OLTP (ऑनलाइन ट्रांजेक्शन प्रोसेसिंग) डेटाबेस के साथ काम करते समय, क्वेरी प्रदर्शन सर्वोपरि है क्योंकि यह सीधे उपयोगकर्ता अनुभव को प्रभावित करता है। धीमी क्वेरी का मतलब है कि एप्लिकेशन अनुत्तरदायी और धीमा लगता है और इसके परिणामस्वरूप खराब रूपांतरण दर, दुखी उपयोगकर्ता और सभी प्रकार की समस्याएं होती हैं।
OLTP PostgreSQL के लिए सामान्य उपयोग के मामलों में से एक है इसलिए आप चाहते हैं कि आपके प्रश्न यथासंभव सुचारू रूप से चले। इस ब्लॉग में हम इस बारे में बात करना चाहेंगे कि आप PostgreSQL में धीमी क्वेरी के साथ समस्याओं की पहचान कैसे कर सकते हैं।
धीमे लॉग को समझना
सामान्यतया, PostgreSQL के साथ प्रदर्शन समस्याओं की पहचान करने का सबसे विशिष्ट तरीका धीमी क्वेरी एकत्र करना है। आप इसे करने के कुछ तरीके हैं। सबसे पहले, आप इसे एकल डेटाबेस पर सक्षम कर सकते हैं:
pgbench=# ALTER DATABASE pgbench SET log_min_duration_statement=0;
ALTER DATABASEइसके बाद 'pgbench' डेटाबेस के सभी नए कनेक्शन PostgreSQL लॉग में लॉग इन हो जाएंगे।
इसे विश्व स्तर पर जोड़कर सक्षम करना भी संभव है:
log_min_duration_statement = 0पोस्टग्रेएसक्यूएल कॉन्फ़िगरेशन के लिए और फिर कॉन्फ़िगरेशन को पुनः लोड करें:
pgbench=# SELECT pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)यह आपके PostgreSQL के सभी डेटाबेस में सभी प्रश्नों को लॉग करने में सक्षम बनाता है। यदि आपको कोई लॉग नहीं दिखाई देता है, तो आप logging_collector =on को भी सक्षम करना चाह सकते हैं। लॉग में पोस्टग्रेएसक्यूएल सिस्टम टेबल पर आने वाले सभी ट्रैफिक शामिल होंगे, जिससे इसे और अधिक शोर बना दिया जाएगा। हमारे उद्देश्यों के लिए आइए डेटाबेस स्तर लॉगिंग से चिपके रहें।
लॉग में आप जो देखेंगे वह नीचे दी गई प्रविष्टियां हैं:
2020-02-21 09:45:39.022 UTC [13542] LOG: duration: 0.145 ms statement: SELECT abalance FROM pgbench_accounts WHERE aid = 29817899;
2020-02-21 09:45:39.022 UTC [13544] LOG: duration: 0.107 ms statement: SELECT abalance FROM pgbench_accounts WHERE aid = 11782597;
2020-02-21 09:45:39.022 UTC [13529] LOG: duration: 0.065 ms statement: SELECT abalance FROM pgbench_accounts WHERE aid = 16318529;
