पैरामीटर सूँघना
क्वेरी पैरामीटराइज़ेशन कैश्ड निष्पादन योजनाओं के पुन:उपयोग को बढ़ावा देता है, जिससे अनावश्यक संकलन से बचा जाता है, और योजना कैश में तदर्थ प्रश्नों की संख्या कम हो जाती है।
ये सभी अच्छी चीजें हैं, प्रदान की गई पैरामीटर की जा रही क्वेरी को वास्तव में विभिन्न पैरामीटर मानों के लिए समान कैश्ड निष्पादन योजना का उपयोग करना चाहिए। एक पैरामीटर मान के लिए कुशल निष्पादन योजना नहीं . हो सकती है अन्य संभावित पैरामीटर मानों के लिए एक अच्छा विकल्प बनें।
जब पैरामीटर सूँघना सक्षम होता है (डिफ़ॉल्ट), SQL सर्वर संकलन समय पर मौजूद विशेष पैरामीटर मानों के आधार पर एक निष्पादन योजना चुनता है। निहित धारणा यह है कि पैरामीटरयुक्त कथनों को सबसे सामान्य पैरामीटर मानों के साथ निष्पादित किया जाता है। यह काफी उचित (यहां तक कि स्पष्ट) लगता है और वास्तव में यह अक्सर अच्छा काम करता है।
कैश्ड योजना का स्वत:पुनर्संकलन होने पर कोई समस्या उत्पन्न हो सकती है। सभी प्रकार के कारणों के लिए एक पुनर्संकलन ट्रिगर किया जा सकता है, उदाहरण के लिए क्योंकि कैश्ड योजना द्वारा उपयोग किया गया एक इंडेक्स गिरा दिया गया है (एक सटीकता पुनर्संकलन) या क्योंकि सांख्यिकीय जानकारी बदल गई है (एक इष्टतमता पुन:संकलित करें)।
जो भी सटीक कारण हो योजना के पुनर्संकलन की संभावना है कि एक असामान्य मान नई योजना के जनरेट होने के समय एक पैरामीटर के रूप में पारित किया जा रहा है। इसके परिणामस्वरूप एक नया कैश्ड प्लान हो सकता है (सूँघने वाले एटिपिकल पैरामीटर मान के आधार पर) जो अधिकांश निष्पादन के लिए अच्छा नहीं है जिसके लिए इसका पुन:उपयोग किया जाएगा।
यह भविष्यवाणी करना आसान नहीं है कि किसी विशेष निष्पादन योजना को कब पुन:संकलित किया जाएगा (उदाहरण के लिए, क्योंकि आंकड़े पर्याप्त रूप से बदल गए हैं) जिसके परिणामस्वरूप एक अच्छी गुणवत्ता वाली पुन:प्रयोज्य योजना को अचानक असामान्य पैरामीटर मानों के लिए अनुकूलित एक पूरी तरह से अलग योजना द्वारा प्रतिस्थापित किया जा सकता है।
ऐसा ही एक परिदृश्य तब होता है जब असामान्य मान अत्यधिक चयनात्मक होता है, जिसके परिणामस्वरूप एक योजना छोटी संख्या में पंक्तियों के लिए अनुकूलित होती है। ऐसी योजनाएं अक्सर सिंगल-थ्रेडेड निष्पादन, नेस्टेड लूप जॉइन और लुकअप का उपयोग करती हैं। जब इस योजना का विभिन्न पैरामीटर मानों के लिए पुन:उपयोग किया जाता है जो बहुत बड़ी संख्या में पंक्तियाँ उत्पन्न करते हैं, तो गंभीर प्रदर्शन समस्याएँ उत्पन्न हो सकती हैं।
पैरामीटर सूँघना अक्षम करना
दस्तावेज़ ट्रेस फ़्लैग 4136 का उपयोग करके पैरामीटर सूँघने को अक्षम किया जा सकता है। ट्रेस फ़्लैग प्रति-क्वेरी के लिए भी समर्थित है QUERYTRACEON . के माध्यम से उपयोग करें प्रश्न संकेत। दोनों SQL Server 2005 सर्विस पैक 4 से आगे (और अगर आप सर्विस पैक 3 में संचयी अद्यतन लागू करते हैं तो थोड़ा पहले) से लागू होते हैं।
SQL सर्वर 2016 से शुरू होकर, पैरामीटर सूँघने को डेटाबेस स्तर पर भी अक्षम किया जा सकता है , PARAMETER_SNIFFING . का उपयोग करके ALTER DATABASE SCOPED CONFIGURATION ।
जब पैरामीटर सूँघना अक्षम होता है, तो SQL सर्वर औसत वितरण का उपयोग करता है निष्पादन योजना चुनने के लिए आँकड़े।
