
बहुत बार मैंने लोगों को शिकायत करते हुए देखा है कि कैसे उनके लेन-देन लॉग ने उनकी हार्ड डिस्क पर कब्जा कर लिया। कई बार यह पता चलता है कि वे एक बड़े लेन-देन में एक बड़ा डिलीट ऑपरेशन कर रहे थे, जैसे डेटा को शुद्ध करना या संग्रहित करना।
मैं अवधि और लेन-देन लॉग दोनों पर प्रभाव दिखाने के लिए कुछ परीक्षण चलाना चाहता था, एक ही लेनदेन बनाम एक ही लेनदेन में एक ही डेटा ऑपरेशन करने के लिए। मैंने एक डेटाबेस बनाया और इसे एक बड़ी तालिका के साथ भर दिया SalesOrderDetailEnlarged ,
तालिका को पॉप्युलेट करने के बाद, मैंने डेटाबेस का बैकअप लिया, लॉग का बैकअप लिया, और एक DBCC SHRINKFILE चलाया। (मुझे गोली मत मारो) ताकि लॉग फ़ाइल पर प्रभाव एक आधार रेखा से स्थापित किया जा सके (यह अच्छी तरह से जानते हुए कि ये संचालन * लेन-देन लॉग बढ़ने का कारण बनेंगे)।
मैंने एसएसडी के विपरीत जानबूझकर एक यांत्रिक डिस्क का उपयोग किया। जबकि हम एसएसडी में जाने की अधिक लोकप्रिय प्रवृत्ति को देखना शुरू कर सकते हैं, यह अभी तक बड़े पैमाने पर नहीं हुआ है; कई मामलों में बड़े भंडारण उपकरणों में ऐसा करना अभी भी बहुत महंगा है।
परीक्षा
तो आगे मुझे यह निर्धारित करना था कि मैं सबसे बड़े प्रभाव के लिए क्या परीक्षण करना चाहता हूं। चूंकि मैं कल ही एक सहकर्मी के साथ डेटा को टुकड़ों में हटाने के बारे में चर्चा में शामिल था, इसलिए मैंने हटाना चुना। और चूंकि इस टेबल पर क्लस्टर इंडेक्स SalesOrderID . पर है , मैं इसका उपयोग नहीं करना चाहता था - यह बहुत आसान होगा (और वास्तविक जीवन में हटाए जाने के तरीके से बहुत ही कम मेल खाएगा)। इसलिए मैंने इसके बजाय ProductID . की एक श्रृंखला के बाद जाने का फैसला किया मान, जो सुनिश्चित करेगा कि मैं बड़ी संख्या में पृष्ठों को हिट करूंगा और बहुत अधिक लॉगिंग की आवश्यकता होगी। मैंने निम्न क्वेरी द्वारा निर्धारित किया कि कौन से उत्पादों को हटाना है:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
इससे निम्नलिखित परिणाम प्राप्त हुए:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
यह 456,960 पंक्तियों (तालिका का लगभग 10%) को हटा देगा, जो कई आदेशों में फैली हुई है। यह इस संदर्भ में एक वास्तविक संशोधन नहीं है, क्योंकि यह पूर्व-गणना किए गए ऑर्डर के योग के साथ खिलवाड़ करेगा, और आप वास्तव में किसी उत्पाद को पहले से शिप किए गए ऑर्डर से नहीं हटा सकते हैं। लेकिन एक डेटाबेस का उपयोग करना जिसे हम सभी जानते हैं और पसंद करते हैं, यह एक फोरम साइट से उपयोगकर्ता को हटाने, और उनके सभी संदेशों को हटाने के समान है - एक वास्तविक परिदृश्य जिसे मैंने जंगली में देखा है।
तो एक परीक्षण निम्नलिखित करना होगा, एक-शॉट हटाना:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
