एक प्रदर्शन ट्यूनिंग जुड़ाव कई मोड़ ले सकता है क्योंकि आप इसके माध्यम से काम करते हैं - यह सब इस बात पर निर्भर करता है कि समस्या के रूप में क्या दिख रहा है और डेटा आपको क्या बताता है। कुछ दिनों में यह एक विशिष्ट क्वेरी, या प्रश्नों के सेट पर उतरता है, जिसे इंडेक्स के साथ बेहतर बनाया जा सकता है - या तो नए या मौजूदा इंडेक्स में संशोधन। ट्यूनिंग के मेरे पसंदीदा हिस्सों में से एक इंडेक्स के साथ काम कर रहा है और, जैसा कि मैं इस पोस्ट के बारे में सोच रहा था, मुझे इंडेक्स ट्यूनिंग को "आसान" कार्य के रूप में लेबल करने का मोहक था ... लेकिन यह वास्तव में नहीं है।
मैं इंडेक्स ट्यूनिंग को एक कला और विज्ञान के रूप में देखता हूं। आपको ऑप्टिमाइज़र की तरह कोशिश करनी होगी और सोचना होगा, और आपको टेबल स्कीमा और उस क्वेरी (या क्वेरीज़) को समझना होगा जिसे आप ट्यून करने का प्रयास कर रहे हैं। वे दोनों डेटा-संचालित हैं और इस प्रकार विज्ञान की श्रेणी में हैं। जब आप अन्य . के बारे में सोचते हैं तो कला घटक चलन में आ जाता है टेबल पर इंडेक्स, और सभी अन्य वे क्वेरी जिनमें तालिका शामिल है जो अनुक्रमणिका परिवर्तनों से प्रभावित हो सकती हैं।
चरण 1 :क्वेरी की पहचान करें और योजना की समीक्षा करें
जब मैं एक ऐसी क्वेरी की पहचान करता हूं जो किसी इंडेक्स से लाभान्वित हो सकती है, तो मुझे तुरंत इसकी योजना मिल जाती है। मैं अक्सर योजना कैश या क्वेरी स्टोर से निष्पादन योजना प्राप्त करता हूं, और फिर निष्पादन योजना प्लस रन-टाइम सांख्यिकी (उर्फ वास्तविक निष्पादन योजना) प्राप्त करने के लिए एसएसएमएस का उपयोग करता हूं। कई बार उन दोनों योजनाओं का आकार एक जैसा होता है; लेकिन यह कोई गारंटी नहीं है, इसलिए मैं दोनों को देखना पसंद करता हूं।
योजना में एक अनुपलब्ध अनुक्रमणिका अनुशंसा हो सकती है, इसमें एक क्लस्टर इंडेक्स स्कैन हो सकता है (या यदि कोई क्लस्टर इंडेक्स नहीं है तो हीप स्कैन), यह एक गैर-अनुक्रमित अनुक्रमणिका का उपयोग कर सकता है लेकिन फिर अतिरिक्त कॉलम पुनर्प्राप्त करने के लिए एक लुकअप हो सकता है। उन मुद्दों में से प्रत्येक को व्यक्तिगत रूप से ठीक करना बहुत आसान लगता है। बस लापता सूचकांक जोड़ें, है ना? यदि क्लस्टर्ड इंडेक्स या हीप का स्कैन है, तो वह इंडेक्स बनाएं जो मुझे क्वेरी के लिए चाहिए और किया जाए? या यदि कोई अनुक्रमणिका का उपयोग किया जा रहा है, लेकिन वह अतिरिक्त स्तंभ प्राप्त करने के लिए तालिका में जाता है, तो बस उस अनुक्रमणिका में स्तंभ जोड़ें?