यह भी एक उचित दृष्टिकोण की तरह लगता है (और उस स्थिति से बचने में मदद कर सकता है जहां योजना को असामान्य रूप से चुनिंदा पैरामीटर मान के लिए अनुकूलित किया गया है), लेकिन यह एक आदर्श रणनीति भी नहीं है:'औसत' मूल्य के लिए अनुकूलित एक योजना अच्छी तरह से समाप्त हो सकती है आमतौर पर देखे जाने वाले पैरामीटर मानों के लिए गंभीरता से उप-इष्टतम।
एक निष्पादन योजना पर विचार करें जिसमें मेमोरी-खपत ऑपरेटर जैसे सॉर्ट और हैश शामिल हैं। चूंकि क्वेरी निष्पादन शुरू होने से पहले स्मृति आरक्षित है, औसत वितरण मूल्यों के आधार पर एक पैरामीटरयुक्त योजना tempdb तक फैल सकती है सामान्य पैरामीटर मानों के लिए जो अपेक्षित अनुकूलक से अधिक डेटा उत्पन्न करते हैं।
मेमोरी रिजर्वेशन आमतौर पर क्वेरी निष्पादन के दौरान नहीं बढ़ सकता है, भले ही सर्वर के पास कितनी भी फ्री मेमोरी हो। पैरामीटर को सूँघने से कुछ अनुप्रयोगों को लाभ होता है (उदाहरण के लिए डायनेमिक्स एएक्स प्रदर्शन टीम द्वारा यह संग्रह पोस्ट देखें)।
अधिकांश कार्यभार के लिए, पैरामीटर को पूरी तरह से सूँघना अक्षम करना गलत समाधान . है , और एक आपदा भी हो सकती है। पैरामीटर सूँघना एक अनुमानी अनुकूलन है:यह अधिकांश प्रणालियों पर औसत मानों का उपयोग करने से बेहतर काम करता है, अधिकांश समय।
क्वेरी संकेत
SQL सर्वर पैरामीटर सूँघने के व्यवहार को ट्यून करने के लिए कई प्रकार के क्वेरी संकेत और अन्य विकल्प प्रदान करता है:
- द
OPTIMIZE FOR (@parameter = value)क्वेरी संकेत एक विशिष्ट मूल्य के आधार पर एक पुन:प्रयोज्य योजना बनाता है। OPTIMIZE FOR (@parameter UNKNOWN)किसी विशेष पैरामीटर के लिए औसत वितरण आँकड़ों का उपयोग करता है।OPTIMIZE FOR UNKNOWNसभी मापदंडों के लिए औसत वितरण का उपयोग करता है (ट्रेस फ्लैग 4136 के समान प्रभाव)।WITH RECOMPILEसंग्रहीत कार्यविधि विकल्प प्रत्येक निष्पादन के लिए एक नई प्रक्रिया योजना संकलित करता है।- द
OPTION (RECOMPILE)क्वेरी संकेत एक व्यक्तिगत विवरण के लिए एक नई योजना संकलित करता है।
“पैरामीटर छुपाने” . की पुरानी तकनीक (स्थानीय चर के लिए प्रक्रिया पैरामीटर निर्दिष्ट करना, और इसके बजाय चर को संदर्भित करना) का वही प्रभाव है जो निर्दिष्ट करने के लिए OPTIMIZE FOR UNKNOWN . यह SQL Server 2008 से पहले के उदाहरणों पर उपयोगी हो सकता है (OPTIMIZE FOR 2008 के लिए संकेत नया था)।
यह तर्क दिया जा सकता है कि हर पैरामीटर मानों के प्रति संवेदनशीलता के लिए पैरामीटरयुक्त कथन की जाँच की जानी चाहिए, और या तो अकेला छोड़ दिया जाना चाहिए (यदि डिफ़ॉल्ट व्यवहार अच्छी तरह से काम करता है) या ऊपर दिए गए विकल्पों में से किसी एक का उपयोग करके स्पष्ट रूप से संकेत दिया गया है।
यह व्यवहार में शायद ही कभी किया जाता है, आंशिक रूप से क्योंकि सभी संभावित पैरामीटर मानों के लिए एक व्यापक विश्लेषण करना समय लेने वाला हो सकता है और इसके लिए काफी उन्नत कौशल की आवश्यकता होती है। अक्सर, ऐसा कोई विश्लेषण नहीं किया जाता है और पैरामीटर-संवेदनशीलता समस्याओं को संबोधित किया जाता है और जब वे उत्पादन में होते हैं।
पूर्व विश्लेषण की यह कमी शायद एक मुख्य कारण है कि पैरामीटर सूँघने की खराब प्रतिष्ठा है। यह समस्याओं के उत्पन्न होने की संभावना से अवगत होने के लिए भुगतान करता है, और उन बयानों पर कम से कम एक त्वरित विश्लेषण करने के लिए जो एक असामान्य पैरामीटर मान के साथ पुन:संकलित होने पर प्रदर्शन समस्याओं का कारण बन सकते हैं।
पैरामीटर क्या है?
