इन-मेमोरी OLTP के बारे में लेखों की श्रृंखला में यह पहला लेख है। यह आपको यह समझने में मदद करता है कि नया हेकाटन इंजन आंतरिक रूप से कैसे काम करता है। हम इन-मेमोरी अनुकूलित टेबल और इंडेक्स के विवरण पर ध्यान केंद्रित करेंगे। यह प्रवेश स्तर का लेख है, जिसका अर्थ है कि आपको SQL सर्वर विशेषज्ञ होने की आवश्यकता नहीं है, हालाँकि, आपको पारंपरिक SQL सर्वर इंजन के बारे में कुछ बुनियादी ज्ञान की आवश्यकता है।
परिचय
SQL सर्वर 2014 इन-मेमोरी OLTP इंजन (हेकाटन प्रोजेक्ट) उपलब्ध मेमोरी के टेराबाइट्स और बड़ी संख्या में प्रोसेसिंग कोर का उपयोग करने के लिए ग्राउंड जीरो से बनाया गया था। इन-मेमोरी ओएलटीपी उपयोगकर्ताओं को मेमोरी-ऑप्टिमाइज़्ड टेबल और इंडेक्स और मूल रूप से संकलित संग्रहीत प्रक्रियाओं के साथ काम करने की अनुमति देता है। आप इसका उपयोग डिस्क-आधारित तालिकाओं और अनुक्रमणिकाओं और T-SQL संग्रहीत कार्यविधियों के साथ कर सकते हैं, जो SQL सर्वर हमेशा प्रदान करता है।
इन-मेमोरी ओएलटीपी इंजन आंतरिक और क्षमताएं मानक रिलेशनल इंजन से काफी भिन्न हैं। एकाधिक समवर्ती प्रक्रियाओं को कैसे संभाला जाता है, इसके बारे में आपको लगभग सभी चीजों को संशोधित करने की आवश्यकता है।
SQL सर्वर इंजन डिस्क-आधारित संग्रहण के लिए अनुकूलित है। यह प्रोसेसिंग के लिए मेमोरी में 8KB डेटा पेज पढ़ता है और संशोधनों के बाद 8KB डेटा पेज को डिस्क पर वापस लिखता है। बेशक, लेन-देन लॉग में डिस्क में परिवर्तन को सबसे पहले SQL सर्वर ठीक करता है। डिस्क से 8 केबी डेटा पेज पढ़ना और इसे वापस लिखना, बहुत अधिक I/O उत्पन्न कर सकता है और उच्च विलंबता लागत की ओर जाता है। बफ़र कैश में डेटा होने पर भी, SQL सर्वर को यह मानने के लिए डिज़ाइन किया गया है कि यह नहीं है, जो अक्षम CPU उपयोग की ओर जाता है।
पारंपरिक डिस्क-आधारित भंडारण संरचनाओं की सीमाओं को ध्यान में रखते हुए, SQL सर्वर टीम ने बड़ी मुख्य मेमोरी और बहु-कोर CPUs के लिए अनुकूलित एक डेटाबेस इंजन का निर्माण शुरू किया। टीम ने निम्नलिखित लक्ष्य निर्धारित किए:
- डेटा के लिए अनुकूलित जो पूरी तरह से मेमोरी में संग्रहीत था लेकिन SQL सर्वर के पुनरारंभ होने पर भी टिकाऊ था
- मौजूदा SQL सर्वर इंजन में पूरी तरह से एकीकृत
- OLTP संचालन के लिए बहुत उच्च प्रदर्शन
- आधुनिक CPU के लिए डिज़ाइन किया गया
