हैश इंडेक्स डेटाबेस का एक अभिन्न अंग हैं। यदि आपने कभी डेटाबेस का उपयोग किया है, तो संभावना है कि आपने उन्हें बिना एहसास के भी क्रिया में देखा हो।
हैश इंडेक्स अन्य प्रकार के इंडेक्स से काम में भिन्न होते हैं क्योंकि वे पॉइंटर्स के बजाय डिस्क पर स्थित रिकॉर्ड के लिए मूल्यों को संग्रहीत करते हैं। यह सूचकांक में तेजी से खोज और प्रविष्टि सुनिश्चित करता है। इसलिए हैश इंडेक्स को अक्सर प्राथमिक कुंजी या विशिष्ट पहचानकर्ता के रूप में उपयोग किया जाता है।
हैश इंडेक्स को समझना
हैश इंडेक्स एक इंडेक्स प्रकार है जो डेटा प्रबंधन में सबसे अधिक उपयोग किया जाता है। यह आम तौर पर एक कॉलम पर बनाया जाता है जिसमें अद्वितीय मान होते हैं, जैसे प्राथमिक कुंजी या ईमेल पता। हैश इंडेक्स का उपयोग करने का मुख्य लाभ उनका तेज प्रदर्शन है।
इन इंडेक्स के पीछे की अवधारणा को किसी ऐसे व्यक्ति के लिए समझने के लिए परिष्कृत किया जा सकता है जिसने पहले कभी उनके बारे में नहीं सुना है। हालाँकि, हैश इंडेक्स को समझना महत्वपूर्ण है यदि आपको यह समझने की आवश्यकता है कि डेटाबेस कैसे काम करता है। डेटाबेस से संबंधित सामान्य समस्याओं और उनकी गति को हल करने के लिए यह आवश्यक है।
अच्छी खबर यह है कि थोड़े से धैर्य और मोबाइल फोन के बंद होने से, आप निश्चित रूप से हैश इंडेक्स में महारत हासिल कर सकते हैं! तो, आइए एक बेहतर नज़र डालें।
त्वरित और आसान
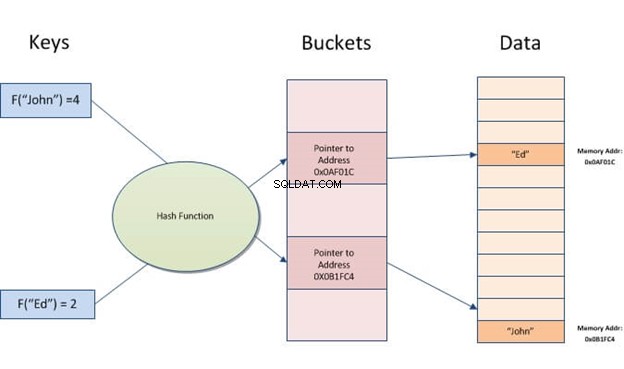
हैश इंडेक्स एक डेटा संरचना है जिसका उपयोग डेटाबेस प्रश्नों को तेज करने के लिए किया जा सकता है। यह इनपुट रिकॉर्ड को बकेट की एक सरणी में परिवर्तित करके काम करता है। प्रत्येक बकेट में तालिका में अन्य सभी बकेट के रिकॉर्ड की संख्या समान होती है। इस प्रकार, किसी विशेष कॉलम के लिए आपके पास चाहे कितने भी अलग-अलग मान हों, प्रत्येक पंक्ति हमेशा एक बकेट में मैप की जाएगी।
हैश इंडेक्स टेबल में संग्रहीत डेटा पर त्वरित लुकअप की अनुमति देता है। वे मूल्य से एक इंडेक्स कुंजी बनाकर काम करते हैं और फिर परिणामी हैश के आधार पर इसका पता लगाते हैं। यह तब उपयोगी होता है जब समान मान या डुप्लीकेट के साथ बहुत सारे इनपुट होते हैं, क्योंकि इसे केवल सभी रिकॉर्ड देखने के बजाय कुंजियों की तुलना करने की आवश्यकता होती है।
क्या यह न तो जल्दी था और न ही आसान? यह समझने के लिए कि हैश इंडेक्स कैसे काम करते हैं और वे इतने शक्तिशाली क्यों हैं, आपको यह समझने की जरूरत है कि हैशिंग का क्या मतलब है।
हैशिंग जानकारी का एक टुकड़ा (एक स्ट्रिंग) ले रहा है और बाद में त्वरित पहुंच के लिए इसे एक पते या सूचक में बदल रहा है।
हैशिंग के साथ विचार यह है कि डेटा को एक छोटी संख्या सौंपी जाती है। जब आप डेटा देख रहे होते हैं, तो आपको वास्तव में बड़े पैमाने पर झारना नहीं पड़ता है। इसके बजाय, बस उस एक नंबर को देखें। दर्जनों पेजों को खुद पढ़ने के बजाय सबसे आसान उदाहरण है Ctrl+F- उस शब्द को जिसे आप टेक्स्ट में ढूंढ रहे हैं।
हैश इंडेक्स किसके लिए हैं?