कुछ लोग कहेंगे कि एक SELECT स्थानीय चर को संदर्भित करने वाला कथन एक “पैरामीटरयुक्त कथन” . है प्रकार की, लेकिन वह परिभाषा नहीं है जो SQL सर्वर उपयोग करता है।
एक उचित संकेत है कि एक बयान पैरामीटर का उपयोग करता है योजना गुणों को देखकर पाया जा सकता है (देखें पैरामीटर संतरी वन प्लान एक्सप्लोरर में टैब। या SSMS में क्वेरी प्लान रूट नोड पर क्लिक करें, गुण खोलें विंडो, और विस्तृत करें पैरामीटर सूची नोड):
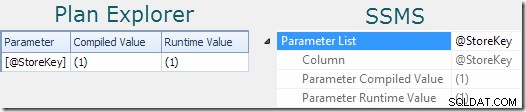
'संकलित मूल्य' कैश्ड योजना को संकलित करने के लिए उपयोग किए गए पैरामीटर का सूँघने वाला मान दिखाता है। 'रनटाइम वैल्यू' योजना में कैप्चर किए गए विशेष निष्पादन पर पैरामीटर के मूल्य को दर्शाता है।
इनमें से कोई भी गुण अलग-अलग परिस्थितियों में खाली या गायब हो सकता है। यदि कोई क्वेरी पैरामीटरयुक्त नहीं है, तो गुण बस गायब हो जाएंगे।
सिर्फ इसलिए कि SQL सर्वर में कुछ भी सरल नहीं है, ऐसी स्थितियां हैं जहां पैरामीटर सूची को पॉप्युलेट किया जा सकता है, लेकिन कथन अभी भी पैरामीटरयुक्त नहीं है। यह तब हो सकता है जब SQL सर्वर सरल पैरामीटराइजेशन का प्रयास करता है (बाद में चर्चा की गई) लेकिन यह तय करता है कि प्रयास "असुरक्षित" है। उस स्थिति में, पैरामीटर मार्कर मौजूद रहेंगे, लेकिन निष्पादन योजना वास्तव में पैरामीटरयुक्त नहीं है।
सूँघना केवल संग्रहित प्रक्रियाओं के लिए नहीं है
पैरामीटर सूँघना तब भी होता है जब एक बैच को sp_executesql का उपयोग करके पुन:उपयोग के लिए स्पष्ट रूप से पैरामीटरकृत किया जाता है ।
उदाहरण के लिए:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'K%';
अनुकूलक @NameLike के सूंघे गए मान के आधार पर एक निष्पादन योजना चुनता है पैरामीटर। पैरामीटर मान “K%” का Product . में बहुत कम पंक्तियों से मेल खाने का अनुमान है तालिका, इसलिए अनुकूलक एक नेस्टेड लूप जॉइन और कुंजी लुकअप रणनीति चुनता है:
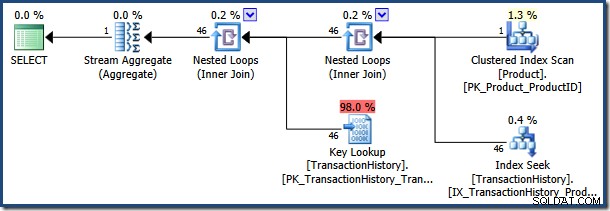

"[H-R]%" के पैरामीटर मान के साथ कथन को फिर से निष्पादित करना (जो कई और पंक्तियों से मेल खाएगा) कैश्ड पैरामीटरयुक्त योजना का पुन:उपयोग करता है:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'[H-R]%';
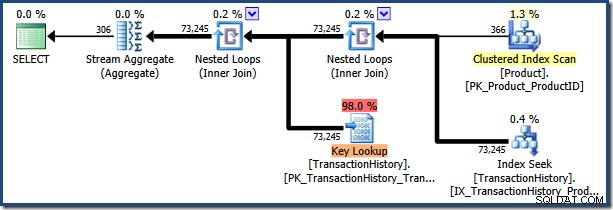

एडवेंचरवर्क्स इसे एक प्रदर्शन आपदा बनाने के लिए नमूना डेटाबेस बहुत छोटा है, लेकिन यह योजना निश्चित रूप से दूसरे पैरामीटर मान के लिए इष्टतम नहीं है।
हम प्लान कैश को साफ़ करके और दूसरी क्वेरी को फिर से निष्पादित करके ऑप्टिमाइज़र द्वारा चुनी गई योजना देख सकते हैं:
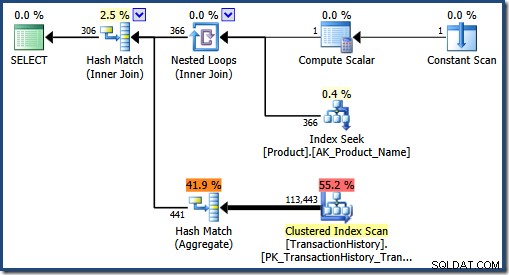

बड़ी संख्या में अपेक्षित मैचों के साथ, ऑप्टिमाइज़र यह निर्धारित करता है कि हैश जॉइन और हैश एकत्रीकरण बेहतर रणनीतियाँ हैं।
T-SQL फंक्शन्स
पैरामीटर सूँघना टी-एसक्यूएल फ़ंक्शंस के साथ भी होता है, हालाँकि जिस तरह से निष्पादन योजनाएँ तैयार की जाती हैं, वह इसे देखना अधिक कठिन बना सकती है।
सामान्य रूप से टी-एसक्यूएल स्केलर और मल्टी-स्टेटमेंट फ़ंक्शंस से बचने के अच्छे कारण हैं, इसलिए केवल शैक्षिक उद्देश्यों के लिए, यहां हमारी टेस्ट क्वेरी का एक टी-एसक्यूएल मल्टी-स्टेटमेंट टेबल-वैल्यूड फंक्शन वर्जन है:
CREATE FUNCTION dbo.F
(@NameLike nvarchar(50))
RETURNS @Result TABLE
(
ProductID integer NOT NULL PRIMARY KEY,
Name nvarchar(50) NOT NULL,
TotalQty integer NOT NULL
)
WITH SCHEMABINDING
AS
BEGIN
INSERT @Result
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
RETURN;
