एक प्रदर्शन समस्या जो मुझे अक्सर दिखाई देती है, वह यह है कि जब उपयोगकर्ताओं को निम्नलिखित की तरह एक क्वेरी के साथ स्ट्रिंग के हिस्से का मिलान करने की आवश्यकता होती है:
... जहां कुछ कॉलम N'%somePortion%' पसंद करते हैं;
एक प्रमुख वाइल्डकार्ड के साथ, यह विधेय "गैर-SARGable" है - यह कहने का एक शानदार तरीका है कि हम SomeColumn पर किसी अनुक्रमणिका के विरुद्ध खोज का उपयोग करके प्रासंगिक पंक्तियों को नहीं ढूंढ सकते हैं। .
एक समाधान जो हमें हाथ से लहराता है, वह है पूर्ण-पाठ खोज; हालांकि, यह एक जटिल समाधान है, और इसके लिए आवश्यक है कि खोज पैटर्न में पूर्ण शब्द हों, स्टॉप शब्दों का उपयोग न हो, इत्यादि। यह मदद कर सकता है अगर हम उन पंक्तियों की तलाश कर रहे हैं जहां एक विवरण में "सॉफ्ट" शब्द (या "सॉफ्टर" या "सॉफ्टली" जैसे अन्य डेरिवेटिव) शामिल हैं, लेकिन जब हम स्ट्रिंग्स की तलाश कर रहे हैं तो यह मदद नहीं करता है निहित किया जा सकता है शब्दों के भीतर (या जो बिल्कुल भी शब्द नहीं हैं, जैसे "X45-B" वाले सभी उत्पाद SKU या "7RA" अनुक्रम वाली सभी लाइसेंस प्लेट)।
क्या होगा यदि SQL सर्वर किसी स्ट्रिंग के सभी संभावित भागों के बारे में जानता है? मेरी विचार प्रक्रिया trigram . की तर्ज पर है / trigraph पोस्टग्रेएसक्यूएल में। मूल अवधारणा यह है कि इंजन में सबस्ट्रिंग पर पॉइंट-स्टाइल लुकअप करने की क्षमता है, जिसका अर्थ है कि आपको संपूर्ण तालिका को स्कैन करने और प्रत्येक पूर्ण मान को पार्स करने की आवश्यकता नहीं है।
वे जिस विशिष्ट उदाहरण का उपयोग करते हैं वह है cat . शब्द . पूरे शब्द के अलावा, इसे भागों में विभाजित किया जा सकता है:c , ca , और at (वे a . छोड़ देते हैं और t परिभाषा के अनुसार - कोई भी अनुगामी विकल्प दो वर्णों से छोटा नहीं हो सकता है)। SQL सर्वर में, हमें इसकी आवश्यकता नहीं है कि यह जटिल हो; हमें वास्तव में केवल आधे ट्रिग्राम की आवश्यकता है - यदि हम एक डेटा संरचना बनाने के बारे में सोचते हैं जिसमें cat के सभी सबस्ट्रिंग शामिल हैं , हमें केवल इन मूल्यों की आवश्यकता है:
- बिल्ली
- पर
- टी
हमें c की आवश्यकता नहीं है या ca , क्योंकि कोई भी LIKE '%ca%' . को खोज रहा है LIKE 'ca%' . का उपयोग करके आसानी से मान 1 प्राप्त कर सकते हैं बजाय। इसी तरह, LIKE '%at%' . को खोजने वाला कोई भी व्यक्ति या LIKE '%a%' केवल इन तीन मानों के विरुद्ध अनुगामी वाइल्डकार्ड का उपयोग कर सकता है और मेल खाने वाले को ढूंढ सकता है (उदा. LIKE 'at%' मान 2 मिलेगा, और LIKE 'a%' मूल्य 1 के अंदर उन सबस्ट्रिंग को खोजने के बिना, मूल्य 2 भी मिलेगा, जहां से वास्तविक दर्द आएगा)।
इसलिए, यह देखते हुए कि SQL सर्वर में ऐसा कुछ भी अंतर्निहित नहीं है, हम ऐसा ट्रिग्राम कैसे उत्पन्न करते हैं?