यह आमतौर पर इतना आसान नहीं होता है, और जब भी होता है, तब भी मैं उस प्रक्रिया से गुजरता हूं जिसे मैं यहां रेखांकित कर रहा हूं।
चरण 2 :निर्धारित करें कि किस तालिका (तालिकाओं) की समीक्षा करनी है
अब जब मेरे पास मेरी क्वेरी है, तो मुझे यह पता लगाना होगा कि कौन सी टेबल ठीक से अनुक्रमित नहीं हैं। योजना की समीक्षा करने के अलावा, मैं SSMS में IO और TIME आँकड़े भी सक्षम करता हूँ। यह शायद मेरा पुराना स्कूल है, क्योंकि निष्पादन योजनाओं में प्रत्येक रिलीज के साथ अवधि और प्रति ऑपरेटर आईओ संख्या सहित अधिक से अधिक जानकारी होती है, लेकिन मुझे आईओ आंकड़े पसंद हैं क्योंकि मैं प्रत्येक तालिका के लिए जल्दी से पढ़ता हूं। कई जॉइन, या सब-क्वेरी, या सीटीई, या नेस्टेड व्यू के साथ जटिल प्रश्नों के लिए, यह समझना कि क्वेरी ड्राइव में IO और/या समय कहाँ बिताया जाता है जहाँ मैं अपना समय बिताता हूँ। इस बिंदु से जब भी संभव हो, मैं बड़ी, जटिल क्वेरी लेता हूं और इसे उस हिस्से तक सीमित कर देता हूं जो सबसे बड़ी समस्या पैदा कर रहा है।
उदाहरण के लिए, यदि कोई प्रश्न है जो 10 तालिकाओं से जुड़ता है और दो उप-प्रश्न हैं, तो योजना (आईओ और अवधि की जानकारी के साथ) मुझे यह पहचानने में मदद करती है कि समस्या कहां मौजूद है। फिर मैं क्वेरी के उस हिस्से को निकाल दूंगा - समस्याग्रस्त तालिका और शायद कुछ अन्य जिससे वह जुड़ता है - और उस पर ध्यान केंद्रित करें। कभी-कभी यह सिर्फ सब-क्वेरी होती है, इसलिए मैं वहीं से शुरू करता हूं।
चरण 3 :मौजूदा अनुक्रमणिका देखें
