अधिकांश OLTP वर्कलोड में यादृच्छिक डिस्क I/O उपयोग शामिल होता है। यह जानते हुए कि डिस्क (एसएसडी सहित) रैम की तुलना में प्रदर्शन में धीमी हैं, डेटाबेस सिस्टम प्रदर्शन को बढ़ाने के लिए कैशिंग का उपयोग करते हैं। बाद के समय में तेज़ पहुँच के लिए कैशिंग मेमोरी (RAM) में डेटा संग्रहीत करने के बारे में है।
PostgreSQL अपने डेटा के कैशिंग का उपयोग साझा_बफ़र्स नामक स्थान में भी करता है। इस ब्लॉग में हम प्रदर्शन बढ़ाने में आपकी मदद करने के लिए इस कार्यक्षमता का पता लगाएंगे।
पोस्टग्रेएसक्यूएल कैशिंग मूल बातें
इससे पहले कि हम कैशिंग की अवधारणा में गहराई से उतरें, आइए बुनियादी बातों पर ध्यान दें।
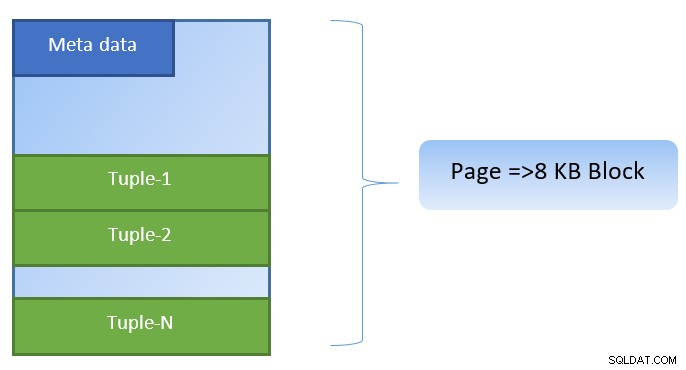
PostgreSQL में, डेटा को 8KB आकार के पृष्ठों के रूप में व्यवस्थित किया जाता है, और ऐसे प्रत्येक पृष्ठ में कई टुपल्स हो सकते हैं (ट्यूपल के आकार के आधार पर)। एक सरलीकृत प्रतिनिधित्व नीचे जैसा हो सकता है:
PostgreSQL डेटा एक्सेस को तेज करने के लिए निम्नलिखित को कैश करता है:
- तालिकाओं में डेटा
- सूचकांक
- क्वेरी निष्पादन योजनाएं
जबकि क्वेरी निष्पादन योजना कैशिंग CPU चक्रों को सहेजने पर केंद्रित है; टेबल डेटा और इंडेक्स डेटा के लिए कैशिंग महंगा डिस्क I/O संचालन को बचाने के लिए केंद्रित है।
PostgreSQL उपयोगकर्ताओं को यह परिभाषित करने देता है कि वे डेटा के लिए इस तरह के कैश को रखने के लिए कितनी मेमोरी आरक्षित करना चाहते हैं। postgresql.conf कॉन्फ़िगरेशन फ़ाइल में संबंधित सेटिंग shared_buffers है। Shared_buffers का परिमित मान परिभाषित करता है कि किसी भी समय कितने पृष्ठ कैश किए जा सकते हैं।
जैसे ही क्वेरी निष्पादित की जाती है, PostgreSQL डिस्क पर उस पृष्ठ की खोज करता है जिसमें प्रासंगिक टपल होता है और इसे पार्श्व पहुंच के लिए साझा_बफ़र्स कैश में धकेलता है। अगली बार उसी टपल (या उसी पृष्ठ में किसी भी टपल) को एक्सेस करने की आवश्यकता है, PostgreSQL डिस्क IO को मेमोरी में पढ़कर सहेज सकता है।
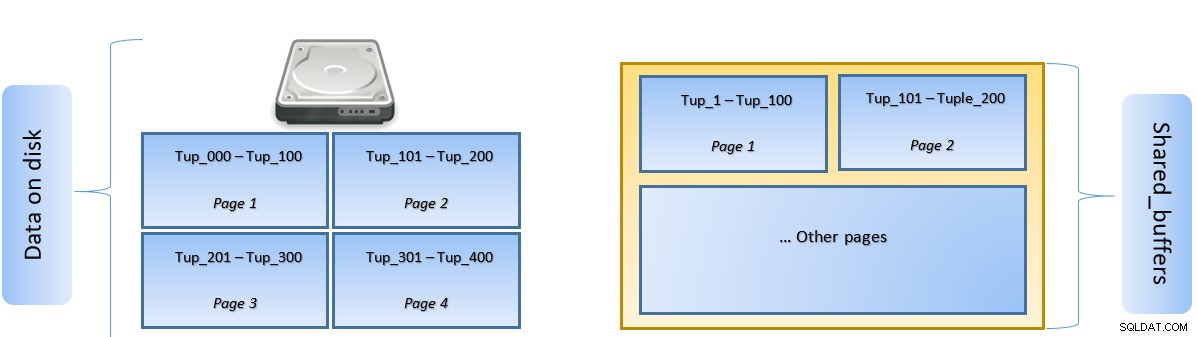
