मल्टी-क्लाउड या मल्टी-डेटासेंटर वातावरण का उपयोग भू-वितरित टोपोलॉजी के लिए या यहां तक कि एक आपदा वसूली योजना के लिए भी उपयोगी है, और वास्तव में, यह आजकल अधिक लोकप्रिय हो रहा है, इसलिए स्प्लिट-ब्रेन की अवधारणा यह और भी महत्वपूर्ण होता जा रहा है क्योंकि इस तरह के परिदृश्य में इसके बढ़ने का जोखिम है। संभावित डेटा हानि या डेटा असंगति से बचने के लिए आपको स्प्लिट-ब्रेन को रोकना चाहिए, जो व्यवसाय के लिए एक बड़ी समस्या हो सकती है।
इस ब्लॉग में, हम देखेंगे कि स्प्लिट-ब्रेन क्या है, और कैसे ClusterControl इस महत्वपूर्ण समस्या से बचने में आपकी मदद कर सकता है।
स्प्लिट-ब्रेन क्या है?
PostgreSQL की दुनिया में, स्प्लिट-ब्रेन तब होता है जब एक ही समय में एक से अधिक प्राथमिक नोड उपलब्ध होते हैं (बहु-मास्टर वातावरण के लिए किसी तीसरे पक्ष के उपकरण के बिना) जो एप्लिकेशन को लिखने की अनुमति देता है दोनों नोड्स में। इस मामले में, आपके पास प्रत्येक नोड पर अलग-अलग जानकारी होगी, जो क्लस्टर में डेटा असंगति उत्पन्न करती है। इस समस्या को ठीक करना कठिन हो सकता है क्योंकि आपको डेटा मर्ज करना होगा, कुछ ऐसा जो कभी-कभी संभव नहीं होता है।
मल्टी-क्लाउड टोपोलॉजी में PostgreSQL स्प्लिट-ब्रेन
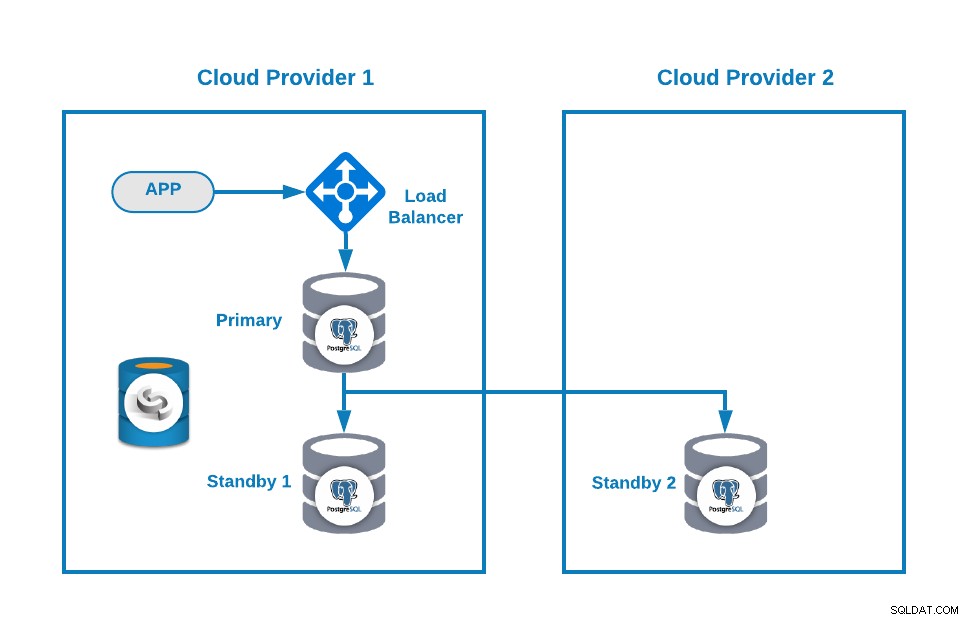
मान लें कि आपके पास PostgreSQL के लिए निम्नलिखित मल्टी-क्लाउड टोपोलॉजी है (जो आजकल एक बहुत ही सामान्य टोपोलॉजी है):