END; निम्न क्वेरी 'K' से शुरू होने वाले उत्पाद नामों की जानकारी प्रदर्शित करने के लिए फ़ंक्शन का उपयोग करती है:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; एम्बेडेड फ़ंक्शन के साथ पैरामीटर को सूँघना अधिक कठिन है क्योंकि SQL सर्वर प्रत्येक फ़ंक्शन आमंत्रण के लिए एक अलग पोस्ट-निष्पादन (वास्तविक) क्वेरी योजना नहीं देता है। फ़ंक्शन को एक ही कथन के भीतर कई बार कॉल किया जा सकता है, और यदि SSMS ने एकल क्वेरी के लिए एक लाख फ़ंक्शन कॉल प्लान प्रदर्शित करने का प्रयास किया तो उपयोगकर्ता प्रभावित नहीं होंगे।
इस डिज़ाइन निर्णय के परिणामस्वरूप, हमारी परीक्षण क्वेरी के लिए SQL सर्वर द्वारा लौटाई गई वास्तविक योजना बहुत उपयोगी नहीं है:
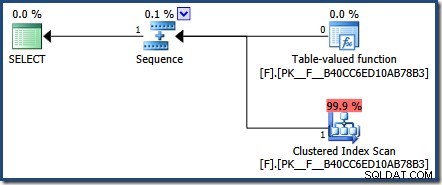
फिर भी, वहाँ हैं एम्बेडेड कार्यों के साथ कार्रवाई में पैरामीटर को सूँघते देखने के तरीके। मैंने यहां इस्तेमाल करने के लिए जो तरीका चुना है, वह है प्लान कैश का निरीक्षण करना:
SELECT
DEQS.plan_generation_num,
DEQS.execution_count,
DEQS.last_logical_reads,
DEQS.last_elapsed_time,
DEQS.last_rows,
DEQP.query_plan
FROM sys.dm_exec_query_stats AS DEQS
CROSS APPLY sys.dm_exec_sql_text(DEQS.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DEQS.plan_handle) AS DEQP
WHERE
DEST.objectid = OBJECT_ID(N'dbo.F', N'TF');
इस परिणाम से पता चलता है कि 2891 माइक्रोसेकंड बीत चुके समय के साथ 201 तार्किक रीड की लागत पर फ़ंक्शन योजना को एक बार निष्पादित किया गया है, और सबसे हालिया निष्पादन ने एक पंक्ति लौटा दी है। लौटाए गए XML योजना प्रतिनिधित्व से पता चलता है कि पैरामीटर मान था सूँघा:
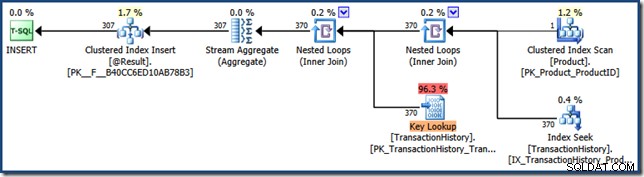

अब एक अलग पैरामीटर के साथ फिर से स्टेटमेंट चलाएँ:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'[H-R]%') AS Result; निष्पादन के बाद की योजना से पता चलता है कि 306 पंक्तियों को फ़ंक्शन द्वारा लौटाया गया था:
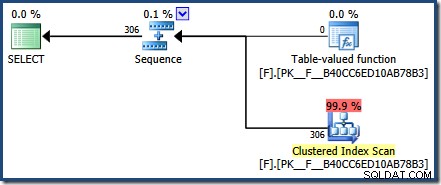
योजना कैश क्वेरी से पता चलता है कि फ़ंक्शन के लिए कैश्ड निष्पादन योजना का पुन:उपयोग किया गया है (execution_count =2):

यह पिछले रन की तुलना में बहुत अधिक संख्या में तार्किक रीड्स और एक लंबा बीता हुआ समय भी दिखाता है। यह नेस्टेड लूप और लुकअप योजना के पुन:उपयोग के अनुरूप है, लेकिन पूरी तरह से सुनिश्चित होने के लिए, पोस्ट-निष्पादन फ़ंक्शन योजना को विस्तारित ईवेंट का उपयोग करके कैप्चर किया जा सकता है। या एसक्यूएल सर्वर प्रोफाइलर उपकरण:
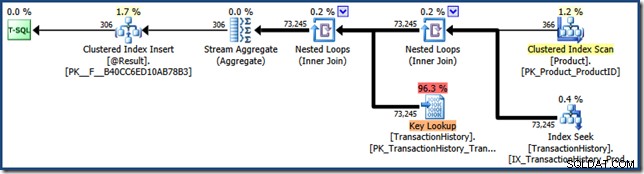

क्योंकि पैरामीटर सूँघना फ़ंक्शन पर लागू होता है, ये मॉड्यूल आमतौर पर संग्रहीत प्रक्रियाओं से जुड़े प्रदर्शन में समान अप्रत्याशित परिवर्तनों से पीड़ित हो सकते हैं।
उदाहरण के लिए, पहली बार किसी फ़ंक्शन को संदर्भित किया जाता है, एक योजना को कैश किया जा सकता है जो समांतरता का उपयोग नहीं करता है। पैरामीटर मानों के साथ बाद के निष्पादन जो समानांतरवाद से लाभान्वित होंगे (लेकिन कैश्ड सीरियल प्लान का पुन:उपयोग) अप्रत्याशित रूप से खराब प्रदर्शन दिखाएगा।
इस समस्या को पहचानना मुश्किल हो सकता है क्योंकि SQL सर्वर फ़ंक्शन कॉल के लिए अलग-अलग पोस्ट-निष्पादन योजनाओं को वापस नहीं करता है जैसा कि हमने देखा है। विस्तारित ईवेंट का उपयोग करना या प्रोफाइलर निष्पादन के बाद की योजनाओं को नियमित रूप से कैप्चर करना अत्यधिक संसाधन-गहन हो सकता है, इसलिए अक्सर उस तकनीक का उपयोग बहुत लक्षित तरीके से करना समझ में आता है। डिबगिंग फ़ंक्शन पैरामीटर-संवेदनशीलता मुद्दों के आसपास की कठिनाइयों का मतलब है कि फ़ंक्शन के उत्पादन को हिट करने से पहले विश्लेषण (और रक्षात्मक रूप से कोडिंग) करना और भी अधिक सार्थक है।
