं, प्रारंभिक स्थिति में लौट सकते हैं।
इस तरह, आप अपने सर्वर पर काम कर सकते हैं, बिना किसी रखरखाव कार्य के ऑफ़लाइन होने या जानकारी खोने का जोखिम उठाए बिना।
अपग्रेड करें
अपने PostgreSQL संस्करण को अपग्रेड करना संभव है (PostgreSQL 10 के बाद से) या यहां तक कि शून्य डाउनटाइम के साथ तार्किक प्रतिकृति का उपयोग करके अपने ऑपरेटिंग सिस्टम को अपग्रेड करना संभव है, जैसा कि अन्य इंजनों के साथ किया जा सकता है।
नए क्लाउड प्रदाता में माइग्रेट करने के चरण समान होंगे, केवल यह कि आपकी प्रतिकृति एक नए PostgreSQL या OS संस्करण में होगी और आपको तार्किक प्रतिकृति का उपयोग करने की आवश्यकता है क्योंकि आप स्ट्रीमिंग का उपयोग नहीं कर सकते विभिन्न संस्करणों के बीच प्रतिकृति।
विफलता केवल डेटाबेस के बारे में नहीं है, बल्कि एप्लिकेशन के बारे में भी है। वे कैसे जानते हैं कि किस डेटाबेस से जुड़ना है? आप शायद अपने आवेदन को संशोधित नहीं करना चाहते हैं, क्योंकि यह केवल आपके डाउनटाइम का विस्तार करेगा, इसलिए, आप लोड बैलेंसर को कॉन्फ़िगर कर सकते हैं कि जब आपका प्राथमिक नोड डाउन हो, तो यह स्वचालित रूप से उस सर्वर को इंगित करेगा जिसे बढ़ावा दिया गया था।
एक सिंगल लोड बैलेंसर इंस्टेंस होना सबसे अच्छा विकल्प नहीं है क्योंकि यह विफलता का एकल बिंदु बन सकता है। इसलिए, आप Keepalived जैसी सेवा का उपयोग करके लोड बैलेंसर के लिए फ़ेलओवर भी लागू कर सकते हैं। इस तरह, यदि आपको अपने प्राथमिक लोड बैलेंसर में कोई समस्या है, तो Keepalived वर्चुअल IP को आपके द्वितीयक लोड बैलेंसर में माइग्रेट कर देगा, और सब कुछ पारदर्शी रूप से काम करना जारी रखेगा।
एक अन्य विकल्प DNS का उपयोग है। द्वितीयक क्लाउड प्रदाता में स्टैंडबाय नोड को बढ़ावा देकर, आप सीधे होस्टनाम आईपी पते को संशोधित करते हैं जो प्राथमिक नोड को इंगित करता है। इस तरह, आप अपने आवेदन को संशोधित करने से बचते हैं, और यद्यपि यह स्वचालित रूप से नहीं किया जा सकता है, यदि आप लोड बैलेंसर को लागू नहीं करना चाहते हैं तो यह एक विकल्प है।
PostgreSQL को मैन्युअल रूप से कैसे विफल करें
मैन्युअल फ़ेलओवर करने से पहले, आपको प्रतिकृति स्थिति की जाँच करनी चाहिए। यह संभव हो सकता है कि, जब आपको विफल होने की आवश्यकता हो, नेटवर्क विफलता, उच्च लोड, या किसी अन्य समस्या के कारण स्टैंडबाय नोड अप-टू-डेट नहीं है, इसलिए आपको यह सुनिश्चित करने की आवश्यकता है कि आपके स्टैंडबाय नोड में सभी (या लगभग) हैं सभी जानकारी। यदि आपके पास एक से अधिक स्टैंडबाय नोड हैं, तो आपको यह भी जांचना चाहिए कि कौन सा सबसे उन्नत नोड है और इसे फेलओवर के लिए चुनें।
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)जब आप नया प्राथमिक नोड चुनते हैं, तो सबसे पहले, आप क्लस्टर जानकारी प्राप्त करने के लिए pg_lsclusters कमांड चला सकते हैं:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logफिर, आपको केवल प्रचार क्रिया के साथ pg_ctlcluster कमांड चलाने की आवश्यकता है:
