2012 में वापस, मैंने यहां एक ब्लॉग पोस्ट लिखा था जिसमें एक माध्यिका की गणना के लिए दृष्टिकोण पर प्रकाश डाला गया था। उस पोस्ट में, मैंने बहुत ही सरल मामले को निपटाया:हम एक संपूर्ण तालिका में एक कॉलम का माध्यिका खोजना चाहते थे। तब से मुझे कई बार इसका उल्लेख किया गया है कि एक विभाजित माध्य की गणना करने के लिए एक अधिक व्यावहारिक आवश्यकता है . मूल मामले की तरह, SQL सर्वर के विभिन्न संस्करणों में इसे हल करने के कई तरीके हैं; आश्चर्य नहीं कि कुछ दूसरों की तुलना में बहुत बेहतर प्रदर्शन करते हैं।
पिछले उदाहरण में, हमारे पास केवल सामान्य कॉलम आईडी और वैल थे। आइए इसे और अधिक यथार्थवादी बनाएं और कहें कि हमारे पास बिक्री वाले लोग हैं और उन्होंने कुछ अवधि में कितनी बिक्री की है। हमारे प्रश्नों का परीक्षण करने के लिए, आइए पहले 17 पंक्तियों के साथ एक साधारण ढेर बनाएं, और सत्यापित करें कि वे सभी हमारे द्वारा अपेक्षित परिणाम उत्पन्न करते हैं (सेल्सपर्सन 1 का माध्य 7.5 है, और सेल्सपर्सन 2 का माध्य 6.0 है):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