पैरामीटर-सूँघना ठीक उसी तरह काम करता है जैसे टी-एसक्यूएल स्केलर यूज़र-डिफ़ाइंड फ़ंक्शंस (जब तक कि इन-लाइन नहीं, SQL सर्वर 2019 पर आगे)। इन-लाइन तालिका-मूल्यवान फ़ंक्शन प्रत्येक आमंत्रण के लिए एक अलग निष्पादन योजना उत्पन्न नहीं करते हैं, क्योंकि (जैसा कि नाम से पता चलता है) ये संकलन से पहले कॉलिंग क्वेरी में इन-लाइन हैं।
स्निफ्ड NULLs से सावधान रहें
प्लान कैश साफ़ करें और अनुमानित . का अनुरोध करें (पूर्व-निष्पादन) परीक्षण क्वेरी के लिए योजना:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; आपको दो निष्पादन योजनाएं दिखाई देंगी, जिनमें से दूसरी फ़ंक्शन कॉल के लिए है:
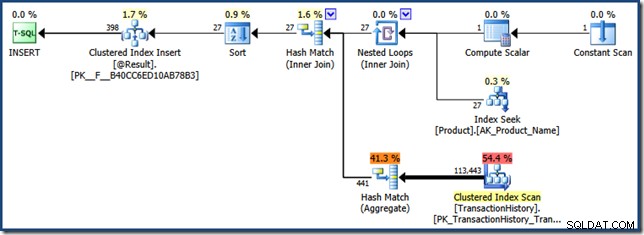
अनुमानित योजनाओं में एम्बेडेड फ़ंक्शंस के साथ सूँघने वाले पैरामीटर की एक सीमा का मतलब है कि पैरामीटर मान को NULL के रूप में सूँघ लिया गया है ("के%" नहीं):

2012 से पहले SQL सर्वर के संस्करणों में, यह योजना (NULL . के लिए अनुकूलित) पैरामीटर) पुन:उपयोग के लिए संचित . है . यह दुर्भाग्यपूर्ण है, क्योंकि NULL प्रतिनिधि पैरामीटर मान होने की संभावना नहीं है, और यह निश्चित रूप से क्वेरी में निर्दिष्ट मान नहीं था।
SQL सर्वर 2012 (और बाद में) "अनुमानित योजना" अनुरोध के परिणामस्वरूप योजनाओं को कैश नहीं करता है, हालांकि यह अभी भी NULL के लिए अनुकूलित फ़ंक्शन योजना प्रदर्शित करेगा। संकलन समय पर पैरामीटर मान।
सरल और जबरदस्ती Parameterization
एक तदर्थ टी-एसक्यूएल स्टेटमेंट जिसमें निरंतर शाब्दिक मान होते हैं, SQL सर्वर द्वारा पैरामीटर किया जा सकता है, या तो क्योंकि क्वेरी सरल पैरामीटर के लिए योग्य है या क्योंकि मजबूर पैरामीटर के लिए डेटाबेस विकल्प सक्षम है (या एक योजना गाइड का उपयोग उसी प्रभाव के लिए किया जाता है)।
इस तरह से पैरामीटरयुक्त एक बयान भी पैरामीटर सूँघने के अधीन है। निम्नलिखित क्वेरी सरल मानकीकरण के लिए योग्य है:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Heidestieg Straße 8664'; अनुमानित निष्पादन योजना सूँघने वाले पैरामीटर मान के आधार पर 2.5 पंक्तियों का अनुमान दिखाती है:
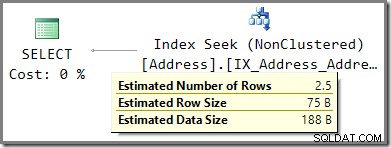
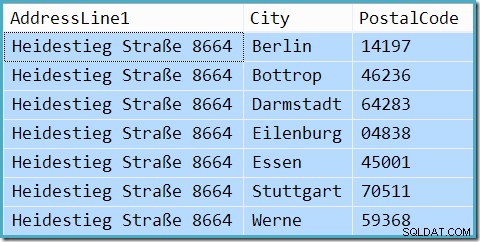
वास्तव में, क्वेरी 7 पंक्तियाँ लौटाती है (कार्डिनैलिटी का अनुमान सही नहीं है, यहाँ तक कि जहाँ मान सूँघे जाते हैं):
इस बिंदु पर, आप सोच रहे होंगे कि सबूत कहां है कि इस क्वेरी को पैरामीटर किया गया था, और परिणामी पैरामीटर मान सूँघा गया था। क्वेरी को दूसरी बार किसी भिन्न मान के साथ चलाएँ:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Winter der Böck 8550'; क्वेरी एक पंक्ति लौटाती है:

निष्पादन योजना से पता चलता है कि दूसरा निष्पादन पुन:उपयोग किया गया पैरामीटरयुक्त योजना जिसे एक सूँघने वाले मान का उपयोग करके संकलित किया गया था:
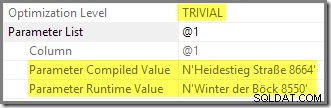
पैरामीटरीकरण और सूंघना अलग-अलग गतिविधियां हैं
एक एड-हॉक स्टेटमेंट को SQL सर्वर बिना के पैरामीटराइज़ किया जा सकता है पैरामीटर मान सूँघे जा रहे हैं।
प्रदर्शित करने के लिए, हम एक बैच के लिए पैरामीटर सूँघने को अक्षम करने के लिए ट्रेस फ्लैग 4136 का उपयोग कर सकते हैं जिसे सर्वर द्वारा पैरामीटर किया जाएगा:
DBCC FREEPROCCACHE;
DBCC TRACEON (4136);
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Heidestieg Straße 8664';