SQL सर्वर इन-मेमोरी OLTP इन सभी लक्ष्यों को पूरा करता है।
इन-मेमोरी OLTP के बारे में
SQL सर्वर 2014 इन-मेमोरी OLTP डिस्क-आधारित तालिकाओं के साथ-साथ मेमोरी-अनुकूलित तालिकाओं के साथ काम करने के लिए कई तकनीकें प्रदान करता है। उदाहरण के लिए, यह आपको टी-एसक्यूएल और एसएसएमएस जैसे मानक इंटरफेस का उपयोग करके इन-मेमोरी डेटा तक पहुंचने की अनुमति देता है। निम्न उदाहरण मेमोरी ऑप्टिमाइज़्ड टेबल और इंडेक्स को इन-मेमोरी ओएलटीपी (बाईं ओर) और डिस्क-आधारित टेबल (बाईं ओर) के एक भाग के रूप में प्रदर्शित करता है, जिसमें 8 केबी डेटा पेज पढ़ने और लिखने की आवश्यकता होती है। इन-मेमोरी OLTP मूल रूप से संकलित संग्रहीत कार्यविधियों का भी समर्थन करता है और नया इन-मेमोरी OLTP कंपाइलर प्रदान करता है।
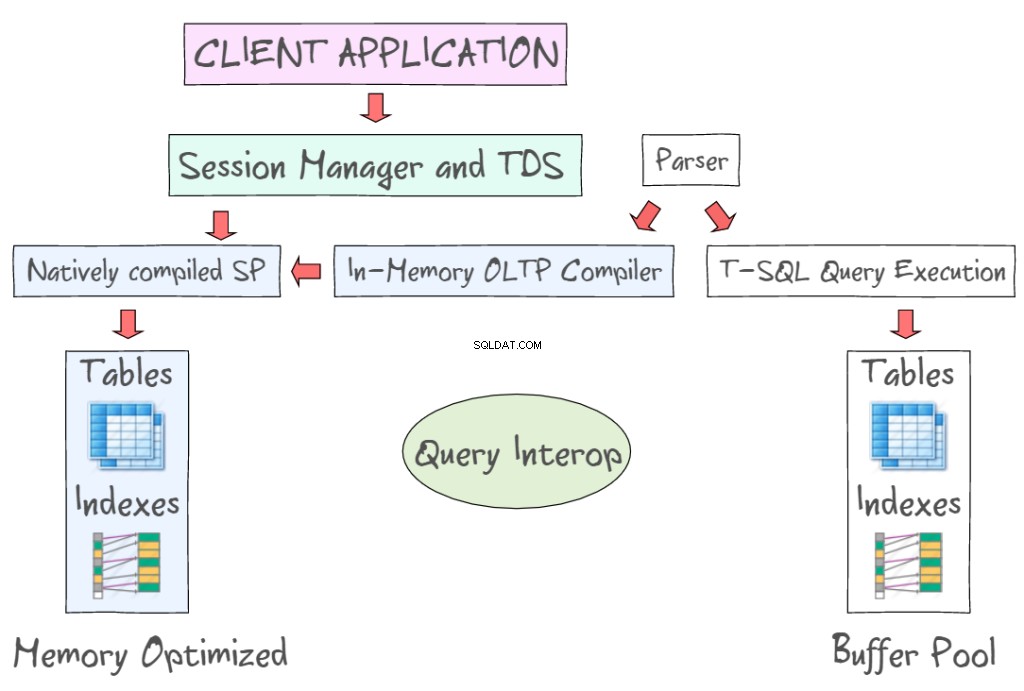
क्वेरी इंटरऑप स्मृति-अनुकूलित तालिकाओं को संदर्भित करने के लिए टी-एसक्यूएल की व्याख्या करने की अनुमति देता है। यदि कोई लेन-देन स्मृति-अनुकूलित और डिस्क-आधारित तालिकाओं दोनों को संदर्भित करता है, तो इसे s क्रॉस-कंटेनर लेनदेन के रूप में संदर्भित किया जा सकता है। क्लाइंट ऐप Tabular Data Stream का उपयोग करता है - एक एप्लिकेशन लेयर प्रोटोकॉल जिसका उपयोग डेटाबेस सर्वर और क्लाइंट के बीच डेटा ट्रांसफर करने के लिए किया जाता है। इसे शुरू में Sybase Inc. द्वारा उनके Sybase SQL सर्वर रिलेशनल डेटाबेस इंजन के लिए 1984 में और बाद में Microsoft द्वारा Microsoft SQL सर्वर में डिज़ाइन और विकसित किया गया था।
स्मृति-अनुकूलित तालिकाएं
डिस्क-आधारित तालिकाओं तक पहुँचने के दौरान, आवश्यक डेटा पहले से ही स्मृति में हो सकता है, हालाँकि यह नहीं भी हो सकता है। यदि डेटा मेमोरी में नहीं है, तो SQL सर्वर को इसे डिस्क से पढ़ने की आवश्यकता है। स्मृति-अनुकूलित तालिकाओं का उपयोग करते समय सबसे बुनियादी अंतर यह है कि संपूर्ण तालिका और उसके सूचकांक हर समय स्मृति में संग्रहीत होते हैं . समवर्ती डेटा संचालन के लिए किसी लॉकिंग या लैचिंग की आवश्यकता नहीं होती है।
जबकि एक उपयोगकर्ता इन-मेमोरी डेटा को संशोधित करता है, SQL सर्वर किसी भी तालिका के लिए कुछ डिस्क I/O करता है जिसे टिकाऊ होने की आवश्यकता होती है, अन्यथा बोलना, जहां हमें सर्वर क्रैश या पुनरारंभ होने के समय इन-मेमोरी डेटा को बनाए रखने के लिए एक टेबल की आवश्यकता होती है।