$ pg_ctlcluster 12 main promoteपिछली कमांड के बजाय, आप pg_ctl कमांड को इस तरह से चला सकते हैं:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedफिर, आपके स्टैंडबाय नोड को प्राथमिक में पदोन्नत किया जाएगा, और आप अपने नए प्राथमिक नोड में निम्न क्वेरी चलाकर इसे सत्यापित कर सकते हैं:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)यदि परिणाम "f" है, तो यह आपका नया प्राथमिक नोड है।
अब, आपको अपने एप्लिकेशन में प्राथमिक डेटाबेस आईपी पता, लोड बैलेंसर, डीएनएस, या उस कार्यान्वयन को बदलना होगा जिसका आप उपयोग कर रहे हैं, जैसा कि हमने उल्लेख किया है, इसे मैन्युअल रूप से बदलने से डाउनटाइम बढ़ जाएगा। आपको यह सुनिश्चित करने की भी आवश्यकता है कि संभावित प्रदाताओं के बीच आपकी कनेक्टिविटी ठीक से काम कर रही है, एप्लिकेशन नए प्राथमिक नोड तक पहुंच सकता है, एप्लिकेशन उपयोगकर्ता के पास इसे एक अलग क्लाउड प्रदाता से एक्सेस करने का विशेषाधिकार है, और आपको स्टैंडबाय नोड को फिर से बनाना चाहिए। रिमोट या यहां तक कि स्थानीय क्लाउड प्रदाता में, नए प्राथमिक से दोहराने के लिए, अन्यथा, यदि आवश्यक हो तो आपके पास एक नया फ़ेलओवर विकल्प नहीं होगा।
ClusterControl का उपयोग करके PostgreSQL को कैसे विफल करें
ClusterControl में PostgreSQL प्रतिकृति और स्वचालित विफलता से संबंधित कई विशेषताएं हैं। हम मान लेंगे कि आपने अपना क्लस्टरकंट्रोल सर्वर स्थापित कर लिया है और यह आपके मल्टी-क्लाउड पोस्टग्रेएसक्यूएल वातावरण का प्रबंधन कर रहा है।
ClusterControl के साथ, आप बिना किसी नेटवर्क IP प्रतिबंध के जितने चाहें उतने स्टैंडबाय नोड्स या लोड बैलेंसर नोड्स जोड़ सकते हैं। इसका अर्थ है कि यह आवश्यक नहीं है कि स्टैंडबाय नोड एक ही प्राथमिक नोड नेटवर्क में हो या एक ही क्लाउड प्रदाता में भी हो। विफलता के संदर्भ में, ClusterControl आपको इसे मैन्युअल रूप से या स्वचालित रूप से करने की अनुमति देता है।
मैन्युअल विफलता
मैन्युअल फ़ेलओवर करने के लिए, ClusterControl पर जाएँ -> क्लस्टर चुनें -> Nodes, और अपने स्टैंडबाय नोड्स में से किसी एक की नोड क्रिया में, "प्रोमोट स्लेव" चुनें।
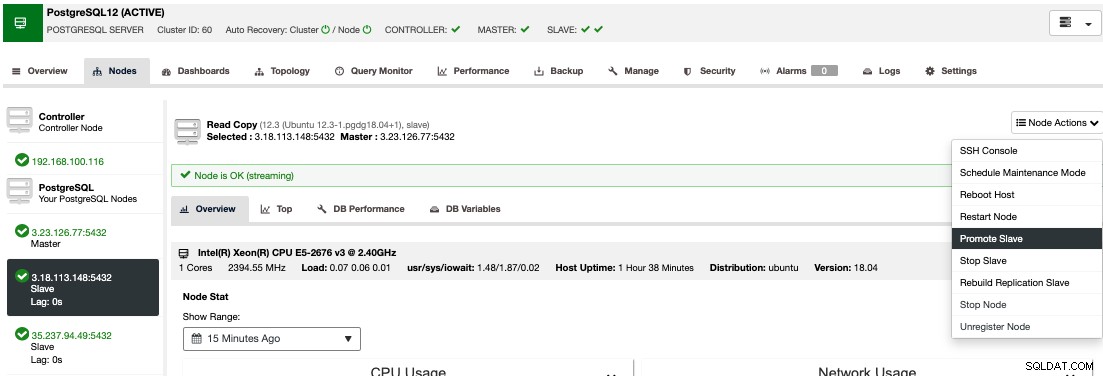
इस तरह, कुछ सेकंड के बाद, आपका स्टैंडबाय नोड प्राथमिक हो जाता है, और जो पहले आपका प्राथमिक था, उसे स्टैंडबाय में बदल दिया गया है। इसलिए, यदि आपकी प्रतिकृति किसी अन्य क्लाउड प्रदाता में थी, तो आपका नया प्राथमिक नोड वहां होगा, ऊपर और चल रहा होगा।
स्वचालित विफलता
स्वचालित विफलता के मामले में, ClusterControl प्राथमिक नोड में विफलताओं का पता लगाता है और नए प्राथमिक के रूप में सबसे वर्तमान डेटा के साथ एक स्टैंडबाय नोड को बढ़ावा देता है। यह बाकी स्टैंडबाय नोड्स पर भी काम करता है ताकि उन्हें इस नए प्राथमिक से दोहराया जा सके।