यहां वे प्रश्न दिए गए हैं, जिनका हम परीक्षण करने जा रहे हैं (बहुत अधिक डेटा के साथ!) मैंने पिछले परीक्षण से कुछ प्रश्नों को छोड़ दिया है, जो या तो बिल्कुल भी स्केल नहीं करते थे या विभाजित मध्यस्थों के लिए बहुत अच्छी तरह से मैप नहीं करते थे (अर्थात्, 2000_B, जो #temp तालिका का उपयोग करता था, और 2005_A, जो विरोधी पंक्ति का उपयोग करता था नंबर)। हालाँकि, मैंने ड्वेन कैंप्स (@DwainCSQL) के एक हालिया लेख से कुछ दिलचस्प विचार जोड़े हैं, जो मेरी पिछली पोस्ट पर बनाया गया था।
एसक्यूएल सर्वर 2000+
पिछले दृष्टिकोण से एकमात्र तरीका जो SQL सर्वर 2000 पर पर्याप्त रूप से काम करता था, यहां तक कि इसे इस परीक्षण में शामिल करने के लिए "एक आधे का न्यूनतम, दूसरे का अधिकतम" दृष्टिकोण था:
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; मैंने ईमानदारी से #temp तालिका संस्करण की नकल करने की कोशिश की, जिसका उपयोग मैंने सरल उदाहरण में किया था, लेकिन यह बिल्कुल भी अच्छा नहीं था। 20 या 200 पंक्तियों में इसने ठीक काम किया; 2000 में इसमें लगभग एक मिनट का समय लगा; 1,000,000 पर मैंने एक घंटे के बाद हार मान ली। मैंने इसे यहां भावी पीढ़ी के लिए शामिल किया है (प्रकट करने के लिए क्लिक करें)।
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL सर्वर 2005+ 1
यह एक क्रम और प्रति बिक्री व्यक्ति की कुल मात्रा की गणना के लिए दो अलग-अलग विंडोिंग कार्यों का उपयोग करता है।
