आजकल किसी से संपर्क करने के कई तरीके हैं, है ना?
हमारे पास विभिन्न फोन हैं:मोबाइल और लैंडलाइन, व्यक्तिगत और काम। हमारे पास अलग-अलग पते हैं - आवासीय, मेलिंग, बिलिंग, व्यवसाय, आदि - और संभवतः कई ईमेल पते भी हैं। स्काइप और विभिन्न मैसेजिंग ऐप्स को न भूलें। अब लिंक्डइन और फेसबुक में जोड़ें-वैसे, दोनों के अपने मैसेजिंग तत्व हैं।
बहुत पहले नहीं, इनमें से कई मौजूद नहीं थे। तो आप इस बात की बहुत अधिक गारंटी दे सकते हैं कि कुछ वर्षों में, हमारे पास लोगों और संगठनों से संपर्क करने का कोई नया तरीका होगा।
क्या हम इस सभी संपर्क जानकारी को इस तरह से मॉडल कर सकते हैं कि 'नवीनतम चीज़' आने पर हमें अपना डेटाबेस डिज़ाइन बदलना न पड़े? जानने के लिए पढ़ें…
पार्टी संपर्क बिंदु मॉडल
एक शब्द में, हाँ। डेटाबेस को ऐसी जानकारी को समायोजित करने के लिए डिज़ाइन किया जा सकता है जो हमारे पास अभी तक नहीं है।
मैं सीधे कूदूंगा और आपको समाधान दिखाऊंगा, फिर मैं वर्णन करूंगा कि टुकड़े एक साथ कैसे काम करते हैं। मैं पार्टियों से संपर्क करने के विभिन्न तरीकों पर कॉल करने जा रहा हूं संपर्क बिंदु , हालांकि मैंने संपर्क विधियां . देखी हैं और यहां तक कि संपर्क स्थान इस्तेमाल किया।
भौतिक रूप से, इन सभी संपर्क बिंदुओं को एक ही तालिका कॉलम में संग्रहीत किया जाएगा, contact_point.contact_value . किसी फ़ोन नंबर, ईमेल पते या वेब पते (URL) के बारे में सोचें और आप समझ जाएंगे कि हम उन सभी को यहां क्यों संग्रहीत कर सकते हैं; वे इस स्तर पर सिर्फ तार (varchars) हैं। भेदभाव मेटाडेटा में है। इसका एकमात्र अपवाद डाक पता है, जिसे बाद में और अधिक विस्तार से वर्णित किया जाएगा।
बाईं ओर की पीली तालिकाओं में मेटाडेटा होता है, और दाईं ओर की नीली तालिकाओं में व्यावसायिक डेटा होता है।
प्रमुख श्रेणियाँ
हालांकि हमारे पास किसी से संपर्क करने के कई तरीके हैं, लेकिन वास्तव में ये तरीके बहुत कम श्रेणियों या प्रकारों में आते हैं। जब आप नीचे दी गई सूची को देखेंगे तो आप देखेंगे कि मेरा क्या मतलब है:
| संपर्क बिंदु प्रकार |
|---|
| फ़ोन नंबर (लैंडलाइन) |
| मोबाइल नंबर |
| फैक्स नंबर |
| ईमेल पता |
| डाक का पता |
| वेब पता |
| पेजर |