उपरोक्त आकृति में, एक निश्चित के पृष्ठ-1 और पृष्ठ-2 तालिका कैश की गई है। यदि किसी उपयोगकर्ता क्वेरी को Tuple-1 से Tuple-200 के बीच टुपल्स तक पहुंचने की आवश्यकता होती है, तो PostgreSQL इसे RAM से ही प्राप्त कर सकता है।
हालाँकि यदि क्वेरी को Tuples 250 से 350 तक पहुँचने की आवश्यकता है, तो उसे पेज 3 और पेज 4 के लिए डिस्क I/O करने की आवश्यकता होगी। Tuple 201 से 400 के लिए आगे कोई भी एक्सेस कैश से प्राप्त किया जाएगा और डिस्क I/O की आवश्यकता नहीं होगी - जिससे क्वेरी तेज हो जाएगी।
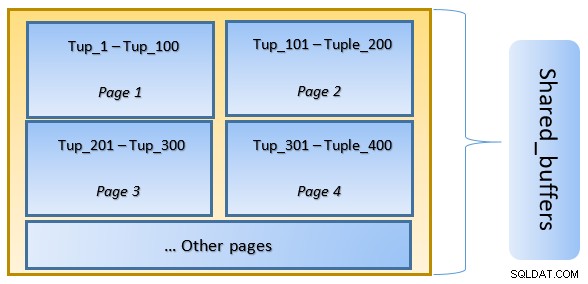
उच्च स्तर पर, PostgreSQL LRU (कम से कम हाल ही में प्रयुक्त) एल्गोरिथम का अनुसरण करता है उन पृष्ठों की पहचान करें जिन्हें कैश से बेदखल करने की आवश्यकता है। दूसरे शब्दों में, एक पेज जिसे केवल एक बार एक्सेस किया जाता है, उसके निष्कासन की संभावना अधिक होती है (उस पेज की तुलना में जिसे कई बार एक्सेस किया जाता है), अगर पोस्टग्रेएसक्यूएल द्वारा कैश में एक नया पेज लाने की आवश्यकता होती है।
PostgreSQL कैशिंग इन एक्शन
आइए एक उदाहरण निष्पादित करते हैं और प्रदर्शन पर कैश के प्रभाव को देखते हैं।
शेयर्ड_बफर को डिफ़ॉल्ट 128 एमबी पर सेट रखते हुए PostgreSQL प्रारंभ करें
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startसर्वर से कनेक्ट करें और एक डमी टेबल tblDummy और c_id पर एक इंडेक्स बनाएं
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );डमी डेटा को 200000 टुपल्स से भरें, जैसे कि 10000 अद्वितीय p_id हों और प्रत्येक p_id के लिए 200 c_id हों
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;कैश साफ़ करने के लिए सर्वर को पुनरारंभ करें। अब एक क्वेरी निष्पादित करें और उसे निष्पादित करने में लगने वाले समय की जांच करें
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msफिर डिस्क से पढ़े गए ब्लॉकों की जांच करें
