परिचय
हाल ही में हमें अपने SQL सर्वर डेटाबेस में से एक पर एक दिलचस्प प्रदर्शन समस्या का सामना करना पड़ा जो लेनदेन को गंभीर दर पर संसाधित करता है। इन लेन-देन को पकड़ने के लिए उपयोग की जाने वाली लेन-देन तालिका एक हॉट टेबल बन गई। नतीजतन, समस्या एप्लिकेशन परत में दिखाई दी। यह लेन-देन पोस्ट करने के लिए सत्र का रुक-रुक कर चलने वाला समय था।
ऐसा इसलिए हुआ क्योंकि एक सत्र आम तौर पर टेबल पर "होल्ड" होता है और डेटाबेस में नकली ताले की एक श्रृंखला का कारण बनता है।
एक विशिष्ट डेटाबेस व्यवस्थापक की पहली प्रतिक्रिया प्राथमिक अवरोधन सत्र की पहचान करना और इसे सुरक्षित रूप से समाप्त करना होगा। यह सुरक्षित था क्योंकि यह आमतौर पर एक सेलेक्ट स्टेटमेंट या एक निष्क्रिय सत्र था।
समस्या को हल करने के अन्य प्रयास भी थे:
- तालिका को शुद्ध करना। यह उम्मीद की गई थी कि यह अच्छा प्रदर्शन देगा, भले ही क्वेरी को एक पूर्ण तालिका को स्कैन करना पड़े।
- ब्लॉकिंग सेशन के प्रभाव को कम करने के लिए रीड कमिटेड स्नैपशॉट आइसोलेशन स्तर को सक्षम करना।
इस लेख में, हम परिदृश्य के एक सरलीकृत संस्करण को फिर से बनाने की कोशिश करेंगे और इसका उपयोग यह दिखाने के लिए करेंगे कि सही तरीके से किए जाने पर सरल अनुक्रमण इस तरह की स्थितियों को कैसे संबोधित कर सकता है।
दो संबंधित टेबल
लिस्टिंग 1 और लिस्टिंग 2 पर एक नज़र डालें। वे विचाराधीन परिदृश्य में शामिल तालिकाओं के सरलीकृत संस्करण दिखाते हैं।
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
लिस्टिंग 3 एक ट्रिगर दिखाता है जो TranDetails . में चार पंक्तियों को सम्मिलित करता है TranLog . में डाली गई प्रत्येक पंक्ति के लिए तालिका टेबल।
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
क्वेरी में शामिल हों
बड़ी तालिकाओं द्वारा समर्थित लेन-देन तालिकाएँ खोजना विशिष्ट है। इसका उद्देश्य बहुत पुराने लेन-देन को रखना या पहली तालिका में संक्षेपित रिकॉर्ड के विवरण को संग्रहीत करना है। इसे आदेश के रूप में सोचें और आदेश विवरण तालिकाएँ जो SQL सर्वर नमूना डेटाबेस में विशिष्ट हैं। हमारे मामले में, हम TranLog . पर विचार कर रहे हैं और TranDetails टेबल।