2020-02-21 09:45:39.022 UTC [13529] LOG: duration: 0.082 ms statement: UPDATE pgbench_tellers SET tbalance = tbalance + 3063 WHERE tid = 3244;
2020-02-21 09:45:39.022 UTC [13526] LOG: duration: 16.450 ms statement: UPDATE pgbench_branches SET bbalance = bbalance + 1359 WHERE bid = 195;
2020-02-21 09:45:39.023 UTC [13523] LOG: duration: 15.824 ms statement: UPDATE pgbench_accounts SET abalance = abalance + -3726 WHERE aid = 5290358;
2020-02-21 09:45:39.023 UTC [13542] LOG: duration: 0.107 ms statement: UPDATE pgbench_tellers SET tbalance = tbalance + -2716 WHERE tid = 1794;
2020-02-21 09:45:39.024 UTC [13544] LOG: duration: 0.112 ms statement: UPDATE pgbench_tellers SET tbalance = tbalance + -3814 WHERE tid = 278;
2020-02-21 09:45:39.024 UTC [13526] LOG: duration: 0.060 ms statement: INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (4876, 195, 39955137, 1359, CURRENT_TIMESTAMP);
2020-02-21 09:45:39.024 UTC [13529] LOG: duration: 0.081 ms statement: UPDATE pgbench_branches SET bbalance = bbalance + 3063 WHERE bid = 369;
2020-02-21 09:45:39.024 UTC [13523] LOG: duration: 0.063 ms statement: SELECT abalance FROM pgbench_accounts WHERE aid = 5290358;
2020-02-21 09:45:39.024 UTC [13542] LOG: duration: 0.100 ms statement: UPDATE pgbench_branches SET bbalance = bbalance + -2716 WHERE bid = 210;
2020-02-21 09:45:39.026 UTC [13523] LOG: duration: 0.092 ms statement: UPDATE pgbench_tellers SET tbalance = tbalance + -3726 WHERE tid = 67;
2020-02-21 09:45:39.026 UTC [13529] LOG: duration: 0.090 ms statement: INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (3244, 369, 16318529, 3063, CURRENT_TIMESTAMP);आप क्वेरी और उसकी अवधि के बारे में जानकारी देख सकते हैं। ज्यादा नहीं लेकिन यह निश्चित रूप से शुरू करने के लिए एक अच्छी जगह है। ध्यान रखने वाली मुख्य बात यह है कि हर धीमी क्वेरी एक समस्या नहीं है। कभी-कभी प्रश्नों के लिए महत्वपूर्ण मात्रा में डेटा तक पहुंचना होता है और यह उम्मीद की जाती है कि उपयोगकर्ता द्वारा मांगी गई सभी सूचनाओं तक पहुंचने और उनका विश्लेषण करने में उन्हें अधिक समय