"स्वतः पुनर्प्राप्ति" विकल्प चालू होने पर, ClusterControl एक स्वचालित विफलता का प्रदर्शन करेगा जैसे साथ ही आपको समस्या से अवगत कराते हैं। इस तरह, आपके सिस्टम सेकंड में और आपके हस्तक्षेप के बिना ठीक हो सकते हैं।
ClusterControl आपको यह परिभाषित करने के लिए एक श्वेतसूची/ब्लैकलिस्ट कॉन्फ़िगर करने की संभावना प्रदान करता है कि आप प्राथमिक उम्मीदवार के बारे में निर्णय लेते समय अपने सर्वर को कैसे ध्यान में रखना चाहते हैं (या नहीं लिया जाना चाहिए)।
ClusterControl फेलओवर प्रक्रिया पर कई जांच भी करता है, उदाहरण के लिए, डिफ़ॉल्ट रूप से, यदि आप अपने पुराने विफल प्राथमिक नोड को पुनर्प्राप्त करने का प्रबंधन करते हैं, तो इसे क्लस्टर में स्वचालित रूप से पुन:प्रस्तुत नहीं किया जाएगा, न ही प्राथमिक के रूप में और न ही एक स्टैंडबाय के रूप में, आपको इसे मैन्युअल रूप से करने की आवश्यकता होगी। यह उस स्थिति में डेटा हानि या असंगति की संभावना से बच जाएगा जब विफलता के समय आपका स्टैंडबाय (जिसे आपने प्रचारित किया था) में देरी हुई थी। हो सकता है कि आप समस्या का विस्तार से विश्लेषण करना चाहें, लेकिन इसे अपने क्लस्टर में जोड़ते समय, आप संभवतः नैदानिक जानकारी खो देंगे।
बैलेंसर लोड करें
जैसा कि हमने पहले उल्लेख किया है, लोड बैलेंसर आपके फेलओवर के लिए विचार करने के लिए एक महत्वपूर्ण उपकरण है, खासकर यदि आप अपने डेटाबेस टोपोलॉजी में स्वचालित विफलता का उपयोग करना चाहते हैं।
उपयोगकर्ता और एप्लिकेशन दोनों के लिए विफलता पारदर्शी होने के लिए, आपको बीच में एक घटक की आवश्यकता है, क्योंकि यह एक नए प्राथमिक नोड को बढ़ावा देने के लिए पर्याप्त नहीं है। इसके लिए आप HAProxy + Keepalived का उपयोग कर सकते हैं।
ClusterControl के साथ इस समाधान को लागू करने के लिए, अपने PostgreSQL क्लस्टर पर क्लस्टर क्रियाएँ -> लोड बैलेंसर जोड़ें -> HAProxy पर जाएँ। यदि आप अपने लोड बैलेंसर के लिए फ़ेलओवर लागू करना चाहते हैं, तो आपको कम से कम दो HAProxy इंस्टेंस को कॉन्फ़िगर करना होगा, और फिर, आप Keepalived (क्लस्टर क्रियाएँ -> लोड बैलेंसर जोड़ें -> Keepalived) को कॉन्फ़िगर कर सकते हैं। आप इस ब्लॉग पोस्ट में इस कार्यान्वयन के बारे में अधिक जानकारी प्राप्त कर सकते हैं।
इसके बाद, आपके पास निम्न टोपोलॉजी होगी:

HAProxy डिफ़ॉल्ट रूप से दो अलग-अलग पोर्ट के साथ कॉन्फ़िगर किया गया है, एक रीड-राइट और केवल पढ़ने के लिए।
रीड-राइट पोर्ट में, आपके पास अपना प्राथमिक नोड ऑनलाइन और शेष नोड ऑफ़लाइन के रूप में होता है। केवल-पढ़ने के लिए पोर्ट में, आपके पास प्राथमिक और स्टैंडबाय दोनों नोड्स ऑनलाइन हैं। इस तरह, आप नोड्स के बीच रीडिंग ट्रैफिक को संतुलित कर सकते हैं। लिखते समय, रीड-राइट पोर्ट का उपयोग किया जाएगा, जो वर्तमान प्राथमिक नोड को इंगित करेगा।