क्वेरी (या क्वेरी का हिस्सा) परिभाषित होने के साथ, मैं शामिल तालिकाओं के लिए मौजूदा अनुक्रमणिका पर ध्यान केंद्रित करता हूं। इस चरण के लिए, मैं किम्बर्ली के sp_helpindex के संस्करण पर निर्भर हूं। मैं उसके संस्करण को मानक sp_helpindex के लिए बहुत पसंद करता हूं क्योंकि इसमें INCLUDEd कॉलम और फ़िल्टर परिभाषा (यदि कोई मौजूद है) को भी सूचीबद्ध करता है। किसी तालिका के लिए दिखाई देने वाली अनुक्रमणिका की संख्या के आधार पर, मैं अक्सर इसे कॉपी करता हूं और इसे एक्सेल में पेस्ट करता हूं, और फिर इंडेक्स कुंजी और फिर शामिल कॉलम के आधार पर ऑर्डर करता हूं। यह मुझे किसी भी अतिरेक को शीघ्रता से ढूंढने देता है।
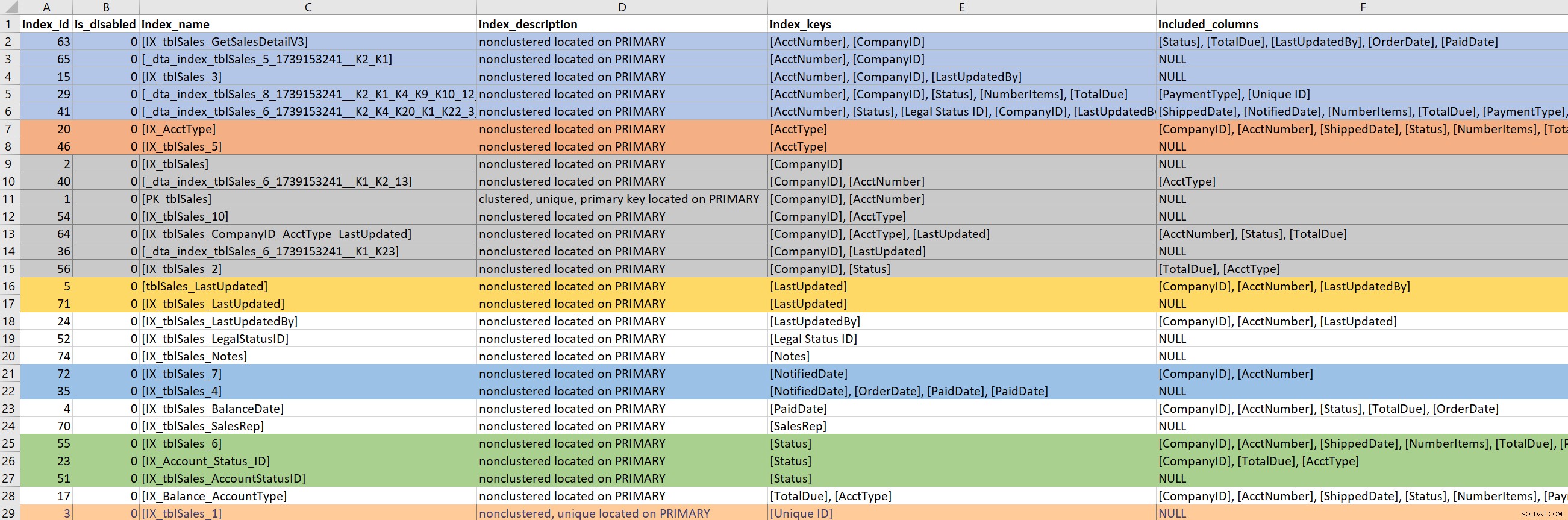
ऊपर दिए गए उदाहरण आउटपुट के आधार पर, सात इंडेक्स हैं जो कंपनीआईडी से शुरू होते हैं, पांच जो AcctNumber से शुरू होते हैं, और कुछ अन्य संभावित अतिरेक। जबकि केवल एक . होना आदर्श लगता है अनुक्रमणिका जो किसी विशेष कॉलम (जैसे CompanyID) पर ले जाती है, कुछ क्वेरी पैटर्न के लिए जो पर्याप्त नहीं है।
जब मैं मौजूदा अनुक्रमितों को देख रहा होता हूं, तो खरगोश के छेद से नीचे जाना बहुत आसान होता है। मैं उपरोक्त आउटपुट को देखता हूं और तुरंत पूछना शुरू करता हूं कि कंपनी आईडी से शुरू होने वाले सात इंडेक्स क्यों हैं, और मैं जानना चाहता हूं कि उन्हें किसने बनाया, और क्यों, और किस प्रश्न के लिए। लेकिन... अगर मेरी समस्यात्मक क्वेरी CompanyID का उपयोग नहीं करती है, तो क्या मुझे परवाह करनी चाहिए? हां ... क्योंकि सामान्य तौर पर मैं प्रदर्शन में सुधार करने के लिए हूं, और अगर इसका मतलब है कि रास्ते में टेबल पर अन्य इंडेक्स को देखना, तो ऐसा ही हो। लेकिन यह वह जगह है जहां समय (और सही उद्देश्य) का ट्रैक खोना आसान है।