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; एसक्यूएल सर्वर 2005+ 2
यह ड्वेन कैंप्स के लेख से आया है, जो ऊपर जैसा ही है, थोड़ा और विस्तृत तरीके से करता है। यह मूल रूप से प्रत्येक समूह में दिलचस्प पंक्तियों को हटा देता है।
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; एसक्यूएल सर्वर 2005+ 3
यह मेरी पिछली पोस्ट की टिप्पणियों में एडम मचानिक के एक सुझाव पर आधारित था, और ड्वेन द्वारा उपरोक्त अपने लेख में भी बढ़ाया गया था।
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; एसक्यूएल सर्वर 2005+ 4
यह ऊपर "2005+ 1" के समान है, लेकिन COUNT(*) OVER() का उपयोग करने के बजाय गणनाओं को प्राप्त करने के लिए, यह एक व्युत्पन्न तालिका में एक पृथक समुच्चय के विरुद्ध एक स्व-जुड़ाव करता है।
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL सर्वर 2012+ 1
यह ड्वेन के लेख पर टिप्पणियों में साथी SQL सर्वर MVP पीटर "पेसो" लार्सन (@SwePeso) का एक बहुत ही दिलचस्प योगदान था; यह CROSS APPLY का उपयोग करता है और नया OFFSET / FETCH सरल माध्यिका गणना के लिए इट्ज़िक के समाधान की तुलना में अधिक रोचक और आश्चर्यजनक तरीके से कार्यक्षमता।
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); एसक्यूएल सर्वर 2012+ 2