जब HAProxy को पता चलता है कि नोड्स में से एक, प्राथमिक या स्टैंडबाय, है पहुंच योग्य नहीं है, यह स्वचालित रूप से इसे ऑफ़लाइन के रूप में चिह्नित करता है। HAProxy इस पर कोई ट्रैफिक नहीं भेजेगा। यह जाँच स्वास्थ्य जाँच स्क्रिप्ट द्वारा की जाती है जो परिनियोजन के समय ClusterControl द्वारा कॉन्फ़िगर की जाती है। ये जाँचते हैं कि क्या इंस्टेंस ऊपर हैं, क्या वे ठीक हो रहे हैं, या केवल-पढ़ने के लिए हैं।
जब ClusterControl एक नए प्राथमिक नोड को बढ़ावा देता है, HAProxy पुराने को ऑफ़लाइन (दोनों पोर्ट के लिए) के रूप में चिह्नित करता है और प्रचारित नोड को रीड-राइट पोर्ट में ऑनलाइन रखता है। इस तरह, आपके सिस्टम सामान्य रूप से काम करना जारी रखते हैं।
यदि सक्रिय HAProxy (जिसने एक वर्चुअल IP पता दिया है जिससे आपका सिस्टम कनेक्ट होता है) विफल हो जाता है, Keepalived इस वर्चुअल IP को निष्क्रिय HAProxy में स्वचालित रूप से माइग्रेट करता है। इसका मतलब है कि आपका सिस्टम तब सामान्य रूप से कार्य करना जारी रखने में सक्षम है।
क्लाउड में क्लस्टर-टू-क्लस्टर प्रतिकृति
मल्टी-क्लाउड वातावरण के लिए, आप अपने PostgreSQL क्लस्टर पर ClusterControl Add स्लेव क्रिया का उपयोग कर सकते हैं, लेकिन क्लस्टर-टू-क्लस्टर प्रतिकृति सुविधा का भी उपयोग कर सकते हैं। फिलहाल, इस सुविधा में PostgreSQL के लिए एक सीमा है जो आपको केवल एक दूरस्थ नोड रखने की अनुमति देती है, लेकिन हम भविष्य के रिलीज में जल्द ही उस सीमा को हटाने के लिए काम कर रहे हैं।
इसे परिनियोजित करने के लिए, आप इस ब्लॉग पोस्ट में "क्लाउड में क्लस्टर-टू-क्लस्टर प्रतिकृति" अनुभाग देख सकते हैं।

जब यह जगह में हो, तो आप दूरस्थ क्लस्टर को बढ़ावा दे सकते हैं जो उत्पन्न करेगा द्वितीयक क्लाउड प्रदाता पर चलने वाले प्राथमिक नोड के साथ एक स्वतंत्र PostgreSQL क्लस्टर।

इसलिए, यदि आपको इसकी आवश्यकता है, तो आपके पास वही क्लस्टर चल रहा होगा कुछ ही सेकंड में एक नए क्लाउड प्रदाता में।
निष्कर्ष
यदि आप यथासंभव कम डाउनटाइम चाहते हैं तो स्वचालित विफलता प्रक्रिया अनिवार्य है, और HAProxy और Keepalived जैसी विभिन्न तकनीकों का उपयोग करने से इस विफलता में सुधार होगा।
क्लस्टरकंट्रोल की जिन सुविधाओं का हमने ऊपर उल्लेख किया है, वे आपको विभिन्न क्लाउड प्रदाताओं के बीच शीघ्रता से विफल होने और सेटअप को आसान और मैत्रीपूर्ण तरीके से प्रबंधित करने की अनुमति देंगी।
विभिन्न क्लाउड प्रदाताओं के बीच एक विफलता प्रक्रिया करने से पहले ध्यान रखने वाली सबसे महत्वपूर्ण बात कनेक्टिविटी है। आपको यह सुनिश्चित करना होगा कि आपका एप्लिकेशन या आपका डेटाबेस कनेक्शन विफलता के मामले में मुख्य लेकिन द्वितीयक क्लाउड प्रदाता का उपयोग करके सामान्य रूप से काम करेगा, और सुरक्षा कारणों से, आपको केवल ज्ञात स्रोतों से ट्रैफ़िक को प्रतिबंधित करना होगा, इसलिए केवल क्लाउड के बीच प्रदाता और किसी बाहरी स्रोत से इसकी अनुमति नहीं देते हैं।