पंक्ति-आधारित संग्रहण संरचना
एक और महत्वपूर्ण अंतर अंतर्निहित भंडारण संरचना है। डिस्क-आधारित तालिकाओं को ब्लॉक-एड्रेसेबल . के लिए अनुकूलित किया गया है डिस्क भंडारण, जबकि इन-मेमोरी अनुकूलित टेबल बाइट-एड्रेसेबल . के लिए अनुकूलित हैं मेमोरी स्टोरेज।
SQL सर्वर डेटा पंक्तियों को 8K डेटा पृष्ठों में रखता है, डिस्क-आधारित तालिकाओं के लिए विस्तार से स्थान आवंटन के साथ। डेटा पेज डिस्क और मेमोरी स्टोरेज की मूलभूत इकाई है। डिस्क से डेटा पढ़ते और लिखते समय, SQL सर्वर केवल संबंधित डेटा पेजों को पढ़ता और लिखता है। एक डेटा पेज में केवल एक टेबल या इंडेक्स का डेटा होगा। एप्लिकेशन प्रक्रियाएं आवश्यकतानुसार विभिन्न डेटा पृष्ठों पर पंक्तियों को संशोधित करती हैं। बाद में, CHECKPOINT ऑपरेशन के दौरान, SQL सर्वर पहले लॉग रिकॉर्ड को डिस्क पर ठीक करता है और फिर डिस्क पर सभी गंदे पेज लिखता है। यह ऑपरेशन अक्सर बहुत सारे यादृच्छिक भौतिक I/O का कारण बनता है।
स्मृति-अनुकूलित तालिकाओं के लिए, कोई डेटा पृष्ठ नहीं हैं, साथ ही कोई विस्तार भी नहीं है। लेन-देन के क्रम में क्रमिक रूप से स्मृति में लिखी गई केवल डेटा पंक्तियाँ हैं। प्रत्येक पंक्ति में अगली पंक्ति के लिए एक सूचकांक सूचक होता है। सभी I/O इन संरचनाओं की इन-मेमोरी स्कैनिंग है। डेटा पंक्तियों को किसी विशेष स्थान पर लिखे जाने की कोई धारणा नहीं है जो किसी निर्दिष्ट वस्तु से संबंधित है। हालाँकि, आपको यह सोचने की ज़रूरत नहीं है कि स्मृति-अनुकूलित तालिकाओं को डेटा पंक्तियों के असंगठित सेट (डिस्क-आधारित ढेर के समान) के रूप में संग्रहीत किया जाता है। स्मृति-अनुकूलित तालिका के लिए प्रत्येक तालिका बनाएँ कथन कम से कम एक अनुक्रमणिका बनाता है जो SQL सर्वर उस तालिका में सभी डेटा पंक्तियों को एक साथ जोड़ने के लिए उपयोग करता है।
प्रत्येक एकल डेटा पंक्ति में पंक्ति शीर्षलेख और पेलोड होता है जो वास्तविक कॉलम डेटा होता है। हेडर उस कथन के बारे में जानकारी संग्रहीत करता है जिसने पंक्ति बनाई, लक्ष्य तालिका पर प्रत्येक अनुक्रमणिका के लिए पॉइंटर्स, और टाइमस्टैम्प मान। टाइमस्टैम्प उस समय को इंगित करता है जब कोई लेन-देन एक पंक्ति को सम्मिलित और हटाता है। SQL सर्वर रिकॉर्ड एक नया पंक्ति संस्करण सम्मिलित करके और पुराने संस्करण को हटाए गए के