PostgreSQL में मेमोरी प्रबंधन डेटाबेस सर्वर के प्रदर्शन को बेहतर बनाने के लिए महत्वपूर्ण है। PostgreSQL कॉन्फ़िगरेशन फ़ाइल (postgres.conf) डेटाबेस सर्वर के कॉन्फ़िगरेशन का प्रबंधन करती है। यह पैरामीटर के डिफ़ॉल्ट मानों का उपयोग करता है, लेकिन हम इन मानों को कार्यभार और ऑपरेटिंग वातावरण को बेहतर ढंग से प्रतिबिंबित करने के लिए बदल सकते हैं।
इस ब्लॉग में, हम इन स्मृति संबंधी मापदंडों को कवर करेंगे। लेकिन शुरू करने से पहले, आइए PostgreSQL में मेमोरी आर्किटेक्चर पर एक नज़र डालते हैं।
मेमोरी आर्किटेक्चर
PostgreSQL में मेमोरी को दो श्रेणियों में वर्गीकृत किया जा सकता है:
- स्थानीय मेमोरी क्षेत्र:यह प्रत्येक बैकएंड प्रक्रिया द्वारा अपने स्वयं के उपयोग के लिए आवंटित किया जाता है।
- साझा स्मृति क्षेत्र:इसका उपयोग PostgreSQL सर्वर की सभी प्रक्रियाओं द्वारा किया जाता है।
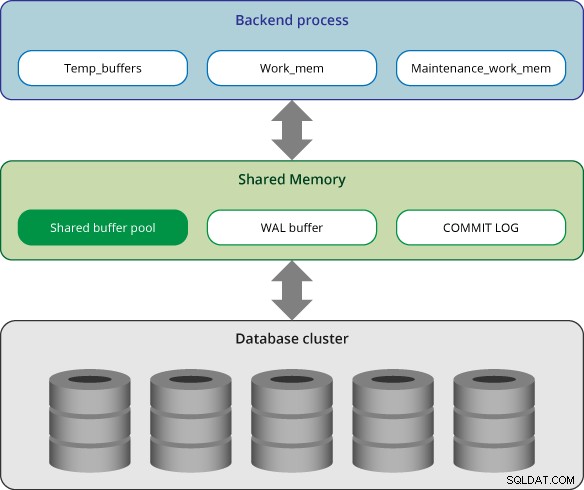
स्थानीय मेमोरी क्षेत्र
PostgreSQL में, प्रत्येक बैकएंड प्रक्रिया क्वेरी प्रोसेसिंग के लिए स्थानीय मेमोरी आवंटित करती है; प्रत्येक क्षेत्र को उप-क्षेत्रों में विभाजित किया गया है जिनके आकार या तो निश्चित हैं या परिवर्तनशील हैं।
उप-क्षेत्र इस प्रकार हैं।
वर्क_मेम
निष्पादक इस क्षेत्र का उपयोग ORDER BY और DISTINCT संचालन द्वारा टुपल्स को सॉर्ट करने के लिए करता है। यह मर्ज-जॉइन और हैश-जॉइन ऑपरेशंस द्वारा टेबल में शामिल होने के लिए भी इसका इस्तेमाल करता है।
रखरखाव_कार्य_मेम
इस पैरामीटर का उपयोग कुछ प्रकार के रखरखाव कार्यों (VACUUM, REINDEX) के लिए किया जाता है।
Temp_buffers
निष्पादक इस क्षेत्र का उपयोग अस्थायी तालिकाओं को संग्रहीत करने के लिए करता है।
साझा स्मृति क्षेत्र
साझा स्मृति क्षेत्र PostgreSQL सर्वर द्वारा आवंटित किया जाता है जब यह शुरू होता है। यह क्षेत्र कई निश्चित आकार के उप-क्षेत्रों में विभाजित है।
साझा बफर पूल
PostgreSQL टेबल और इंडेक्स के भीतर पेजों को लगातार स्टोरेज से साझा बफर पूल में लोड करता है, और फिर सीधे उन पर काम करता है।
वाल बफर
PostgreSQL यह सुनिश्चित करने के लिए WAL (आगे लॉग लिखें) तंत्र का समर्थन करता है कि सर्वर विफलता के बाद कोई डेटा खो नहीं जाता है। WAL डेटा वास्तव में PostgreSQL में एक लेन-देन लॉग है और WAL बफ़र, WAL डेटा को स्थायी संग्रहण में लिखने से पहले उसका एक बफ़रिंग क्षेत्र है।
लॉग कमिट करें
