पिछले ब्लॉग में, हमने चर्चा की थी कि क्लस्टर डेटाबेस के आधार पर एक स्टैंडअलोन मूडल सेटअप को स्केलेबल सेटअप में कैसे माइग्रेट किया जाए। अगला कदम जिसके बारे में आपको सोचना होगा वह है फेलओवर मैकेनिज्म - अगर आपकी डेटाबेस सेवा बंद हो जाती है तो आप क्या करते हैं।
एक विफल डेटाबेस सर्वर असामान्य नहीं है यदि आपके पास अपने बैकएंड मूडल डेटाबेस के रूप में MySQL प्रतिकृति है, और यदि ऐसा होता है, तो आपको अपनी टोपोलॉजी को पुनर्प्राप्त करने का एक तरीका खोजने की आवश्यकता होगी, उदाहरण के लिए एक स्टैंडबाय सर्वर को बढ़ावा देना एक नया प्राथमिक सर्वर बनें। आपके Moodle MySQL डेटाबेस के लिए स्वचालित फ़ेलओवर होने से एप्लिकेशन अपटाइम में मदद मिलती है। हम बताएंगे कि फ़ेलओवर मैकेनिज़्म कैसे काम करता है, और आपके सेटअप में स्वचालित फ़ेलओवर कैसे बनाया जाता है।
MySQL डेटाबेस के लिए उच्च उपलब्धता आर्किटेक्चर
आपके MySQL डेटाबेस को दो अलग-अलग तरीकों से क्लस्टर करके उच्च उपलब्धता आर्किटेक्चर प्राप्त किया जा सकता है। आप MySQL प्रतिकृति का उपयोग कर सकते हैं, कई प्रतिकृतियां सेट कर सकते हैं जो आपके प्राथमिक डेटाबेस का बारीकी से पालन करते हैं। उसके ऊपर, आप पढ़ने/लिखने के ट्रैफ़िक को विभाजित