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Winter der Böck 8550';
GO
DBCC TRACEOFF (4136); स्क्रिप्ट का परिणाम उन बयानों में होता है जो पैरामीटरयुक्त होते हैं, लेकिन कार्डिनैलिटी अनुमान उद्देश्यों के लिए पैरामीटर मान को सूँघ नहीं लिया जाता है। इसे देखने के लिए, हम योजना कैश का निरीक्षण कर सकते हैं:
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
DECP.cacheobjtype,
DECP.objtype,
DECP.usecounts,
DECP.plan_handle,
parameterized_plan_handle =
DEQP.query_plan.value
(
'(//StmtSimple)[1]/@ParameterizedPlanHandle',
'NVARCHAR(100)'
)
FROM sys.dm_exec_cached_plans AS DECP
CROSS APPLY sys.dm_exec_sql_text(DECP.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DECP.plan_handle) AS DEQP
WHERE
DEST.[text] LIKE N'%AddressLine1%'
AND DEST.[text] NOT LIKE N'%XMLNAMESPACES%'; परिणाम तदर्थ प्रश्नों के लिए दो कैश प्रविष्टियां दिखाते हैं, जो पैरामीटरयुक्त (तैयार) क्वेरी योजना से पैरामीटरयुक्त योजना हैंडल से जुड़ी होती हैं।
पैरामीटरयुक्त योजना का दो बार उपयोग किया जाता है:

निष्पादन योजना अब एक अलग कार्डिनैलिटी अनुमान दिखाती है कि पैरामीटर सूँघना अक्षम है:
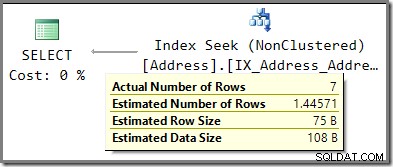
1.44571 पंक्तियों के अनुमान की तुलना उस 2.5 पंक्ति अनुमान से करें जब पैरामीटर सूँघना सक्षम किया गया था।
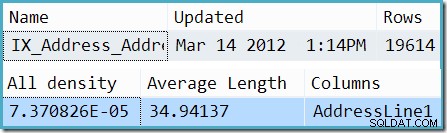
स्नीफिंग अक्षम होने पर, अनुमान AddressLine1 के बारे में औसत आवृत्ति जानकारी से प्राप्त होता है कॉलम। DBCC SHOW_STATISTICS . का एक उद्धरण विचाराधीन इंडेक्स के लिए आउटपुट दिखाता है कि इस संख्या की गणना कैसे की गई:तालिका में पंक्तियों की संख्या (19,614) को घनत्व (7.370826e-5) से गुणा करने पर 1.44571 पंक्ति अनुमान मिलता है।
साइड नोट: आमतौर पर यह माना जाता है कि एक अद्वितीय सूचकांक का उपयोग करके केवल पूर्णांक तुलना ही सरल मानदंड के लिए योग्य हो सकती है। मैंने इसका खंडन करने के लिए जानबूझकर इस उदाहरण (एक गैर-अद्वितीय अनुक्रमणिका का उपयोग करके एक स्ट्रिंग तुलना) को चुना।
RECOMPILE और OPTION (RECOMPILE) के साथ
जब एक पैरामीटर-संवेदनशीलता समस्या का सामना करना पड़ता है, तो मंचों और प्रश्नोत्तर साइटों पर सलाह का एक सामान्य टुकड़ा "पुन:संकलन का उपयोग करना" है (यह मानते हुए कि पहले प्रस्तुत किए गए अन्य ट्यूनिंग विकल्प अनुपयुक्त हैं)। दुर्भाग्य से, उस सलाह का अक्सर गलत अर्थ निकाला जाता है WITH RECOMPILE संग्रहीत प्रक्रिया के लिए विकल्प।
WITH RECOMPILE Using का उपयोग करना प्रभावी रूप से हमें SQL Server 2000 व्यवहार पर लौटाता है, जहां संपूर्ण संग्रहीत कार्यविधि प्रत्येक निष्पादन पर पुन:संकलित किया जाता है।
एक बेहतर विकल्प , SQL सर्वर 2005 और बाद में, OPTION (RECOMPILE) का उपयोग करना है केवल कथन . पर क्वेरी संकेत जो पैरामीटर-सूँघने की समस्या से ग्रस्त है। यह क्वेरी संकेत समस्याग्रस्त कथन . के पुनर्संकलन में परिणत होता है केवल। संग्रहीत कार्यविधि के भीतर अन्य कथनों के लिए निष्पादन योजना कैश की जाती है और सामान्य रूप से पुन:उपयोग की जाती है।
WITH RECOMPILE Using का उपयोग करना इसका मतलब यह भी है कि संग्रहित प्रक्रिया के लिए संकलित योजना कैश नहीं है। परिणामस्वरूप, DMVs जैसे sys.dm_exec_query_stats में कोई प्रदर्शन जानकारी नहीं रखी जाती है ।