अगर मेरी समस्याग्रस्त क्वेरी को एक इंडेक्स की आवश्यकता है जो पेडडेट पर ले जाता है, तो मुझे केवल एक मौजूदा इंडेक्स से निपटना होगा। अगर मेरी समस्यात्मक क्वेरी को एक इंडेक्स की आवश्यकता है जो AcctNumber पर ले जाता है, तो यह मुश्किल हो जाता है। जब मौजूदा इंडेक्स एक क्वेरी को कवर करते हैं, और मैं एक इंडेक्स का विस्तार करना चाहता हूं (अधिक कॉलम जोड़ें) या समेकित (दो या शायद तीन इंडेक्स को एक में मर्ज करें), तो मुझे खोदना होगा।
चरण 4:इंडेक्स उपयोग के आंकड़े
मुझे लगता है कि बहुत से लोग निरंतर आधार पर अनुक्रमणिका उपयोग के आँकड़े नहीं लेते हैं। यह दुर्भाग्यपूर्ण है, क्योंकि मुझे यह तय करते समय डेटा मददगार लगता है कि कौन से इंडेक्स को रखना है, और कौन सा ड्रॉप या मर्ज करना है। उस मामले में जहां मेरे पास ऐतिहासिक उपयोग आंकड़े नहीं हैं, मैं कम से कम यह देखने के लिए जांच करता हूं कि वर्तमान में उपयोग कैसा दिखता है (अंतिम सेवा पुनरारंभ होने के बाद से):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
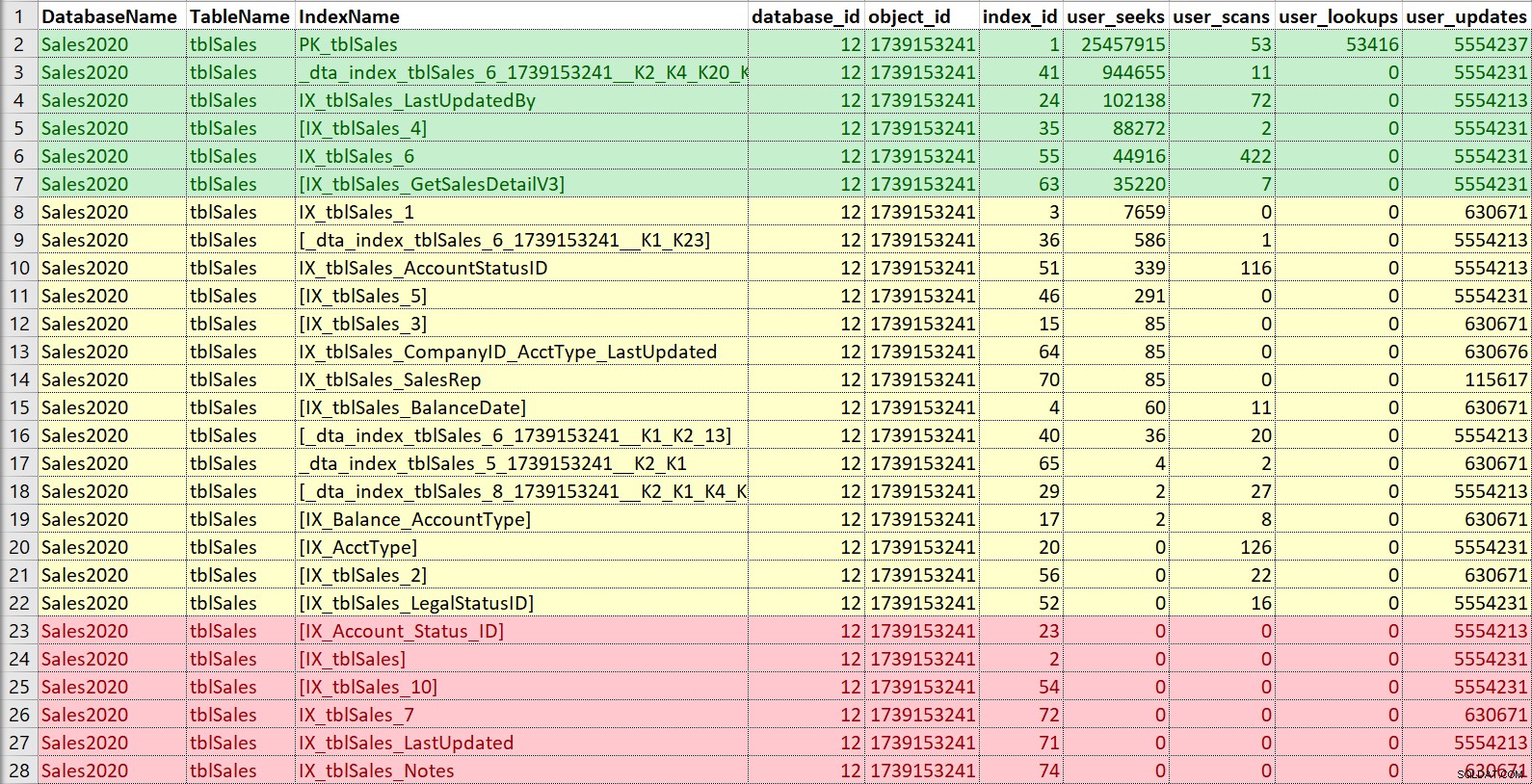
फिर से, मैं इसे एक्सेल में रखना चाहता हूं, खोज के आधार पर छाँटना और फिर स्कैन करना, और अपडेट पर भी ध्यान देना। इस उदाहरण के लिए, लाल रंग में अनुक्रमणिका वे हैं जिनमें कोई खोज, स्कैन या लुकअप नहीं है... केवल अद्यतन। वे विकलांग होने के लिए उम्मीदवार हैं और संभावित रूप से गिराए गए हैं, अगर उनका वास्तव में उपयोग नहीं किया जाता है (फिर से, उपयोग इतिहास होने से यहां मदद मिलेगी)। हरे रंग में अनुक्रमित निश्चित रूप से