हर पोस्टग्रेएसक्यूएल रिलीज कुछ प्रमुख फीचर एन्हांसमेंट के साथ आता है, लेकिन जो समान रूप से दिलचस्प है वह यह है कि हर रिलीज अपनी पिछली सुविधाओं में भी सुधार करता है।
चूंकि PostgreSQL 13 जल्द ही जारी होने वाला है, यह जांचने का समय है कि समुदाय हमें कौन सी सुविधाएँ और सुधार ला रहा है। ऐसा ही एक बिना शोर वाला सुधार है "विभाजन के लिए तार्किक प्रतिकृति सुधार।"
चलिए उदाहरण से इस सुविधा सुधार को समझते हैं।
शब्दावली
इस सुविधा को समझने के लिए दो शब्द महत्वपूर्ण हैं:
- विभाजन तालिकाएं
- तार्किक प्रतिकृति
विभाजन तालिकाएं
लाभ प्राप्त करने के लिए एक बड़ी तालिका को अनेक भौतिक टुकड़ों में विभाजित करने का एक तरीका:
- बेहतर क्वेरी प्रदर्शन
- तेज़ अपडेट
- तेज़ बल्क लोड और डिलीट
- धीमी डिस्क ड्राइव पर शायद ही कभी इस्तेमाल किए गए डेटा को व्यवस्थित करना
इनमें से कुछ लाभ विभाजन प्रूनिंग के माध्यम से प्राप्त किए जाते हैं (अर्थात विभाजन की परिभाषा का उपयोग करके क्वेरी प्लानर यह तय करने के लिए कि विभाजन को स्कैन करना है या नहीं) और यह तथ्य कि एक विभाजन सीमित मेमोरी में फिट होना आसान है एक विशाल टेबल की तुलना में।
एक तालिका को इस आधार पर विभाजित किया जाता है:
- सूची
- हैश
- रेंज

तार्किक प्रतिकृति
जैसा कि नाम का तात्पर्य है, यह एक प्रतिकृति विधि है जिसमें डेटा को उनकी पहचान (जैसे कुंजी) के आधार पर वृद्धिशील रूप से दोहराया जाता है। यह वाल या भौतिक प्रतिकृति विधियों के समान नहीं है जहां डेटा बाइट-बाय-बाइट भेजा जाता है।
प्रकाशक-सब्सक्राइबर पैटर्न के आधार पर, डेटा के स्रोत को एक प्रकाशक को परिभाषित करने की आवश्यकता होती है जबकि लक्ष्य को एक ग्राहक के रूप में पंजीकृत करने की आवश्यकता होती है। इसके लिए दिलचस्प उपयोग के मामले हैं:
- चयनात्मक प्रतिकृति (डेटाबेस का केवल कुछ भाग)
- डेटाबेस के दो उदाहरणों को एक साथ लिखता है जहां डेटा दोहराया जा रहा है
- विभिन्न ऑपरेटिंग सिस्टम (जैसे Linux और Windows) के बीच प्रतिकृति
- डेटा की प्रतिकृति पर बेहतर सुरक्षा
- रिसीवर की तरफ से डेटा आने पर निष्पादन को ट्रिगर करता है
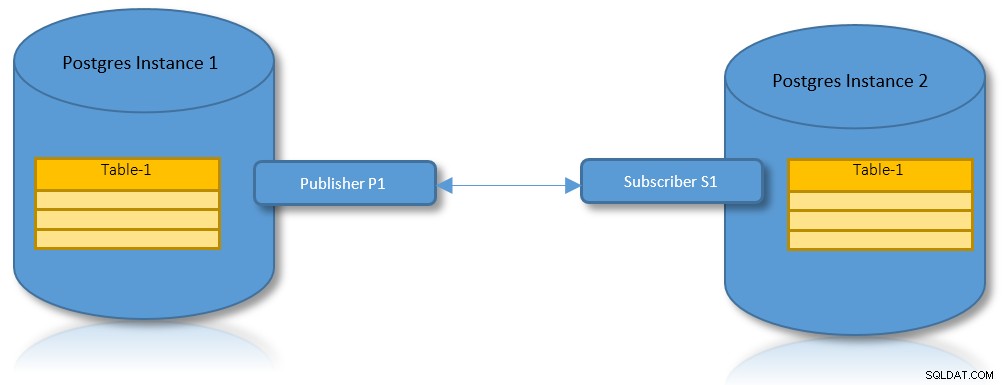
विभाजन के लिए तार्किक प्रतिकृति