हैश इंडेक्स खोज प्रक्रिया को तेज करने का एक तरीका है। पारंपरिक अनुक्रमणिका के साथ, आपको यह सुनिश्चित करने के लिए प्रत्येक पंक्ति को स्कैन करना होगा कि आपकी क्वेरी सफल है। लेकिन हैश इंडेक्स के साथ ऐसा नहीं है!
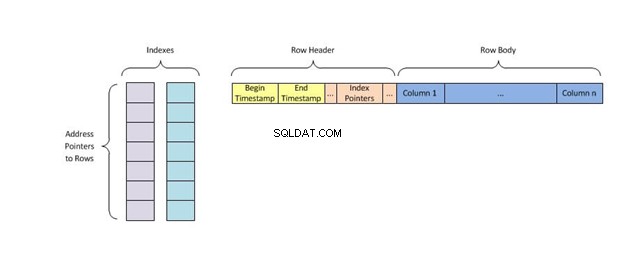
अनुक्रमणिका की प्रत्येक कुंजी में तालिका डेटा की केवल एक पंक्ति होती है और हैशिंग नामक अनुक्रमण एल्गोरिथम का उपयोग करती है जो उन्हें स्मृति में एक अद्वितीय स्थान प्रदान करता है, जो वह ढूंढ रहा है उसे खोजने से पहले डुप्लिकेट मानों वाली अन्य सभी कुंजियों को हटा देता है।
हैश इंडेक्स डेटाबेस में डेटा को व्यवस्थित करने के कई तरीकों में से एक है। वे इनपुट लेकर और डिस्क पर स्टोरेज के लिए कुंजी के रूप में इसका उपयोग करके काम करते हैं। ये कुंजी, या हैश मान , इनपुट में स्ट्रिंग की लंबाई से लेकर वर्णों तक कुछ भी हो सकता है।
विशिष्ट विशेषताओं के साथ विशिष्ट इनपुट को क्वेरी करते समय हैश इंडेक्स का सबसे अधिक उपयोग किया जाता है। उदाहरण के लिए, यह सभी ए-अक्षरों को ढूंढ रहा है जो 10 सेमी से अधिक हैं। हैश इंडेक्स फ़ंक्शन बनाकर आप इसे जल्दी से कर सकते हैं।
हैश इंडेक्स PostgreSQL डेटाबेस सिस्टम का एक हिस्सा हैं। इस प्रणाली को गति और प्रदर्शन को बढ़ाने के लिए विकसित किया गया था। हैश इंडेक्स का उपयोग अन्य इंडेक्स प्रकारों, जैसे बी-ट्री या जीआईएसटी के संयोजन में किया जा सकता है।
एक हैश इंडेक्स चाबियों को बकेट नामक छोटे टुकड़ों में विभाजित करके संग्रहीत करता है, जहां हैश तालिका में किसी कुंजी के स्थान की खोज करते समय प्रत्येक बकेट को एक पूर्णांक आईडी-नंबर दिया जाता है। बाल्टी को क्रमिक रूप से एक डिस्क पर संग्रहीत किया जाता है ताकि उनमें मौजूद डेटा को जल्दी से एक्सेस किया जा सके।
इस पृष्ठ पर अधिक तकनीकी स्पष्टीकरण मिल सकते हैं (राइट-माउस-क्लिक करें और "अंग्रेजी में अनुवाद करें" चुनें)।
फायदे
हैश इंडेक्स का उपयोग करने का मुख्य लाभ यह है कि वे कुंजी मान द्वारा रिकॉर्ड प्राप्त करते समय तेजी से पहुंच की अनुमति देते हैं। यह अक्सर समानता की स्थिति वाले प्रश्नों के लिए उपयोगी होता है। साथ ही, हैश बेंचमार्क का उपयोग करने के लिए अधिक संग्रहण स्थान की आवश्यकता नहीं होगी। इस प्रकार, यह एक प्रभावी उपकरण है, लेकिन कमियों के बिना नहीं।
