एक डेटाबेस प्रबंधन प्रणाली सूचना का मजबूत बॉक्स है। हम डेटाबेस प्रबंधन प्रणाली को डिजाइन करने का प्रयास करेंगे ताकि डेटाबेस अच्छी तरह से प्रबंधित और उद्देश्यों को प्रस्तुत कर सके।
इस लेख में, हम बड़े आकार के डेटाबेस सिस्टम के डिजाइन और प्रशासन पर चर्चा करने जा रहे हैं। हम कई संविधानों का उपयोग करेंगे जिनमें डेटाबेस तकनीक, भंडारण, डेटा वितरण, सर्वर संपत्ति, वास्तुकला पैटर्न, और कुछ अन्य शामिल होंगे।
अधिमानतः, हमें टेल्को डोमेन, ईकामर्स प्लेटफॉर्म, बीमा डोमेन, बैंकिंग सिस्टम, हेल्थकेयर, एनर्जी सिस्टम आदि में एक बड़े आकार के डेटाबेस की तलाश करनी चाहिए। हमें सही डेटाबेस तकनीक चुनने से पहले कुछ मापदंडों को ध्यान में रखना चाहिए। यानी, ट्रैफ़िक, TPS (लेन-देन प्रति सेकंड), अनुमानित संग्रहण प्रति दिन, HA, और DR.
एक बड़े आकार के डेटाबेस को डिज़ाइन करना
अपने डेटाबेस का निर्माण करते समय, हमें कई मापदंडों पर ध्यान देना चाहिए क्योंकि डेटाबेस को किसी विकल्प के साथ बदलने में अक्सर बहुत समस्या होती है। आइए अब उन पर विचार करें।
डेटाबेस प्रौद्योगिकी
डेटाबेस प्रौद्योगिकी प्राथमिक कारक है। यदि आप सही डेटाबेस प्रबंधन प्रणाली चुनते हैं, तो यह आपके व्यवसाय को कुशलतापूर्वक और सहजता से चलाने में मदद करेगी।
कई विशेषताओं के साथ विभिन्न डेटाबेस प्रौद्योगिकियां हैं। हालाँकि, ओपन-सोर्स डेटाबेस तकनीकों के साथ काम करते समय, आपको पूर्वनिर्धारित समाधानों की कुछ स्पष्ट विशेषताओं तक पहुँच प्राप्त नहीं हो सकती है। Microsoft SQL Server, Oracle, आदि जैसी एंटरप्राइज़ डेटाबेस प्रौद्योगिकियाँ उन्हें प्रदान करेंगी।
बहुत सारी एंटरप्राइज़ डेटाबेस प्रौद्योगिकियां HA (उच्च उपलब्धता), DR (आपदा रिकवरी), मिररिंग, डेटा प्रतिकृति, सेकेंडरी रीड रेप्लिका, और काफी अधिक सुविधाजनक और तैयार कॉन्फ़िगर करने योग्य व्यावसायिक समाधान लागू करती हैं। वे ओपन-सोर्स डेटाबेस में मौजूद हो भी सकते हैं और नहीं भी।
बहुत सारे कारण हैं। उदाहरण के लिए, हम कभी-कभी पाते हैं कि मौजूदा वास्तुकला में गड़बड़ी हो रही है क्योंकि ऊपर वर्णित कारक काम नहीं कर रहे हैं क्योंकि हमें उनकी आवश्यकता है।
संग्रहण
भंडारण व्यावसायिक समाधान के प्रदर्शन को अत्यधिक प्रभावित करता है। व्यावसायिक समाधानों के लिए आईओपीएस की एक निश्चित मात्रा के साथ प्रथम श्रेणी के भंडारण या एसएसडी की आवश्यकता होती है। हालाँकि, क्या ऐसा है? ऑन-प्रिमाइसेस या क्लाउड, स्टोरेज का आकार और प्रकार बुनियादी ढांचे की लागत निर्धारित करते हैं।
