मैंने हाल ही में DISTINCT और GROUP BY के बारे में एक पोस्ट लिखी थी। यह एक तुलना थी जिसने दिखाया कि DISTINCT की तुलना में GROUP BY आम तौर पर एक बेहतर विकल्प है। यह एक अलग साइट पर है, लेकिन इसके तुरंत बाद sqlperformance.com पर वापस आना सुनिश्चित करें..
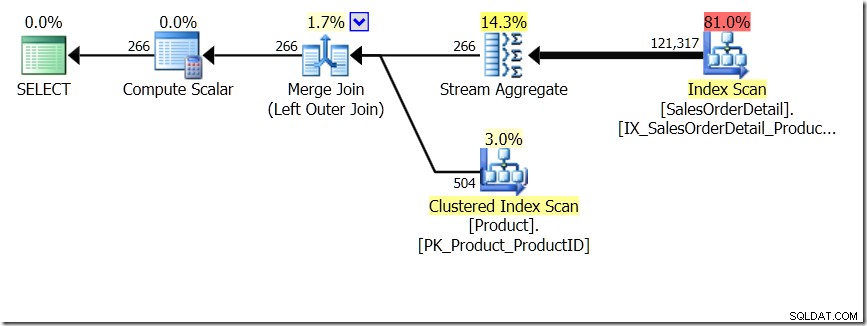
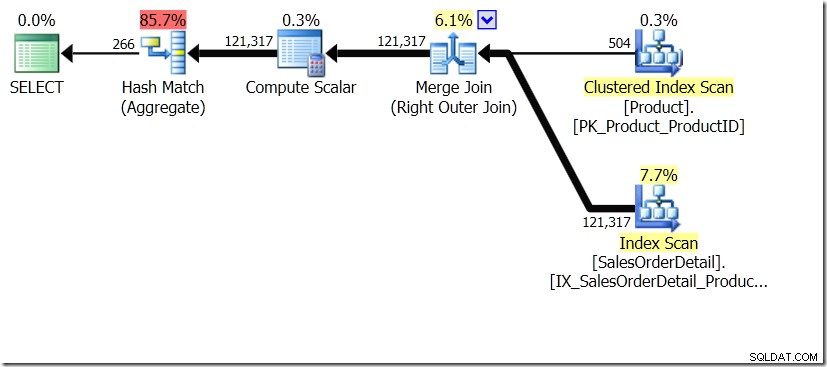
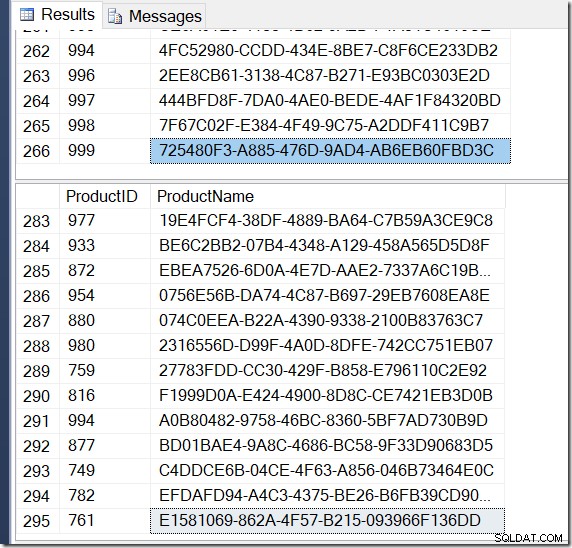
उस पोस्ट में दिखाई गई क्वेरी तुलनाओं में से एक उप-क्वेरी के लिए GROUP BY और DISTINCT के बीच थी, यह दर्शाता है कि DISTINCT बहुत धीमा है, क्योंकि इसे बिक्री तालिका में प्रत्येक पंक्ति के लिए उत्पाद का नाम लाना है, बल्कि केवल प्रत्येक भिन्न ProductID के लिए। यह क्वेरी योजनाओं से बिल्कुल स्पष्ट है, जहां आप देख सकते हैं कि पहली क्वेरी में, एग्रीगेट शामिल होने के परिणामों के बजाय केवल एक तालिका से डेटा पर काम करता है। ओह, और दोनों क्वेरीज़ समान 266 पंक्तियाँ देती हैं।
od.ProductID चुनें, (उत्पादन से नाम चुनें। उत्पाद p जहां p.ProductID =od.ProductID) Sales से ProductName के रूप में। अलग od.ProductID चुनें, (उत्पादन से नाम चुनें। उत्पाद p जहां p.ProductID =od.ProductID) Sales से ProductName के रूप में।
अब, यह इंगित किया गया है, जिसमें एडम मैकैनिक (@adammacanic) ने एक ट्वीट में ग्रुप बाय v DISTINCT के बारे में हारून की पोस्ट को संदर्भित किया है कि दो प्रश्न अनिवार्य रूप से अलग हैं, कि एक वास्तव में परिणामों