इसके बजाय क्वेरी संकेत का उपयोग करने का अर्थ है कि एक संकलित योजना को कैश किया जा सकता है, और प्रदर्शन की जानकारी DMV में उपलब्ध है (हालाँकि यह सबसे हाल के निष्पादन तक सीमित है, केवल प्रभावित विवरण के लिए)।
कम से कम SQL Server 2008 चलाने वाले उदाहरणों के लिए OPTION (RECOMPILE) का उपयोग करके 2746 (संचयी अद्यतन 5 के साथ सर्विस पैक 1) का निर्माण करें एक और महत्वपूर्ण लाभ है WITH RECOMPILE . से अधिक :केवल OPTION (RECOMPILE) पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन को सक्षम करता है ।
पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन
सूँघने वाले पैरामीटर मान अनुकूलक को कार्डिनैलिटी अनुमान प्राप्त करने के लिए पैरामीटर मान का उपयोग करने की अनुमति देते हैं। दोनों WITH RECOMPILE और OPTION (RECOMPILE) प्रत्येक निष्पादन पर वास्तविक पैरामीटर मानों से गणना किए गए अनुमानों के साथ क्वेरी योजनाओं में परिणाम।
पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन इस प्रक्रिया को एक कदम आगे ले जाता है। क्वेरी पैरामीटर प्रतिस्थापित हैं क्वेरी पार्सिंग के दौरान शाब्दिक स्थिर मानों के साथ।
पार्सर आश्चर्यजनक रूप से जटिल सरलीकरण करने में सक्षम है, और बाद में क्वेरी अनुकूलन चीजों को और भी परिष्कृत कर सकता है। निम्नलिखित संग्रहीत कार्यविधि पर विचार करें, जिसमें WITH RECOMPILE . की सुविधा है विकल्प:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
WITH RECOMPILE
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC;
END; निम्नलिखित पैरामीटर मानों के साथ प्रक्रिया को दो बार निष्पादित किया जाता है:
EXECUTE dbo.P @NameLike = N'K%', @Sort = 1; GO EXECUTE dbo.P @NameLike = N'[H-R]%', @Sort = 4;
क्योंकि WITH RECOMPILE का उपयोग किया जाता है, प्रक्रिया प्रत्येक निष्पादन पर पूरी तरह से पुन:संकलित की जाती है। पैरामीटर मान स्निफ़्ड हैं हर बार, और अनुकूलक द्वारा कार्डिनैलिटी अनुमानों की गणना करने के लिए उपयोग किया जाता है।
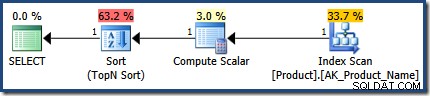
पहली प्रक्रिया निष्पादन की योजना 1 पंक्ति का अनुमान लगाते हुए बिल्कुल सही है:
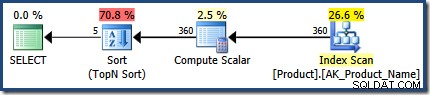
दूसरा निष्पादन 360 पंक्तियों का अनुमान लगाता है, जो रन टाइम में देखे गए 366 के बहुत करीब है:
दोनों योजनाएँ समान सामान्य निष्पादन रणनीति का उपयोग करती हैं:WHERE . को लागू करते हुए एक अनुक्रमणिका में सभी पंक्तियों को स्कैन करें खंड एक अवशिष्ट के रूप में विधेय; CASE की गणना करें ORDER BY . में प्रयुक्त एक्सप्रेशन खंड; और एक शीर्ष N क्रमित करें . निष्पादित करें CASE . के परिणाम पर अभिव्यक्ति।
OPTION (RECOMPILE)
अब OPTION (RECOMPILE) . का उपयोग करके संग्रहीत कार्यविधि को फिर से बनाएं WITH RECOMPILE . के बजाय क्वेरी संकेत :
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END; पहले के समान पैरामीटर मानों के साथ संग्रहीत कार्यविधि को दो बार निष्पादित करने से नाटकीय रूप से भिन्न . उत्पन्न होता है निष्पादन योजनाएं।
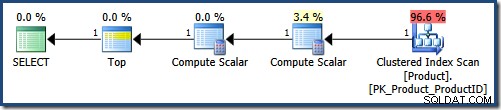
यह पहली निष्पादन योजना है ("K" से शुरू होने वाले नामों का अनुरोध करने वाले मापदंडों के साथ, ProductID द्वारा आदेशित किया गया है आरोही):
पार्सर एम्बेड करता है क्वेरी टेक्स्ट में पैरामीटर मान, जिसके परिणामस्वरूप निम्न मध्यवर्ती रूप प्राप्त होता है:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
'K%' IS NULL
OR Name LIKE 'K%'
ORDER BY
CASE WHEN 1 = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN 1 = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN 1 = 3 THEN Name ELSE NULL END ASC,