प्रतिबद्ध लॉग (सीएलओजी) सभी लेनदेन की स्थिति रखता है, और समवर्ती नियंत्रण तंत्र का हिस्सा है। प्रतिबद्ध लॉग साझा मेमोरी को आवंटित किया जाता है और पूरे लेनदेन प्रसंस्करण में उपयोग किया जाता है।
PostgreSQL निम्नलिखित चार लेन-देन की स्थिति को परिभाषित करता है।
- IN_PROGRESS
- प्रतिबद्ध
- निरस्त
- उप-प्रतिबद्ध
PostgreSQL मेमोरी पैरामीटर्स को ट्यून करना
कुछ महत्वपूर्ण पैरामीटर हैं जो PostgreSQL में मेमोरी प्रबंधन के लिए अनुशंसित हैं। आपको निम्नलिखित बातों का ध्यान रखना चाहिए।
साझा_बफ़र
यह पैरामीटर साझा मेमोरी बफ़र्स के लिए उपयोग की जाने वाली मेमोरी की मात्रा को निर्दिष्ट करता है। Shared_buffers पैरामीटर यह निर्धारित करता है कि कैशिंग डेटा के लिए सर्वर को कितनी मेमोरी समर्पित है। Shared_buffers का डिफ़ॉल्ट मान आमतौर पर 128 मेगाबाइट (128MB) होता है।
इस पैरामीटर का डिफ़ॉल्ट मान बहुत कम है क्योंकि पुराने सोलारिस संस्करणों और एसजीआई जैसे कुछ प्लेटफार्मों पर, बड़े मूल्यों वाले कर्नेल को पुन:संकलित करने जैसी आक्रामक कार्रवाई की आवश्यकता होती है। आधुनिक Linux सिस्टम पर भी, कर्नेल पहले कर्नेल सेटिंग्स को समायोजित किए बिना साझा_बफ़र्स को 32MB से अधिक पर सेट करने की अनुमति नहीं देगा।
PostgreSQL 9.4 और बाद के संस्करणों में तंत्र बदल गया है, इसलिए कर्नेल सेटिंग्स को वहां समायोजित करने की आवश्यकता नहीं होगी।
यदि डेटाबेस सर्वर पर उच्च भार है, तो उच्च मान सेट करने से प्रदर्शन में सुधार होगा।
यदि आपके पास 1GB या अधिक RAM वाला एक समर्पित DB सर्वर है, तो साझा_बफ़र कॉन्फ़िगरेशन पैरामीटर के लिए एक उचित प्रारंभिक मान आपके सिस्टम की मेमोरी का 25% है।
Shared_buffers का डिफ़ॉल्ट मान =128 एमबी। परिवर्तन के लिए PostgreSQL सर्वर के पुनरारंभ की आवश्यकता है।
Shared_buffers सेट करने की सामान्य अनुशंसा इस प्रकार है।
- 2GB मेमोरी से कम, शेयर्ड_बफ़र्स का मान कुल सिस्टम मेमोरी के 20% पर सेट करें।
- 32GB मेमोरी से कम, Shared_buffers का मान कुल सिस्टम मेमोरी के 25% पर सेट करें।
- 32GB मेमोरी से ऊपर, Shared_buffers का मान 8GB पर सेट करें
वर्क_मेम
यह पैरामीटर अस्थायी डिस्क फ़ाइलों को लिखने से पहले आंतरिक सॉर्ट संचालन और हैश टेबल द्वारा उपयोग की जाने वाली मेमोरी की मात्रा को निर्दिष्ट करता है। यदि बहुत सारे जटिल प्रकार हो रहे हैं, और आपके पास पर्याप्त मेमोरी है, तो वर्क_मेम पैरामीटर को बढ़ाने से PostgreSQL बड़े इन-मेमोरी प्रकार कर सकता है जो डिस्क आधारित समकक्षों की तुलना में तेज़ होगा।