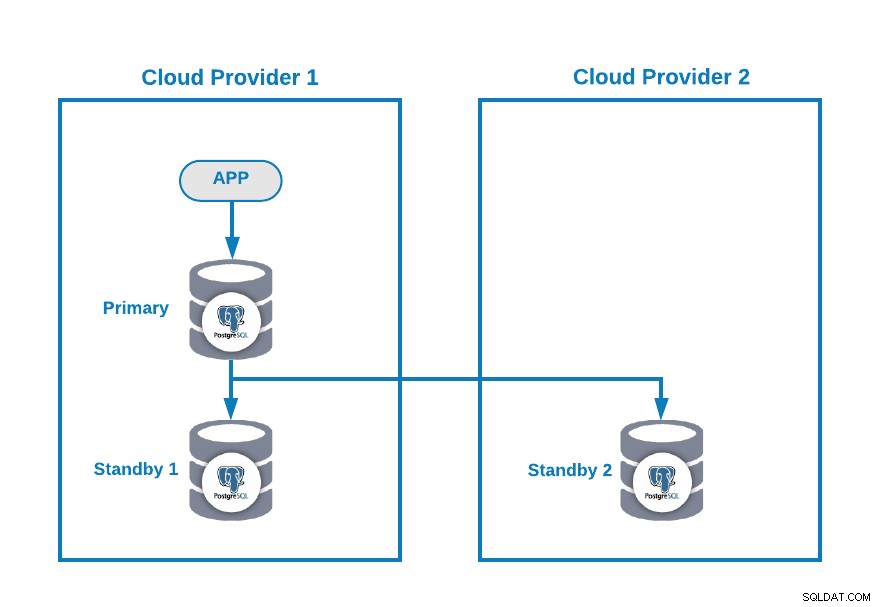
बेशक, उदाहरण के लिए, आप एक जोड़कर इस वातावरण को बेहतर बना सकते हैं। क्लाउड प्रदाता 2 में एप्लिकेशन सर्वर, लेकिन इस मामले में, आइए इस बुनियादी कॉन्फ़िगरेशन का उपयोग करें।
यदि आपका प्राथमिक नोड नीचे है, तो स्टैंडबाय नोड्स में से एक को नए प्राथमिक के रूप में प्रचारित किया जाना चाहिए और इस नए प्राथमिक नोड का उपयोग करने के लिए आपको अपने आवेदन में आईपी पता बदलना चाहिए।
इसे स्वचालित तरीके से बनाने के विभिन्न तरीके हैं। उदाहरण के लिए, आप अपने प्राथमिक नोड को असाइन किए गए वर्चुअल आईपी पते का उपयोग कर सकते हैं और इसकी निगरानी कर सकते हैं। यदि यह विफल हो जाता है, तो स्टैंडबाय नोड्स में से किसी एक को बढ़ावा दें और वर्चुअल आईपी पते को इस नए प्राथमिक नोड में माइग्रेट करें, ताकि आपको अपने एप्लिकेशन में कुछ भी बदलने की आवश्यकता न हो, और इसे आपकी अपनी स्क्रिप्ट या टूल का उपयोग करके बनाया जा सकता है।
फिलहाल, आपके पास कोई समस्या नहीं है, लेकिन... यदि आपका पुराना प्राथमिक नोड वापस आता है, तो आपको यह सुनिश्चित करना होगा कि आपके पास एक ही समय में एक ही क्लस्टर में दो प्राथमिक नोड नहीं होंगे ।
इस स्थिति से बचने के सबसे सामान्य तरीके हैं:
- STONITH:सिर में दूसरे नोड को गोली मारो।
- स्मिथ:खुद को सिर में गोली मारो।
PostgreSQL इस प्रक्रिया को स्वचालित करने का कोई तरीका प्रदान नहीं करता है। आपको इसे स्वयं बनाना होगा।