एक अलग टुकड़े तालिका
मैं यहां "ट्रिग्राम" को संदर्भित करना बंद करने जा रहा हूं क्योंकि यह वास्तव में PostgreSQL में उस सुविधा के अनुरूप नहीं है। अनिवार्य रूप से, हम मूल स्ट्रिंग के सभी "टुकड़ों" के साथ एक अलग तालिका बनाने जा रहे हैं। (तो cat . में उदाहरण के लिए, उन तीन पंक्तियों के साथ एक नई तालिका होगी, और LIKE '%pattern%' खोजों को उस नई तालिका के विरुद्ध LIKE 'pattern%' . के रूप में निर्देशित किया जाएगा भविष्यवाणी करता है।)
इससे पहले कि मैं यह दिखाना शुरू करूं कि मेरा प्रस्तावित समाधान कैसे काम करेगा, मुझे पूरी तरह से स्पष्ट कर देना चाहिए कि इस समाधान का उपयोग हर एक मामले में नहीं किया जाना चाहिए जहां LIKE '%wildcard%' खोज धीमी हैं। जिस तरह से हम स्रोत डेटा को टुकड़ों में "विस्फोट" करने जा रहे हैं, यह संभवतः छोटे स्ट्रिंग्स तक सीमित है, जैसे कि पते या नाम, बड़े स्ट्रिंग्स के विपरीत, जैसे उत्पाद विवरण या सत्र सार।
cat . से अधिक व्यावहारिक उदाहरण Sales.Customer को देखना है वाइडवर्ल्ड इम्पोर्टर्स नमूना डेटाबेस में तालिका। इसकी पता पंक्तियाँ हैं (दोनों nvarchar(60) ), कॉलम में मूल्यवान पता जानकारी के साथ DeliveryAddressLine2 (अज्ञात कारणों से)। हो सकता है कोई किसी को ढूंढ रहा हो जो Hudecova . नाम की गली में रहता हो , इसलिए वे इस तरह एक खोज चला रहे होंगे:
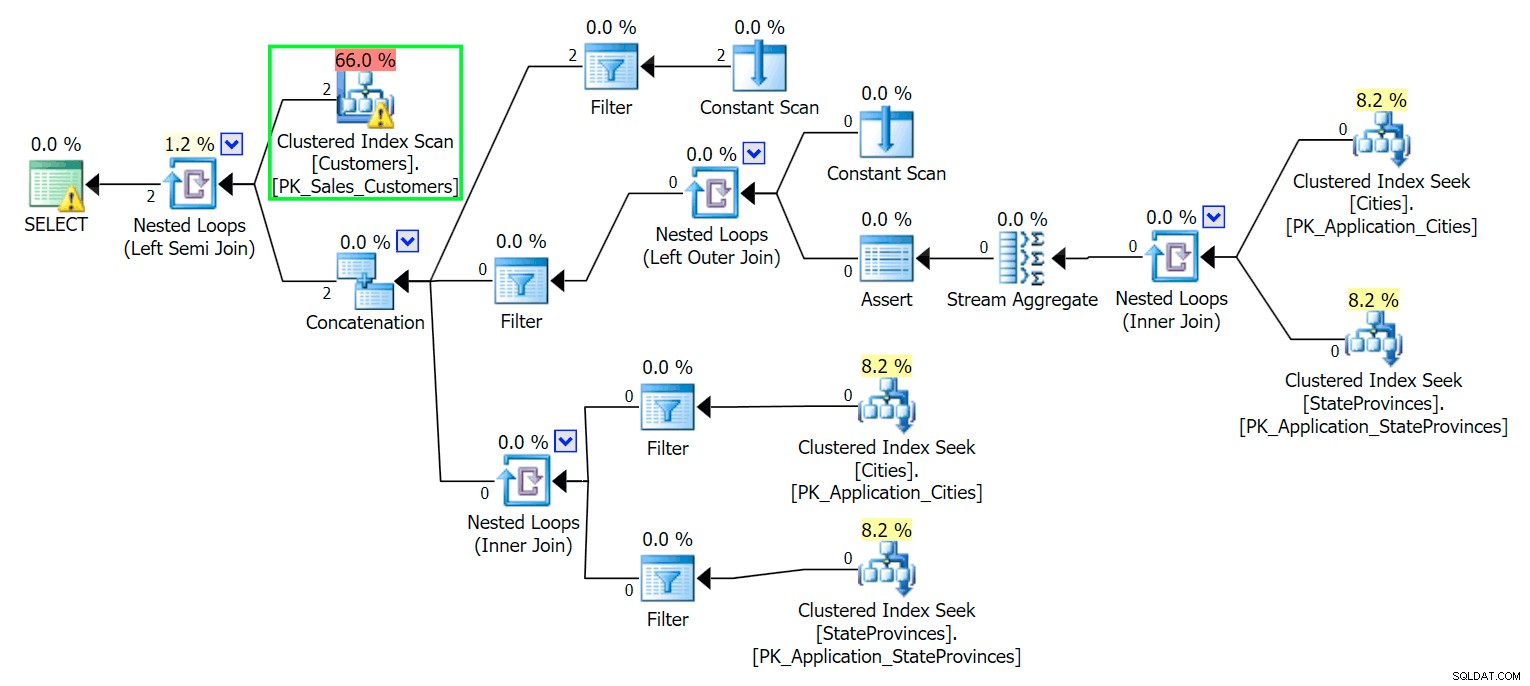
सेल्स से CustomerID, DeliveryAddressLine2 चुनें। ग्राहक जहां डिलिवरीAddressLine2 N'%Hudecova%' पसंद करते हैं; /* यह दो पंक्तियाँ लौटाता है:CustomerID DeliveryAddressLine2 ---------- ----------------------- 61 1695 हुडकोवा एवेन्यू 181 1846 हुडकोवा क्रिसेंट* // पूर्व>जैसा कि आप उम्मीद करेंगे, SQL सर्वर को उन दो पंक्तियों का पता लगाने के लिए एक स्कैन करने की आवश्यकता है। जो सरल होना चाहिए; हालांकि, तालिका की जटिलता के कारण, यह तुच्छ क्वेरी एक बहुत ही गन्दा निष्पादन योजना उत्पन्न करती है (स्कैन हाइलाइट किया गया है, और अवशिष्ट I/O के लिए एक चेतावनी है):