अंत में, हमारे पास नया PERCENTILE_CONT() है SQL सर्वर 2012 में पेश किया गया फ़ंक्शन।
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; असली टेस्ट
उपरोक्त प्रश्नों के प्रदर्शन का परीक्षण करने के लिए, हम एक और अधिक महत्वपूर्ण तालिका बनाने जा रहे हैं। हमारे पास 100 अद्वितीय सेल्सपर्सन होंगे, जिनमें 10,000 बिक्री राशि के आंकड़े होंगे, कुल 1,000,000 पंक्तियों के लिए। हम ढेर के खिलाफ प्रत्येक क्वेरी को चलाने जा रहे हैं, जैसा कि यह है, (SalesPerson, Amount) पर एक अतिरिक्त गैर-संकुल अनुक्रमणिका के साथ , और एक ही कॉलम पर क्लस्टर इंडेक्स के साथ। यहाँ सेटअप है:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
और यहां उपरोक्त प्रश्नों के परिणाम हैं, ढेर के विरुद्ध, गैर-संकुल अनुक्रमणिका, और संकुल अनुक्रमणिका:
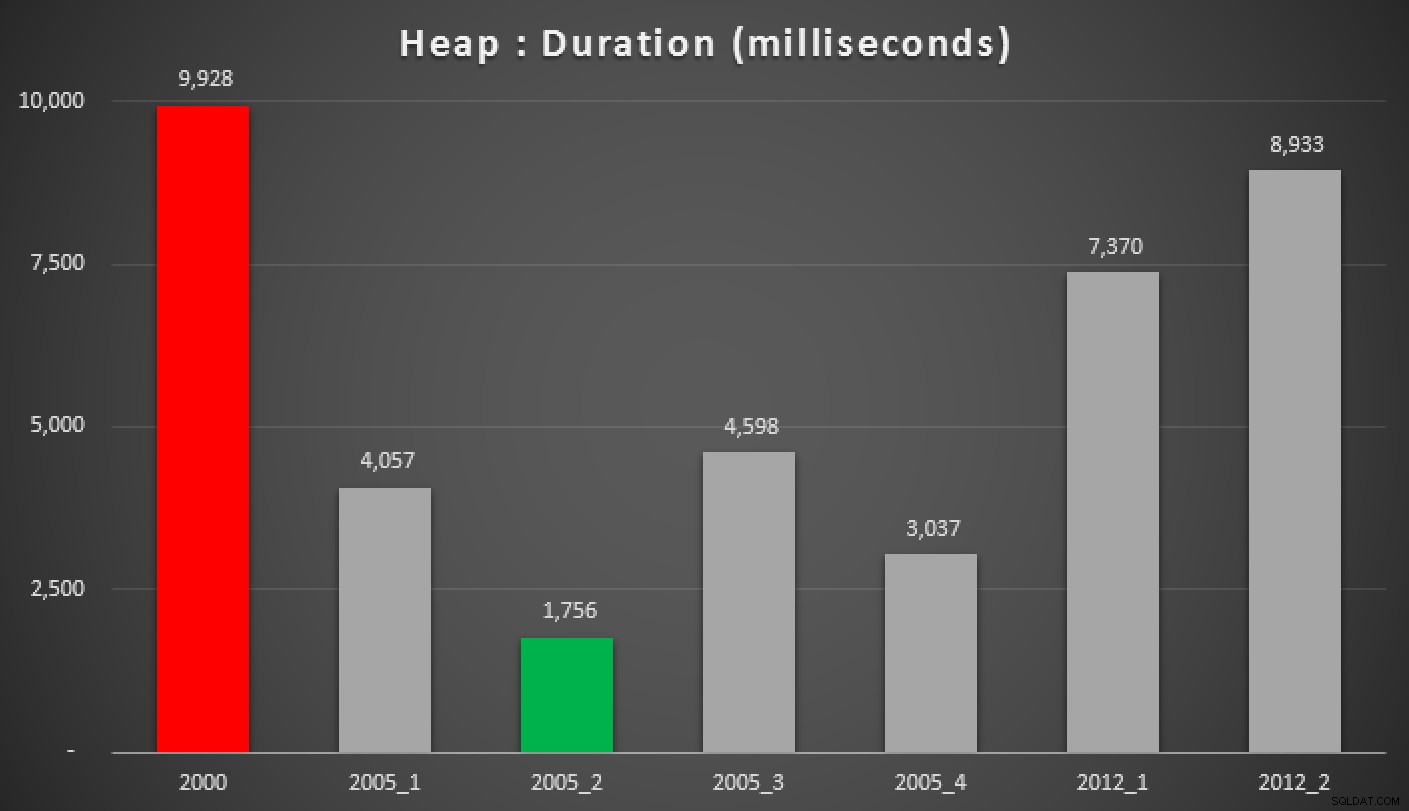
अवधि, मिलीसेकंड में, विभिन्न समूहीकृत माध्यिका दृष्टिकोणों (एक के विरुद्ध) ढेर)
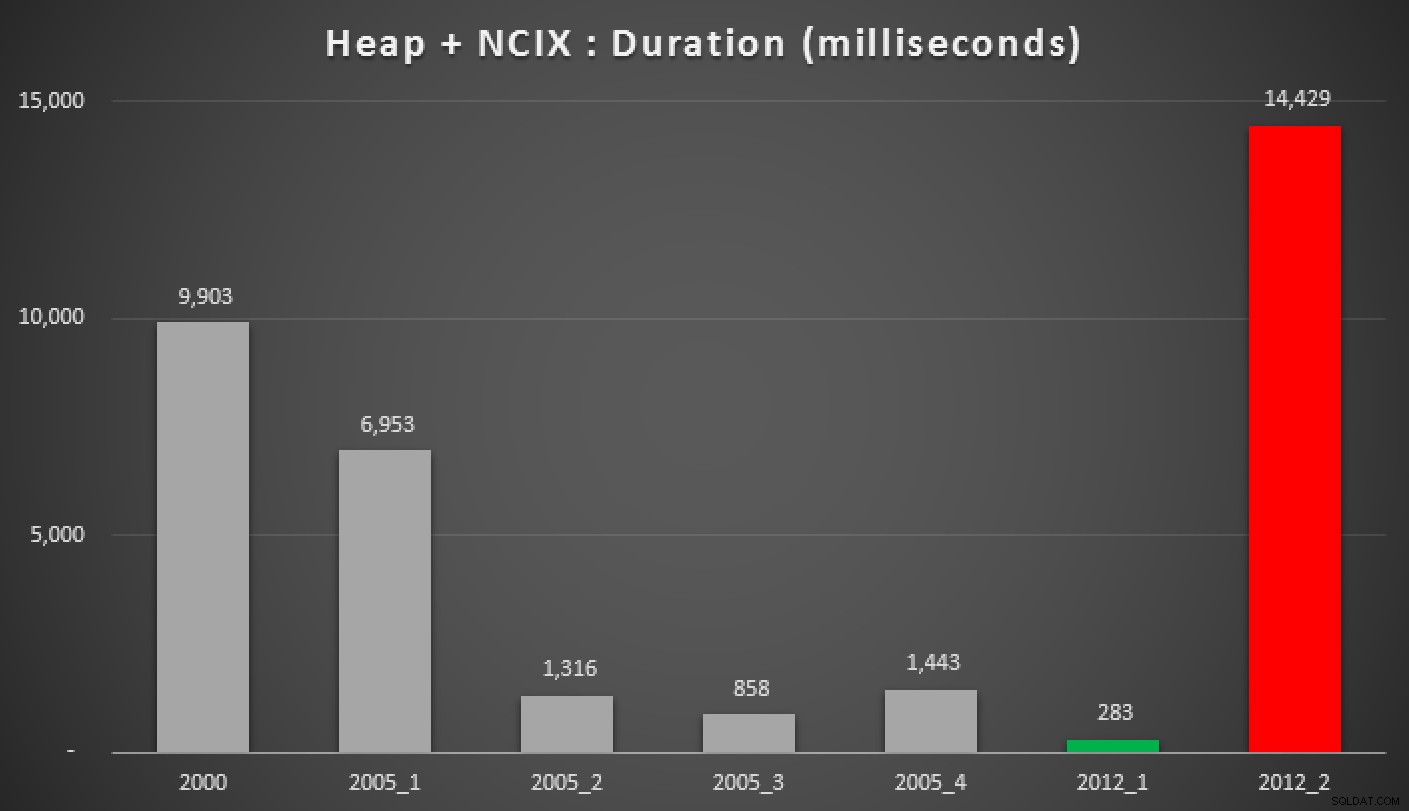
अवधि, मिलीसेकंड में, विभिन्न समूहीकृत माध्यिका दृष्टिकोण (एक के विरुद्ध) एक गैर-संकुल सूचकांक के साथ ढेर)
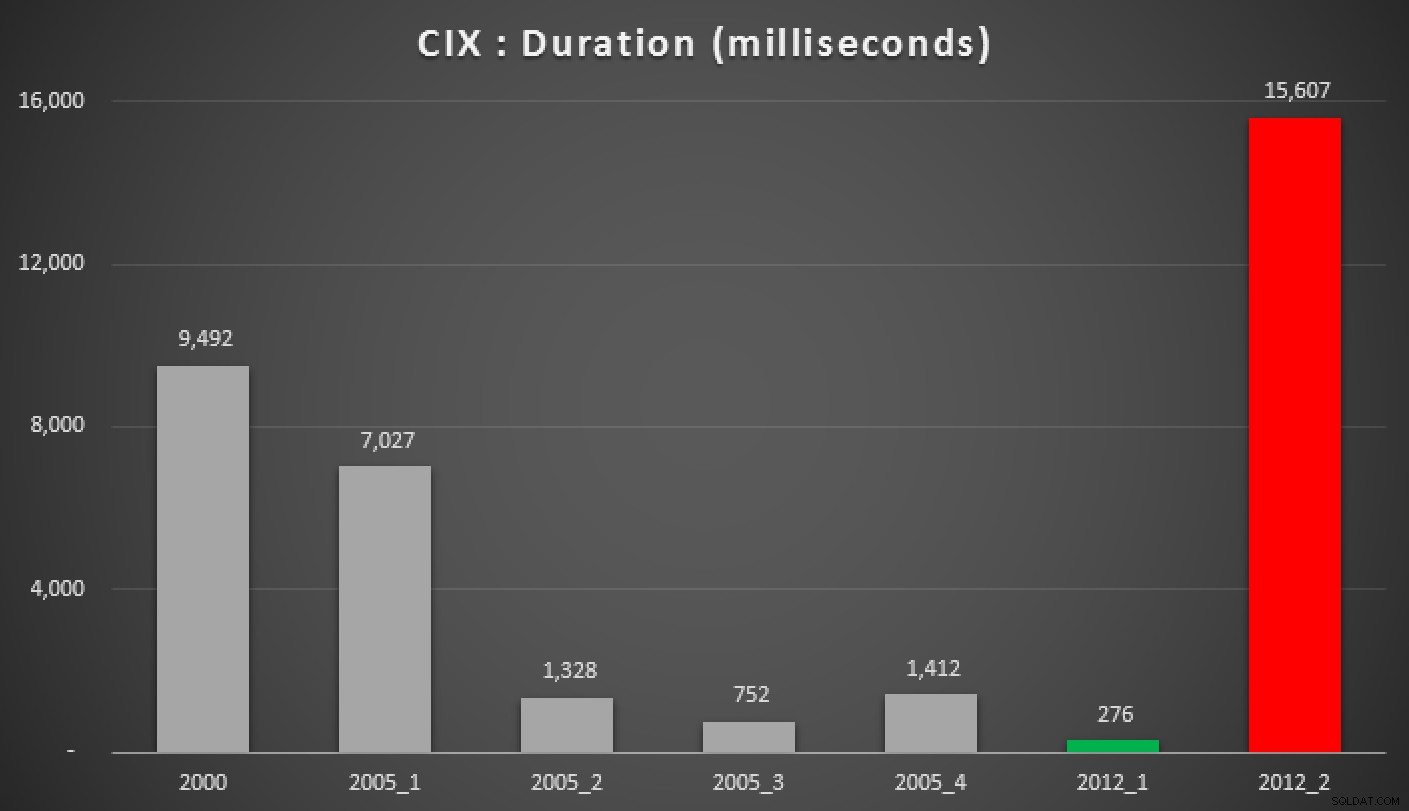
अवधि, मिलीसेकंड में, विभिन्न समूहीकृत माध्यिका दृष्टिकोणों (एक के विरुद्ध) संकुल अनुक्रमणिका)
हेकाटन के बारे में क्या?
