विषय-सूची
Oracle इंडेक्स क्लस्टरिंग फैक्टर (CF) क्या है?
क्लस्टरिंग कारक एक संख्या है जो अनुक्रमित कॉलम की तुलना में तालिका में डेटा को यादृच्छिक रूप से वितरित करने की डिग्री का प्रतिनिधित्व करता है। सरल शब्दों में, यह एक इंडेक्स का उपयोग करके टेबल को पढ़ते समय "ब्लॉक स्विच" की संख्या है।
यह एक महत्वपूर्ण आँकड़ा है जो अनुकूलक गणना में महत्वपूर्ण भूमिका निभाता है। इसका उपयोग इंडेक्स रेंज स्कैन के लिए गणना को भारित करने के लिए किया जाता है। जब क्लस्टरिंग कारक अधिक होता है, तो इंडेक्स रेंज स्कैन की लागत अधिक होती है
एक अच्छा क्लस्टरिंग कारक तालिका के ब्लॉकों की संख्या के मानों के बराबर (या निकट) होता है।
एक खराब क्लस्टरिंग कारक तालिका की पंक्तियों की संख्या के बराबर (या निकट) होता है।
CF की गणना कैसे की जाती है?
ओरेकल लीफ ब्लॉक्स को सिरे से अंत तक चलने वाले इंडेक्स का पूरा स्कैन करके क्लस्टरिंग फैक्टर की गणना करता है। प्रत्येक पत्ती में प्रत्येक प्रविष्टि के लिए, Oracle निरपेक्ष फ़ाइल संख्या और ब्लॉक आईडी की जाँच करता है, जैसा कि अनुक्रमित मान के ROWID से प्राप्त होता है। यह इस बात की गिनती रखता है कि कितने "अलग" ब्लॉक में इंडेक्स द्वारा इंगित डेटा पंक्तियाँ हैं। पहली प्रविष्टि के ब्लॉक पते की तुलना दूसरी प्रविष्टि के ब्लॉक पते से की जाती है। यदि यह समान तालिका ब्लॉक है, तो Oracle काउंटर को नहीं बढ़ाता है। यदि टेबल ब्लॉक अलग हैं, तो Oracle एक को गिनती में जोड़ देता है। यह गिनती प्रक्रिया प्रवेश से प्रविष्टि तक जारी रहती है, हमेशा पिछली प्रविष्टि की तुलना वर्तमान प्रविष्टि से करती है।
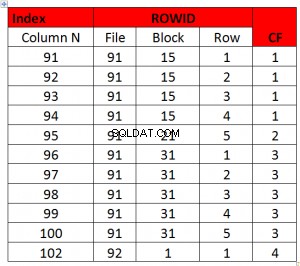
ऊपर एक अच्छा CF उदाहरण है क्योंकि CF ब्लॉकों की संख्या के बराबर है
खराब क्लस्टरिंग कारक का उदाहरण
यहाँ क्लस्टरिंग फ़ैक्टर पंक्तियों की संख्या के बराबर है
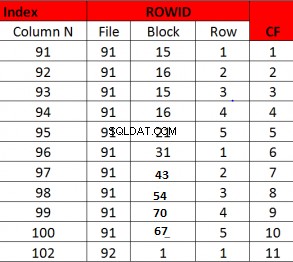
गिनती की इस पद्धति का अपना अप्रत्याशित परिणाम है। मान लीजिए कि डेटा ब्लॉकों के एक छोटे से सेट पर भरा हुआ है, लेकिन इंडेक्स कुंजी के संदर्भ में नहीं है, तो पंक्तियों का एक सेट ब्लॉक के एक बड़े सेट के ऊपर दिखाई दे सकता है, जब शायद कुछ ही सही अलग ब्लॉक हों . तो CF अधिक होगा लेकिन वास्तव में, यह बहुत कम ब्लॉकों को छू रहा है। तालिका प्राथमिकताओं का उपयोग करके और तालिकाबद्ध कैश्ड ब्लॉक को निर्दिष्ट करके इस समस्या को 12c में कम किया जा सकता है।
ओरेकल में क्लस्टरिंग कारक को कैसे सुधारें
एक अनुक्रमणिका पुनर्निर्माण का क्लस्टरिंग कारक पर कोई प्रभाव नहीं पड़ेगा। क्लस्टरिंग कारक को कम करने के लिए तालिका को क्रमबद्ध और पुनर्निर्माण करने की आवश्यकता है।
क्लस्टरिंग कारक निर्धारित करने के लिए क्वेरी
CF डेटा डिक्शनरी में संग्रहीत है और इसे dba_indexes (या user_indexes) से देखा जा सकता है।
वास्तव में, सभी सूचकांक आँकड़े वहाँ पाए जा सकते हैं
SELECT index_name, index_type, uniqueness, blevel, leaf_blocks, distinct_keys, avg_leaf_blocks_per_key,
avg_data_blocks_per_key, clustering_factor, num_rows, sample_size, last_analyzed, partitioned
FROM dba_indexes
WHERE table_name = 'ORDERS' ;
Oracle अनुक्रमणिका क्लस्टरिंग कारक अनुकूलक योजना को कैसे प्रभावित करता है?
क्लस्टरिंग कारक प्राथमिक आँकड़ा है जिसका उपयोग ऑप्टिमाइज़र इंडेक्स एक्सेस पथों को वेट करने के लिए करता है। यह उन सभी पंक्तियों को प्राप्त करने के लिए आवश्यक LIO से तालिका ब्लॉकों की संख्या का अनुमान है जो क्वेरी को क्रम से संतुष्ट करती हैं। क्लस्टरिंग कारक जितना अधिक होगा, ऑप्टिमाइज़र के लिए उतने ही अधिक LIO की आवश्यकता होगी। जितने अधिक एलआईओ की आवश्यकता होगी, उतना ही कम आकर्षक, और इस प्रकार अधिक महंगा, सूचकांक का उपयोग होगा।
संबंधित लेख
ओरेकल पार्टीशन इंडेक्स:ओरेकल पार्टीशन इंडेक्स को समझना, ग्लोबल नॉनपार्टिशन इंडेक्स क्या है?, लोकल प्रीफिक्स्ड इंडेक्स क्या है, नॉन प्रीफिक्स्ड लोकल इंडेक्स
ऑरेकल में टेबल पर इंडेक्स ढूंढें:इस लेख को देखें कि कैसे ओरेकल में एक टेबल पर इंडेक्स खोजने के लिए, स्कीमा में सभी इंडेक्स सूचीबद्ध करें, इंडेक्स स्टेटस, इंडेक्स कॉलम
ऑरेकल में इंडेक्स के प्रकार:इस पेज में ऑरैकल इंडेक्स जानकारी, ओरेकल में विभिन्न प्रकार के इंडेक्स एक उदाहरण के साथ, कैसे ओरेकल में इंडेक्स बनाने/छोड़ने/बदलने के लिए
ओरेकल में वर्चुअल इंडेक्स:ओरेकल में वर्चुअल इंडेक्स क्या है? Oracle डेटाबेस में व्याख्या योजना की जांच करने के लिए उपयोग, सीमा, लाभ और उपयोग कैसे करें, हिडन पैरामीटर _USE_NOSEGMENT_INDEXES