ब्लीच। अपने जीवन को सरल रखने के लिए, और यह सुनिश्चित करने के लिए कि हम लाल झुंडों के झुंड का पीछा नहीं करते हैं, आइए स्तंभों के सबसेट के साथ एक नई तालिका बनाएं, और शुरू करने के लिए हम ऊपर से उन्हीं दो पंक्तियों को सम्मिलित करेंगे:
टेबल सेल्स बनाएं। कस्टमरकॉपी (ग्राहक आईडी इंट पहचान (1,1) कॉन्स्ट्रेंट पीके_कस्टमर कॉपी प्राथमिक कुंजी, ग्राहक नाम nvarchar (100) न्यूल नहीं, डिलिवरी एड्रेसलाइन 1 nvarchar (60) न्यूल, डिलिवरी एड्रेसलाइन 2 nvarchar (60)); बिक्री सम्मिलित करें। ग्राहक कॉपी करें ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) CustomerName, DeliveryAddressLine1, DeliveryAddressLine2FROM सेल्स का चयन करें। CustomersWHERE DeliveryAddressLine2 LIKE N'%Hudecova%';अब, यदि हम वही क्वेरी चलाते हैं जो हम मुख्य तालिका के विरुद्ध चलाते हैं, तो हमें प्रारंभिक बिंदु के रूप में देखने के लिए कुछ अधिक उचित मिलता है। यह अभी भी एक स्कैन होने जा रहा है चाहे हम कुछ भी करें - अगर हम
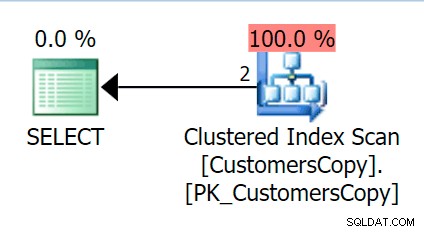
DeliveryAddressLine2के साथ एक इंडेक्स जोड़ते हैं प्रमुख कुंजी कॉलम के रूप में, हम सबसे अधिक संभावना एक इंडेक्स स्कैन प्राप्त करेंगे, जिसमें एक कुंजी लुकअप होगा जो इस पर निर्भर करता है कि इंडेक्स क्वेरी में कॉलम को कवर करता है या नहीं। जैसे, हमें एक क्लस्टर इंडेक्स स्कैन मिलता है:
इसके बाद, चलिए एक ऐसा फंक्शन बनाते हैं जो इन एड्रेस वैल्यू को टुकड़ों में "विस्फोट" करेगा। हम उम्मीद करेंगे
1846 Hudecova Crescent, उदाहरण के लिए, टुकड़ों का निम्नलिखित सेट रखना:
- 1846 हुडेकोवा क्रिसेंट
- 846 हुडेकोवा क्रिसेंट
- 46 हुडेकोवा क्रिसेंट
- 6 हुडेकोवा क्रिसेंट
- हुडेकोवा क्रिसेंट
- हुडेकोवा क्रिसेंट
- यूडेकोवा क्रिसेंट
- डेकोवा क्रिसेंट
- इकोवा क्रिसेंट
- कोवा क्रिसेंट
- ओवा क्रिसेंट
- वा क्रिसेंट
- एक क्रिसेंट
- क्रिसेंट
- क्रिसेंट
- नवीनतम
- सेंटेंट
- सुगंध
- प्रतिशत
- ent
- एनटी
- टी
इस आउटपुट को उत्पन्न करने वाले फ़ंक्शन को लिखना काफी तुच्छ है - हमें केवल एक पुनरावर्ती सीटीई की आवश्यकता है जिसका उपयोग इनपुट की पूरी लंबाई में प्रत्येक वर्ण के माध्यम से कदम उठाने के लिए किया जा सकता है:
CREATE FUNCTION dbo.CreateStringFragments(@input nvarchar(60)) SCHEMABINDINGAS RETURN के साथ रिटर्न टेबल (x(x) AS के साथ (चुनें 1 यूनियन सभी का चयन करें x+1 से x जहां x <(LEN(@input))) सेलेक्ट फ्रैगमेंट =सबस्ट्रिंग(@इनपुट, एक्स, एलईएन(@इनपुट)) एक्स से); डीबीओ से सेलेक्ट फ्रैगमेंट पर जाएं। क्रिएटस्ट्रिंगफ्रैगमेंट (एन'1846 ह्यूडेकोवा क्रिसेंट'); - उपरोक्त बुलेटेड सूची के समान आउटपुट
अब, आइए एक तालिका बनाते हैं जो सभी पते के अंशों को संग्रहीत करेगी, और वे किस ग्राहक से संबंधित हैं:
टेबल सेल्स बनाएं। CustomerAddressFragments( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, FK_Customers FK_Customers FOREIGN KEY(CustomerID) संदर्भ बिक्री। CustomerCopy(CustomerID)); सेल्स पर CLUSTERED INDEX s_cat बनाएँ। CustomerAddressFragments(Fragment, CustomerID);
फिर हम इसे इस तरह से भर सकते हैं:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment)Select c.CustomerID, f.Fragment from Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
हमारे दो मानों के लिए, यह 42 पंक्तियों को सम्मिलित करता है (एक पते में 20 वर्ण हैं, और दूसरे में 22 हैं)। अब हमारी क्वेरी बन जाती है:
चुनें c.CustomerID, c.DeliveryAddressLine2 from Sales.CustomersCopy as c INNER JOIN Sales.CustomerAddressFragments as f ON f.CustomerID =c.CustomerID और f.Fragment LIKE N'Hudecova%';
यहाँ एक बहुत अच्छी योजना है - दो संकुल सूचकांक *तलाश* और एक नेस्टेड लूप जुड़ते हैं:
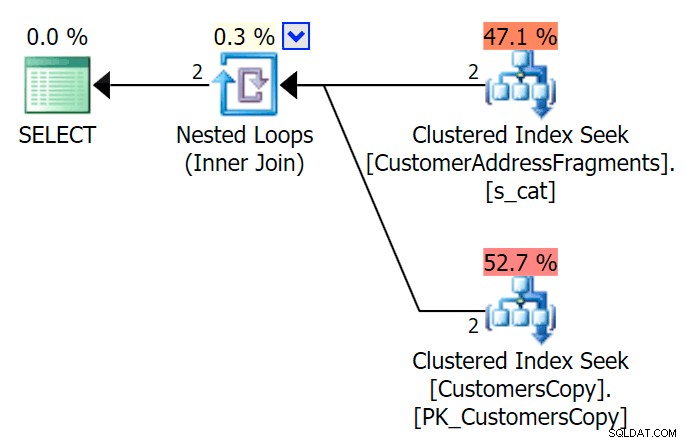
हम इसे दूसरे तरीके से भी कर सकते हैं, EXISTS . का उपयोग करके :
चयन c.CustomerID, c.DeliveryAddressLine2 from Sales.CustomersCopy as c जहाँ मौजूद है (सेल्स से 1 चुनें। CustomerAddressFragments जहाँ CustomerID =c.CustomerID और Fragment L'Hudecova%');
यहाँ वह योजना है, जो सतह पर अधिक महंगी लगती है - यह CustomersCopy तालिका को स्कैन करना चुनती है। हम जल्द ही देखेंगे कि यह बेहतर क्वेरी दृष्टिकोण क्यों है:
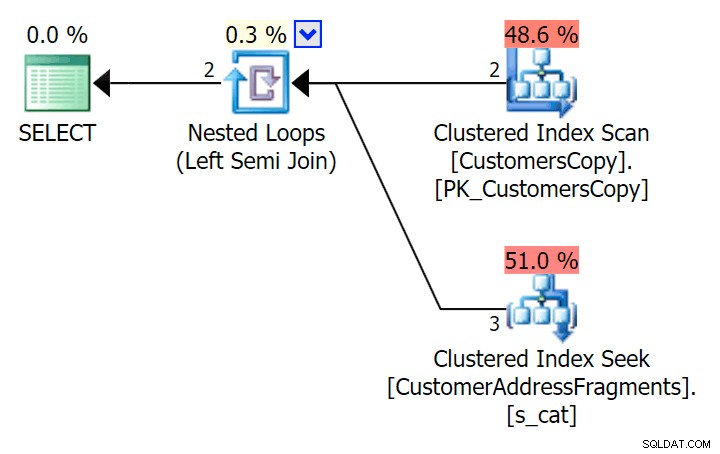