स्वाभाविक रूप से, मैं उत्सुक था कि क्या SQL सर्वर 2014 में यह नई सुविधा इनमें से किसी भी प्रश्न के साथ मदद कर सकती है। इसलिए मैंने एक इन-मेमोरी डेटाबेस बनाया, बिक्री तालिका के दो इन-मेमोरी संस्करण (एक हैश इंडेक्स के साथ (SalesPerson, Amount) , और दूसरा केवल (SalesPerson) . पर ), और उन्हीं परीक्षणों को फिर से चलाया:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
परिणाम:
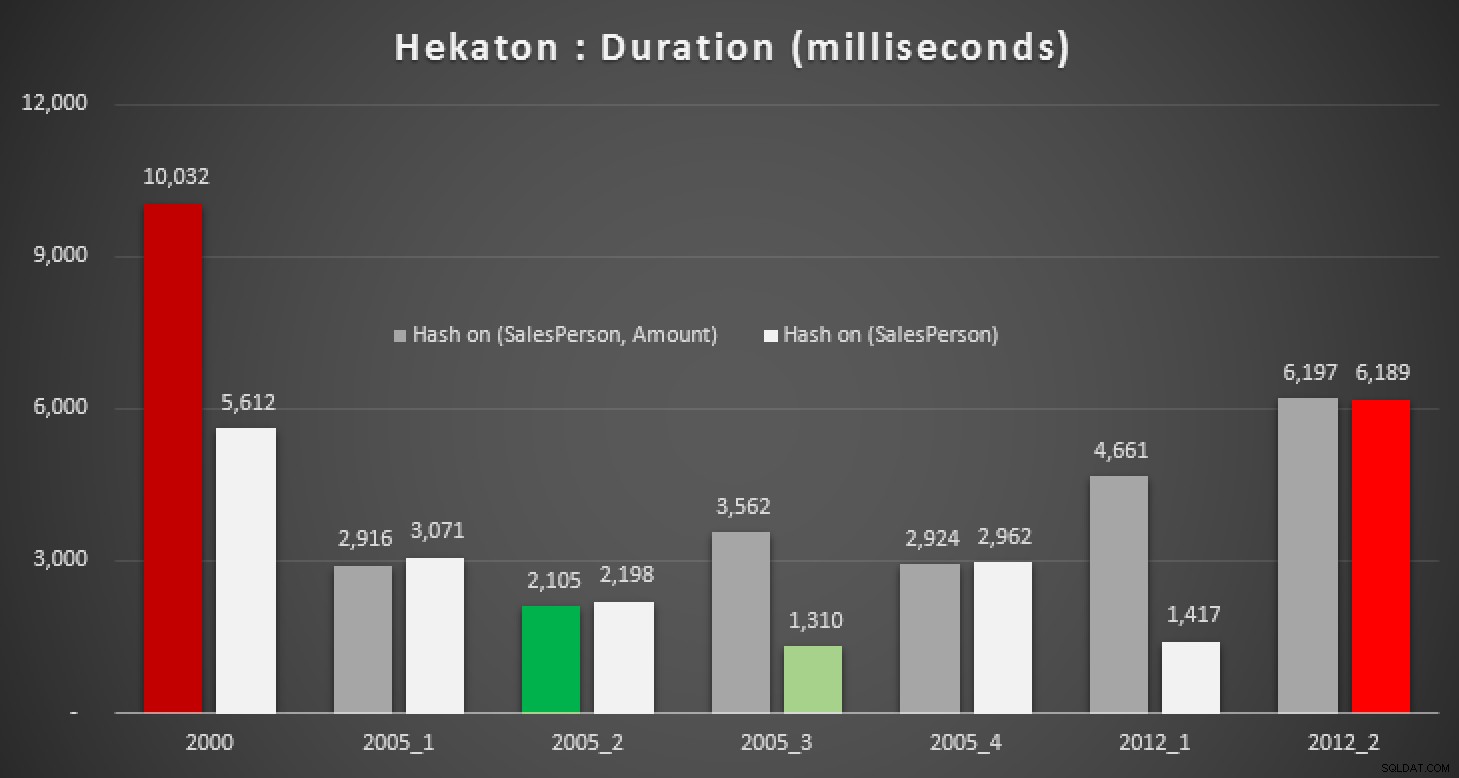
अवधि, मिलीसेकंड में, इन-मेमोरी के विरुद्ध विभिन्न माध्य गणनाओं के लिए टेबल
सही हैश इंडेक्स के साथ भी, हम वास्तव में पारंपरिक तालिका में महत्वपूर्ण सुधार नहीं देखते हैं। इसके अलावा, मूल रूप से संकलित संग्रहीत प्रक्रिया का उपयोग करके औसत समस्या को हल करने का प्रयास करना एक आसान काम नहीं होगा, क्योंकि ऊपर उपयोग की जाने वाली कई भाषा संरचनाएं मान्य नहीं हैं (मैं इनमें से कुछ के बारे में भी हैरान था)। उपरोक्त सभी क्वेरी विविधताओं को संकलित करने का प्रयास करने से त्रुटियों की यह परेड निकली; प्रत्येक प्रक्रिया के भीतर कई बार कुछ हुआ, और डुप्लिकेट को हटाने के बाद भी, यह अभी भी एक प्रकार का हास्यपूर्ण है:
संदेश 10794, स्तर 16, राज्य 47, प्रक्रिया GroupedMedian_2000विकल्प 'DISTINCT' मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 12311, स्तर 16, राज्य 37, प्रक्रिया GroupedMedian_2000
उपश्रेणियाँ ( किसी अन्य क्वेरी के अंदर नेस्टेड क्वेरी) मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 10794, स्तर 16, राज्य 48, प्रक्रिया GroupedMedian_2000
विकल्प 'PERCENT' मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 12311, स्तर 16, राज्य 37, प्रक्रिया GroupedMedian_2005_1
उपश्रेणियाँ (किसी अन्य क्वेरी के अंदर नेस्टेड क्वेरी) मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 10794, स्तर 16, राज्य 91 , प्रक्रिया GroupedMedian_2005_1
समग्र फ़ंक्शन 'ROW_NUMBER' मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 10794, स्तर 16, राज्य 56, प्रक्रिया GroupedMedian_2005_1
ऑपरेटर 'IN' के साथ समर्थित नहीं है स्थानीय रूप से संकलित संग्रहीत कार्यविधियाँ।
संदेश 12310, स्तर 16, राज्य 36, प्रक्रिया GroupedMedian_2005_2
सामान्य तालिका अभिव्यक्तियाँ (CTE) स्थानीय रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 12309, स्तर 16, राज्य 35, प्रक्रिया GroupedMedian_2005_2