भंडारण प्रदर्शन पर विचार करते समय हमें डेटा के प्रकार और डेटा प्रोसेसिंग के व्यवहार पर ध्यान देने की आवश्यकता है। हमें उपयोगकर्ता के डेटा और उसके प्रसंस्करण के अनुसार भंडारण चयन का विकल्प चुनना होगा। यदि उपयोगकर्ता कई डेटाबेस का उपयोग करने जा रहा है, तो हमें डेटा प्रकारों और डेटा प्रोसेसिंग व्यवहार के लिए विभिन्न डेटाबेस के लिए सैन पर भंडारण विकल्प प्रदान करने की आवश्यकता है।
यदि उपयोगकर्ताओं को प्रीमियम संग्रहण की बिल्कुल भी आवश्यकता नहीं है, तो डेटाबेस इंजीनियर IOPS गणना के लिए आवश्यक विभिन्न डेटाबेस पर एक बेहतर पूर्व-निरीक्षण प्रदान करेगा।
डेटा वितरण
अधिकांश हालिया डेटाबेस तकनीकें (एसक्यूएल या नोएसक्यूएल) विभाजन या साझाकरण सुविधाएं प्रदान करती हैं।
- विभाजन फ़ाइल सिस्टम में डेटा को पुनर्वितरित करता है जो विभाजन कुंजी पर आधारित होता है।
- साझाकरण डेटाबेस नोड्स में जानकारी वितरित करता है और डेटा उसी या अलग मशीन में संग्रहीत किया जाएगा।
मूल रूप से, प्रत्येक डेटाबेस सेवा या डेटाबेस तालिका को डेटा विभाजन/साझाकरण सुविधाओं की आवश्यकता नहीं होगी। उन्हें केवल बड़े आकार की वस्तुओं वाले डेटाबेस पर लागू करने की आवश्यकता होती है। इससे प्रदर्शन में वृद्धि होगी।
सर्वर एसेट
विभिन्न मशीनों को मेमोरी और सीपीयू के विभिन्न प्रकारों और आकारों की आवश्यकता होती है। आपको हार्डवेयर स्तर की संपत्ति, जैसे मेमोरी, प्रोसेसर, आदि पर विचार करना होगा। उदाहरण के लिए, एक मशीन जिसे बड़े डेटाबेस या कई डेटाबेस को संभालना होता है, उसे अधिक मेमोरी और सीपीयू की आवश्यकता होगी। इसलिए, मेमोरी और प्रोसेसर की गुणवत्ता महत्वपूर्ण है। यह विभिन्न CPU कैश के साथ बाजार में उपलब्ध विभिन्न प्रकार के प्रोसेसर को संभालने वाला है।
कई बार हमारे सामने ऐसे मुद्दे आ जाते हैं जिनके बारे में हम नहीं जानते। हमने हार्डवेयर के सीपीयू कैश के उपयोग और भूमिका पर ध्यान नहीं दिया। लेकिन बड़े डेटाबेस सिस्टम के साथ हार्डवेयर आवश्यकताओं को चुनने और पूरा करने के लिए यह महत्वपूर्ण है।
वास्तुकला पैटर्न
डेटाबेस डिजाइनिंग में, आर्किटेक्चर पैटर्न हमेशा एक अनुकरणीय भूमिका में होता है। इससे पहले, डेटाबेस सिस्टम को बेहद अखंड तरीके से डिजाइन किया गया था। अब, हम माइक्रो-सर्विस आधारित या हाइब्रिड (मोनोलिथिक + माइक्रो) का उपयोग करते हैं।
प्रदर्शन, विस्तारशीलता और शून्य डाउनटाइम आर्किटेक्चर पैटर्न और डेटाबेस डिज़ाइन पर बहुत अधिक निर्भर करता है। प्रत्येक एप्लिकेशन का एक अलग डेटाबेस हो सकता है, और सभी डेटाबेस एक दूसरे के साथ शिथिल रूप से युग्मित हो सकते हैं। किसी भी एप्लिकेशन या डेटाबेस के डाउन होने की स्थिति में, उत्पाद का दूसरा हिस्सा बाधित नहीं होगा। सभी सूक्ष्म सेवाएं स्वतंत्र और शिथिल युग्मन वाली होंगी।