मुझे पता है कि इसके लिए बड़े पैमाने पर स्कैन की आवश्यकता होगी और लेन-देन लॉग पर भारी असर पड़ेगा। ऐसी बात है। :-)
जब वह चल रहा था, मैंने एक अलग स्क्रिप्ट को एक साथ रखा जो इस डिलीट को विखंडू में करेगा:एक समय में 25,000, 50,000, 75,000 और 100,000 पंक्तियाँ। प्रत्येक खंड अपने स्वयं के लेन-देन में प्रतिबद्ध होगा (ताकि यदि आपको स्क्रिप्ट को रोकने की आवश्यकता है, तो आप कर सकते हैं, और सभी पिछले भाग पहले से ही शुरू होने के बजाय प्रतिबद्ध होंगे), और पुनर्प्राप्ति मॉडल के आधार पर, का पालन किया जाएगा CHECKPOINT . द्वारा या तो या एक BACKUP LOG लेन-देन लॉग पर चल रहे प्रभाव को कम करने के लिए। (मैं इन ऑपरेशनों के बिना भी परीक्षण करूंगा।) यह कुछ इस तरह दिखाई देगा (मैं इस परीक्षण के लिए त्रुटि प्रबंधन और अन्य बारीकियों से परेशान नहीं होने जा रहा हूं, लेकिन आपको उतना नहीं होना चाहिए):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
बेशक, प्रत्येक परीक्षण के बाद, मैं डेटाबेस के मूल बैकअप को पुनर्स्थापित कर दूंगा WITH REPLACE, RECOVERY के साथ , उसके अनुसार पुनर्प्राप्ति मॉडल सेट करें, और अगला परीक्षण चलाएँ।
परिणाम
पहले परीक्षण का परिणाम बिल्कुल भी आश्चर्यजनक नहीं था। एक ही स्टेटमेंट में डिलीट को करने में, 42 सेकंड का पूरा समय और 43 सेकंड का साधारण समय लगता है। दोनों ही मामलों में इसने लॉग को 579 एमबी तक बढ़ा दिया।
परीक्षणों के अगले सेट में मेरे लिए कुछ आश्चर्य थे। एक यह है कि, जबकि इन चंकिंग विधियों ने लॉग फ़ाइल पर प्रभाव को काफी कम कर दिया, केवल कुछ संयोजन अवधि के करीब आए, और कोई भी वास्तव में तेज़ नहीं था। एक और यह है कि, सामान्य रूप से, पूर्ण पुनर्प्राप्ति में (चरणों के बीच लॉग बैकअप किए बिना) सरल पुनर्प्राप्ति में समकक्ष संचालन से बेहतर प्रदर्शन किया। यहां अवधि और लॉग प्रभाव के परिणाम दिए गए हैं:
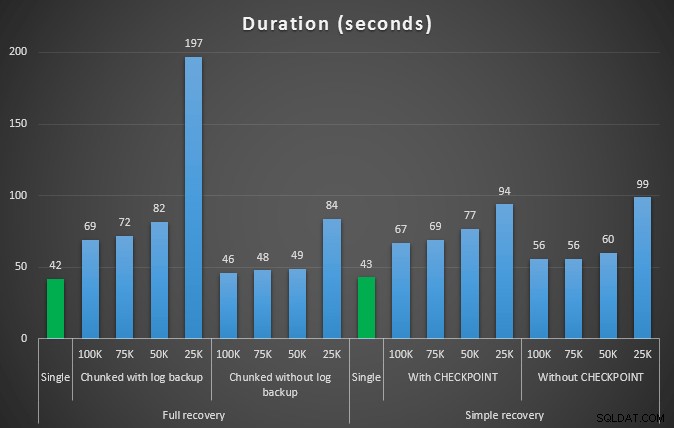
अवधि, सेकंडों में, 457K पंक्तियों को हटाते हुए विभिन्न डिलीट ऑपरेशनों की अवधि
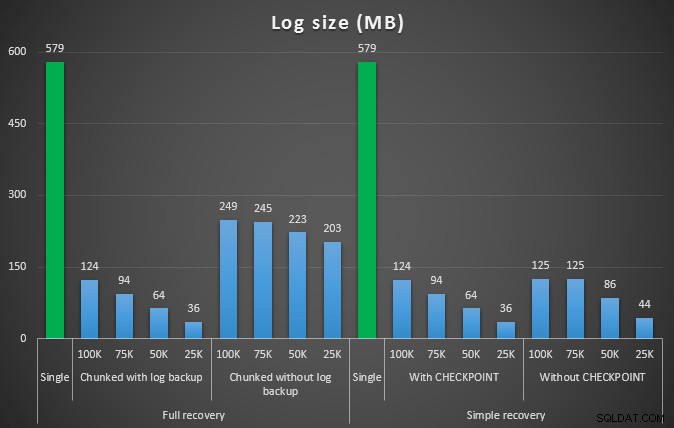
लॉग साइज, एमबी में, विभिन्न डिलीट ऑपरेशन के बाद 457K पंक्तियों को हटाते हुए
फिर से, सामान्य तौर पर, जबकि लॉग का आकार काफी कम हो जाता है, अवधि बढ़ जाती है। आप इस प्रकार के पैमाने का उपयोग यह निर्धारित करने के लिए कर सकते हैं कि डिस्क स्थान पर प्रभाव को कम करना या खर्च किए गए समय की मात्रा को कम करना अधिक महत्वपूर्ण है या नहीं। अवधि में एक छोटे से हिट के लिए (और आखिरकार, इनमें से अधिकतर प्रक्रियाएं पृष्ठभूमि में चलती हैं), लॉग स्पेस उपयोग में आपके पास महत्वपूर्ण बचत (इन परीक्षणों में 94% तक) हो सकती है।
ध्यान दें कि मैंने इनमें से किसी भी परीक्षण को संपीड़न सक्षम (संभवतः भविष्य का परीक्षण!) यह भयानक सेटिंग।
लेकिन क्या होगा यदि मेरे पास अधिक डेटा है?
