दो या दो से अधिक डेटा सेटों का संयोजन आमतौर पर टी-एसक्यूएल में UNION ALL का उपयोग करके व्यक्त किया जाता है। खंड। यह देखते हुए कि SQL सर्वर ऑप्टिमाइज़र अक्सर प्रदर्शन को बेहतर बनाने के लिए जॉइन और एग्रीगेट जैसी चीज़ों को पुन:व्यवस्थित कर सकता है, यह अपेक्षा करना काफी उचित है कि SQL सर्वर कॉन्सटेनेशन इनपुट को पुन:व्यवस्थित करने पर भी विचार करेगा, जहाँ यह एक लाभ प्रदान करेगा। उदाहरण के लिए, अनुकूलक A UNION ALL B . को फिर से लिखने के लाभों पर विचार कर सकता है B UNION ALL A . के रूप में ।
वास्तव में, SQL सर्वर अनुकूलक नहीं करता है इसे करें। अधिक सटीक रूप से, 2008 R2 तक SQL सर्वर रिलीज़ में संयोजन इनपुट पुनर्क्रमण के लिए कुछ सीमित समर्थन था, लेकिन इसे निकाल दिया गया SQL सर्वर 2012 में, और तब से फिर से सामने नहीं आया है।
SQL सर्वर 2008 R2
सहज रूप से, संयोजन इनपुट का क्रम केवल तभी मायने रखता है जब कोई पंक्ति लक्ष्य . हो . डिफ़ॉल्ट रूप से, SQL सर्वर इस आधार पर निष्पादन योजनाओं का अनुकूलन करता है कि सभी योग्य पंक्तियाँ क्लाइंट को वापस कर दी जाएँगी। जब एक पंक्ति लक्ष्य प्रभावी होता है, तो अनुकूलक एक निष्पादन योजना खोजने का प्रयास करता है जो पहली कुछ पंक्तियों को शीघ्रता से उत्पन्न करेगा।
पंक्ति लक्ष्यों को कई तरीकों से निर्धारित किया जा सकता है, उदाहरण के लिए TOP . का उपयोग करके , एक FAST n क्वेरी संकेत, या EXISTS . का उपयोग करके (जिसे इसकी प्रकृति से अधिकतम एक पंक्ति में खोजने की जरूरत है)। जहां कोई पंक्ति लक्ष्य नहीं है (यानी क्लाइंट को सभी पंक्तियों की आवश्यकता होती है), यह आम तौर पर कोई फर्क नहीं पड़ता कि किस क्रम में संयोजन इनपुट पढ़े जाते हैं:प्रत्येक इनपुट को किसी भी मामले में पूरी तरह से संसाधित किया जाएगा।
SQL Server 2008 R2 तक के संस्करणों में सीमित समर्थन लागू होता है जहां बिल्कुल एक पंक्ति का लक्ष्य होता है . इस विशिष्ट परिस्थिति में, SQL सर्वर अपेक्षित लागत के आधार पर संयोजन इनपुट को पुन:व्यवस्थित करेगा।
यह लागत-आधारित अनुकूलन (जैसा कि कोई उम्मीद कर सकता है) के दौरान नहीं किया जाता है, बल्कि सामान्य अनुकूलक आउटपुट के अंतिम-मिनट के बाद के अनुकूलन के पुनर्लेखन के रूप में किया जाता है। इस व्यवस्था में लागत-आधारित योजना खोज स्थान (संभावित रूप से प्रत्येक संभावित पुन:क्रम के लिए एक विकल्प) में वृद्धि नहीं करने का लाभ है, जबकि अभी भी पहली पंक्ति को जल्दी से वापस करने के लिए अनुकूलित एक योजना तैयार कर रहा है।
उदाहरण
निम्नलिखित उदाहरण समान सामग्री वाली दो तालिकाओं का उपयोग करते हैं:एक से दस लाख तक पूर्णांकों की एक लाख पंक्तियाँ। एक तालिका एक ढेर है जिसमें कोई गैर-अनुक्रमित अनुक्रमणिका नहीं है; दूसरे के पास एक अद्वितीय संकुल अनुक्रमणिका है:
टेबल डीबीओ बनाएं। महंगा (वैल बिगिंट न्यूल नहीं); टेबल डीबीओ बनाएं। सस्ता (वैल बिगिंट न्यूल, बाधा [पीके डीबीओ। सस्ता वैल] अद्वितीय क्लस्टर (वैल)); GOINSERT डीबीओ। सस्ता (TABLOCKX) (वैल) के साथ सस्ता चुनें (1000000) वैल =ROW_NUMBER() ओवर (ऑर्डर करें) SV1.number द्वारा) Master.dbo.spt_values के रूप में SV1CROSS के रूप में Master.dbo.spt_values के रूप में शामिल हों SV2ORDER के रूप में ValOPTION (MAXDOP 1) द्वारा; GOINSERT dbo. महंगा (TABLOCKX) (वैल) के साथ महंगा (TABLOCKX) (वैल) चुनें C.ValFROM ASdbo.Cheap 1);
कोई पंक्ति लक्ष्य नहीं
निम्न क्वेरी प्रत्येक तालिका में समान पंक्तियों की तलाश करती है, और दो सेटों का संयोजन लौटाती है:
dbo से E.Val का चयन करें। E.E के रूप में महंगा E.Val 751000 और 751005 यूनियन के बीच सभी चयन C.Dbo से सस्ता। C के रूप में सस्ता जहां C.Val 751000 और 751005 के बीच;
क्वेरी ऑप्टिमाइज़र द्वारा निर्मित निष्पादन योजना है:
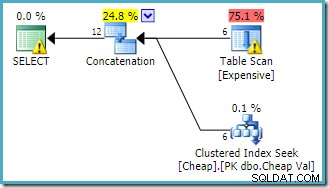
रूट पर चेतावनी SELECT ऑपरेटर हमें हीप टेबल पर स्पष्ट लापता सूचकांक के लिए सचेत कर रहा है। टेबल स्कैन ऑपरेटर पर चेतावनी संतरी वन प्लान एक्सप्लोरर द्वारा जोड़ी जाती है। यह स्कैन के भीतर छिपे हुए अवशिष्ट विधेय की I/O लागत की ओर हमारा ध्यान आकर्षित कर रहा है।
Concatenation के लिए इनपुट का क्रम यहां कोई मायने नहीं रखता, क्योंकि हमने एक पंक्ति लक्ष्य निर्धारित नहीं किया है। सभी परिणाम पंक्तियों को वापस करने के लिए दोनों इनपुट पूरी तरह से पढ़े जाएंगे। रुचि की (हालांकि इसकी गारंटी नहीं है) ध्यान दें कि इनपुट का क्रम मूल क्वेरी के पाठ क्रम का अनुसरण करता है। यह भी देखें कि अंतिम परिणाम पंक्तियों का क्रम भी निर्दिष्ट नहीं है, क्योंकि हमने शीर्ष-स्तरीय ORDER BY का उपयोग नहीं किया है खंड। हम मान लेंगे कि यह जानबूझकर किया गया है और अंतिम आदेश कार्य के लिए अप्रासंगिक है।
अगर हम क्वेरी में टेबल के लिखित क्रम को इस तरह उलट दें:
C.ValFROM dbo से चुनें।निष्पादन योजना परिवर्तन का अनुसरण करती है, पहले संकुल तालिका तक पहुँचती है (फिर से, इसकी गारंटी नहीं है):
दोनों प्रश्नों में समान प्रदर्शन विशेषताओं की उम्मीद की जा सकती है, क्योंकि वे समान संचालन करते हैं, बस एक अलग क्रम में।
एक पंक्ति लक्ष्य के साथ