ClusterControl के साथ PostgreSQL में स्प्लिट-ब्रेन से कैसे बचें
अब, देखते हैं कि ClusterControl इस कार्य में आपकी कैसे मदद कर सकता है।
सबसे पहले, आप इसका उपयोग अपने PostgreSQL मल्टी-क्लाउड वातावरण को एक आसान तरीके से परिनियोजित या आयात करने के लिए कर सकते हैं जैसा कि आप इस ब्लॉग पोस्ट में देख सकते हैं।
फिर, आप एक लोड बैलेंसर (HAProxy) जोड़कर अपनी टोपोलॉजी में सुधार कर सकते हैं, जिसे आप इस ब्लॉग के बाद ClusterControl का उपयोग करके भी कर सकते हैं। तो, आपके पास कुछ इस तरह होगा:
ClusterControl में एक ऑटो-फेलओवर सुविधा है जो मास्टर विफलताओं का पता लगाती है और स्टैंडबाय को बढ़ावा देती है एक नए प्राथमिक के रूप में सबसे वर्तमान डेटा के साथ नोड। यह नए प्राथमिक नोड से दोहराने के लिए बाकी स्टैंडबाय नोड्स पर भी विफल रहता है।
HAProxy को ClusterControl द्वारा डिफ़ॉल्ट रूप से दो अलग-अलग पोर्ट के साथ कॉन्फ़िगर किया गया है, एक रीड-राइट और एक रीड-ओनली। रीड-राइट पोर्ट में, आपके पास अपना प्राथमिक नोड ऑनलाइन है और आपके बाकी नोड्स ऑफ़लाइन हैं, और रीड-ओनली पोर्ट में, आपके पास प्राथमिक और स्टैंडबाय दोनों नोड्स ऑनलाइन हैं। इस तरह, आप अपने नोड्स के बीच पठन ट्रैफ़िक को संतुलित कर सकते हैं लेकिन आप यह सुनिश्चित करते हैं कि लेखन के समय, रीड-राइट पोर्ट का उपयोग किया जाएगा, प्राथमिक नोड में लिखना जो कि सर्वर है जो ऑनलाइन है।
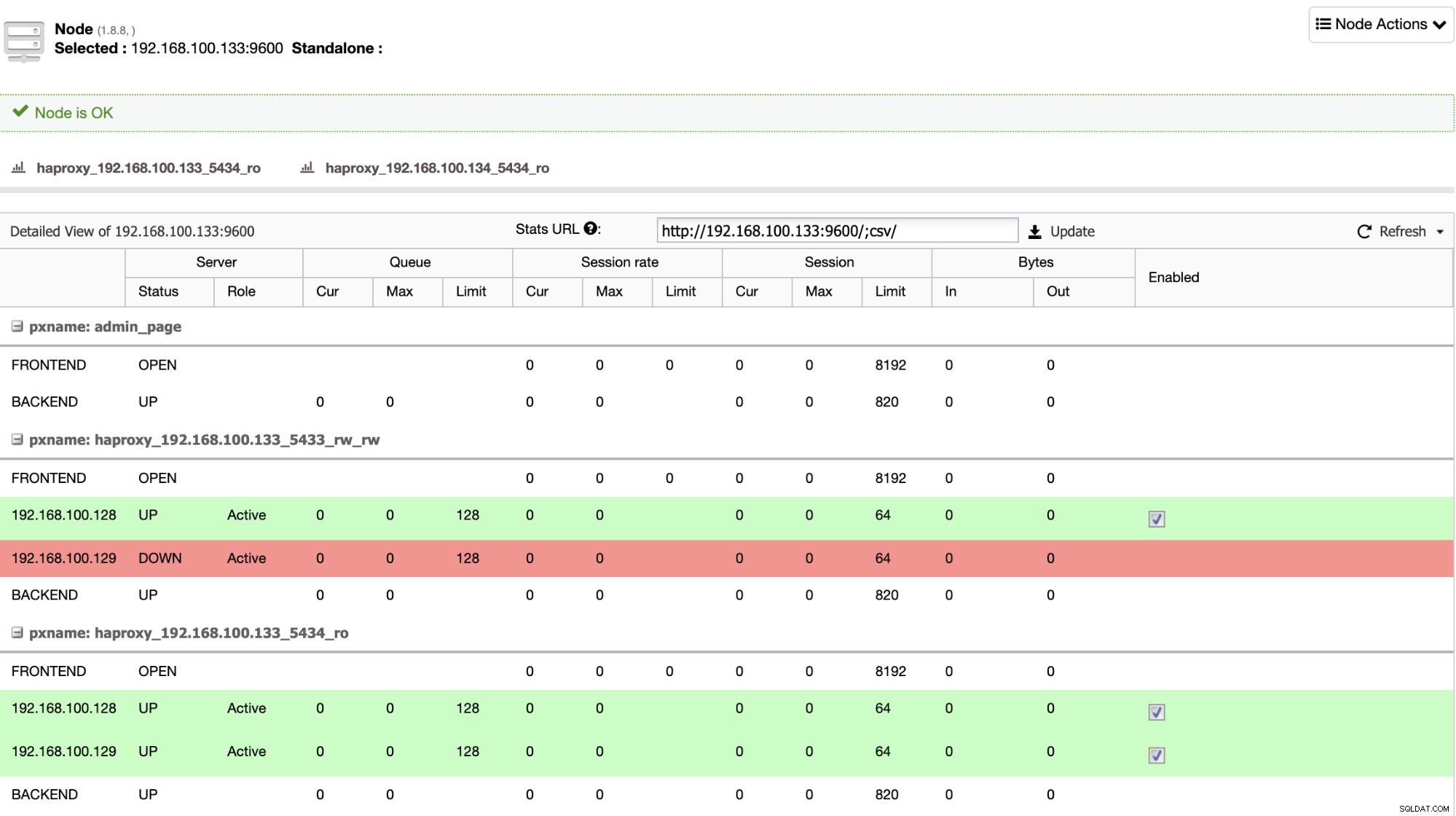