रूप में चिह्नित करके अद्यतन किया जाता है। एक ही पंक्ति के कई संस्करण किसी भी समय मौजूद हो सकते हैं। यह डेटा संशोधन के दौरान एक ही पंक्ति में एक साथ पहुंच की अनुमति देता है। SQL सर्वर पंक्ति संस्करण के टाइमस्टैम्प के सापेक्ष लेन-देन शुरू होने के समय के अनुसार प्रत्येक लेनदेन के लिए प्रासंगिक पंक्ति संस्करण प्रदर्शित करता है। यह नए बहु संस्करण समवर्ती नियंत्रण का मूल है इन-मेमोरी टेबल के लिए तंत्र।
वैसे, Oracle में एक उत्कृष्ट बहु-संस्करण नियंत्रण प्रणाली है। मूल रूप से, यह निम्नानुसार काम करता है:
- उपयोगकर्ता A एक लेन-देन शुरू करता है और T1 पर कुछ मूल्य के साथ 1000 पंक्तियों को अपडेट करता है।
- उपयोगकर्ता B समय T2 पर समान 1000 पंक्तियों को पढ़ता है।
- उपयोगकर्ता A पंक्ति 565 को Y मान के साथ अपडेट करता है (मूल मान X था)।
- उपयोगकर्ता B पंक्ति 565 पर पहुंचता है और पाता है कि समय T1 से लेन-देन चल रहा है।
- डेटाबेस लॉग से असंशोधित रिकॉर्ड लौटाता है। लौटाया गया मान वह मान है जो उस समय T2 से कम या उसके बराबर किया गया था।
- यदि रिकॉर्ड को फिर से करें लॉग से पुनर्प्राप्त नहीं किया जा सकता है तो इसका मतलब है कि डेटाबेस उचित रूप से सेट नहीं किया गया है। लॉग के लिए अधिक स्थान आवंटित करने की आवश्यकता है।
- लेनदेन के प्रारंभ समय के संबंध में लौटाए गए परिणाम हमेशा समान होते हैं। तो लेन-देन के भीतर, पढ़ने की स्थिरता हासिल की जाती है।
मूल रूप से संकलित टेबल
अंतिम प्रमुख अंतर यह है कि मेमोरी में अनुकूलित टेबल मूल रूप से संकलित . हैं . जब कोई उपयोगकर्ता स्मृति-अनुकूलित तालिका या अनुक्रमणिका बनाता है, तो SQL सर्वर मेटाडेटा में प्रत्येक तालिका की संरचना (सभी अनुक्रमणिका के साथ) संग्रहीत करता है। बाद में, SQL सर्वर उस मेटाडेटा का उपयोग तालिका तक पहुँचने के लिए मूल भाषा रूटीन के एक सेट को DDL में संकलित करने के लिए करता है। ऐसे डीडीएल डेटाबेस से जुड़े होते हैं लेकिन वास्तव में इसका हिस्सा नहीं होते हैं।
दूसरे शब्दों में, SQL सर्वर इन संरचनाओं तक पहुँचने और संशोधित करने के लिए न केवल टेबल और इंडेक्स बल्कि DDL को भी मेमोरी में रखता है। एक बार तालिका बदल जाने के बाद, SQL सर्वर को तालिका संचालन के लिए सभी DDL को फिर से बनाने की आवश्यकता होती है। इसलिए आप एक बार बनाई गई तालिका को बदल नहीं सकते हैं। ये संचालन उपयोगकर्ताओं के लिए अदृश्य हैं।