अब, 42 पंक्तियों के इस विशाल डेटा सेट पर, अवधि और I/O में देखे गए अंतर इतने कम हैं कि वे अप्रासंगिक हैं (और वास्तव में, इस छोटे आकार में, आधार तालिका के विरुद्ध स्कैन I/ ओ अन्य दो योजनाओं की तुलना में जो खंड तालिका का उपयोग करती हैं):

क्या होगा अगर हम इन तालिकाओं को बहुत अधिक डेटा के साथ पॉप्युलेट करें? Sales.Customers . की मेरी प्रति इसमें 663 पंक्तियाँ हैं, इसलिए यदि हम इसे स्वयं के विरुद्ध जोड़ते हैं, तो हमें लगभग 440,000 पंक्तियाँ मिलेंगी। तो चलिए 400K को मैश करते हैं और एक बहुत बड़ी तालिका तैयार करते हैं:
TRUNCATE TABLE Sales.CustomerAddressFragments;DELETE Sales.CustomersCopy;DBCC FREEPROCCACHE with NO_INFOMSGS; INSERT Sales.CustomersCopy with (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) सेलेक्ट टॉप (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 from Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID (); - वितरण के लिए मजेदार - इसमें थोड़ा अधिक समय लगेगा - मेरे सिस्टम पर, ~ 4 मिनट-- शायद इसलिए कि मैंने फाइलों को पूर्व-विस्तारित करने की जहमत नहीं उठाई। CustomerID, f.Fragment from Sales.CustomersCopy as c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- तालिका के संपीड़ित संस्करण के लिए दोहराया गया-- 7.25 मिलियन पंक्तियाँ, 278MB (79MB संकुचित; उन परीक्षणों को किसी अन्य दिन के लिए सहेजना)
अब विभिन्न संभावित खोज मापदंडों को देखते हुए प्रदर्शन और निष्पादन योजनाओं की तुलना करने के लिए, मैंने इन विधेय के साथ उपरोक्त तीन प्रश्नों का परीक्षण किया:
| प्रश्न | <वें colspan=5>भविष्यवाणी करता है||||
|---|---|---|---|---|
| जहां डिलिवरी लाइन एड्रेस 2 पसंद है … | N'%हुडेकोवा%' | N'%cova%' | N'%ova%' | N'%va%' |
| शामिल हों ... जहां टुकड़ा पसंद है ... | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' |
| कहां मौजूद है (... जहां टुकड़ा पसंद है ...) |
जैसे ही हम खोज पैटर्न से अक्षरों को हटाते हैं, मैं उम्मीद करता हूं कि अधिक पंक्तियां आउटपुट, और शायद अनुकूलक द्वारा चुनी गई विभिन्न रणनीतियों को देखें। आइए देखें कि यह प्रत्येक पैटर्न के लिए कैसा रहा:
हुडेकोवा%