आगे मैंने सोचा कि मुझे इसे थोड़े बड़े डेटाबेस पर परखना चाहिए। इसलिए मैंने एक और डेटाबेस बनाया और dbo.SalesOrderDetailEnlarged की एक नई, बड़ी कॉपी बनाई . वास्तव में लगभग दस गुना बड़ा। इस बार SalesOrderID, SalesorderDetailID . पर प्राथमिक कुंजी के बजाय , मैंने इसे अभी एक संकुल अनुक्रमणिका (डुप्लिकेट के लिए अनुमति देने के लिए) बनाया है, और इसे इस तरह से पॉप्युलेट किया है:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); पर गैर-संकुल अनुक्रमणिका बनाएं डिस्क स्थान की सीमाओं के कारण, मुझे इस परीक्षण के लिए अपने लैपटॉप के वीएम से दूर जाना पड़ा (और 128 जीबी रैम के साथ 40-कोर बॉक्स चुना, जो कि अर्ध-निष्क्रिय :-) के आसपास बैठे थे), और फिर भी यह किसी भी तरह से एक त्वरित प्रक्रिया नहीं थी। तालिका की जनसंख्या और अनुक्रमणिका के निर्माण में ~24 मिनट लगे।
तालिका में 48.5 मिलियन पंक्तियाँ हैं और डिस्क में 7.9 GB (डेटा में 4.9 GB, और अनुक्रमणिका में 2.9 GB) है।
इस बार, उम्मीदवार का एक अच्छा सेट निर्धारित करने के लिए मेरी क्वेरी ProductID मिटाने के लिए मान:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
निम्नलिखित परिणाम दिए:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
इसलिए हम 4,455,360 पंक्तियों को हटाने जा रहे हैं, जो तालिका के 10% से थोड़ा कम है। उपरोक्त परीक्षण के समान पैटर्न का अनुसरण करते हुए, हम सभी को एक शॉट में हटा देंगे, फिर 500,000, 250,000 और 100,000 पंक्तियों में।
परिणाम:
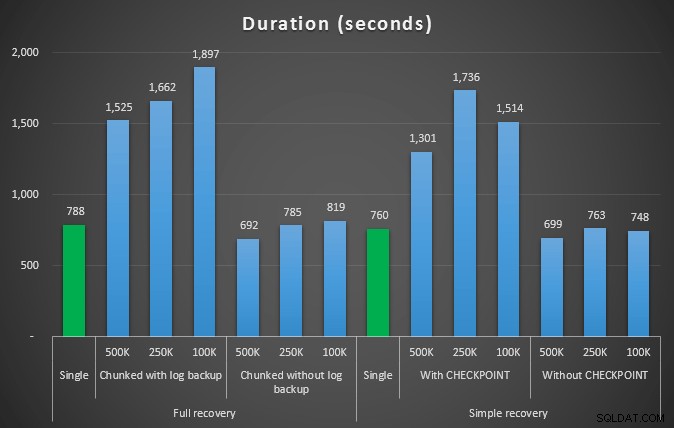 अवधि, सेकंड में, 4.5MM पंक्तियों को हटाकर विभिन्न डिलीट ऑपरेशनों की अवधि
अवधि, सेकंड में, 4.5MM पंक्तियों को हटाकर विभिन्न डिलीट ऑपरेशनों की अवधि
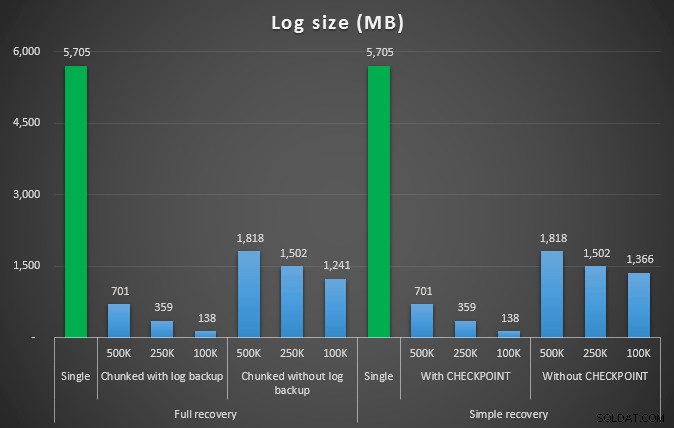 लॉग आकार, एमबी में, 4.5MM पंक्तियों को हटाने के बाद विभिन्न डिलीट ऑपरेशन के बाद
लॉग आकार, एमबी में, 4.5MM पंक्तियों को हटाने के बाद विभिन्न डिलीट ऑपरेशन के बाद