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0उपरोक्त उदाहरण में, काउंट टुपल्स को खोजने के लिए डिस्क से 1000 ब्लॉक पढ़े गए थे जहां c_id =1. डिस्क से उन रिकॉर्ड्स को लाने के लिए डिस्क I/O शामिल होने के बाद से इसमें 160 एमएस का समय लगा।
यदि उसी क्वेरी को फिर से निष्पादित किया जाता है तो निष्पादन तेज होता है, क्योंकि इस स्तर पर सभी ब्लॉक अभी भी PostgreSQL सर्वर के कैश में हैं
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msऔर डिस्क बनाम कैश से पढ़े जाने वाले ब्लॉक
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000ऊपर से यह स्पष्ट है कि चूंकि सभी ब्लॉक कैश से पढ़े गए थे और किसी डिस्क I/O की आवश्यकता नहीं थी। इसलिए इसने परिणाम भी तेजी से दिए।
PostgreSQL कैश का आकार सेट करना
कैश के आकार को उत्पादन परिवेश में उपलब्ध RAM की मात्रा के साथ-साथ निष्पादित किए जाने वाले प्रश्नों के अनुसार ट्यून करने की आवश्यकता है।
एक उदाहरण के रूप में - 128MB का साझा_बफ़र सभी डेटा को कैश करने के लिए पर्याप्त नहीं हो सकता है, यदि क्वेरी अधिक टुपल्स लाने के लिए थी:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288heap_blks_hit को बढ़ाने के लिए share_buffer को 1024MB में बदलें।
वास्तव में, प्रश्नों (c_id के आधार पर) पर विचार करते हुए, यदि डेटा को फिर से व्यवस्थित किया जाता है, तो छोटे शेयर्ड_बफ़र के साथ बेहतर कैश हिट अनुपात प्राप्त किया जा सकता है।
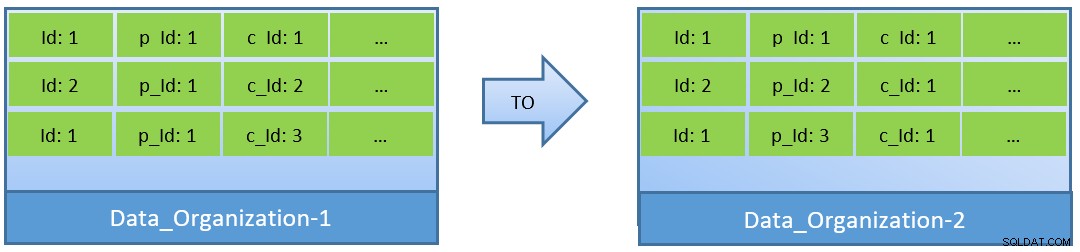
Data_Organization-1 में, PostgreSQL को 1000 ब्लॉक रीड (और कैश खपत) की आवश्यकता होगी ) c_id=1 खोजने के लिए। दूसरी ओर, Data_Organisation-2 के लिए, उसी क्वेरी के लिए, PostgreSQL को केवल 104 ब्लॉक की आवश्यकता होगी।
एक ही क्वेरी के लिए आवश्यक कम ब्लॉक अंततः कम कैश की खपत करते हैं और क्वेरी निष्पादन समय को भी अनुकूलित रखते हैं।
निष्कर्ष
जबकि Share_buffer को PostgreSQL प्रक्रिया स्तर पर बनाए रखा जाता है, अनुकूलित क्वेरी निष्पादन योजनाओं की पहचान के लिए कर्नेल स्तर कैश को भी ध्यान में रखा जाता है। मैं इस विषय को बाद के ब्लॉगों की श्रृंखला में उठाऊंगा।