इस पैटर्न के लिए, LIKE स्थिति के लिए स्कैन अभी भी वही था; हालांकि, अधिक डेटा के साथ, लागत बहुत अधिक है। टुकड़े तालिका में तलाश वास्तव में इस पंक्ति गणना (1,206) पर भुगतान करती है, यहां तक कि वास्तव में कम अनुमानों के साथ भी। EXISTS योजना एक अलग प्रकार जोड़ती है, जिसे आप लागत में जोड़ने की उम्मीद करेंगे, हालांकि इस मामले में यह कम पढ़ता है:

 फ्रैगमेंट टेबल में शामिल होने की योजना बनाएं
फ्रैगमेंट टेबल में शामिल होने की योजना बनाएं 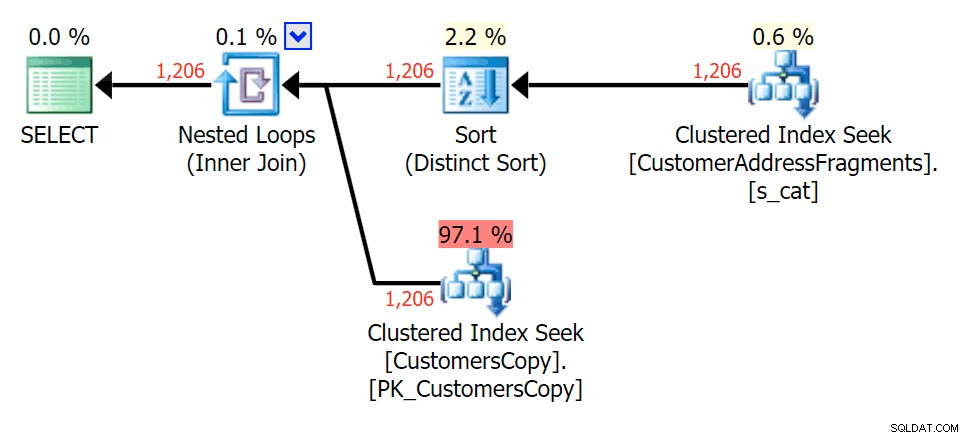 फ्रैगमेंट टेबल के सामने EXISTS के लिए योजना बनाएं
फ्रैगमेंट टेबल के सामने EXISTS के लिए योजना बनाएं cova%
जैसे ही हम अपने विधेय से कुछ अक्षर हटाते हैं, हम देखते हैं कि वास्तव में मूल क्लस्टर इंडेक्स स्कैन की तुलना में थोड़ा अधिक पढ़ता है, और अब हम ओवर -पंक्तियों का अनुमान लगाएं। फिर भी, दोनों खंड प्रश्नों के साथ हमारी अवधि काफी कम है; इस बार अंतर अधिक सूक्ष्म है - दोनों के प्रकार हैं (केवल EXISTS अलग है):

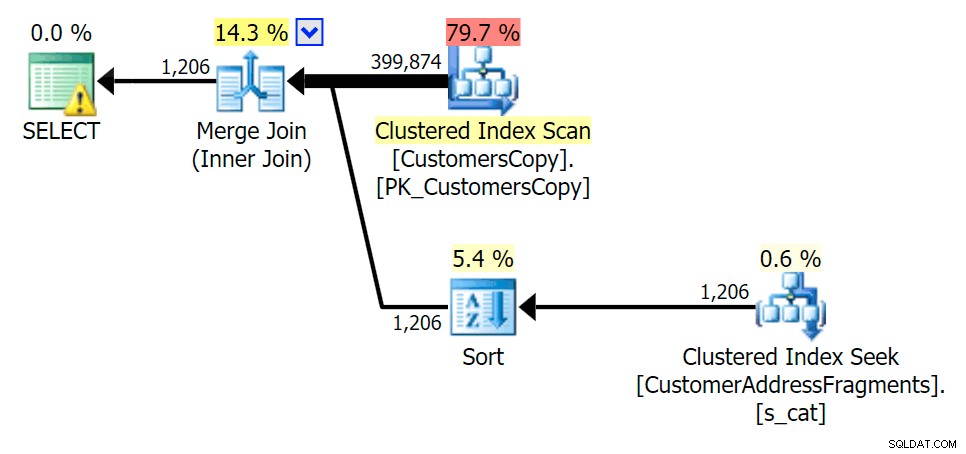 फ्रैगमेंट टेबल में शामिल होने की योजना बनाएं
फ्रैगमेंट टेबल में शामिल होने की योजना बनाएं 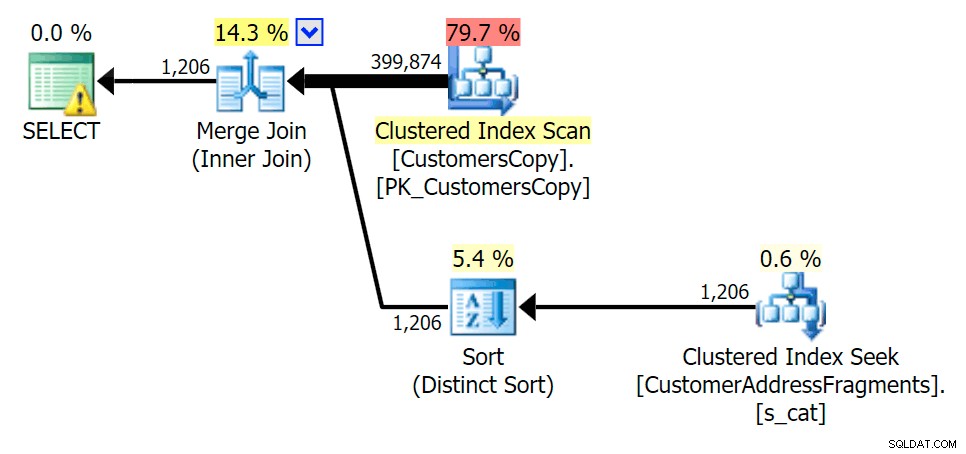 फ्रैगमेंट टेबल के सामने EXISTS की योजना बनाएं
फ्रैगमेंट टेबल के सामने EXISTS की योजना बनाएं ova%
एक अतिरिक्त पत्र को अलग करने से बहुत कुछ नहीं बदला; हालांकि यह ध्यान देने योग्य है कि अनुमानित और वास्तविक पंक्तियाँ यहाँ कितनी छलांग लगाती हैं - जिसका अर्थ है कि यह एक सामान्य सबस्ट्रिंग पैटर्न हो सकता है। मूल LIKE क्वेरी अभी भी खंड प्रश्नों की तुलना में काफी धीमी है।

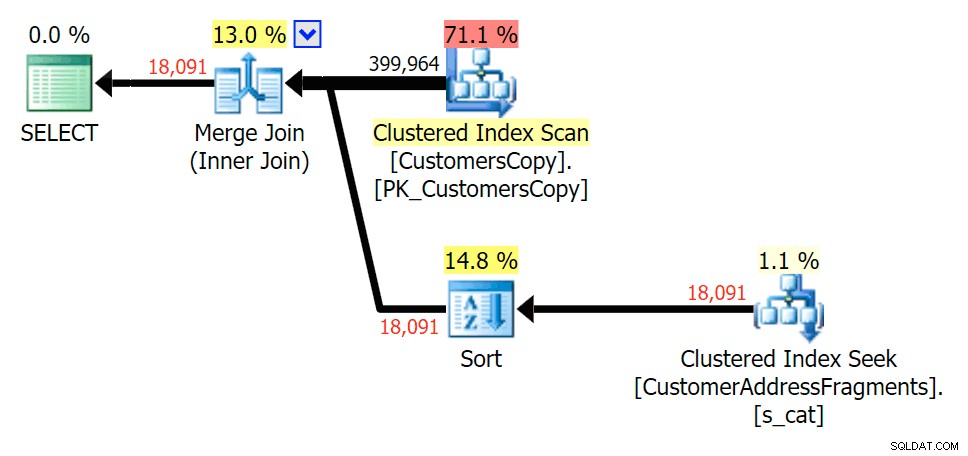 फ्रैगमेंट टेबल में शामिल होने की योजना बनाएं
फ्रैगमेंट टेबल में शामिल होने की योजना बनाएं 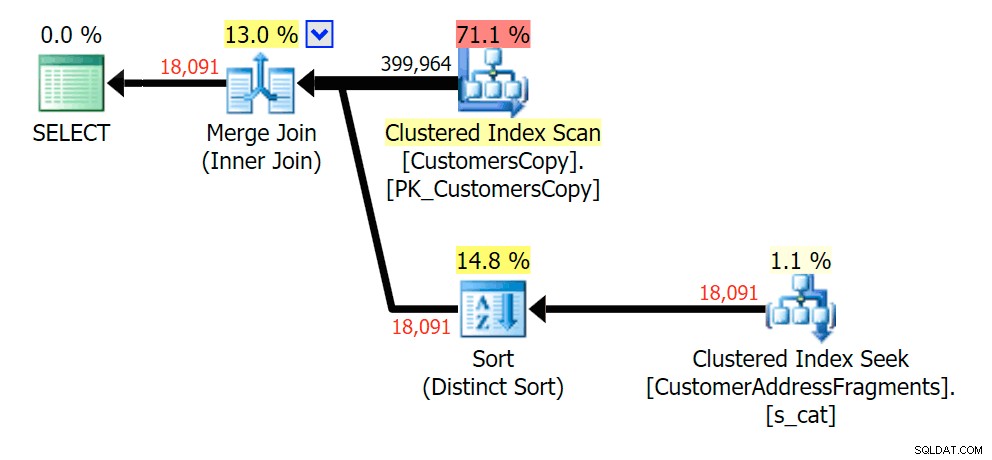 फ्रैगमेंट टेबल के सामने EXISTS की योजना बनाएं
फ्रैगमेंट टेबल के सामने EXISTS की योजना बनाएं va%
दो अक्षरों तक, यह हमारी पहली विसंगति का परिचय देता है। ध्यान दें कि जॉइन अधिक produces पैदा करता है मूल क्वेरी या EXISTS की तुलना में पंक्तियाँ। ऐसा क्यों होगा?