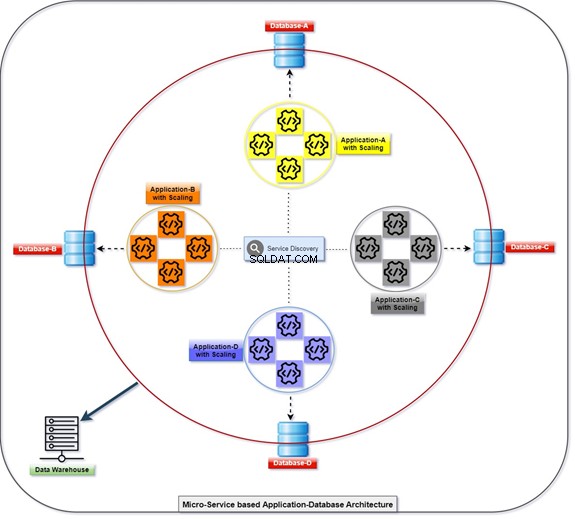
सूक्ष्म सेवा
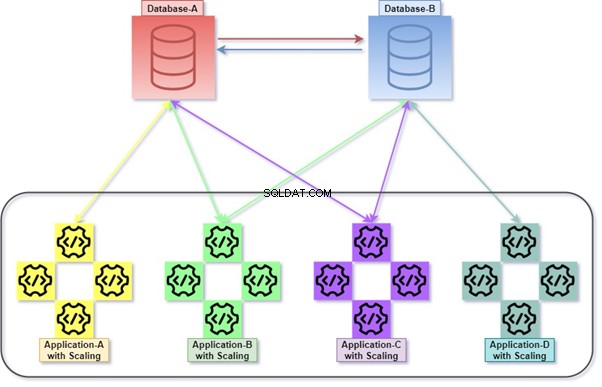
नीचे दिया गया चित्र बताता है कि कैसे सभी एप्लिकेशन अपने डेटाबेस की मदद से परिनियोजित और संचार कर रहे हैं, जो एक ही समय में शिथिल रूप से युग्मित हैं। हम टी-एसक्यूएल के साथ डेटा में हेरफेर कर सकते हैं। जानकारी विभिन्न अनुप्रयोगों द्वारा एकत्रित या संचित की जाएगी, और ग्राहक डेटा तक पहुंचने में सक्षम होगा। स्केल किए गए एप्लिकेशन और उसके एकीकृत डेटाबेस की संख्या के साथ आरेख देखें।
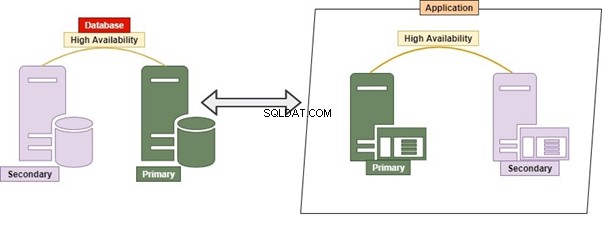
मोनोलिथिक
हमें किस RDBMS का उपयोग करना चाहिए? यह Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB, या कोई अन्य डेटाबेस हो सकता है। एकल सर्वर में एकल या एकाधिक डेटाबेस में प्रबंधित सभी तालिकाओं या वस्तुओं से निपटने का पारंपरिक तरीका मोनोलिथिक के रूप में जाना जाता है।
हाइब्रिड
हाइब्रिड मोनोलिथिक और माइक्रो सर्विस का क्रमचय है। यह काफी सामान्य अभ्यास है, क्योंकि यह कई एप्लिकेशन, कई डेटाबेस और डेटाबेस सर्वर की अनुमति देता है। कई डेटाबेस और डेटाबेस सर्वर को एक दूसरे के साथ कसकर जोड़ा जा सकता है।
उदाहरण के लिए, एक ही डेटाबेस सर्वर या भिन्न में दो या दो से अधिक डेटाबेस से संबंधित तालिकाओं के बीच जॉइन के साथ क्वेरी करना। किसी अन्य डेटाबेस सर्वर के साथ डेटा पुनर्प्राप्त/हेरफेर करने के लिए उपयोग की जाने वाली दूरस्थ क्वेरी।
सब कुछ SQL सर्वर आर्किटेक्चर के बारे में है। हालांकि, हम एक ही डेटाबेस या अलग-अलग डेटाबेस में अलग-अलग तालिकाओं के बीच डेटा हेरफेर के बारे में बात कर रहे हैं जो एक ही सर्वर या अलग-अलग सर्वर पर रह सकते हैं।
या तो हाइब्रिड या मोनोलिथिक आर्किटेक्चर में, हम एक ही या अलग-अलग डेटाबेस में विभिन्न तालिकाओं के बीच जॉइन का उपयोग करते हैं। जब हम कोर माइक्रो-सर्विस मानकों का पालन करते हैं तो यह काफी जटिल होता है क्योंकि टेबल का वितरण डेटाबेस सेवाओं (डीबीएएस) के बीच हो सकता है।
Microsoft SQL सर्वर, Oracle, आदि जैसी एंटरप्राइज़ डेटाबेस तकनीकों के तहत, उपयोगकर्ता लिंक्ड सर्वर जॉइन की मदद से वितरित डेटाबेस की तालिकाओं को क्वेरी कर सकता है। लेकिन यह सभी ओपन-सोर्स डेटाबेस तकनीकों में उपलब्ध नहीं है। इसे तंग-युग्मित दृष्टिकोण के रूप में जाना जाता है जो दूरस्थ डेटाबेस सेवा उपलब्ध नहीं होने पर काम नहीं कर सकता है।
अब, आइए इसे ढीला-कपल्ड बनाने पर चर्चा करें। हमें दूरस्थ डेटाबेस के बीच डेटा हेरफेर की आवश्यकता क्यों है?