मूल रूप से संकलित संग्रहीत कार्यविधियाँ
मूल रूप से संकलित तालिकाओं तक पहुँचने के लिए मूल रूप से संकलित संग्रहीत कार्यविधियों का उपयोग करते हुए सर्वोत्तम प्रदर्शन प्राप्त किया जाता है। ऐसी प्रक्रियाओं में प्रोसेसर निर्देश होते हैं और बिना किसी संकलन के सीधे सीपीयू द्वारा निष्पादित किया जा सकता है। हालांकि, मूल रूप से संकलित संग्रहीत प्रक्रियाओं (पारंपरिक रूप से व्याख्या किए गए कोड की तुलना में) के लिए टी-एसक्यूएल निर्माण पर कुछ प्रतिबंध हैं। एक और महत्वपूर्ण बात यह है कि मूल रूप से संकलित संग्रहीत कार्यविधियाँ केवल स्मृति अनुकूलित तालिकाओं तक पहुँच सकती हैं।
कोई लॉक नहीं
इन-मेमोरी OLTP एक लॉक-फ्री सिस्टम है। यह संभव है क्योंकि SQL सर्वर कभी भी किसी मौजूदा पंक्ति को संशोधित नहीं करता है। अद्यतन ऑपरेशन नया संस्करण बनाता है और पिछले संस्करण को हटाए गए के रूप में चिह्नित करता है। फिर यह इसके अंदर नए डेटा के साथ एक नया पंक्ति संस्करण सम्मिलित करता है।
सूचकांक
जैसा कि आपने अनुमान लगाया होगा, अनुक्रमित पारंपरिक लोगों से बहुत अलग हैं। इन-मेमोरी ऑप्टिमाइज़्ड टेबल में कोई पेज नहीं होता है। SQL सर्वर तालिका से संबंधित सभी पंक्तियों को एकल संरचना में जोड़ने के लिए अनुक्रमणिका का उपयोग करता है। हम इन-मेमोरी ऑप्टिमाइज़ टेबल के लिए इंडेक्स बनाने के लिए CREATE INDEX स्टेटमेंट का उपयोग नहीं कर सकते हैं। एक बार जब आप कॉलम पर प्राथमिक कुंजी बना लेते हैं, तो SQL सर्वर स्वचालित रूप से उस कॉलम पर एक अद्वितीय अनुक्रमणिका बनाता है। असल में, यह एकमात्र अनुमत अद्वितीय अनुक्रमणिका है। आप स्मृति-अनुकूलित तालिका पर अधिकतम आठ अनुक्रमणिकाएँ बना सकते हैं।
तालिकाओं के अनुरूप, SQL सर्वर स्मृति-अनुकूलित अनुक्रमणिका को स्मृति में रखता है। हालाँकि, SQL सर्वर कभी भी अनुक्रमणिका पर संचालन लॉग नहीं करता है। SQL सर्वर तालिका संशोधनों के दौरान स्वचालित रूप से अनुक्रमणिका बनाए रखता है।
स्मृति-अनुकूलित तालिकाएं दो प्रकार के अनुक्रमणिका का समर्थन करती हैं:हैश अनुक्रमणिका और श्रेणी अनुक्रमणिका . दोनों गैर-संकुल संरचनाएं हैं।