करने के लिए एक डेटाबेस लोड बैलेंसर रख सकते हैं, और ट्रैफ़िक को रीड-राइट और रीड-ओनली नोड्स में वितरित कर सकते हैं। MySQL प्रतिकृति का उपयोग करते हुए डेटाबेस उच्च उपलब्धता वास्तुकला को नीचे वर्णित किया जा सकता है:
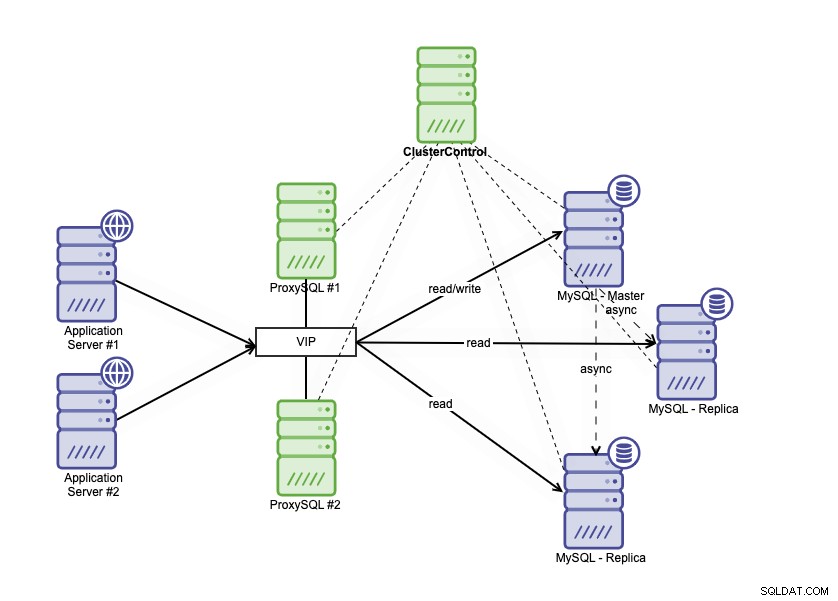
इसमें एक प्राथमिक डेटाबेस, दो डेटाबेस प्रतिकृतियां और डेटाबेस लोड बैलेंसर शामिल हैं। (इस ब्लॉग में, हम ProxySQL को डेटाबेस लोड बैलेंसर के रूप में उपयोग करते हैं), और ProxySQL प्रक्रियाओं की निगरानी के लिए एक सेवा के रूप में बनाए रखा जाता है। हम एप्लिकेशन से एकल कनेक्शन के रूप में वर्चुअल आईपी एड्रेस का उपयोग करते हैं। सक्रिय लोड बैलेंसर को ट्रैफिक को कीपलाइव में रोल फ्लैग के आधार पर वितरित किया जाएगा।
ProxySQL ट्रैफ़िक का विश्लेषण करने और यह समझने में सक्षम है कि अनुरोध पढ़ा गया है या लिखा गया है। इसके बाद यह अनुरोध को उपयुक्त होस्ट (होस्टों) को अग्रेषित करेगा।
MySQL प्रतिकृति पर विफलता
MySQL प्रतिकृति प्राथमिक से प्रतिकृतियों में डेटा को दोहराने के लिए बाइनरी लॉगिंग का उपयोग करती है। प्रतिकृतियां प्राथमिक नोड से जुड़ती हैं, और प्रत्येक परिवर्तन को दोहराया जाता है और IO_THREAD के माध्यम से प्रतिकृति नोड्स के रिले लॉग में लिखा जाता है। रिले लॉग में परिवर्तन संग्रहीत होने के बाद, SQL_THREAD प्रक्रिया प्रतिकृति डेटाबेस में डेटा लागू करने के साथ आगे बढ़ेगी।