तार्किक प्रतिकृति और विभाजन दोनों के लाभों के साथ, यह एक परिदृश्य के लिए एक व्यावहारिक उपयोग का मामला है जहां एक विभाजित तालिका को दो PostgreSQL उदाहरणों में दोहराया जाना चाहिए।
इस संदर्भ में PostgreSQL 13 में किए जा रहे सुधार को स्थापित करने और उजागर करने के लिए निम्नलिखित चरण हैं।
सेटअप
विभाजित तालिका वाले दो अलग-अलग उदाहरणों को चलाने के लिए दो नोड सेटअप पर विचार करें:
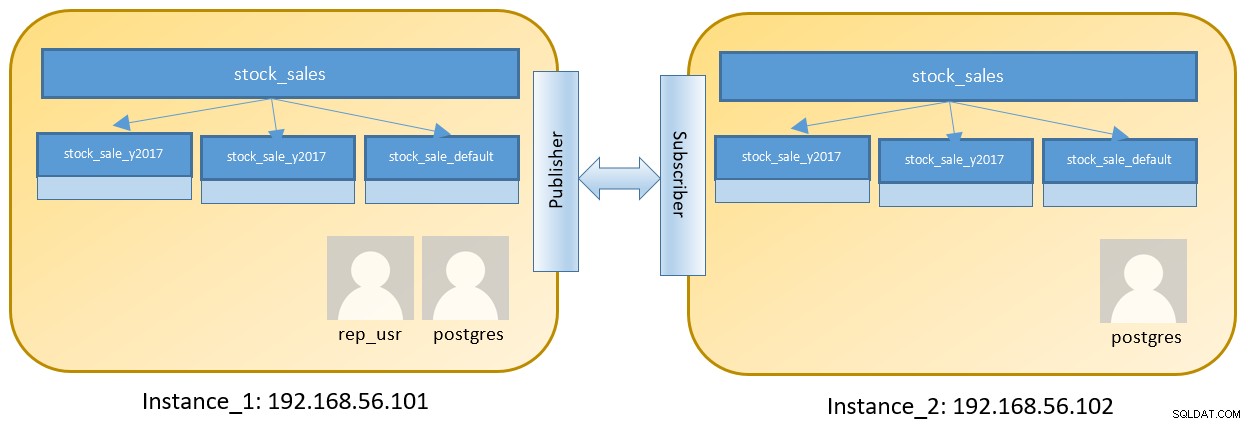
Instance_1 पर चरण 192.168.56.101 पर पोस्ट लॉगिन के रूप में पोस्टग्रेज उपयोगकर्ता के रूप में नीचे दिए गए हैं :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile start'wal_level' को विशेष रूप से 'तार्किक' पर सेट किया जाता है ताकि यह इंगित किया जा सके कि इस उदाहरण से डेटा को दोहराने के लिए तार्किक प्रतिकृति का उपयोग किया जाएगा। 192.168.56.102 से कनेक्शन की अनुमति देने के लिए कॉन्फ़िगरेशन फ़ाइल 'pg_hba.conf' को भी संशोधित किया गया है।
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;हालांकि इंस्टेंस_1 डेटाबेस पर डिफ़ॉल्ट रूप से पोस्टग्रेज भूमिका बनाई जाती है, एक अलग उपयोगकर्ता भी बनाया जाना चाहिए जिसकी सीमित पहुंच हो - जो केवल किसी दिए गए तालिका के दायरे को सीमित करता है।
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Instance_2 पर लगभग समान सेटअप की आवश्यकता है
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startयह ध्यान दिया जाना चाहिए कि चूंकि इंस्टेंस_2 किसी अन्य नोड के लिए डेटा का स्रोत नहीं होगा, इसलिए wal_level सेटिंग्स के साथ-साथ pg_hba.conf फ़ाइल को किसी अतिरिक्त सेटिंग की आवश्यकता नहीं है। कहने की जरूरत नहीं है, pg_hba.conf को उत्पादन आवश्यकताओं के अनुसार अद्यतन करने की आवश्यकता हो सकती है।
तार्किक प्रतिकृति DDL का समर्थन नहीं करती है, हमें Instance_2 पर भी एक तालिका संरचना बनाने की आवश्यकता है। इंस्टेंस_2 पर भी समान तालिका संरचना बनाने के लिए उपरोक्त विभाजन निर्माण का उपयोग करके एक विभाजित तालिका बनाएं।
तार्किक प्रतिकृति सेटअप
PostgreSQL 13 के साथ तार्किक प्रतिकृति सेटअप बहुत आसान हो जाता है। PostgreSQL 12 तक संरचना नीचे की तरह थी:
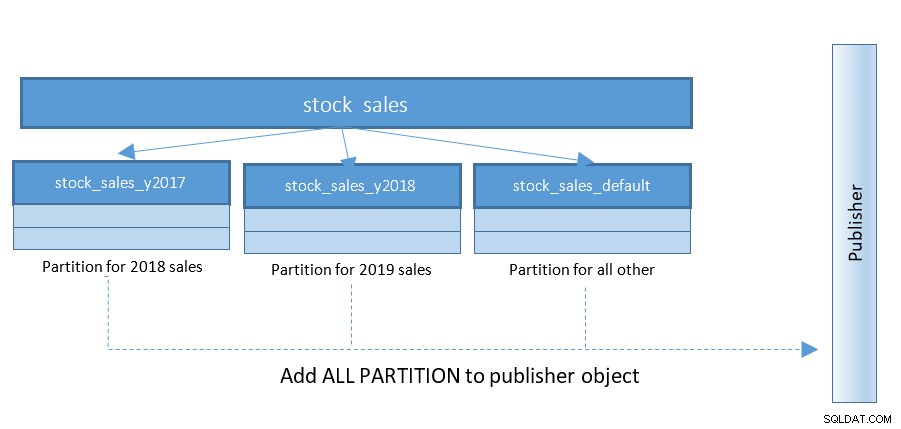
PostgreSQL 13 के साथ, विभाजनों का प्रकाशन बहुत आसान हो जाता है। नीचे दिए गए आरेख को देखें और पिछले आरेख से तुलना करें:
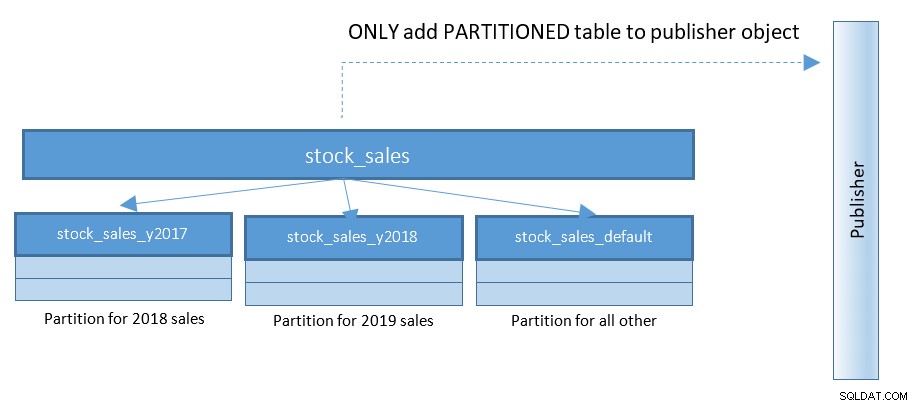
100 और 1000 के विभाजन वाली तालिकाओं के साथ सेटअप के साथ - यह छोटा परिवर्तन सरल करता है चीजें काफी हद तक।
PostgreSQL 13 में, ऐसा प्रकाशन बनाने के लिए कथन होंगे:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);कॉन्फ़िगरेशन पैरामीटर publish_via_partition_root PostgreSQL 13 में नया है, जो प्राप्तकर्ता नोड को थोड़ा अलग पत्ती पदानुक्रम की अनुमति देता है। PostgreSQL 12 में विभाजित तालिकाओं पर केवल प्रकाशन निर्माण, नीचे दिए गए त्रुटि विवरण लौटाएगा:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.पोस्टग्रेएसक्यूएल 12 की सीमाओं को नजरअंदाज करते हुए, और पोस्टग्रेएसक्यूएल 13 पर इस सुविधा के लिए अपने हाथों से आगे बढ़ते हुए, हमें निम्नलिखित कथनों के साथ इंस्टेंस_2 पर ग्राहक स्थापित करना होगा:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;जांच रहा है कि यह वास्तव में काम करता है या नहीं
हम पूरे सेटअप के साथ काफी कुछ कर चुके हैं, लेकिन यह देखने के लिए कि क्या चीजें काम कर रही हैं, आइए कुछ परीक्षण करें।
Instance_1 पर, यह सुनिश्चित करते हुए कई पंक्तियाँ सम्मिलित करें कि वे कई विभाजनों में स्पॉन करती हैं:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Instance_2 पर डेटा जांचें:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721अब देखते हैं कि तार्किक प्रतिकृति काम करती है, भले ही लीफ नोड्स प्राप्तकर्ता पक्ष पर समान न हों।
Instance_1 पर एक और विभाजन जोड़ें और रिकॉर्ड डालें:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Instance_2 पर डेटा जांचें:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174PostgreSQL 13 में अन्य विभाजन सुविधाएँ
PostgreSQL 13 में अन्य सुधार भी हैं जो विभाजन से संबंधित हैं, अर्थात्:
- विभाजित तालिकाओं के बीच जुड़ने में सुधार
- विभाजित तालिकाएं अब पंक्ति-स्तरीय ट्रिगर से पहले का समर्थन करती हैं
निष्कर्ष
मैं निश्चित रूप से अपने अगले ब्लॉग में उपरोक्त दो आगामी विशेषताओं की जाँच करूँगा। तब तक विचार के लिए भोजन - विभाजन और तार्किक प्रतिकृति की संयुक्त शक्ति के साथ, PostgreSQL एक मास्टर-मास्टर सेटअप की ओर बढ़ रहा है?