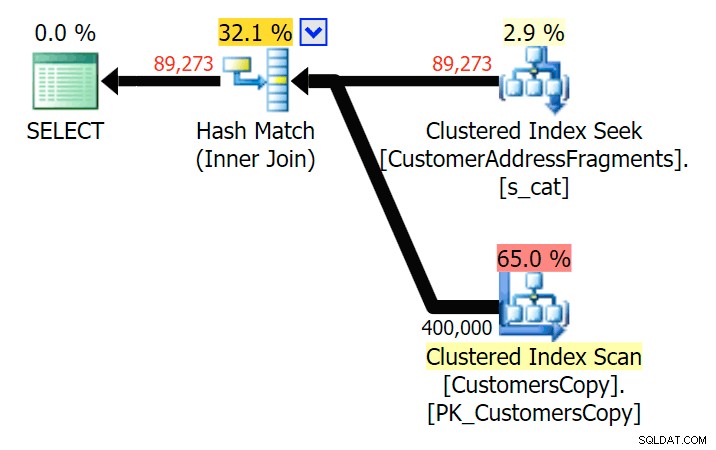 फ्रैगमेंट टेबल में शामिल होने की योजना बनाएं
फ्रैगमेंट टेबल में शामिल होने की योजना बनाएं 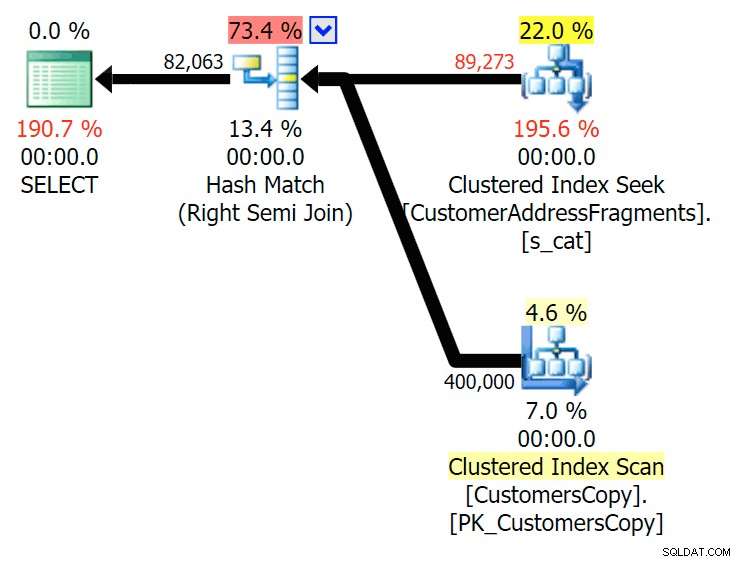 फ्रैगमेंट टेबल के सामने EXISTS के लिए योजना बनाएं हमें दूर देखने की जरूरत नहीं है। याद रखें कि मूल पते में प्रत्येक लगातार वर्ण से शुरू होने वाला एक टुकड़ा है, जिसका अर्थ कुछ ऐसा है
फ्रैगमेंट टेबल के सामने EXISTS के लिए योजना बनाएं हमें दूर देखने की जरूरत नहीं है। याद रखें कि मूल पते में प्रत्येक लगातार वर्ण से शुरू होने वाला एक टुकड़ा है, जिसका अर्थ कुछ ऐसा है 899 Valentova Road खंड तालिका में दो पंक्तियाँ होंगी जो va . से शुरू होती हैं (केस संवेदनशीलता एक तरफ)। तो आप दोनों Fragment = N'Valentova Road' . पर मैच करेंगे और Fragment = N'va Road' . मैं आपको खोज बचाऊंगा और कई का एक उदाहरण प्रदान करूंगा: शीर्ष चुनें (2) c.CustomerID, c.DeliveryAddressLine2, f.FragmentFROM Sales.CustomersCopy as cINNER JOIN Sales.CustomerAddressFragments as fON c.CustomerID =f.CustomerIDWHERE f.Fragment LIKE N'va%'AND c.DeliveryAddressLine2 =N'899 वैलेंटोवा रोड'और f.CustomerID =351; /*CustomerID DeliveryAddressLine2 Fragment----------------------------------------- 351 899 वैलेंटोवा रोड और रोड351 899 वैलेंटोवा रोड वैलेंटोवा रोड*/
यह आसानी से बताता है कि जॉइन अधिक पंक्तियां क्यों उत्पन्न करता है; यदि आप मूल LIKE क्वेरी के आउटपुट से मिलान करना चाहते हैं, तो आपको EXISTS का उपयोग करना चाहिए। तथ्य यह है कि सही परिणाम आमतौर पर कम संसाधन-गहन तरीके से भी प्राप्त किए जा सकते हैं, यह सिर्फ एक बोनस है। (यदि लोग बार-बार अधिक कुशल विकल्प होते तो लोगों को जॉइन का चयन करते हुए देखकर मुझे घबराहट होगी - आपको प्रदर्शन के बारे में चिंता करने के बजाय हमेशा सही परिणामों का पक्ष लेना चाहिए।)
सारांश