एक मायने में, ये शारीरिक रूप से अलग हैं। बेशक, आप लैंडलाइन या किसी अन्य मोबाइल पर कॉल करने के लिए मोबाइल फोन का उपयोग कर सकते हैं। जब लैंडलाइन और मोबाइल के बीच वॉयस कॉल की बात आती है, तो अंतर इतना महत्वपूर्ण नहीं है। फिर भी, हम लैंडलाइन की तुलना में मोबाइल पर टेक्स्ट (एसएमएस) भेजने की अधिक संभावना रखते हैं।
लेकिन आप जानबूझकर फैक्स नंबर पर कॉल करने की संभावना नहीं रखते हैं। आखिर 'उफ़, गलत नंबर' के अलावा आप इसे सुनते ही क्या कहने वाले हैं? आप स्वाभाविक रूप से किसी अन्य फ़ैक्स मशीन से कॉल करने की अधिक संभावना रखते हैं, चाहे वह भौतिक हो या नकली। आप न तो लैंडलाइन को पत्र भेजेंगे, न ही डाक पते पर वॉयस कॉल करने का प्रयास करेंगे।
यह महत्वपूर्ण है कि हम इन प्रकारों में अंतर करें, क्योंकि हम उनके साथ अलग तरह से बातचीत करते हैं। यह विशेष रूप से सच होगा यदि आपके आवेदन में संचार सेवाओं के साथ किसी प्रकार का एकीकरण है। यह जानने की जरूरत है कि किस प्रकार के साथ इंटरैक्ट करना है।
पार्टियां कैसे संपर्क बिंदुओं का उपयोग करती हैं
यह शायद थोड़ा अधिक सहज है, हम संपर्क प्रकारों के बारे में कैसे सोचते हैं, इसके अनुरूप थोड़ा अधिक है। यहां एक लंबी सूची है (लेकिन संपूर्ण नहीं!) जो आपको इन प्रकारों के बारे में जानने में मदद करेगी:
| पार्टी संपर्क प्रकार (संपर्क बिंदु प्रकार) |
|---|
| कॉन्फ्रेंस लाइन (फोन नंबर) |
| बिलिंग पता (डाक पता) |
| वितरण पता (डाक पता) |
| सीधी लाइन (फ़ोन नंबर) |
| छुट्टी/छुट्टी का पता (डाक का पता) |
| छुट्टी/छुट्टी का फ़ोन (फ़ोन नंबर) |
| घर का पता (डाक का पता) |
| होम फ़ोन (फ़ोन नंबर) |
| होम फोन/फैक्स (फोन नंबर) |
| लिंक्डइन प्रोफ़ाइल (वेब पता) |
| मुख्य पता (डाक पता) |
| मुख्य ईमेल (ईमेल पता) |
| मुख्य फ़ैक्स (फ़ैक्स नंबर) |
| मुख्य फ़ोन (फ़ोन नंबर) |
| मुख्य वेबसाइट (वेब पता) |
| निजी ईमेल (ईमेल पता) |
| निजी फैक्स (फैक्स नंबर) |
| निजी मोबाइल (मोबाइल नंबर) |
| निजी पेजर (पेजर) |
| निजी वेबसाइट (वेब पता) |
| द्वितीयक पता (डाक का पता) |
| द्वितीयक फ़ोन (फ़ोन नंबर) |
| सोशल मीडिया प्रोफाइल (वेब पता) |
| कार्य का पता (डाक का पता) |
| कार्य ईमेल (ईमेल पता) |
| कार्य फ़ैक्स (फ़ैक्स नंबर) |
| कार्य मोबाइल (मोबाइल नंबर) |
| कार्य फ़ोन (फ़ोन नंबर) |
डाक का पता - एक विशेष मामला
डाक पते के अपवाद के साथ, इन सभी संपर्क बिंदु प्रकारों को एक ही फ़ील्ड में संग्रहीत किया जाता है। इसके लिए आम तौर पर कई पंक्तियों (या फ़ील्ड) की आवश्यकता होती है।