फ़ॉर्म के विवरण INSERT…VALUES… जो कई पंक्तियों को सम्मिलित करते हैं, मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 10794, स्तर 16, राज्य 53, प्रक्रिया GroupedMedian_2005_2
संचालक 'APPLY' स्थानीय रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 12311, स्तर 16, राज्य 37, प्रक्रिया GroupedMedian_2005_2
उपश्रेणियां (किसी अन्य क्वेरी के अंदर नेस्टेड क्वेरी) मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 10794, स्तर 16, राज्य 91, प्रक्रिया GroupedMedian_2005_2
समग्र कार्य 'ROW_NUMBER' मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 12310, स्तर 16, राज्य 36, प्रक्रिया GroupedMedian_2005_3
सामान्य तालिका अभिव्यक्तियाँ (CTE) हैं मूल रूप से संकलित संग्रहीत के साथ समर्थित नहीं है प्रक्रियाएँ।
संदेश 12311, स्तर 16, राज्य 37, प्रक्रिया GroupedMedian_2005_3
उपश्रेणियाँ (किसी अन्य क्वेरी के अंदर नेस्टेड क्वेरी) मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 10794, स्तर 16, राज्य 91 , प्रक्रिया GroupedMedian_2005_3
समग्र फ़ंक्शन 'ROW_NUMBER' मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 10794, स्तर 16, राज्य 53, प्रक्रिया GroupedMedian_2005_3
ऑपरेटर 'लागू करें' के साथ समर्थित नहीं है स्थानीय रूप से संकलित संग्रहीत कार्यविधियाँ।
संदेश 12311, स्तर 16, राज्य 37, प्रक्रिया GroupedMedian_2005_4
उपश्रेणियाँ (किसी अन्य क्वेरी के अंदर नेस्टेड क्वेरी) मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 10794, स्तर 16, राज्य 91, प्रक्रिया GroupedMedian_2005_4
समग्र कार्य 'ROW_NUMBER' मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 10794, स्तर 16, राज्य 56, प्रक्रिया GroupedMedian_2005_4
संचालक 'IN' मूल रूप से संकलित स्टोर के साथ समर्थित नहीं है ed प्रक्रियाएँ।
संदेश 12311, स्तर 16, राज्य 37, प्रक्रिया GroupedMedian_2012_1
उपश्रेणियाँ (किसी अन्य क्वेरी के अंदर नेस्टेड क्वेरी) स्थानीय रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 10794, स्तर 16, राज्य 38, प्रक्रिया GroupedMedian_2012_1
ऑपरेटर 'OFFSET' मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 10794, स्तर 16, राज्य 53, प्रक्रिया GroupedMedian_2012_1