पर अलग संयोजनों के सेट के लिए पूछ रहा है उप-क्वेरी, अलग-अलग मानों में उप-क्वेरी चलाने के बजाय, जो पास किए गए हैं। यह वही है जो हम योजना में देखते हैं, और यही कारण है कि प्रदर्शन इतना अलग है।
बात यह है कि हम सभी यह मान लेंगे कि परिणाम समान होने वाले हैं।
लेकिन यह एक धारणा है, और अच्छी नहीं है।
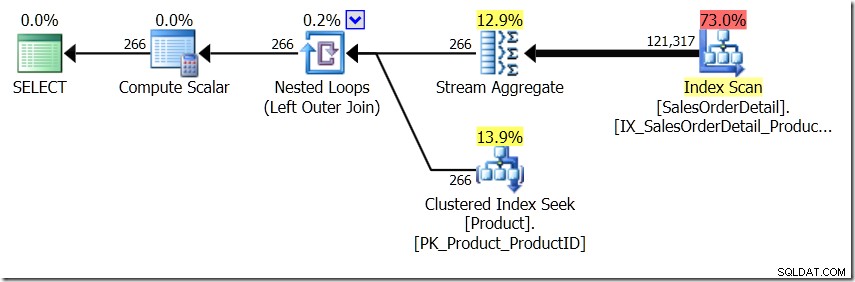
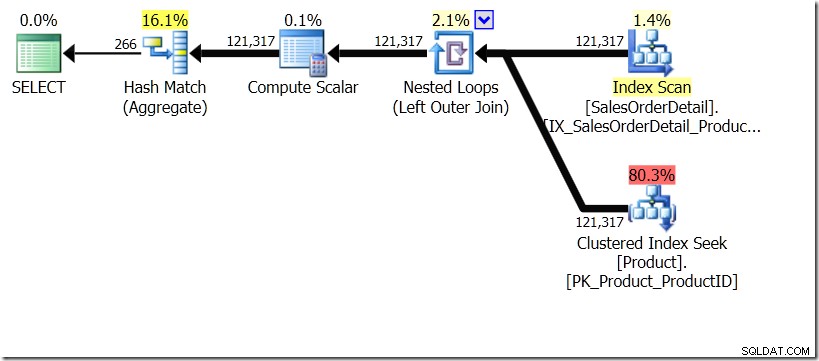
मैं एक पल के लिए कल्पना करने जा रहा हूं कि क्वेरी ऑप्टिमाइज़र एक अलग योजना लेकर आया है। मैंने इसके लिए संकेतों का उपयोग किया, लेकिन जैसा कि आप जानते हैं, क्वेरी ऑप्टिमाइज़र सभी प्रकार के कारणों से सभी प्रकार के आकार में योजनाएँ बनाना चुन सकता है।
od.ProductID चुनें, (उत्पादन से नाम चुनें। उत्पाद p जहां p.ProductID =od.ProductID) बिक्री से ProductName के रूप में। अलग od.ProductID चुनें, (उत्पादन से नाम चुनें।
इस स्थिति में, हम या तो उत्पाद तालिका में 266 सीक्स करते हैं, प्रत्येक भिन्न उत्पाद आईडी के लिए एक जिसमें हम रुचि रखते हैं, या 121,317 सीक्स करते हैं। इसलिए यदि हम किसी विशेष ProductID के बारे में सोच रहे हैं, तो हम जानते हैं कि हम पहले वाले से एक ही नाम वापस प्राप्त करने जा रहे हैं। और हम मानते हैं कि हम उस ProductID के लिए एक ही नाम वापस प्राप्त करने जा रहे हैं, भले ही हमें इसे सौ बार पूछना पड़े। हम बस यह मान लेते हैं कि हमें वही परिणाम वापस मिलने वाले हैं।
लेकिन क्या होगा अगर हम नहीं?