प्रतिलिपि में read_only पैरामीटर के लिए डिफ़ॉल्ट सेटिंग चालू है। इसका उपयोग प्रतिकृति को किसी भी प्रत्यक्ष लेखन से बचाने के लिए किया जाता है, इसलिए परिवर्तन हमेशा प्राथमिक डेटाबेस से आएंगे। यह महत्वपूर्ण है क्योंकि हम नहीं चाहते कि प्रतिकृति प्राथमिक सर्वर से अलग हो जाए। MySQL प्रतिकृति में विफलता परिदृश्य तब होता है जब प्राथमिक पहुंच योग्य नहीं होता है। इसके कई कारण हो सकते हैं; उदा., सर्वर क्रैश या नेटवर्क समस्याएँ।
आपको प्रतिकृतियों में से एक को प्राथमिक में प्रचारित करने की आवश्यकता है, प्रचारित प्रतिकृति पर केवल-पढ़ने के लिए पैरामीटर अक्षम करें ताकि यह लिखने योग्य हो सके। नए प्राथमिक से कनेक्ट करने के लिए आपको अन्य प्रतिकृति को भी बदलना होगा। जीटीआईडी मोड में, आपको बाइनरी लॉग नाम और स्थिति को नोट करने की आवश्यकता नहीं है जहां से प्रतिकृति को फिर से शुरू करना है। हालांकि, पारंपरिक बिनलॉग आधारित प्रतिकृति में, आपको निश्चित रूप से अंतिम बाइनरी लॉग नाम और स्थिति जानने की जरूरत है जिससे आगे बढ़ना