स्पष्ट रूप से, हीप टेबल पर इंडेक्सिंग की कमी सामान्य रूप से क्लस्टर टेबल पर समान ऑपरेशन की तुलना में विशिष्ट पंक्तियों को खोजना अधिक महंगा बना देगी। यदि हम ऑप्टिमाइज़र से ऐसी योजना के लिए कहते हैं जो पहली पंक्ति को शीघ्रता से लौटाती है, तो हम अपेक्षा करेंगे कि SQL सर्वर संयोजन इनपुट को पुन:व्यवस्थित करे ताकि पहले सस्ते क्लस्टर तालिका से परामर्श किया जा सके।
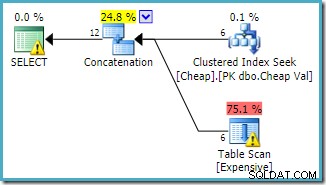
पहले हीप तालिका का उल्लेख करने वाली क्वेरी का उपयोग करना, और पंक्ति लक्ष्य निर्दिष्ट करने के लिए FAST 1 क्वेरी संकेत का उपयोग करना:
dbo से E.Val चुनें।SQL Server 2008 R2 . की आवृत्ति पर निर्मित अनुमानित निष्पादन योजना है:
ध्यान दें कि पहली पंक्ति को वापस करने की अनुमानित लागत को कम करने के लिए संयोजन इनपुट को फिर से व्यवस्थित किया गया है। यह भी ध्यान दें कि लापता सूचकांक और शेष I/O चेतावनियां गायब हो गई हैं। जब लक्ष्य एक पंक्ति को जल्द से जल्द वापस करना है, तो इस योजना के आकार के साथ कोई भी समस्या महत्वपूर्ण नहीं है।
वही क्वेरी SQL Server 2016 पर निष्पादित की गई (या तो कार्डिनैलिटी अनुमान मॉडल का उपयोग करके) है:
SQL सर्वर 2016 ने संयोजन इनपुट को पुन:व्यवस्थित नहीं किया है। प्लान एक्सप्लोरर I/O चेतावनी वापस आ गई है, लेकिन दुख की बात है कि ऑप्टिमाइज़र ने इस बार एक लापता इंडेक्स चेतावनी नहीं दी है (हालांकि यह प्रासंगिक है)।
सामान्य पुन:क्रमित करना
जैसा कि उल्लेख किया गया है, पोस्ट-ऑप्टिमाइज़ेशन फिर से लिखता है कि कॉन्सटेनेशन इनपुट को फिर से व्यवस्थित करना केवल इसके लिए प्रभावी है:
- एसक्यूएल सर्वर 2008 आर2 और पूर्व संस्करण
- बिल्कुल एक पंक्ति लक्ष्य
अगर हम वास्तव में पहली पंक्ति को जल्दी वापस करने के लिए अनुकूलित योजना के बजाय केवल एक पंक्ति लौटाना चाहते हैं (लेकिन जो अंततः सभी पंक्तियों को वापस कर देगी), तो हम TOP का उपयोग कर सकते हैं व्युत्पन्न तालिका या सामान्य तालिका अभिव्यक्ति (CTE) के साथ खंड:
सेलेक्ट टॉप (1) UA.ValFROM (dbo से E.Val का चयन करें। E.E के रूप में महंगा, जहां E.Val 751000 और 751005 यूनियन के बीच dbo से सभी C.Val चुनें। सस्ते के रूप में C जहां C.Val 751000 और 751005 के बीच ) एएस यूए;
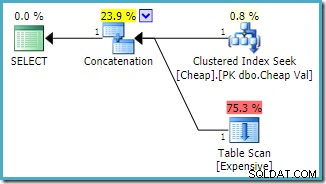
SQL Server 2008 R2 या इससे पहले के संस्करण पर, यह इष्टतम पुन:व्यवस्थित-इनपुट योजना तैयार करता है:
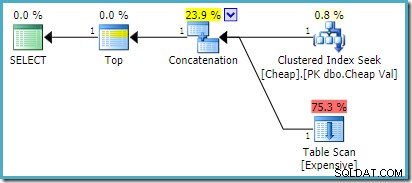
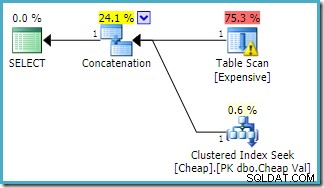
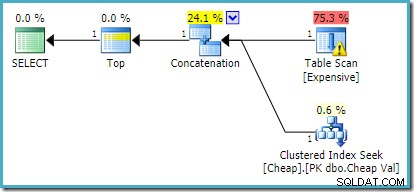
SQL सर्वर 2012, 2014 और 2016 पर कोई पोस्ट-ऑप्टिमाइज़ेशन रीऑर्डरिंग नहीं होती है:
यदि हम चाहते हैं कि एक से अधिक पंक्तियाँ वापस आ जाएँ, उदाहरण के लिए TOP (2) . का उपयोग करना , वांछित पुनर्लेखन लागू नहीं किया जाएगा SQL Server 2008 R2 पर भले ही FAST 1 संकेत का भी प्रयोग किया जाता है। उस स्थिति में, हमें TOP . का उपयोग करने जैसी तरकीबों का सहारा लेना होगा एक चर और एक OPTIMIZE FOR . के साथ संकेत:
DECLARE @TopRows bigint =2; - वास्तव में आवश्यक पंक्तियों की संख्या सेलेक्ट टॉप (@TopRows) UA.ValFROM (डीबीओ से ई.वैल का चयन करें। जहां ई के रूप में महंगा है। 751000 और 751005 यूनियन के बीच सभी चयन सी। डीबीओ से सी। सस्ते के रूप में सी जहां सी। वैल 751000 और 751005 के बीच) UAOPTION के रूप में (इसके लिए ऑप्टिमाइज़ करें (@TopRows =1)); -- बस एक संकेत
क्वेरी संकेत एक का पंक्ति लक्ष्य निर्धारित करने के लिए पर्याप्त है, जबकि चर का रनटाइम मान सुनिश्चित करता है कि पंक्तियों की वांछित संख्या (2) लौटा दी गई है।
SQL Server 2008 R2 पर वास्तविक निष्पादन योजना है:
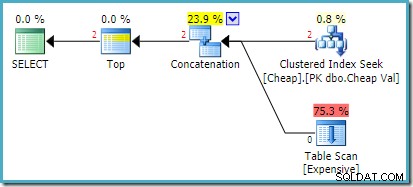
लौटाई गई दोनों पंक्तियाँ पुन:व्यवस्थित खोज इनपुट से आती हैं, और टेबल स्कैन बिल्कुल भी निष्पादित नहीं होता है। प्लान एक्सप्लोरर पंक्तियों की संख्या को लाल रंग में दिखाता है क्योंकि अनुमान एक पंक्ति के लिए था (संकेत के कारण) जबकि दो पंक्तियों का सामना रन टाइम पर हुआ था।
यूनियन ऑल के बिना
यह समस्या UNION ALL . के साथ स्पष्ट रूप से लिखे गए प्रश्नों तक ही सीमित नहीं है . अन्य निर्माण जैसे EXISTS और OR ऑप्टिमाइज़र के परिणामस्वरूप एक संयोजन ऑपरेटर शुरू हो सकता है, जो इनपुट रीऑर्डरिंग की कमी से पीड़ित हो सकता है। इस मुद्दे के साथ डेटाबेस प्रशासक स्टैक एक्सचेंज पर हाल ही में एक प्रश्न था। हमारे उदाहरण तालिकाओं का उपयोग करने के लिए उस प्रश्न से क्वेरी को बदलना:
सेलेक्ट केस जब मौजूद हो (dbo से 1 चुनें.;
SQL सर्वर 2016 पर निष्पादन योजना में पहले इनपुट पर हीप तालिका है:
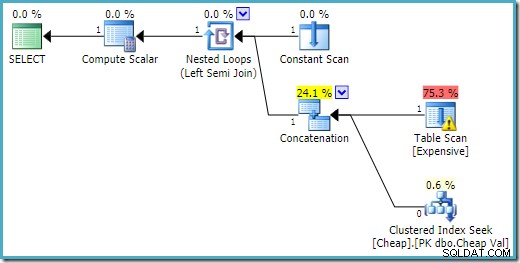
SQL सर्वर 2008 R2 पर इनपुट के क्रम को सेमी जॉइन के एकल पंक्ति लक्ष्य को प्रतिबिंबित करने के लिए अनुकूलित किया गया है:
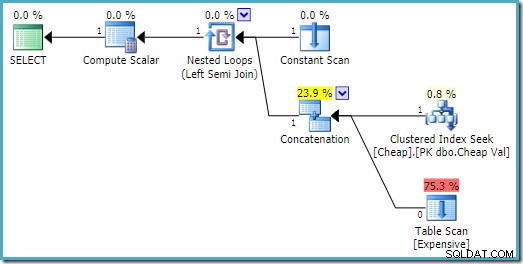
अधिक इष्टतम योजना में, हीप स्कैन कभी निष्पादित नहीं किया जाता है।
समाधान
कुछ मामलों में, क्वेरी लेखक के लिए यह स्पष्ट होगा कि एक संयोजन इनपुट हमेशा दूसरों की तुलना में चलाने के लिए सस्ता होगा। यदि यह सच है, तो क्वेरी को फिर से लिखना काफी मान्य है ताकि सस्ता कॉन्सटेनेशन इनपुट पहले लिखित क्रम में दिखाई दे। बेशक इसका मतलब है कि क्वेरी लेखक को इस अनुकूलक सीमा के बारे में पता होना चाहिए, और अनियंत्रित व्यवहार पर भरोसा करने के लिए तैयार रहना चाहिए।