लगेगा। एक और सवाल यह है कि "धीमा" का क्या अर्थ है? यह ज्यादातर आवेदन पर निर्भर करता है। अगर हम इंटरेक्टिव एप्लिकेशन के बारे में बात कर रहे हैं, तो सबसे अधिक संभावना है कि एक सेकंड से भी धीमी गति से कुछ भी ध्यान देने योग्य है। आदर्श रूप से सब कुछ 100 - 200 मिलीसेकंड की सीमा के भीतर निष्पादित किया जाता है।
एक क्वेरी निष्पादन योजना विकसित करना
एक बार जब हम यह निर्धारित कर लें कि दी गई क्वेरी वास्तव में कुछ ऐसी है जिसे हम सुधारना चाहते हैं, तो हमें क्वेरी निष्पादन योजना पर एक नज़र डालनी चाहिए। सबसे पहले, ऐसा हो सकता है कि हम इसके बारे में कुछ नहीं कर सकते हैं और हमें यह स्वीकार करना होगा कि दी गई क्वेरी बस धीमी है। दूसरा, क्वेरी निष्पादन योजनाएँ बदल सकती हैं। ऑप्टिमाइज़र हमेशा सबसे इष्टतम निष्पादन योजना चुनने का प्रयास करते हैं लेकिन वे केवल डेटा के नमूने के आधार पर अपने निर्णय लेते हैं इसलिए ऐसा हो सकता है कि क्वेरी निष्पादन योजना समय के साथ बदल जाए। PostgreSQL में आप निष्पादन योजना को दो तरह से देख सकते हैं। सबसे पहले, अनुमानित निष्पादन योजना, EXPLAIN का उपयोग करते हुए:
pgbench=# EXPLAIN SELECT abalance FROM pgbench_accounts WHERE aid = 5290358;
QUERY PLAN
----------------------------------------------------------------------------------------------
Index Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.56..8.58 rows=1 width=4)
Index Cond: (aid = 5290358)जैसा कि आप देख सकते हैं, हमें प्राथमिक कुंजी लुकअप का उपयोग करके डेटा तक पहुंचने की उम्मीद है। अगर हम दोबारा जांचना चाहते हैं कि क्वेरी को वास्तव में कैसे निष्पादित किया जाएगा, तो हम EXPLAIN ANALYZE का उपयोग कर सकते हैं:
pgbench=# EXPLAIN ANALYZE SELECT abalance FROM pgbench_accounts WHERE aid = 5290358;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Index Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.56..8.58 rows=1 width=4) (actual time=0.046..0.065 rows=1 loops=1)
Index Cond: (aid = 5290358)
Planning time: 0.053 ms
Execution time: 0.084 ms