CASE WHEN 1 = 4 THEN Name ELSE NULL END DESC;
इसके बाद पार्सर आगे बढ़ता है, अंतर्विरोधों को दूर करता है और CASE . का पूरी तरह से मूल्यांकन करता है भाव। इसका परिणाम है:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
Name LIKE 'K%'
ORDER BY
ProductID ASC,
NULL DESC,
NULL ASC,
NULL DESC; यदि आप उस क्वेरी को सीधे SQL सर्वर पर सबमिट करने का प्रयास करते हैं, तो आपको एक त्रुटि संदेश प्राप्त होगा, क्योंकि स्थिर मान द्वारा ऑर्डर करने की अनुमति नहीं है। फिर भी, यह पार्सर द्वारा निर्मित रूप है। इसे आंतरिक रूप से अनुमति दी गई है क्योंकि यह पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन . को लागू करने के परिणामस्वरूप उत्पन्न हुआ है . सरलीकृत क्वेरी क्वेरी अनुकूलक के लिए जीवन को बहुत आसान बनाती है:
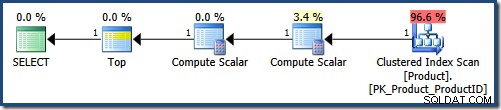
संकुल सूचकांक स्कैन LIKE को लागू करता है अवशिष्ट के रूप में विधेय। गणना स्केलर निरंतर NULL provides प्रदान करता है मूल्य। शीर्ष संकुल अनुक्रमणिका . द्वारा प्रदान किए गए क्रम में पहली 5 पंक्तियों को लौटाता है (एक प्रकार से परहेज)। एक आदर्श दुनिया में, क्वेरी ऑप्टिमाइज़र कंप्यूट स्केलर . को भी हटा देगा जो NULLs . को परिभाषित करता है , क्योंकि उनका उपयोग क्वेरी निष्पादन के दौरान नहीं किया जाता है।
दूसरा निष्पादन ठीक उसी प्रक्रिया का अनुसरण करता है, जिसके परिणामस्वरूप एक क्वेरी योजना होती है ("H" से "R" अक्षरों से शुरू होने वाले नामों के लिए, Name द्वारा आदेशित किया जाता है। अवरोही) इस तरह:

इस योजना में एक गैर-संकुल अनुक्रमणिका खोज . है जो LIKE . को कवर करता है रेंज, एक अवशिष्ट LIKE विधेय, स्थिर NULLs पहले की तरह, और एक शीर्ष (5)। क्वेरी ऑप्टिमाइज़र BACKWARD perform निष्पादित करना चुनता है इंडेक्स सीक . में रेंज स्कैन एक बार फिर छँटाई से बचने के लिए।
ऊपर दी गई योजना की तुलना WITH RECOMPILE . का उपयोग करके बनाई गई योजना से करें , जो पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन . का उपयोग नहीं कर सकता :
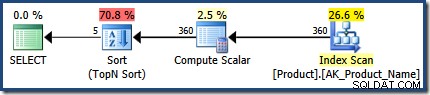
इस डेमो उदाहरण को IF . की एक श्रृंखला के रूप में बेहतर ढंग से लागू किया जा सकता है प्रक्रिया में कथन (पैरामीटर मानों के प्रत्येक संयोजन के लिए एक)। यह हर बार एक स्टेटमेंट संकलन किए बिना समान क्वेरी प्लान लाभ प्रदान कर सकता है। अधिक जटिल परिदृश्यों में, OPTION (RECOMPILE) द्वारा प्रदान किए गए पैरामीटर एम्बेडिंग के साथ कथन-स्तर पुन:संकलित होता है एक अत्यंत उपयोगी अनुकूलन तकनीक हो सकती है।
एक एम्बेडिंग प्रतिबंध
एक परिदृश्य है जहां OPTION (RECOMPILE) . का उपयोग किया जा रहा है इसके परिणामस्वरूप पैरामीटर एम्बेडिंग ऑप्टिमाइज़ेशन लागू नहीं होगा। यदि कथन एक चर को निर्दिष्ट करता है, तो पैरामीटर मान एम्बेड नहीं किए जाते हैं:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
DECLARE
@ProductID integer,
@Name nvarchar(50);
SELECT TOP (1)
@ProductID = ProductID,
@Name = Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END;
क्योंकि SELECT स्टेटमेंट अब एक वेरिएबल को असाइन करता है, उत्पादित क्वेरी प्लान वही होते हैं जब WITH RECOMPILE प्रयोग किया गया। पैरामीटर मान अभी भी सूँघे जाते हैं और कार्डिनैलिटी अनुमान के लिए क्वेरी ऑप्टिमाइज़र द्वारा उपयोग किए जाते हैं, और OPTION (RECOMPILE) अभी भी केवल एक कथन को संकलित करता है, केवल पैरामीटर एम्बेडिंग . का लाभ खो गया है।