यहां एक ब्लॉग आलेख है जो डाक पतों को संग्रहीत करने का एक सरल, भाषा-अज्ञेय तरीका प्रस्तावित करता है। यदि आपकी आवश्यकताएँ बल्कि बुनियादी हैं - उदा। सिस्टम में दर्ज होने के साथ ही एड्रेस लेबल को प्रिंट करने के लिए - यह दृष्टिकोण पर्याप्त होगा। अगर आपकी ज़रूरतें अधिक परिष्कृत हैं, तो आपको शायद एक अलग समाधान विकसित करना होगा।
एड्रेसिंग कितनी जटिल हो सकती है, इसका अंदाजा लगाने के लिए, ब्रिटिश स्टैंडर्ड BS7666 एड्रेस टाइप्स के लिए इस स्कीमा पर एक नज़र डालें। मानक में स्ट्रीट गजेटियर, भूमि और संपत्ति गजेटियर, और वितरण बिंदुओं को कवर करने वाले कई भाग शामिल हैं। यह वाणिज्यिक या आवासीय संपत्तियों के बीच अंतर नहीं करता है; कब्जे वाली, विकसित या खाली भूमि के बीच; शहरी या ग्रामीण क्षेत्रों के बीच; या डाक-पता योग्य संस्थाओं और गैर-डाक-पता योग्य संस्थाओं के बीच जैसे संचार मस्तूल (टावर)। इसे प्राप्त करने के लिए, यह उन शब्दों का परिचय देता है जिनसे हम में से अधिकांश शायद परिचित नहीं हैं, जैसे कि प्राथमिक पता योग्य वस्तु (PAO), जो एक पता योग्य वस्तु को दिया गया नाम है जिसे किसी अन्य पता योग्य वस्तु के संदर्भ के बिना संबोधित किया जा सकता है। पीएओ के परिचित उदाहरणों में भवन का नाम या सड़क संख्या शामिल है। एक सेकेंडरी एड्रेसेबल ऑब्जेक्ट (एसएओ) किसी भी एड्रेसेबल ऑब्जेक्ट को दिया जाता है जिसे पीएओ के संदर्भ में संबोधित किया जाता है। यह किसी नामित इमारत की पहली मंजिल हो सकती है।
हमें इसका एक दृश्य देने के लिए, मैंने इसे यूएमएल मॉडलिंग टूल में जल्दी से रिवर्स-इंजीनियर किया। यहाँ हमें क्या मिलता है:
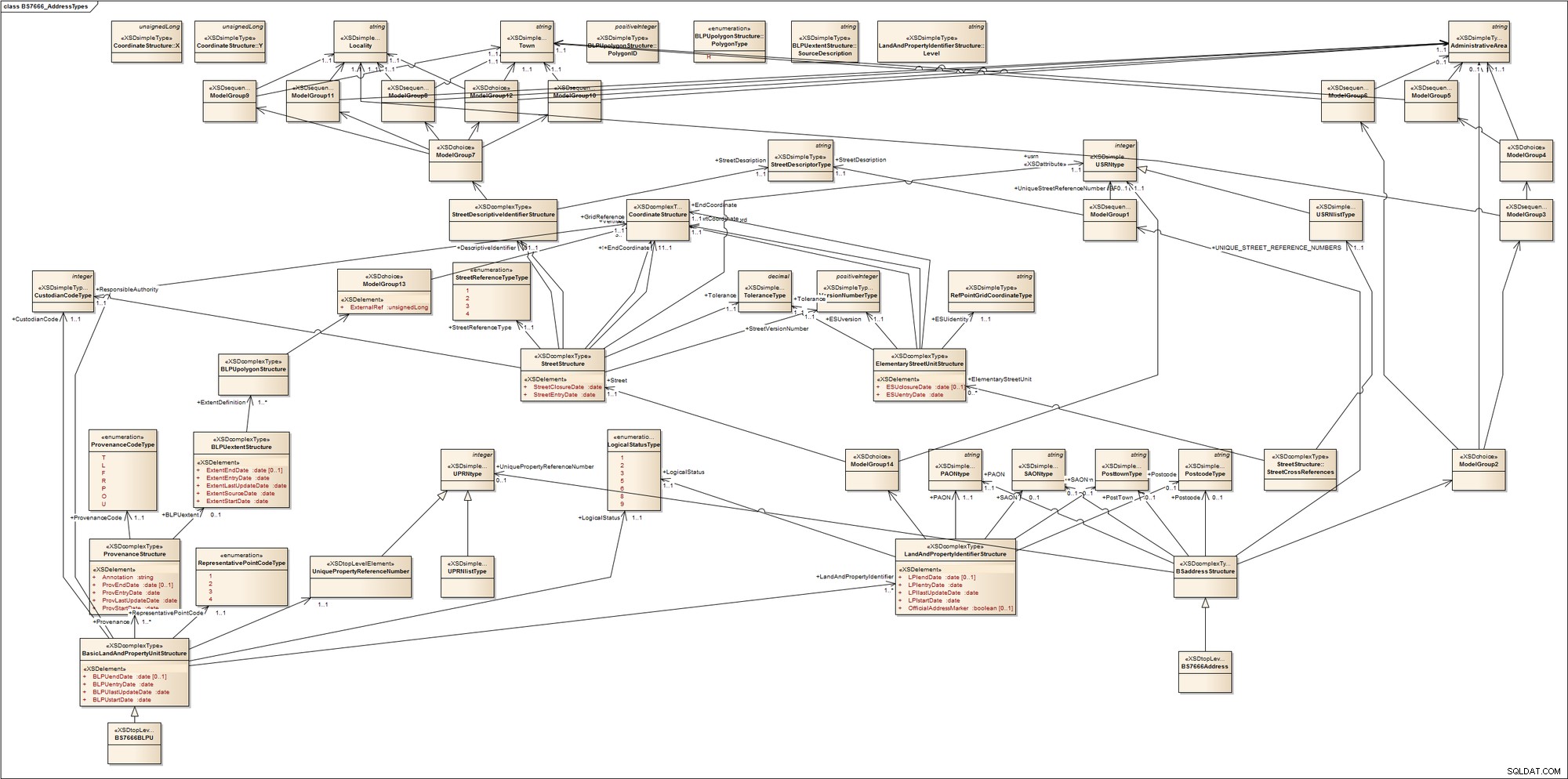
मेरा कहना है कि यह बहुत जटिल और गन्दा हो सकता है; कुछ डोमेन में संबोधित करना वास्तव में बहुत जटिल हो सकता है।
यदि आप इसे एक एकल संबंधपरक तालिका में समतल करना चाहते हैं, तो आपको निम्न जैसा कुछ मिलेगा:
हालांकि यह BS7666 एड्रेस कंपोनेंट्स को कैप्चर करता है, लेकिन यह आपको यह नहीं बताता कि मॉडल कैसे काम करता है। XML स्कीमा के सभी रिलेशनल लॉजिक एप्लिकेशन लॉजिक में छिपे हो जाते हैं।
ये दो आरेख दो डेटा मॉडलिंग चरम सीमाओं . का प्रतिनिधित्व करते हैं . लेकिन क्या पतों को मॉडल करने का कोई बीच का रास्ता है?