ध्यान दें कि एक जटिल क्वेरी के लिए, कई सॉर्ट या हैश ऑपरेशन समानांतर में चल सकते हैं। अस्थायी फ़ाइलों में डेटा लिखना शुरू करने से पहले प्रत्येक ऑपरेशन को उतनी ही मेमोरी का उपयोग करने की अनुमति दी जाएगी जितनी यह मान निर्दिष्ट करता है। एक संभावना है कि कई सत्र एक साथ इस तरह के संचालन कर रहे होंगे। इसलिए, उपयोग की गई कुल मेमोरी work_mem पैरामीटर के मान से कई गुना अधिक हो सकती है।
कृपया याद रखें कि सही मूल्य चुनते समय। सॉर्ट ऑपरेशंस का उपयोग ORDER BY, DISTINCT और मर्ज जॉइन के लिए किया जाता है। हैश टेबल का उपयोग हैश जॉइन, आईएन सबक्वेरी के हैश आधारित प्रोसेसिंग और हैश आधारित एग्रीगेशन में किया जाता है।
पैरामीटर log_temp_files का उपयोग सॉर्ट, हैश और अस्थायी फ़ाइलों को लॉग करने के लिए किया जा सकता है जो यह पता लगाने में उपयोगी हो सकता है कि मेमोरी में फ़िट करने के बजाय डिस्क पर सॉर्ट हो रहे हैं या नहीं। आप EXPLAIN ANALYZE योजनाओं का उपयोग करके डिस्क पर स्पिलिंग के प्रकारों की जांच कर सकते हैं। उदाहरण के लिए, EXPLAIN ANALYZE के आउटपुट में, यदि आप इस तरह की लाइन देखते हैं:“सॉर्ट मेथड:एक्सटर्नल मर्ज डिस्क:7528kB ”, कम से कम 8MB का वर्क_मेम इंटरमीडिएट डेटा को मेमोरी में रखेगा और क्वेरी प्रतिक्रिया समय में सुधार करेगा।
Work_mem का डिफ़ॉल्ट मान =4MB.
Work_mem सेट करने की सामान्य अनुशंसा इस प्रकार है।
- निम्न मान से प्रारंभ करें:32-64MB
- फिर लॉग में 'अस्थायी फ़ाइल' पंक्तियों की तलाश करें
- सबसे बड़ी अस्थायी फ़ाइल के 2-3 गुना पर सेट करें
रखरखाव _work_mem
यह पैरामीटर रखरखाव संचालन जैसे VACUUM, CREATE INDEX और ALTER TABLE ADD FOREIGN KEY द्वारा उपयोग की जाने वाली मेमोरी की अधिकतम मात्रा को निर्दिष्ट करता है। चूंकि इनमें से केवल एक ऑपरेशन को डेटाबेस सत्र द्वारा एक समय में निष्पादित किया जा सकता है और एक PostgreSQL इंस्टॉलेशन में उनमें से कई एक साथ नहीं चल रहे हैं, इसलिए रखरखाव_वर्क_मेम का मान वर्क_मेम से काफी बड़ा सेट करना सुरक्षित है।
बड़ा मान सेट करने से डेटाबेस डंप को वैक्यूम करने और पुनर्स्थापित करने के प्रदर्शन में सुधार हो सकता है।
यह याद रखना आवश्यक है कि जब ऑटोवैक्यूम चलता है, तो autovacuum_max_workers बार तक यह मेमोरी आवंटित की जा सकती है, इसलिए सावधान रहें कि डिफ़ॉल्ट मान बहुत अधिक सेट न करें।
मेनटेनेंस_वर्क_मेम का डिफ़ॉल्ट मान =64MB.