है। बिनलॉग आधारित प्रतिकृति में विफलता काफी जटिल प्रक्रिया है, लेकिन जीटीआईडी आधारित प्रतिकृति में विफलता भी मामूली नहीं है क्योंकि आपको गलत लेनदेन जैसी चीजों को देखने की जरूरत है। विफलता का पता लगाना एक बात है, और फिर थोड़ी देर के भीतर विफलता पर प्रतिक्रिया करना स्वचालन के बिना संभव नहीं है।
ClusterControl स्वचालित विफलता को कैसे सक्षम करता है
ClusterControl में आपके Moodle MySQL डेटाबेस के लिए स्वचालित फ़ेलओवर करने की क्षमता है। क्लस्टर और नोड सुविधा के लिए एक स्वचालित पुनर्प्राप्ति है जो डेटाबेस प्राथमिक क्रैश होने पर विफलता प्रक्रिया को ट्रिगर करेगा।
हम अनुकरण करेंगे कि ClusterControl में स्वचालित विफलता कैसे होती है। हम प्राथमिक डेटाबेस को क्रैश कर देंगे, और बस ClusterControl डैशबोर्ड पर देखेंगे। नीचे क्लस्टर की वर्तमान टोपोलॉजी है:
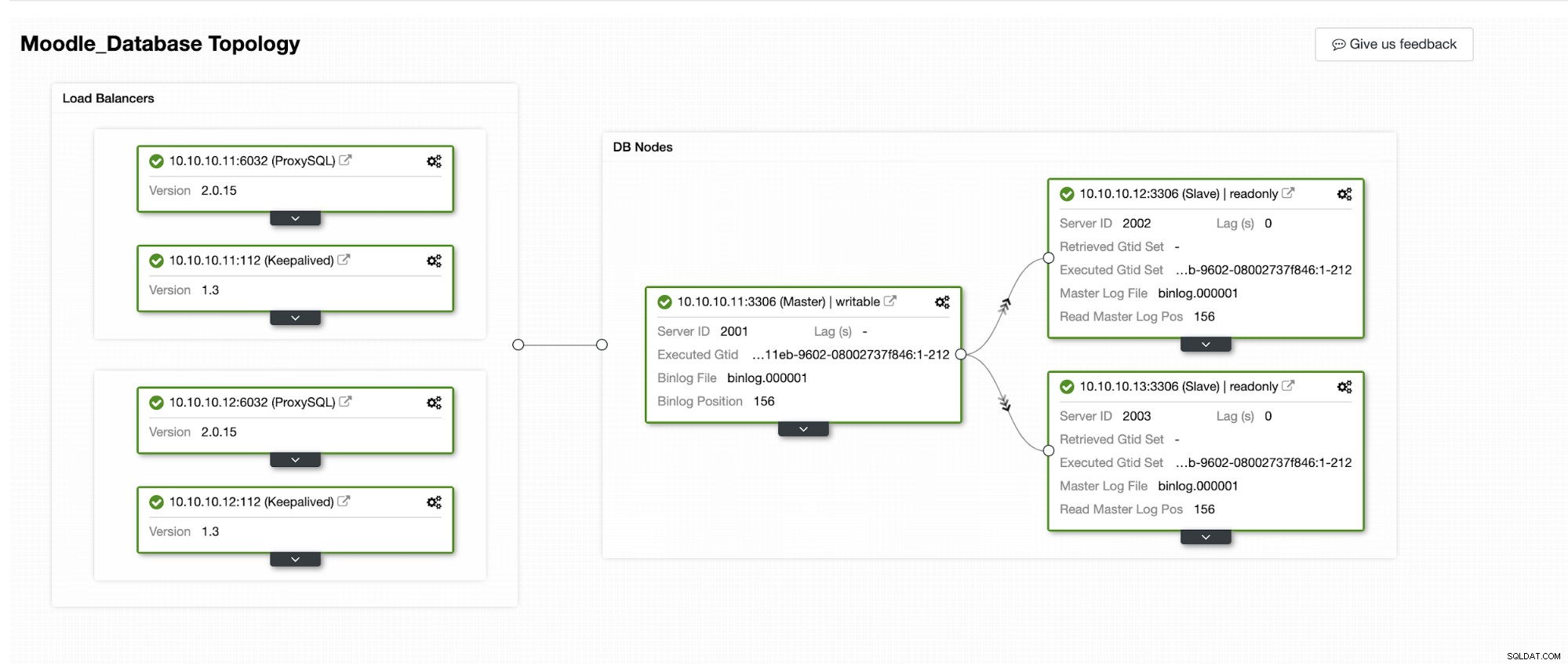
डेटाबेस प्राथमिक आईपी एड्रेस 10.10.10.11 का उपयोग कर रहा है और प्रतिकृतियां हैं:10.10.10.12 और 10.10.10.13। जब प्राथमिक पर क्रैश होता है, तो ClusterControl एक अलर्ट ट्रिगर करता है और एक विफलता शुरू हो जाती है जैसा कि नीचे दी गई तस्वीर में दिखाया गया है:
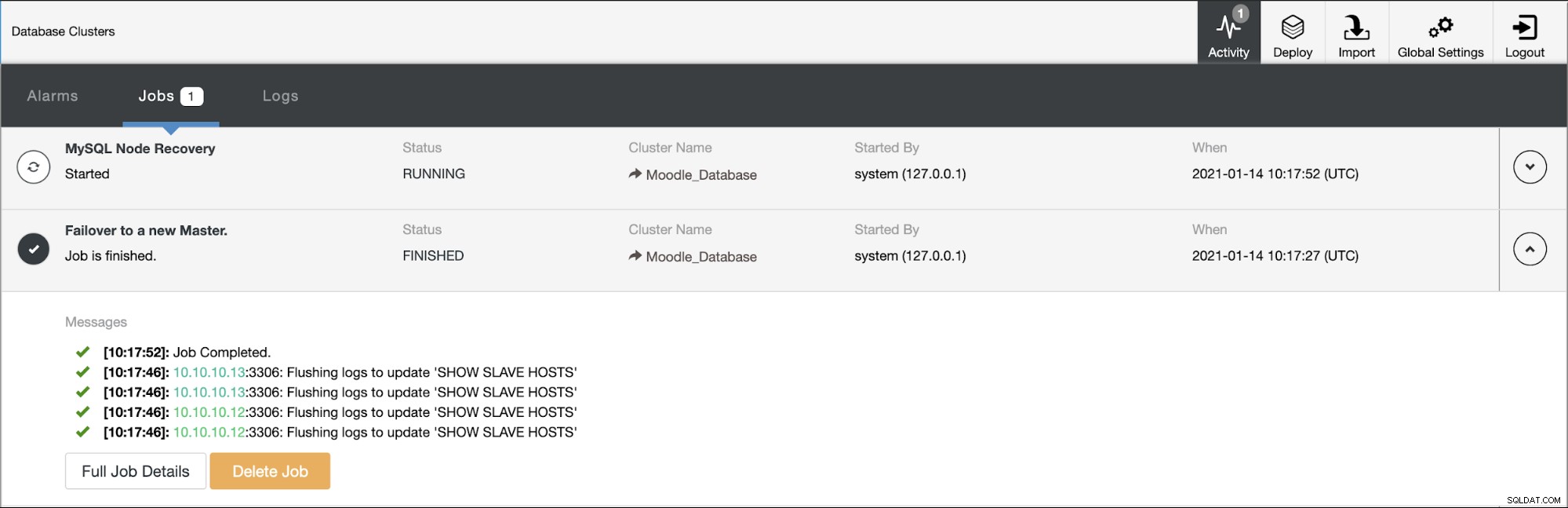
प्रतिलिपियों में से एक को प्राथमिक में पदोन्नत किया जाएगा, जिसके परिणामस्वरूप टोपोलॉजी इस प्रकार होगी नीचे दी गई तस्वीर में:
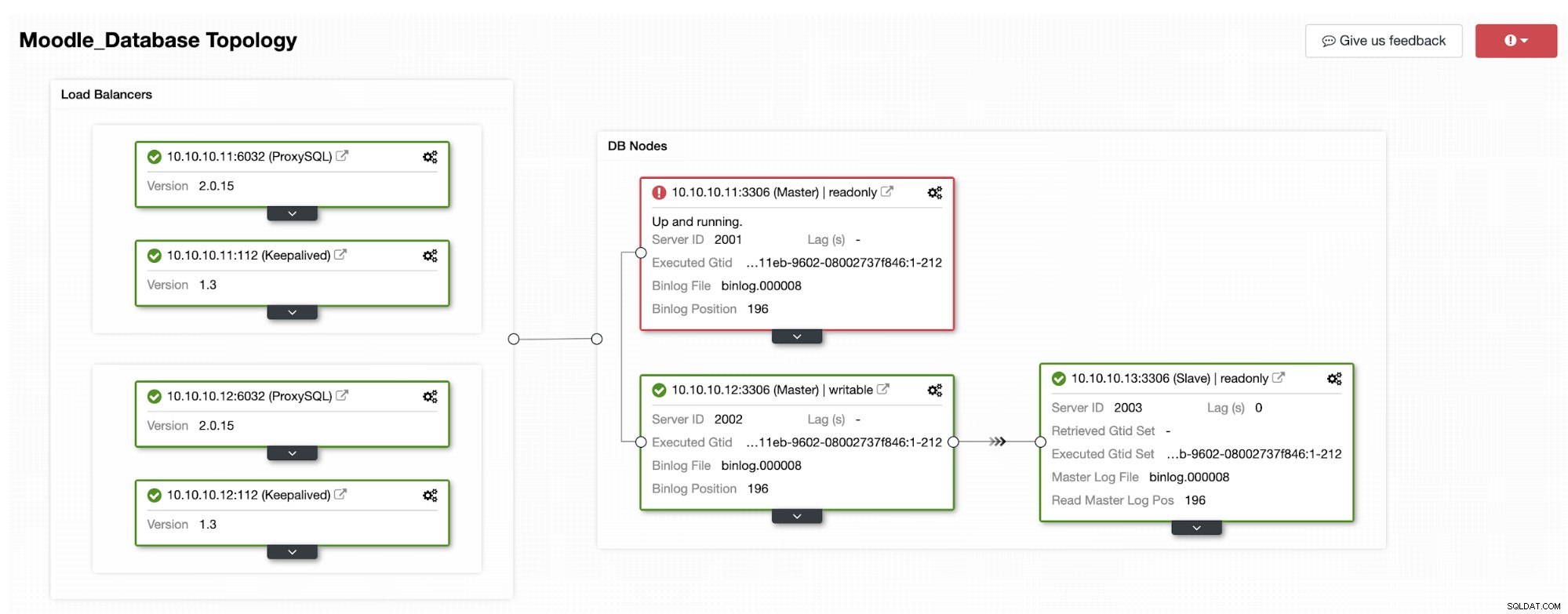
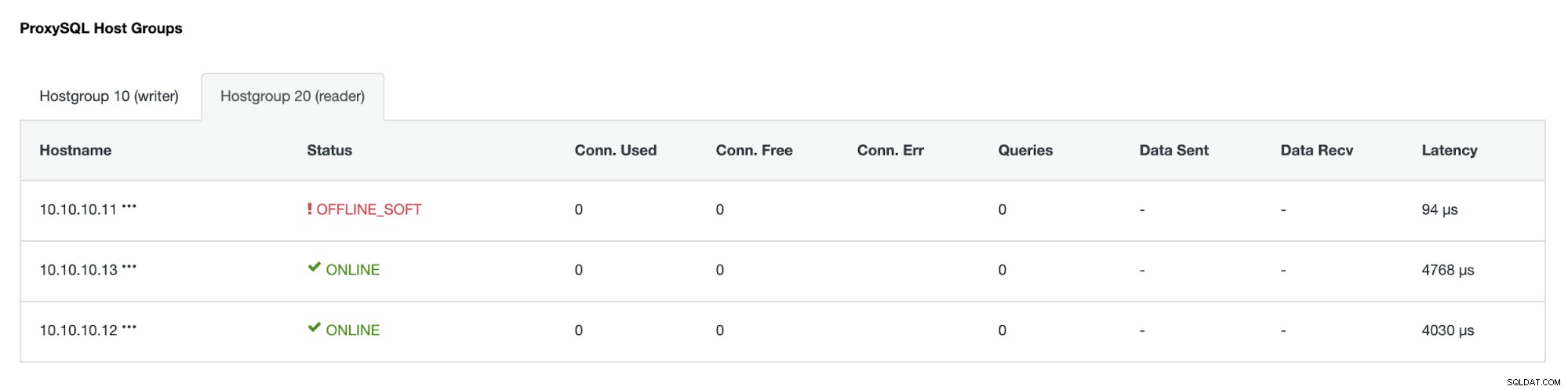
आईपी एड्रेस 10.10.10.12 अब राइट ट्रैफिक को प्राथमिक के रूप में पेश कर रहा है, और साथ ही हमारे पास केवल एक प्रतिकृति बची है जिसका IP पता 10.10.10.13 है। प्रॉक्सीएसक्यूएल पक्ष पर, प्रॉक्सी स्वचालित रूप से नए प्राथमिक का पता लगाएगा। होस्टग्रुप (HG10) अभी भी लिखने वाले ट्रैफ़िक की सेवा करता है जिसका सदस्य 10.10.10.12 है जैसा कि नीचे दिखाया गया है:

होस्टग्रुप (HG20) अभी भी रीड ट्रैफिक प्रदान कर सकता है, लेकिन जैसा कि आप देख सकते हैं दुर्घटना के कारण नोड 10.10.10.11 ऑफ़लाइन है:
एक बार जब प्राथमिक विफल सर्वर ऑनलाइन वापस आ जाता है, तो यह स्वचालित रूप से पुनः नहीं होगा -डेटाबेस टोपोलॉजी में पेश किया गया। यह समस्या निवारण जानकारी को खोने से बचने के लिए है, क्योंकि नोड को प्रतिकृति के रूप में पुन:प्रस्तुत करने के लिए कुछ लॉग या अन्य जानकारी को अधिलेखित करने की आवश्यकता हो सकती है। लेकिन विफल नोड के ऑटो-रिजॉइन को कॉन्फ़िगर करना संभव है।