एक अपेक्षाकृत सरल पता मॉडल होना वास्तव में संभव है जो लचीला और विन्यास योग्य हो।
पता घटक
एड्रेस कंपोनेंट आमतौर पर एड्रेस लेबल पर एक लाइन होता है, या बल्कि लाइन का प्रकार . होता है पता लेबल पर। यूके के पतों के लिए जिन घटकों का हम आमतौर पर उपयोग करते हैं, वे निम्न तालिका में सूचीबद्ध हैं:
| पता घटक प्रकार |
|---|
| पताकर्ता |
| क्षेत्र |
| भवन का नाम |
| भवन संख्या |
| देश |
| काउंटी |
| विभाग का नाम |
| आश्रित इलाके |
| आश्रित ख़ालिस नाम |
| डबल डिपेंडेंट लोकैलिटी |
| अंतर्राष्ट्रीय पोस्ट कोड |
| स्तर |
| इलाका |
| मेल सॉर्ट एसएससी |
| संगठन का नाम |
| PAO अंतिम संख्या |
| PAO अंतिम प्रत्यय |
| PAO प्रारंभ संख्या |
| PAO प्रारंभ प्रत्यय |
| PAO टेक्स्ट |
| पीओ बॉक्स |
| पोस्ट कोड |
| पोस्ट टाउन |
| पोस्टकोड |
| पोस्टकोड प्रकार |
| एसएओ अंतिम संख्या |
| एसएओ एंड सफ़िक्स |
| एसएओ प्रारंभ संख्या |
| एसएओ प्रारंभ प्रत्यय |
| एसएओ टेक्स्ट |
| सड़क |
| सड़क विवरण |
| उप-भवन का नाम |
| पूरी तरह से नाम |
| नगर |
आपके पास तीन या चार पता लाइनें हो सकती हैं, साथ ही पोस्ट टाउन और पोस्टकोड भी हो सकता है। हालांकि, आपके सामने आने वाली कठिनाई यह है कि इन पंक्तियों में वास्तव में क्या है जब यह मायने रखता है - उदा। सिस्टम के बीच डेटा मैप करते समय। जब आप डेटा प्रोफाइलिंग करते हैं, तो आप पाएंगे कि पता पंक्ति 3 में कभी-कभी एक आश्रित इलाका होता है, लेकिन कभी-कभी इसमें एक काउंटी या इलाका होता है। अब आप प्राकृतिक भाषा प्रसंस्करण (एनएलपी) में हैं; आपको अंतर को पहचानना होगा इलाके और काउंटी के बीच। और जैसे-जैसे आप और देशों को जोड़ते हैं क्रमपरिवर्तन कई गुना बढ़ जाता है।
इसलिए हमें उन सभी देशों के लिए सभी पता घटकों को परिभाषित करना चाहिए जिनमें हम काम करते हैं।
पता प्रारूप
पता प्रारूप दो भागों से बने होते हैं:एक शीर्षलेख और उसका विवरण। हेडर मूल रूप से नाम या शीर्षक है जो पता प्रारूप . है से जाना जाता है। उदाहरणों में शामिल हो सकते हैं:
| पता प्रारूप प्रकार |
|---|
| सामान्य 3-पंक्ति |
| सामान्य 5-पंक्ति |
| ब्रिटिश सेना डाकघर (बीएफपीओ) |
| अंतर्राष्ट्रीय |
| डाकघर का पता (PAF) |
| यू.एस. पता |
| फ्रेंच पता |
उदाहरण के तौर पर यूके के पूर्ण डाकघर पता प्रारूप (पीएएफ) को लेते हुए, हम निम्नलिखित पता प्रारूप घटकों को परिभाषित करते हैं:
| प्रारूप | <थ>घटकअनुक्रम | अनिवार्य है? | |
|---|---|---|---|
| PAF | पताकर्ता | 1 | एन |
| PAF | संगठन का नाम | 2 | एन |
| PAF | विभाग का नाम | 3 | एन |
| PAF | पीओ बॉक्स | 4 | एन |
| PAF | भवन का नाम | 5 | एन |
| PAF | उप-भवन का नाम | 6 | एन |
| PAF | भवन संख्या | 7 | एन |
| PAF | पूरी तरह से | 8 | एन |
| PAF | सड़क | 9 | एन |
| PAF | डबल डिपेंडेंट लोकैलिटी | 10 | एन |
| PAF | आश्रित स्थान | 11 | एन |
| PAF | पोस्ट टाउन | 12 | वाई |