मेनटेनेंस_वर्क_मेम सेट करने की सामान्य अनुशंसा इस प्रकार है।
- सिस्टम मेमोरी का 10% मान 1GB तक सेट करें
- यदि आपको VACUUM की समस्या हो रही है, तो आप इसे और भी ऊंचा सेट कर सकते हैं
प्रभावी_कैश_आकार
प्रभावी_कैश_साइज को इस अनुमान पर सेट किया जाना चाहिए कि ऑपरेटिंग सिस्टम और डेटाबेस के भीतर ही डिस्क कैशिंग के लिए कितनी मेमोरी उपलब्ध है। यह एक दिशानिर्देश है कि आप ऑपरेटिंग सिस्टम और पोस्टग्रेएसक्यूएल बफर कैश में कितनी मेमोरी उपलब्ध होने की उम्मीद करते हैं, आवंटन नहीं।
PostgreSQL क्वेरी प्लानर इस मान का उपयोग यह पता लगाने के लिए करता है कि यह जिन योजनाओं पर विचार कर रहा है, वे RAM में फिट होने की उम्मीद करेंगे या नहीं। यदि यह बहुत कम सेट किया गया है, तो इंडेक्स का उपयोग क्वेरी को निष्पादित करने के लिए नहीं किया जा सकता है जिस तरह से आप उम्मीद करेंगे। चूंकि अधिकांश यूनिक्स सिस्टम कैशिंग करते समय काफी आक्रामक होते हैं, एक समर्पित डेटाबेस सर्वर पर उपलब्ध रैम का कम से कम 50% कैश्ड डेटा से भरा होगा।
प्रभावी_कैश_साइज के लिए सामान्य अनुशंसा इस प्रकार है।
- उपलब्ध फ़ाइल सिस्टम कैश की मात्रा पर मान सेट करें
- यदि आप नहीं जानते हैं, तो मान को कुल सिस्टम मेमोरी के 50% पर सेट करें
प्रभावी_कैश_साइज़ का डिफ़ॉल्ट मान =4GB.
Temp_buffers
यह पैरामीटर प्रत्येक डेटाबेस सत्र द्वारा उपयोग किए जाने वाले अस्थायी बफ़र्स की अधिकतम संख्या निर्धारित करता है। सत्र स्थानीय बफ़र्स का उपयोग केवल अस्थायी तालिकाओं तक पहुँच के लिए किया जाता है। इस पैरामीटर की सेटिंग अलग-अलग सत्रों में बदली जा सकती है लेकिन सत्र के भीतर अस्थायी तालिकाओं के पहले उपयोग से पहले।
PostgreSQL डेटाबेस प्रत्येक सत्र की अस्थायी तालिकाओं को रखने के लिए इस मेमोरी क्षेत्र का उपयोग करता है, कनेक्शन बंद होने पर इन्हें साफ़ कर दिया जाएगा।
Temp_buffer का डिफ़ॉल्ट मान =8MB.
निष्कर्ष
मेमोरी आर्किटेक्चर को समझना और उपयुक्त मापदंडों को ट्यून करना प्रदर्शन को बेहतर बनाने के लिए महत्वपूर्ण है। यह उच्च कार्यभार प्रणालियों के लिए विशेष रूप से आवश्यक है। अधिक सामान्य प्रदर्शन ट्यूनिंग युक्तियों के लिए, कृपया PostgreSQL के लिए इस प्रदर्शन चीट शीट की समीक्षा करें।