यह एक अलगाव स्तर की बात की तरह लगता है, इसलिए जब हम उत्पाद तालिका को हिट करते हैं तो NOLOCK का उपयोग करें। और चलिए एक स्क्रिप्ट चलाते हैं (एक अलग विंडो में) नाम कॉलम में टेक्स्ट को बदलता है। मैं अपनी क्वेरी के बीच कुछ बदलाव लाने की कोशिश करने के लिए इसे बार-बार करने जा रहा हूं।
अपडेट प्रोडक्शन.प्रोडक्टसेट नेम =कास्ट(newid() as varchar(36));go 1000अब, मेरे परिणाम अलग हैं। योजनाएं समान हैं (दूसरी क्वेरी में हैश एग्रीगेट से निकलने वाली पंक्तियों की संख्या को छोड़कर), लेकिन मेरे परिणाम अलग हैं।
निश्चित रूप से, मेरे पास DISTINCT के साथ और पंक्तियाँ हैं, क्योंकि यह एक ही ProductID के लिए अलग-अलग नाम मान पाता है। और जरूरी नहीं कि मेरे पास 295 पंक्तियाँ हों। एक और मैं इसे चलाता हूं, मुझे 273, या 300, या संभवतः, 121,317 मिल सकते हैं।
उत्पाद आईडी का एक उदाहरण खोजना मुश्किल नहीं है जो कई नाम मान दिखाता है, जो पुष्टि करता है कि क्या हो रहा है।
स्पष्ट रूप से, यह सुनिश्चित करने के लिए कि हम इन पंक्तियों को परिणामों में नहीं देखते हैं, हमें या तो DISTINCT का उपयोग नहीं करना होगा, या फिर एक सख्त अलगाव स्तर का उपयोग करना होगा।
बात यह है कि हालांकि मैंने इस उदाहरण के लिए NOLOCK का उपयोग करने का उल्लेख किया है, मुझे इसकी आवश्यकता नहीं थी। यह स्थिति READ COMMITTED के साथ भी होती है, जो कि कई SQL सर्वर सिस्टम पर डिफ़ॉल्ट आइसोलेशन स्तर है।
आप देखिए, हमें इस स्थिति से बचने के लिए रिपीटेबल रीड आइसोलेशन स्तर की आवश्यकता है, एक बार पढ़ने के बाद प्रत्येक पंक्ति पर ताले रखने के लिए। अन्यथा, जैसा कि हमने देखा, एक अलग थ्रेड डेटा को बदल सकता है।
लेकिन... मैं आपको यह नहीं दिखा सकता कि परिणाम निश्चित हैं, क्योंकि मैं क्वेरी पर गतिरोध से बचने का प्रबंधन नहीं कर सका।
तो आइए शर्तों को बदलें, यह सुनिश्चित करके कि हमारी अन्य क्वेरी किसी समस्या से कम नहीं है। एक बार में पूरी तालिका को अपडेट करने के बजाय (जिसकी वास्तविक दुनिया में वैसे भी बहुत कम संभावना है), आइए एक बार में केवल एक पंक्ति को अपडेट करें।
@id int =1 घोषित करें; @maxid int =घोषित करें (उत्पादन से गिनती (*) चुनें। उत्पाद); जबकि (@id < @maxid) p के साथ शुरू होता है (चयन करें *, row_number() ओवर (ऑर्डर करें) ProductID द्वारा) उत्पादन से RN के रूप में। सेट @id +=1;endgo 100अब, हम अभी भी कम आइसोलेशन स्तर के तहत समस्या का प्रदर्शन कर सकते हैं, जैसे कि पढ़ें कमिटेड या रीड अनकॉमिटेड (हालाँकि आपको पहली बार 266 मिलने पर आपको क्वेरी को कई बार चलाने की आवश्यकता हो सकती है, क्योंकि क्वेरी के दौरान एक पंक्ति को अपडेट करने की संभावना है) कम है), और अब हम प्रदर्शित कर सकते हैं कि दोहराने योग्य पढ़ें इसे ठीक करता है (चाहे हम कितनी भी बार क्वेरी चलाएँ)।
रिपीटेबल रीड वही करता है जो वह टिन पर कहता है। एक बार जब आप लेन-देन के भीतर एक पंक्ति पढ़ लेते हैं, तो यह सुनिश्चित करने के लिए लॉक हो जाता है कि आप पढ़ने को दोहरा सकते हैं और समान परिणाम प्राप्त कर सकते हैं। जब तक आप डेटा को बदलने का प्रयास नहीं करते हैं, तब तक कम अलगाव स्तर उन तालों को नहीं हटाते हैं। यदि आपकी क्वेरी योजना को कभी भी पढ़ने की आवश्यकता नहीं है (जैसा कि हमारे ग्रुप बाय प्लान के आकार के मामले में है), तो आपको दोहराने योग्य पढ़ने की आवश्यकता नहीं होगी।
यकीनन, हमें हमेशा उच्च आइसोलेशन स्तरों का उपयोग करना चाहिए, जैसे कि रिपीटेबल रीड या सीरियल, लेकिन यह सब पता लगाने के लिए नीचे आता है कि हमारे सिस्टम को क्या चाहिए। ये स्तर अवांछित लॉकिंग का परिचय दे सकते हैं, और स्नैपशॉट अलगाव स्तरों को संस्करण की आवश्यकता होती है जो कीमत के साथ भी आती है। मेरे लिए, मुझे लगता है कि यह एक व्यापार बंद है। अगर मैं कोई ऐसा प्रश्न पूछ रहा हूं जो डेटा बदलने से प्रभावित हो सकता है, तो मुझे कुछ समय के लिए आइसोलेशन स्तर बढ़ाने की आवश्यकता हो सकती है।
आदर्श रूप से, आप केवल उस डेटा को अपडेट नहीं करते हैं जिसे अभी पढ़ा गया है और क्वेरी के दौरान फिर से पढ़ने की आवश्यकता हो सकती है, ताकि आपको दोहराने योग्य पढ़ने की आवश्यकता न हो। लेकिन यह निश्चित रूप से समझने योग्य है कि क्या हो सकता है, और यह पहचानना कि यह एक ऐसा परिदृश्य है जब DISTINCT और GROUP BY समान नहीं हो सकते हैं।
@rob_farley