| PAF | पोस्टकोड | 13 | वाई |
हमारा एप्लिकेशन इस मेटाडेटा को पढ़ता है और पता घटकों को सही क्रम में प्रदर्शित करता है। जब पता कैप्चर की आवश्यकता होती है, तो मेटाडेटा हमें बताता है कि पता घटक अनिवार्य है या नहीं।
अधिक बार, हमारा एप्लिकेशन अंतिम उपयोगकर्ता से पोस्टकोड का अनुरोध करता है और संबंधित मानों को देखता है और पता घटकों को स्वचालित रूप से पॉप्युलेट करता है। कुछ एप्लिकेशन उपयोगकर्ता को पता संपादित करने की अनुमति देते हैं; अन्य [कष्टप्रद] नहीं करते हैं!
यह पीडीएम में नहीं दिखाया जाता है, लेकिन अगर आपका संगठन अंतरराष्ट्रीय स्तर पर काम करता है, तो आप address_format_type के बीच कई-से-अनेक संबंध परिभाषित कर सकते हैं और country ताकि सही पता प्रारूप (उपयोगकर्ता के देश के आधार पर) अंतिम उपयोगकर्ता (party) को प्रस्तुत किया जा सके )।
कब और केवल जब contact_points एक डाक पता है contact_point_type , इसका एक पता_format_type से संबंध होना चाहिए। इसके विपरीत, यह इस प्रकार है कि गैर-डाक पता प्रकार कभी नहीं address_format_type . से संबंध रखें . इसके अलावा, प्रारूप स्थिर रहना चाहिए contact_points . के जीवन भर के लिए , अन्यथा आप डेटा अखंडता मुद्दों की संभावना का परिचय देंगे। (इसके लिए ऐसा नहीं होना चाहिए , लक्ष्य address_format_components स्रोत का एक सबसेट होना चाहिए address_format_components )।
कॉलम contact_value डाक पते का कोई अर्थ नहीं है क्योंकि मान ddress_line.line_content में संग्रहीत हैं . इसके विपरीत, contact_value अन्य सभी contact_point_types . के लिए अनिवार्य है . मूल रूप से, contact_point.contact_value और address_line.line_content परस्पर अनन्य हैं।
पार्टी और संपर्क बिंदु के बीच अनेक-से-अनेक संबंध
आप contact_points के बारे में सोच सकते हैं (प्लस address_line ) मान और party_contact . के रूप में उपयोग को परिभाषित करने के रूप में। यह एकल contact_points . की अनुमति देता है एकाधिक उपयोग . करने के लिए . हमारे घर [डाक] का पता संदर्भ के आधार पर हमारा बिलिंग पता और वितरण पता भी हो सकता है।
अब तक, कहानी में यह माना गया है कि एक पार्टी एक विशेष contact_points . का मालिक है . लेकिन डेटा मॉडल इस स्वामित्व नियम को लागू नहीं करता है! यह किसी भी तरह का कोई प्रतिबंध नहीं लगाता है। इस डिज़ाइन के साथ एक और संभावना मौजूद है:एक ही संपर्क बिंदुओं के लिए कई पक्ष।
इस मार्ग पर उतरने से पहले आपको इसके निहितार्थों पर सावधानीपूर्वक विचार करने की आवश्यकता है।
यहाँ एक उदाहरण है। यूके में, पुरस्कार देने वाले संगठन (एओ) आमतौर पर शिक्षकों को परीक्षक के रूप में नियुक्त करते हैं। एक शिक्षक के दो संबंध होते हैं:एक उस स्कूल के साथ जहां वह काम करता है, और दूसरा एओ के साथ एक परीक्षक के रूप में। स्कूल में contact_points . का एक बैंक होगा विभिन्न फोन नंबरों और संभवतः एक या अधिक डाक पते के साथ। ये स्कूल का मुख्य पता (डाक पता), मुख्य ईमेल (ईमेल पता), मुख्य फैक्स (फैक्स नंबर), और मुख्य फोन (फोन नंबर) जैसी चीजें होंगी।