(4 rows)अब, PostgreSQL ने इस क्वेरी को निष्पादित किया है और यह हमें न केवल अनुमान बल्कि सटीक संख्याएं बता सकता है जब निष्पादन योजना, एक्सेस की गई पंक्तियों की संख्या आदि की बात आती है। कृपया ध्यान रखें कि सभी प्रश्नों को लॉग करना आपके सिस्टम पर एक गंभीर ओवरहेड बन सकता है। आपको लॉग पर भी नजर रखनी चाहिए और सुनिश्चित करना चाहिए कि वे ठीक से घुमाए गए हैं।
Pg_stat_statements
Pg_stat_statements वह एक्सटेंशन है जो विभिन्न क्वेरी प्रकारों के लिए निष्पादन आंकड़े एकत्र करता है।
pgbench=# select query, calls, total_time, min_time, max_time, mean_time, stddev_time, rows from public.pg_stat_statements order by calls desc LIMIT 10;
query | calls | total_time | min_time | max_time | mean_time | stddev_time | rows
------------------------------------------------------------------------------------------------------+-------+------------------+----------+------------+---------------------+---------------------+-------
UPDATE pgbench_branches SET bbalance = bbalance + $1 WHERE bid = $2 | 30437 | 6636.83641200002 | 0.006533 | 83.832148 | 0.218051595492329 | 1.84977058799388 | 30437
BEGIN | 30437 | 231.095600000001 | 0.000205 | 20.260355 | 0.00759258796859083 | 0.26671126085716 | 0
END | 30437 | 229.483213999999 | 0.000211 | 16.980678 | 0.0075396134310215 | 0.223837608828596 | 0
UPDATE pgbench_accounts SET abalance = abalance + $1 WHERE aid = $2 | 30437 | 290021.784321001 | 0.019568 | 805.171845 | 9.52859297305914 | 13.6632712046825 | 30437
UPDATE pgbench_tellers SET tbalance = tbalance + $1 WHERE tid = $2 | 30437 | 6667.27243200002 | 0.00732 | 212.479269 | 0.219051563294674 | 2.13585110968012 | 30437
SELECT abalance FROM pgbench_accounts WHERE aid = $1 | 30437 | 3702.19730600006 | 0.00627 | 38.860846 | 0.121634763807208 | 1.07735927551245 | 30437
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES ($1, $2, $3, $4, CURRENT_TIMESTAMP) | 30437 | 2349.22475800002 | 0.003218 | 61.372127 | 0.0771831901304325 | 0.971590327400244 | 30437
SELECT $1 | 6847 | 60.785467 | 0.002321 | 7.882384 | 0.00887767883744706 | 0.105198744982906 | 6847
insert into pgbench_tellers(tid,bid,tbalance) values ($1,$2,$3) | 5000 | 18.592042 | 0.001572 | 0.741427 | 0.0037184084 | 0.0137660355678027 | 5000