सामान्य परिस्थितियों में, लेन-देन समय के साथ इन दो तालिकाओं को भर देता है। रिपोर्टिंग या सरल प्रश्नों के संदर्भ में, क्वेरी इन दो तालिकाओं में शामिल हो जाएगी। यह जुड़ाव तालिकाओं के बीच एक सामान्य कॉलम पर कैपिटल करेगा।
सबसे पहले, हम लिस्टिंग 4 में क्वेरी का उपयोग करके तालिका को पॉप्युलेट करते हैं।
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
हमारे नमूने में, शामिल होने द्वारा उपयोग किया जाने वाला सामान्य कॉलम TranID . है कॉलम:
-- Listing 5 Join Query
-- 5a
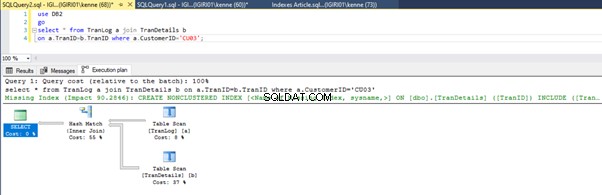
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
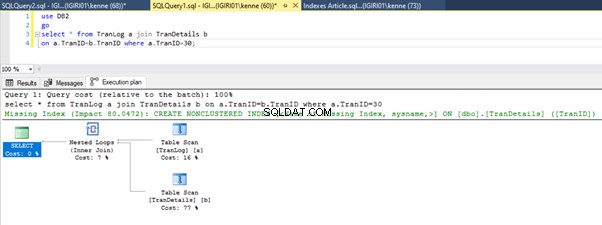
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
आप दो साधारण नमूना क्वेरी देख सकते हैं जो TranLog . से रिकॉर्ड पुनर्प्राप्त करने के लिए एक जॉइन का उपयोग करती हैं और TranDetails ।
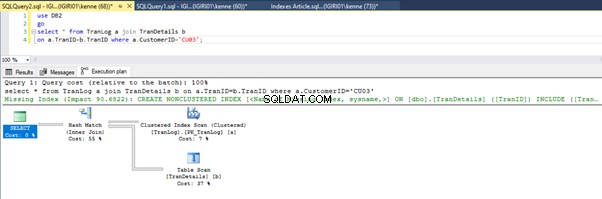
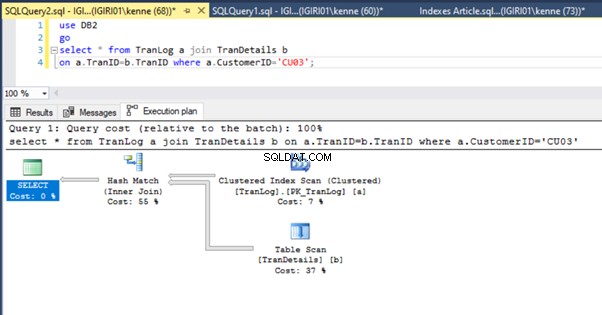
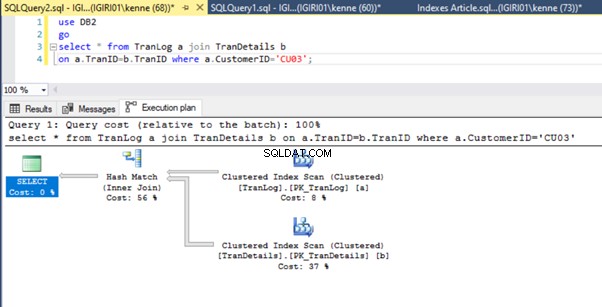
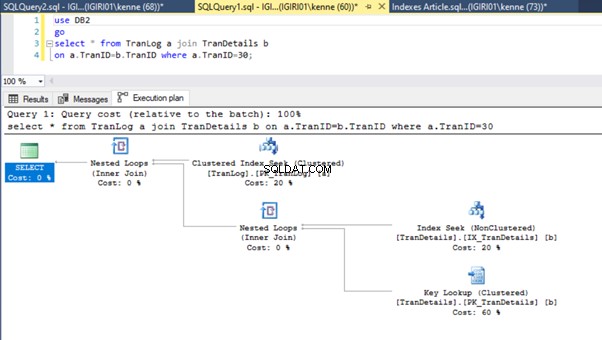
जब हम सूची 5 में प्रश्नों को चलाते हैं, तो दोनों ही मामलों में, हमें दोनों तालिकाओं पर एक पूर्ण तालिका स्कैन करना होता है (चित्र 1 और 2 देखें)। प्रत्येक क्वेरी का प्रमुख हिस्सा भौतिक संचालन है। दोनों आंतरिक जोड़ हैं। हालांकि, लिस्टिंग 5a एक हैश मैच . का उपयोग करता है शामिल हों, जबकि लिस्टिंग 5b एक नेस्टेड लूप . का उपयोग करता है जोड़ना। नोट:लिस्टिंग 5a 4000 पंक्तियाँ देता है जबकि लिस्टिंग 4बी 4 पंक्तियाँ देता है।
तीन प्रदर्शन ट्यूनिंग चरण
पहला अनुकूलन हम करते हैं TranID पर एक अनुक्रमणिका (एक प्राथमिक कुंजी, सटीक होने के लिए) पेश कर रहे हैं TranLog . का स्तंभ तालिका:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
आंकड़े 3 और 4 दिखाते हैं कि SQL सर्वर दोनों प्रश्नों में इस अनुक्रमणिका का उपयोग करता है, लिस्टिंग 5a में स्कैन करता है और लिस्टिंग 5b में खोज करता है।
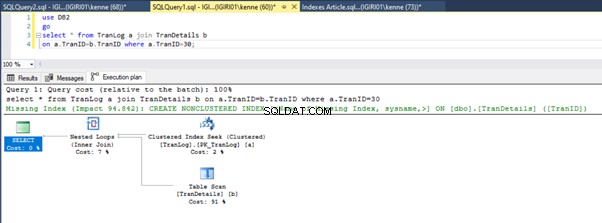
हमारे पास लिस्टिंग 5b में एक इंडेक्स सीक है। यह WHERE क्लॉज विधेय में शामिल कॉलम के कारण होता है - TranID। यह वह कॉलम है जिस पर हमने एक इंडेक्स लागू किया है।