हैश इंडेक्स एक नई प्रकार की अनुक्रमणिका है, जिसे विशेष रूप से स्मृति-अनुकूलित तालिकाओं के लिए डिज़ाइन किया गया है। यह विशिष्ट मूल्यों पर लुकअप करने के लिए अत्यंत उपयोगी है। इंडेक्स को ही हैश टेबल के रूप में स्टोर किया जाता है। यह हैश बकेट की एक सरणी है, जहां प्रत्येक बकेट एक पंक्ति का सूचक है।
श्रेणी अनुक्रमणिका (गैर-संकुल) मूल्यों की श्रेणियों को पुनः प्राप्त करने के लिए उपयोगी है।
पुनर्प्राप्ति
स्मृति-अनुकूलित तालिकाओं वाले डेटाबेस के लिए मूल पुनर्स्थापना तंत्र डिस्क-आधारित तालिकाओं वाले डेटाबेस के पुनर्प्राप्ति तंत्र के समान है। हालांकि, स्मृति-अनुकूलित तालिकाओं की पुनर्प्राप्ति में उपयोगकर्ता पहुंच के लिए डेटाबेस उपलब्ध होने से पहले स्मृति-अनुकूलित तालिकाओं को स्मृति में लोड करने का चरण शामिल है।
जब SQL सर्वर पुनरारंभ होता है, तो प्रत्येक डेटाबेस पुनर्प्राप्ति प्रक्रिया के निम्नलिखित चरणों से गुजरता है:विश्लेषण , फिर से करें , और पूर्ववत करें ।
विश्लेषण चरण पर, इन-मेमोरी ओएलटीपी इंजन चेकपॉइंट इन्वेंट्री को लोड करने के लिए पहचानता है और इसकी सिस्टम टेबल लॉग प्रविष्टियों को प्रीलोड करता है। यह कुछ फ़ाइल आवंटन लॉग रिकॉर्ड को भी संसाधित करेगा।
फिर से करें चरण पर, डेटा और डेल्टा फ़ाइल जोड़े से डेटा मेमोरी में लोड किया जाता है। फिर डेटा को अंतिम टिकाऊ चेकपॉइंट के आधार पर सक्रिय लेनदेन लॉग से अपडेट किया जाता है और इन-मेमोरी टेबल को पॉप्युलेट किया जाता है और इंडेक्स को फिर से बनाया जाता है। इस चरण के दौरान, डिस्क-आधारित और स्मृति-अनुकूलित तालिका पुनर्प्राप्ति एक साथ चलती है।
स्मृति-अनुकूलित तालिकाओं के लिए पूर्ववत चरण की आवश्यकता नहीं है क्योंकि इन-मेमोरी OLTP स्मृति-अनुकूलित तालिकाओं के लिए किसी भी अनकमिटेड लेनदेन को रिकॉर्ड नहीं करता है।
जब सभी ऑपरेशन पूरे हो जाते हैं, तो डेटाबेस एक्सेस के लिए उपलब्ध हो जाता है।
सारांश
इस लेख में, हमने SQL सर्वर इन-मेमोरी OLTP इंजन पर एक त्वरित नज़र डाली। हमने सीखा है कि स्मृति-अनुकूलित संरचनाएं स्मृति में संग्रहीत होती हैं। एप्लिकेशन प्रक्रियाएं डिस्क I/O की आवश्यकता के बिना स्मृति में इन संरचनाओं तक पहुंच कर आवश्यक डेटा प्राप्त कर सकती हैं। निम्नलिखित लेखों में, हम देखेंगे कि इन-मेमोरी OLTP डेटाबेस और तालिकाओं को कैसे बनाया और एक्सेस किया जाए।
आगे पढ़ना
इन-मेमोरी OLTP:SQL सर्वर 2016 में नया क्या है
SQL सर्वर मेमोरी-ऑप्टिमाइज़्ड टेबल्स में इंडेक्स का उपयोग करना