insert into pgbench_tellers(tid,bid,tbalance) values ($1,$2,$3) | 3000 | 7.323788 | 0.001598 | 0.40152 | 0.00244126266666667 | 0.00834442591085048 | 3000
(10 rows)जैसा कि आप ऊपर दिए गए डेटा पर देख सकते हैं, हमारे पास विभिन्न प्रश्नों और उनके निष्पादन समय के बारे में जानकारी की एक सूची है - यह डेटा का केवल एक हिस्सा है जिसे आप pg_stat_statements में देख सकते हैं लेकिन यह पर्याप्त है हमें यह समझने के लिए कि हमारे प्राथमिक कुंजी लुकअप को पूरा होने में कभी-कभी लगभग 39 सेकंड लगते हैं - यह अच्छा नहीं लगता है और यह निश्चित रूप से कुछ ऐसा है जिसकी हम जांच करना चाहते हैं।
यदि आपके पास pg_stat_statements सक्षम नहीं है, तो आप इसे मानक तरीके से कर सकते हैं। या तो कॉन्फ़िगरेशन फ़ाइल के माध्यम से और
shared_preload_libraries = 'pg_stat_statements'या आप इसे PostgreSQL कमांड लाइन के माध्यम से सक्षम कर सकते हैं:
pgbench=# CREATE EXTENSION pg_stat_statements;
CREATE EXTENSIONधीमी क्वेरी को हटाने के लिए ClusterControl का उपयोग करना
यदि आप अपने PostgreSQL डेटाबेस को प्रबंधित करने के लिए ClusterControl का उपयोग करते हैं, तो आप इसका उपयोग धीमी क्वेरी के बारे में डेटा एकत्र करने के लिए कर सकते हैं।
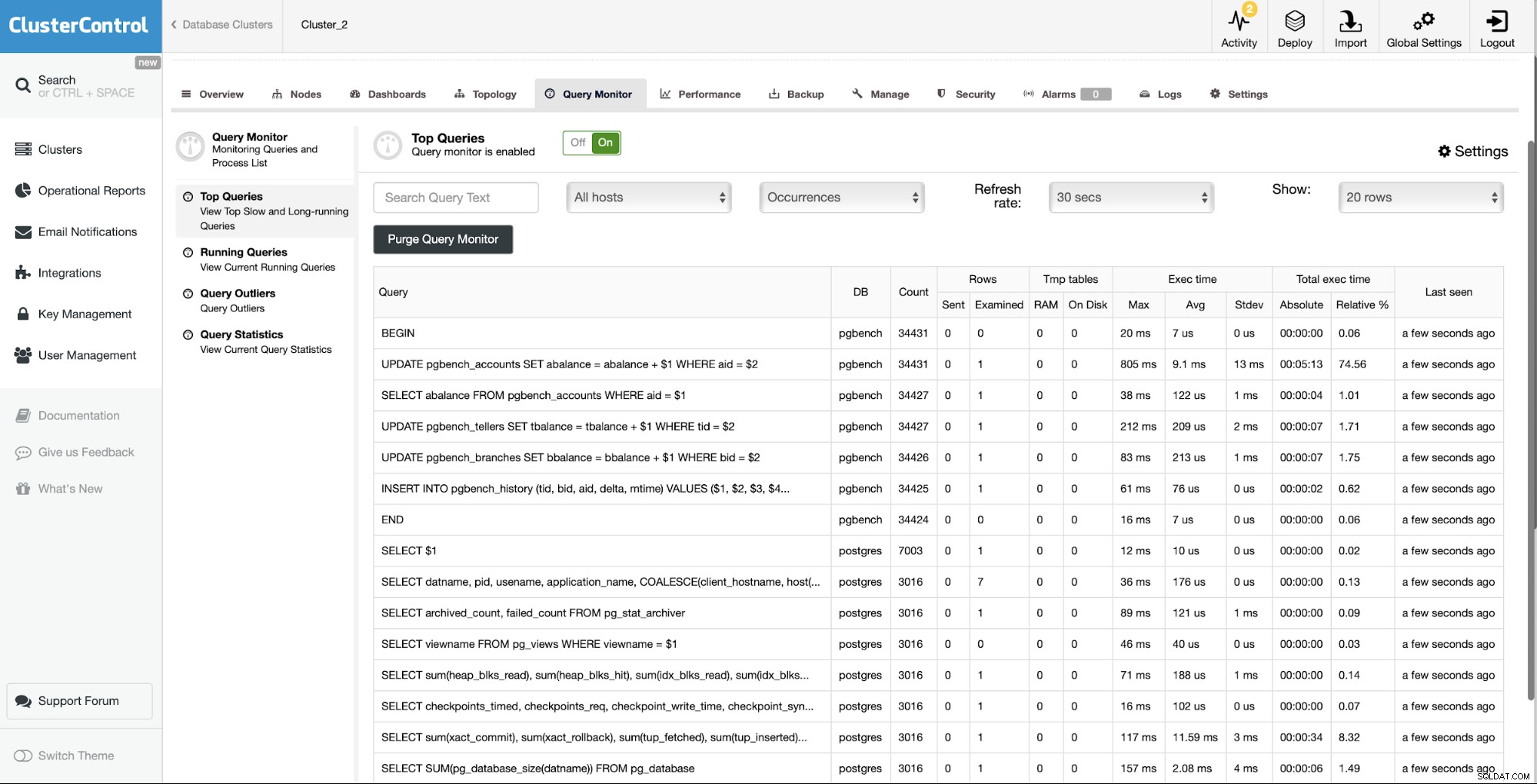
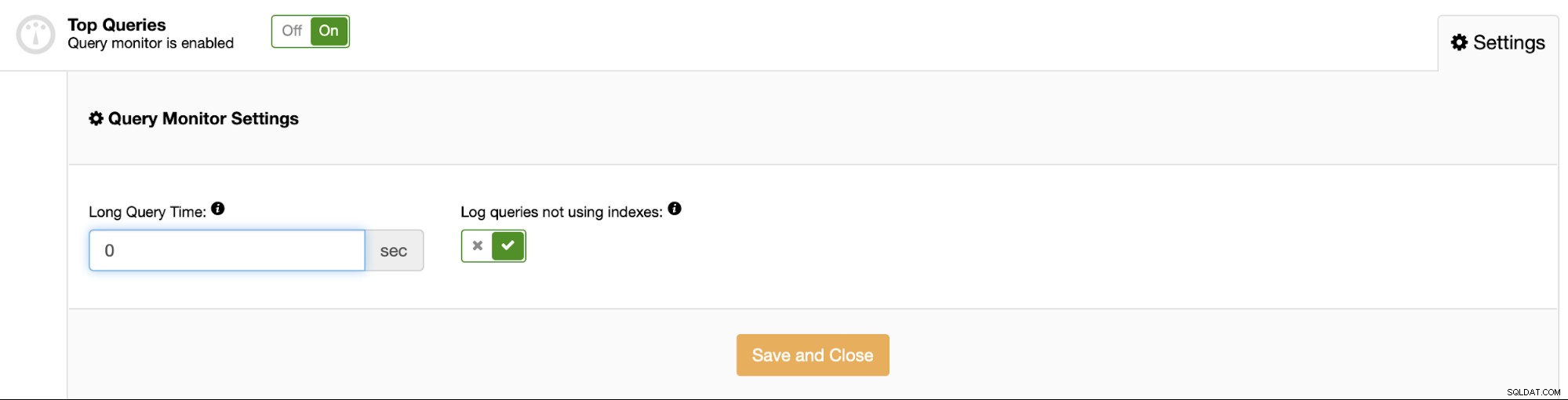
जैसा कि आप देख सकते हैं, यह क्वेरी निष्पादन के बारे में डेटा एकत्र करता है - पंक्तियां भेजी जाती हैं और जांच की, निष्पादन समय के आँकड़े और इतने पर। इसके साथ आप सबसे महंगे प्रश्नों को आसानी से इंगित कर सकते हैं, और देख सकते हैं कि औसत और अधिकतम निष्पादन समय कैसा दिखता है। डिफ़ॉल्ट रूप से ClusterControl उन प्रश्नों को एकत्रित करता है जिन्हें पूर्ण होने में 0.5 सेकंड से अधिक समय लगता है, आप इसे सेटिंग में बदल सकते हैं:
निष्कर्ष
यह संक्षिप्त ब्लॉग किसी भी तरह से उन सभी पहलुओं और उपकरणों को शामिल नहीं करता है जो PostgreSQL में क्वेरी प्रदर्शन समस्याओं को पहचानने और हल करने में सहायक होते हैं। हमें उम्मीद है कि यह एक अच्छी शुरुआत है और इससे आपको यह समझने में मदद मिलेगी कि आप धीमी क्वेरी के मूल कारण का पता लगाने के लिए क्या कर सकते हैं।