तो फिर, हम लॉग फ़ाइल आकार में उल्लेखनीय कमी देखते हैं (100K के सबसे छोटे चंक आकार वाले मामलों में 97% से अधिक); हालाँकि, इस पैमाने पर, हम कुछ ऐसे मामले देखते हैं जहाँ हम कम समय में भी डिलीट को पूरा कर लेते हैं, यहाँ तक कि उन सभी ऑटोग्रो घटनाओं के साथ भी जो घटित हुई होंगी। यह मेरे लिए जीत-जीत की तरह एक भयानक बहुत कुछ लगता है!
इस बार बड़े लॉग के साथ
अब, मैं उत्सुक था कि इस तरह के बड़े संचालन के लिए समायोजित करने के लिए पूर्व-आकार की लॉग फ़ाइल के साथ इन अलग-अलग डिलीट की तुलना कैसे की जाएगी। हमारे बड़े डेटाबेस के साथ चिपके हुए, मैंने लॉग फ़ाइल को 6 जीबी तक पूर्व-विस्तारित किया, उसका बैक अप लिया, फिर परीक्षण फिर से चलाया:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
परिणाम, एक निश्चित लॉग फ़ाइल के साथ अवधि की तुलना उस मामले से करना जहाँ फ़ाइल को लगातार ऑटोग्रो करना था:
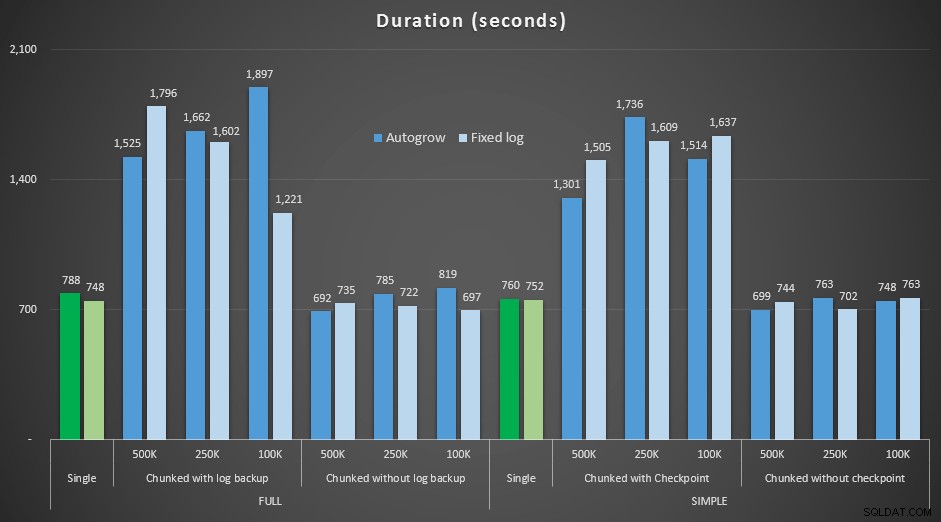
अवधि, सेकंड में, 4.5MM पंक्तियों को हटाते हुए विभिन्न डिलीट ऑपरेशनों की , निश्चित लॉग आकार और ऑटोग्रो की तुलना करना
फिर से हम देखते हैं कि जो तरीके चंक को बैचों में हटाते हैं, और प्रत्येक चरण के बाद लॉग बैकअप या चेकपॉइंट *नहीं* करते हैं, अवधि के संदर्भ में समकक्ष एकल ऑपरेशन को प्रतिद्वंद्वी करते हैं। वास्तव में, देखें कि अधिकांश वास्तव में कम समग्र समय में प्रदर्शन करते हैं, अतिरिक्त बोनस के साथ कि अन्य लेनदेन चरणों के बीच में और बाहर निकलने में सक्षम होंगे। जो एक अच्छी बात है जब तक आप नहीं चाहते कि यह डिलीट ऑपरेशन सभी असंबंधित लेनदेन को ब्लॉक कर दे।
निष्कर्ष
यह स्पष्ट है कि इस समस्या का कोई एकल, सही उत्तर नहीं है - बहुत सारे अंतर्निहित "यह निर्भर करता है" चर हैं। आपके मैजिक नंबर को खोजने में कुछ प्रयोग हो सकते हैं, क्योंकि लॉग का बैकअप लेने में लगने वाले ओवरहेड और विभिन्न चंक आकारों में आप कितना काम और समय बचाते हैं, के बीच एक संतुलन होगा। लेकिन अगर आप बड़ी संख्या में पंक्तियों को हटाने या संग्रहीत करने की योजना बना रहे हैं, तो यह काफी संभावना है कि आप एक के बजाय बड़े पैमाने पर लेन-देन करने के बजाय, कुल मिलाकर, बेहतर होगा, भले ही अवधि संख्याएं बनाने लगती हैं कि एक कम आकर्षक ऑपरेशन। यह केवल अवधि के बारे में नहीं है - यदि आपके पास पर्याप्त रूप से पूर्व-आवंटित लॉग फ़ाइल नहीं है, और इतने बड़े लेनदेन को समायोजित करने के लिए स्थान नहीं है, तो संभवतः अवधि की कीमत पर लॉग फ़ाइल वृद्धि को कम करना बेहतर है, ऐसी स्थिति में आप ऊपर दिए गए अवधि ग्राफ़ को नज़रअंदाज़ करना चाहेंगे और लॉग आकार के ग्राफ़ पर ध्यान देना चाहेंगे।