यह पूरी तरह से संभव है कि हमारे परीक्षक उसी contact_points . का उपयोग कर सकें अपने स्कूल के रूप में, लेकिन वह party_contact . का उपयोग करेगा/करेगी उन्हें काम से संबंधित के रूप में परिभाषित करने के लिए। अगर स्कूल का मुख्य फोन नंबर बदल जाता है, तो शिक्षक का काम नंबर अपने आप अपडेट हो जाएगा, जो काफी साफ-सुथरा है।
यदि आप इस मार्ग से नीचे जाते हैं, तो आपको आवेदन स्तर पर . परिभाषित करना होगा contact_points . को अपडेट करने के लिए किस पार्टी या पार्टियों को अनुमति है? ।
प्रदर्शन पर एक त्वरित शब्द
पीले मेटाडेटा तालिकाओं का लगातार प्रश्नों द्वारा उपयोग किया जा रहा है। नतीजतन, उनके स्मृति में बने रहने की संभावना है। अधिकांश RDBMS पर, आप इसे सुनिश्चित करने के लिए तालिकाओं को मेमोरी में पिन कर सकते हैं। ओरेकल में, मैं इन्हें इंडेक्स-संगठित टेबल के रूप में बनाउंगा, जो छोटे हैं और अच्छा प्रदर्शन करते हैं। अपने RDBMS के लिए जो भी समकक्ष हो वह करें।
आप यह भी सुनिश्चित करना चाहते हैं कि party_contact party_id पर संकुल अनुक्रमणिका का उपयोग करके पंक्तियों को एक ही ब्लॉक (या पृष्ठ) में सह-स्थित किया जाता है . address_line.contact_point_id . के साथ भी ऐसा ही करें . यह IO की राशि में कटौती करता है।
एक अन्य विकल्प मौजूद है यदि आप party . चाहते हैं विशेष रूप से एक contact_points . के स्वामी होने के लिए . फिर आप contact_points . को मर्ज कर सकते हैं party_contact . में party_contact_point बनाने के लिए (अभी भी party_id पर क्लस्टर किया गया है ) यह मॉडल को सरल करता है और प्रदर्शन में सहायता कर सकता है।
संपर्क बदलने का मतलब डेटाबेस बदलना नहीं है
हम ऐसे समय में रहते हैं जब यह कहा जा सकता है कि परिवर्तन ही एकमात्र स्थिरांक है।
इसका मतलब यह नहीं है कि हर बार जब कुछ बदलता है तो इसका असर आपके डेटाबेस पर पड़ता है। थोड़े से विचार के साथ, हम अपने डिजाइनों को भविष्य में प्रमाणित कर सकते हैं - शायद उससे कहीं अधिक जो हमने आज तक किया है। ऐसा करने से हमें अपरिहार्य परिवर्तन का तुरंत जवाब देने में मदद मिलती है।
यदि आप ग्रीन-फील्ड प्रोजेक्ट शुरू कर रहे हैं, तो मैं संगठनों और लोगों के लिए पार्टी मॉडल (जिसमें से संपर्क बिंदु एक हिस्सा है) का उपयोग करने की सलाह दूंगा। क्यों न इस मॉडल को खोलें और इसे अपनी आवश्यकताओं के अनुसार ट्वीक करें? कृपया बेझिझक एक प्रति लें और इसे अपना बनाएं।
लेकिन अगर आपका डेटाबेस या डेटाबेस पहले से ही निर्धारित हैं, तो मैंने यहां जो स्कीमा प्रस्तुत किया है, उसका उपयोग अभी भी एक्सएमएल फॉर्म में किया जा सकता है, ताकि सिस्टम के बीच डेटा को एकीकृत करते समय आपके पेलोड को परिभाषित किया जा सके।