उपयोग किए जा रहे हैं, मैं उन्हें रखना चाहता हूं (हालांकि शायद कुछ मामलों में उन्हें ट्वीक किया जा सकता है)। पीले रंग वाले... कुछ इस्तेमाल किए जा रहे हैं, कुछ बमुश्किल इस्तेमाल किए जा रहे हैं। फिर, इतिहास यहां मददगार होगा, या दूसरों से संदर्भ - कभी-कभी एक रिपोर्ट या प्रक्रिया के लिए एक सूचकांक महत्वपूर्ण हो सकता है जो हर समय नहीं चलता है।
अगर मैं सिर्फ एक नई अनुक्रमणिका को संशोधित करना या जोड़ना चाहता हूं, बनाम सच्ची सफाई और समेकन, तो मैं ज्यादातर ऐसे किसी भी अनुक्रमणिका से चिंतित हूं जो मैं जोड़ना या बदलना चाहता हूं। हालांकि, मैं ग्राहक को उपयोग की जानकारी बताना सुनिश्चित करूंगा और, यदि समय मिले, तो तालिका के लिए समग्र अनुक्रमण रणनीति में सहायता करूंगा।
आगे क्या है?
हम नहीं कर रहे हैं! यह इंडेक्स ट्यूनिंग के मेरे दृष्टिकोण का भाग 1 है, और मेरी अगली किस्त मेरे बाकी चरणों को सूचीबद्ध करेगी। इस बीच, यदि आप अनुक्रमणिका उपयोग के आँकड़े कैप्चर नहीं कर रहे हैं, तो यह कुछ ऐसा है जिसे आप ऊपर दी गई क्वेरी या किसी अन्य भिन्नता का उपयोग करके रख सकते हैं। मैं सभी उपयोगकर्ता डेटाबेस के लिए उपयोग के आँकड़ों को कैप्चर करने की सलाह दूंगा, न कि केवल एक विशिष्ट तालिका और डेटाबेस के रूप में, जैसा कि मैंने ऊपर किया है, इसलिए विधेय को आवश्यकतानुसार संशोधित करें। और अंत में, उस शेड्यूल्ड जॉब के हिस्से के रूप में उस जानकारी को एक टेबल पर स्नैपशॉट करने के लिए, कुछ समय के लिए डेटा होने के बाद टेबल को साफ करने के लिए एक और कदम मत भूलना (मैं इसे कम से कम छह महीने तक रखता हूं; कुछ लोग कह सकते हैं a वर्ष आवश्यक है)।