जब HAProxy को पता चलता है कि आपका कोई नोड, प्राथमिक या स्टैंडबाय, है पहुंच योग्य नहीं है, यह स्वचालित रूप से इसे ऑफ़लाइन के रूप में चिह्नित करता है और इसे ट्रैफ़िक भेजने के लिए ध्यान में नहीं रखता है। यह जाँच स्वास्थ्य जाँच स्क्रिप्ट द्वारा की जाती है जो परिनियोजन के समय ClusterControl द्वारा कॉन्फ़िगर की जाती है। ये जाँचते हैं कि क्या मामले बढ़ रहे हैं, क्या वे ठीक हो रहे हैं, या केवल पढ़ने के लिए हैं।
यदि आपका पुराना प्राथमिक नोड वापस आता है, तो ClusterControl इसे शुरू करने से भी बच जाएगा, संभावित विभाजन-मस्तिष्क को रोकने के लिए यदि आपके पास एक सीधा कनेक्शन है जो लोड बैलेंसर का उपयोग नहीं कर रहा है, लेकिन आप इसे जोड़ सकते हैं ClusterControl UI या CLI का उपयोग करके स्वचालित या मैन्युअल तरीके से एक स्टैंडबाय नोड के रूप में क्लस्टर में, फिर आप इसे उसी टोपोलॉजी के लिए प्रचारित कर सकते हैं जो आपने समस्या से पहले चलाई थी।
निष्कर्ष
"स्वतः पुनर्प्राप्ति" विकल्प चालू होने पर, ClusterControl इस स्वचालित विफलता को निष्पादित करेगा और साथ ही आपको समस्या के बारे में सूचित करेगा। इस तरह, आपके सिस्टम आपके हस्तक्षेप के बिना सेकंड में ठीक हो सकते हैं और आप PostgreSQL मल्टी-क्लाउड वातावरण में विभाजित मस्तिष्क से बचेंगे।
आप इस ब्लॉग में वर्णित CMON HA सुविधा का उपयोग करके अधिक ClusterControl नोड्स जोड़कर अपने उच्च उपलब्धता वातावरण में सुधार कर सकते हैं।