हमें दूरस्थ डेटाबेस के बीच डेटा हेरफेर की आवश्यकता क्यों है?
जब सिस्टम को माइक्रो या हाइब्रिड सेवाओं की मदद से डिजाइन किया जाता है, तो उपयोगकर्ताओं को डेटा को एक से अधिक डेटाबेस सेवा से पुनर्प्राप्त करने की आवश्यकता होगी। पूरी प्रक्रिया को बैकएंड से देखा जाता है जो एप्लिकेशन द्वारा हेरफेर की गई डेटा मात्रा को संभाल सकता है।
जब हम रीयल-टाइम क्रॉस-डेटाबेस क्वेरी को देखते हैं, तो हम हमेशा मास्टर एंटिटी टेबल में शामिल होते हैं, मेटाडेटा टेबल नहीं। मास्टर टेबल मेटाडेटा टेबल से बड़ी नहीं होगी। रिपोर्टिंग उद्देश्यों के लिए, हम सभी जानकारी एक साथ प्राप्त करने के लिए हमेशा डेटा वेयरहाउस का उपयोग करते हैं। लेकिन प्रत्येक उत्पाद के लिए प्रबंधन और रखरखाव करना आसान नहीं है। यदि हम उद्यम समाधान तैयार करते हैं, तो हम गोदाम का खर्च उठा सकते हैं। लेकिन हम इसे छोटे या मध्यम आकार के उत्पादों के लिए नहीं खरीद सकते।
उदाहरण के लिए, हमें विभिन्न डेटाबेस में रहने वाली कई तालिकाओं के डेटा के साथ एक रिपोर्ट की आवश्यकता होती है। यह प्रदर्शन करना आसान काम नहीं है, क्योंकि यह विभिन्न माइक्रोसर्विसेज का उपयोग करके डेटा को जोड़ता है और रिपोर्ट तैयार करने के लिए इसे मर्ज करता है। इसलिए, आवश्यक डेटा को समन्वयित करने की आवश्यकता है।
हम एक मानक समाधान के रूप में क्या उपयोग कर सकते हैं दो डेटाबेस के बीच ढीली-युग्मित तालिका डेटा सिंक्रनाइज़ेशन बनाने के लिए?
एकाधिक डेटाबेस के बीच सरल डेटा सिंक्रनाइज़ेशन के लिए तालिका प्रतिकृति का उपयोग किया जाना चाहिए। उदाहरण सिम्प्लेक्स डेटा सिंक्रनाइज़ेशन के लिए लेनदेन प्रतिकृति और SQL सर्वर द्वारा प्रदान किए गए डुप्लेक्स डेटा सिंक्रनाइज़ेशन के लिए मर्ज प्रतिकृति है।
कुछ भुगतान किए गए तृतीय-पक्ष और ओपन-सोर्स समाधान हैं जो कई डेटाबेस के बीच डेटा को सिंक्रनाइज़ कर सकते हैं। एसक्यूएल सर्वर ट्रांजेक्शन रेप्लिकेशन जैसे संदेश कतारों की मदद से ढीले युग्मित समाधान भी उपयोगकर्ताओं द्वारा स्वयं विकसित किए जा सकते हैं।
निष्कर्ष
डीबीए अपने तरीके से डेटाबेस डिजाइन करते हैं। डेटाबेस को आर्किटेक्चर करते समय और डेटाबेस मैनेजमेंट सिस्टम को चुनते समय, उन्हें कई पहलुओं को ध्यान में रखना होता है। हमने डेटाबेस डिज़ाइन के लिए सबसे आवश्यक कारक प्रस्तुत किए, विशेष रूप से बड़े आकार के डेटाबेस के लिए। अगली सामग्री के लिए बने रहें!