एक अधिक कठिन मुद्दा तब उत्पन्न होता है जब संयोजन इनपुट की लागत परिस्थितियों के साथ बदलती है, शायद पैरामीटर मानों के आधार पर। OPTION (RECOMPILE) का उपयोग करना SQL सर्वर 2012 या बाद में मदद नहीं करेगा। वह विकल्प SQL Server 2008 R2 या इससे पहले के संस्करण में सहायता कर सकता है, लेकिन केवल तभी जब एकल पंक्ति लक्ष्य आवश्यकता भी पूरी हो।
यदि देखे गए व्यवहार पर भरोसा करने के बारे में चिंताएं हैं (क्वेरी प्लान कॉन्सटेनेशन इनपुट क्वेरी टेक्स्ट ऑर्डर से मेल खाते हैं) तो योजना के आकार को लागू करने के लिए एक योजना गाइड का उपयोग किया जा सकता है। जहां अलग-अलग परिस्थितियों के लिए अलग-अलग इनपुट ऑर्डर इष्टतम होते हैं, वहां कई प्लान गाइड का उपयोग किया जा सकता है, जहां शर्तों को पहले से सटीक रूप से कोडित किया जा सकता है। हालांकि यह शायद ही आदर्श है।
अंतिम विचार
SQL सर्वर क्वेरी ऑप्टिमाइज़र में वास्तव में एक लागत-आधारित होता है अन्वेषण नियम, UNIAReorderInputs , जो लागत-आधारित अनुकूलन के दौरान संयोजन इनपुट ऑर्डर विविधताएं उत्पन्न करने और विकल्पों की खोज करने में सक्षम है (न कि एकल-शॉट पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन के रूप में)।
यह नियम वर्तमान में सामान्य उपयोग के लिए सक्षम नहीं है। जहां तक मैं बता सकता हूं, यह केवल तभी सक्रिय होता है जब कोई योजना मार्गदर्शिका या USE PLAN संकेत मौजूद है। यह इंजन को एक ऐसी योजना को सफलतापूर्वक लागू करने की अनुमति देता है जो एक क्वेरी के लिए उत्पन्न हुई थी जो इनपुट-रीऑर्डरिंग पुनर्लेखन के लिए योग्य थी, तब भी जब वर्तमान क्वेरी योग्य नहीं होती है।
मेरी समझ यह है कि यह अन्वेषण नियम जानबूझकर इस उपयोग तक सीमित है, क्योंकि लागत-आधारित अनुकूलन के हिस्से के रूप में संयोजन इनपुट पुन:क्रम से लाभान्वित होने वाले प्रश्नों को पर्याप्त रूप से सामान्य नहीं माना जाता है, या शायद इसलिए कि चिंता है कि अतिरिक्त प्रयास का भुगतान नहीं होगा बंद। मेरा अपना विचार है कि जब कोई पंक्ति लक्ष्य प्रभावी हो तो Concatenation ऑपरेटर इनपुट रीऑर्डरिंग को हमेशा एक्सप्लोर किया जाना चाहिए।
यह भी शर्म की बात है कि (अधिक सीमित) पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन SQL सर्वर 2012 या बाद में प्रभावी नहीं है। यह एक सूक्ष्म बग के कारण हो सकता है, लेकिन मुझे इसके बारे में दस्तावेज़ीकरण, ज्ञानकोष, या कनेक्ट पर कुछ भी नहीं मिला। मैंने यहां एक नया कनेक्ट आइटम जोड़ा है।
अपडेट 9 अगस्त 2017 :यह अब तय है SQL सर्वर 2014 और 2016 के लिए ट्रेस फ़्लैग 4199 के अंतर्गत, KB 4023419 देखें:
FIX:UNION ALL के साथ क्वेरी और एक पंक्ति लक्ष्य SQL Server 2014 या बाद के संस्करणों में धीमी गति से चल सकता है जब इसकी तुलना SQL Server 2008 R2 से की जाती है