यदि आप जगह का खर्च उठा सकते हैं, तो भी आप अपने लेन-देन लॉग को तदनुसार पूर्व-आकार देना चाह सकते हैं या नहीं भी कर सकते हैं। परिदृश्य के आधार पर, कभी-कभी डिफ़ॉल्ट ऑटोग्रो सेटिंग्स का उपयोग मेरे परीक्षणों में बहुत सारे कमरे के साथ एक निश्चित लॉग फ़ाइल का उपयोग करने से थोड़ा तेज हो गया। साथ ही, यह अनुमान लगाना कठिन हो सकता है कि आपके द्वारा अभी तक नहीं चलाए गए बड़े लेन-देन को समायोजित करने के लिए आपको कितनी राशि की आवश्यकता होगी। यदि आप एक यथार्थवादी परिदृश्य का परीक्षण नहीं कर सकते हैं, तो अपने सबसे खराब स्थिति को चित्रित करने के लिए अपना सर्वश्रेष्ठ प्रयास करें - फिर, सुरक्षा के लिए, इसे दोगुना करें। किम्बर्ली ट्रिप (ब्लॉग | @KimberlyLTripp) ने इस पोस्ट में कुछ बेहतरीन सलाह दी है:बेहतर ट्रांजैक्शन लॉग थ्रूपुट के लिए 8 कदम - इस संदर्भ में, विशेष रूप से, बिंदु #6 को देखें। भले ही आप अपनी लॉग स्पेस आवश्यकताओं की गणना करने का निर्णय कैसे लेते हैं, यदि आप किसी भी तरह से स्थान की आवश्यकता को समाप्त करने जा रहे हैं, तो इसे नियंत्रित तरीके से पहले से ही लेना बेहतर है, जब तक कि वे ऑटोग्रो की प्रतीक्षा करते हुए अपनी व्यावसायिक प्रक्रियाओं को रोक दें ( कोई बात नहीं कई!)।
इसका एक और बहुत महत्वपूर्ण पहलू जिसे मैंने स्पष्ट रूप से नहीं मापा, वह है संगामिति का प्रभाव - छोटे लेनदेन का एक समूह, सिद्धांत रूप में, समवर्ती संचालन पर कम प्रभाव डालेगा। जबकि एक एकल डिलीट में लंबे, बैच किए गए संचालन की तुलना में थोड़ा कम समय लगता है, इसने अपने सभी लॉक को उस पूरी अवधि के लिए धारण किया, जबकि खंडित संचालन अन्य कतारबद्ध लेनदेन को प्रत्येक लेनदेन के बीच में घुसने की अनुमति देगा। भविष्य की पोस्ट में मैं इस प्रभाव पर करीब से नज़र डालने की कोशिश करूँगा (और मेरे पास अन्य गहन विश्लेषण की भी योजना है)।