नुकसान
हैश इंडेक्स एक अपेक्षाकृत नई इंडेक्सिंग संरचना है जिसमें महत्वपूर्ण प्रदर्शन लाभ प्रदान करने की क्षमता है। आप उन्हें बाइनरी सर्च ट्री (बीएसटी) के विस्तार के रूप में सोच सकते हैं।
हैश इंडेक्स डेटा को उनके हैश वैल्यू के आधार पर बकेट में स्टोर करके काम करते हैं, जो डेटा की तेज और कुशल पुनर्प्राप्ति की अनुमति देता है। उनके क्रम में होने की गारंटी है।
हालाँकि, डुप्लिकेट कुंजियों को एक बाल्टी के भीतर संग्रहीत करना असंभव है। इसलिए, हमेशा कुछ ओवरहेड होगा। लेकिन अभी तक, हैश इंडेक्स का उपयोग करने के फायदे विपक्ष से आगे निकल गए हैं।
यह सब कुछ और गहराई में कैसे काम करता है?
आइए एक डेमो लें aviasales हैश इंडेक्स कैसे काम करता है, इसकी अधिक गहन समझ प्राप्त करने के लिए डेटाबेस।
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
यहां आप देख सकते हैं कि हम डेटा को सेट में संकलित करके हैश इंडेक्स कैसे लागू कर रहे हैं।
यह एक आसान उदाहरण है, लेकिन ध्यान दें कि सीमाएं कम कोड अवसंरचना के साथ आती हैं। क्रैश के बाद WAL-लॉग एक्सेस की कमी या इंडेक्स (सूचकांक?) को पुनर्प्राप्त करने में असमर्थता हो सकती है। इसके अलावा, अनुक्रमणिका प्रतिकृति में भाग नहीं ले सकती है - यह PostgreSQL के पुराने होने के कारण है। हालांकि, पायथन की तरह ही, आपको चेतावनियां मिलती हैं जो अक्सर आपको गलतियों को रोकने की अनुमति देती हैं।
यदि आप पर्याप्त रूप से उत्सुक हैं तो आप इन इंडेक्स के अंदर गहराई से देख सकते हैं। उसके लिए, हम एक पृष्ठ निरीक्षण . बना रहे हैं विस्तार उदाहरण।
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
यदि आप पूरी तरह से कोड का निरीक्षण करना चाहते हैं, तो README से शुरू करें।
सारांश
हैश इंडेक्स एक डेटा संरचना है जो बड़े डेटाबेस में जानकारी खोजने की प्रक्रिया को गति देता है। वे डेटा को छोटे टुकड़ों में विभाजित करके और फिर उन्हें क्रमबद्ध करके काम करते हैं। इस प्रकार, जब आप किसी चीज़ की खोज करते हैं, तो आप उसे बहुत तेज़ी से ढूंढ सकते हैं।
यदि आप और अधिक सामग्री देखना चाहते हैं, तो DYOR के लिए संसाधन हैं। साथ ही, हमारे नए लेखों पर नज़र रखें, जो इस पृष्ठ पर "हैश" शब्द को Ctrl+F से अधिक तेज़ी से प्रकाशित कर रहे हैं। आशा है कि यह मदद करता है!