इसके बाद, हम TranID . पर एक विदेशी कुंजी पेश करते हैं TranDetails . का कॉलम तालिका (सूची 7)।
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
यह निष्पादन योजना में ज्यादा बदलाव नहीं करता है। स्थिति लगभग वैसी ही है जैसी पहले चित्र 3 और 4 में दिखाई गई थी।
फिर हम विदेशी कुंजी कॉलम पर एक इंडेक्स पेश करते हैं:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
यह क्रिया नाटकीय रूप से लिस्टिंग 5b की निष्पादन योजना को बदल देती है (चित्र 6 देखें)। हम देखते हैं कि अधिक सूचकांक होना चाहता है। साथ ही, चित्र 6 में RID लुकअप पर ध्यान दें।
ढेर पर RID लुकअप आमतौर पर प्राथमिक कुंजी के अभाव में होता है। ढेर एक तालिका है जिसमें कोई प्राथमिक कुंजी नहीं है।
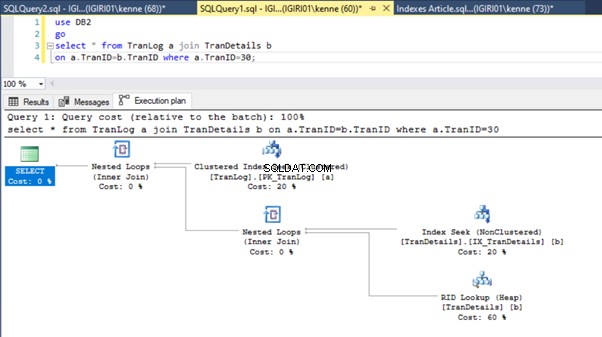
अंत में, हम TranDetails . में एक प्राथमिक कुंजी जोड़ते हैं टेबल। यह क्रमशः 5a और 5b लिस्टिंग में टेबल स्कैन और RID हीप लुकअप से छुटकारा दिलाता है (आंकड़े 7 और 8 देखें)।
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
निष्कर्ष
इंडेक्स द्वारा पेश किए गए प्रदर्शन में सुधार नौसिखिए डीबीए के लिए भी जाना जाता है। हालांकि, हम यह बताना चाहते हैं कि आपको यह देखने की ज़रूरत है कि क्वेरीज़ इंडेक्स का उपयोग कैसे करती हैं।
इसके अलावा, विचार उस विशेष मामले में समाधान स्थापित करना है जहां हमारे पास लेनदेन लॉग के बीच जुड़ने के प्रश्न हैं। टेबल और लेन-देन विवरण टेबल।
यह आम तौर पर एक कुंजी का उपयोग करके ऐसी तालिकाओं के बीच संबंध लागू करने और प्राथमिक और विदेशी कुंजी कॉलम में अनुक्रमणिका पेश करने के लिए समझ में आता है।
ऐसे डिज़ाइन का उपयोग करने वाले अनुप्रयोगों को विकसित करने में, डेवलपर्स को डिज़ाइन चरण में आवश्यक अनुक्रमणिका और संबंधों को ध्यान में रखना चाहिए। SQL सर्वर विशेषज्ञों के लिए आधुनिक उपकरण इन आवश्यकताओं को पूरा करना बहुत आसान बनाते हैं। आप विशेष क्वेरी प्रोफाइलर टूल का उपयोग करके अपने प्रश्नों को प्रोफाइल कर सकते हैं। यह डीबीए के जीवन को सरल बनाने के लिए देवार्ट द्वारा विकसित SQL सर्वर के लिए बहु-विशेषताओं वाले पेशेवर समाधान डीबीफोर्ज स्टूडियो का एक हिस्सा है।