यह स्पष्ट है कि इस विशिष्ट मामले में - nvarchar(60) . के एड्रेस कॉलम के साथ और 26 वर्णों की अधिकतम लंबाई - प्रत्येक पते को टुकड़ों में विभाजित करने से अन्यथा महंगी "अग्रणी वाइल्डकार्ड" खोजों में कुछ राहत मिल सकती है। बेहतर भुगतान तब होता है जब खोज पैटर्न बड़ा होता है और परिणामस्वरूप, अधिक अद्वितीय होता है। मैंने यह भी प्रदर्शित किया है कि EXISTS उन परिदृश्यों में बेहतर क्यों है जहां कई मैच संभव हैं - जॉइन के साथ, आपको तब तक अनावश्यक आउटपुट मिलेगा जब तक कि आप कुछ "सबसे बड़ा n प्रति समूह" तर्क नहीं जोड़ते।
चेतावनी
मैं यह स्वीकार करने वाला पहला व्यक्ति होगा कि यह समाधान अपूर्ण है, अपूर्ण है, और पूरी तरह से तैयार नहीं किया गया है:
- आपको ट्रिगर्स का उपयोग करके आधार तालिका के साथ फ़्रैगमेंट तालिका को सिंक्रनाइज़ रखने की आवश्यकता होगी - इन्सर्ट और अपडेट के लिए सबसे सरल होगा, उन ग्राहकों के लिए सभी पंक्तियों को हटाएं और उन्हें फिर से डालें, और हटाए जाने के लिए स्पष्ट रूप से पंक्तियों को टुकड़ों से हटा दें टेबल।
- जैसा कि बताया गया है, यह समाधान इस विशिष्ट डेटा आकार के लिए बेहतर काम करता है, और अन्य स्ट्रिंग लंबाई के लिए इतना अच्छा नहीं कर सकता है। यह सुनिश्चित करने के लिए आगे परीक्षण की आवश्यकता होगी कि यह आपके कॉलम आकार, औसत मूल्य लंबाई और विशिष्ट खोज पैरामीटर लंबाई के लिए उपयुक्त है।
- चूंकि हमारे पास "क्रिसेंट" और "स्ट्रीट" जैसे टुकड़ों की बहुत सारी प्रतियां होंगी (सभी समान या समान सड़क के नाम और घर के नंबरों पर ध्यान न दें), प्रत्येक अद्वितीय टुकड़े को एक टुकड़े तालिका में संग्रहीत करके इसे और सामान्य कर सकते हैं, और फिर एक और तालिका जो कई-से-अनेक जंक्शन तालिका के रूप में कार्य करती है। यह सेटअप करने के लिए बहुत अधिक बोझिल होगा, और मुझे पूरा यकीन नहीं है कि इसमें बहुत कुछ हासिल करना होगा।
- मैंने अभी तक पृष्ठ संपीड़न की पूरी तरह से जांच नहीं की है, ऐसा लगता है कि - कम से कम सिद्धांत रूप में - यह कुछ लाभ प्रदान कर सकता है। मुझे यह भी लगता है कि कुछ मामलों में कॉलमस्टोर कार्यान्वयन भी फायदेमंद हो सकता है।
वैसे भी, जो कुछ भी कहा गया है, मैं इसे एक विकासशील विचार के रूप में साझा करना चाहता था, और विशिष्ट उपयोग के मामलों के लिए इसकी व्यावहारिकता पर कोई प्रतिक्रिया मांगना चाहता था। यदि आप मुझे बता सकते हैं कि इस समाधान के किन पहलुओं में आपकी रुचि है, तो मैं भविष्य की पोस्ट के लिए और अधिक विशिष्टताओं में खुदाई कर सकता हूं।