ऑपरेटर 'लागू करें' स्थानीय रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
संदेश 12311, स्तर 16, राज्य 37, प्रक्रिया GroupedMedian_2012_2
उपश्रेणियाँ (किसी अन्य क्वेरी के अंदर नेस्टेड क्वेरी) स्थानीय रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं हैं।
संदेश 10794, स्तर 16, राज्य 90, प्रक्रिया GroupedMedian_2012_2
समग्र कार्य 'PERCENTILE_CONT' मूल रूप से संकलित संग्रहीत कार्यविधियों के साथ समर्थित नहीं है।
जैसा कि वर्तमान में लिखा गया है, इनमें से एक भी प्रश्न को मूल रूप से संकलित संग्रहीत कार्यविधि में पोर्ट नहीं किया जा सकता है। शायद किसी अन्य अनुवर्ती पोस्ट को देखने के लिए कुछ।
निष्कर्ष
हेकाटन परिणामों को त्यागना, और जब एक सहायक सूचकांक मौजूद हो, पीटर लार्सन की क्वेरी ("2012+ 1") OFFSET/FETCH का उपयोग कर रही है इन परीक्षणों में दूर-दूर के विजेता के रूप में सामने आया। जबकि गैर-विभाजित परीक्षणों में समकक्ष क्वेरी की तुलना में थोड़ा अधिक जटिल, यह मेरे द्वारा पिछली बार देखे गए परिणामों से मेल खाता था।
उन्हीं मामलों में, 2000 MIN/MAX दृष्टिकोण और 2012 का PERCENTILE_CONT() असली कुत्तों के रूप में बाहर आया; फिर से, सरल मामले के खिलाफ मेरे पिछले परीक्षणों की तरह।
यदि आप अभी तक SQL सर्वर 2012 पर नहीं हैं, तो आपका अगला सबसे अच्छा विकल्प "2005+ 3" (यदि आपके पास एक सहायक अनुक्रमणिका है) या "2005+ 2" है यदि आप एक ढेर के साथ काम कर रहे हैं। क्षमा करें, मुझे इनके लिए एक नई नामकरण योजना के साथ आना पड़ा, ज्यादातर मेरी पिछली पोस्ट में विधियों के साथ भ्रम से बचने के लिए।
बेशक, ये मेरे परिणाम एक बहुत ही विशिष्ट स्कीमा और डेटा सेट के विरुद्ध हैं - जैसा कि सभी अनुशंसाओं के साथ है, आपको अपने स्कीमा और डेटा के विरुद्ध इन दृष्टिकोणों का परीक्षण करना चाहिए, क्योंकि अन्य कारक अलग-अलग परिणामों को प्रभावित कर सकते हैं।
एक अन्य नोट
खराब परफ़ॉर्मर होने के अलावा, और स्थानीय रूप से संकलित संग्रहीत कार्यविधियों में समर्थित नहीं होने के अलावा, PERCENTILE_CONT() का एक और दर्द बिंदु है। यह है कि इसका उपयोग पुराने संगतता मोड में नहीं किया जा सकता है। यदि आप कोशिश करते हैं, तो आपको यह त्रुटि मिलती है:
वर्तमान संगतता मोड में PERCENTILE_CONT फ़ंक्शन की अनुमति नहीं है। यह केवल 110 मोड या उच्चतर में अनुमत है।