प्रमुख जनसंख्या क्वेरी का कुछ और विश्लेषण करना
हमारी ODBC ट्रेसिंग सीरीज़ के भाग 3 में, हम ODBC लिंक्ड टेबल के लिए एक्सेस मैनेजिंग कीज़ के बारे में और अधिक जानकारी लेने जा रहे हैं और यह कैसे SELECT क्वेरीज़ को एक साथ सॉर्ट और ग्रुप करता है। पिछले लेख में हमने सीखा कि कैसे एक डायनेसेट-प्रकार का रिकॉर्डसेट वास्तव में 2 अलग-अलग प्रश्न हैं, जिसमें पहली क्वेरी केवल ODBC लिंक्ड टेबल की कुंजियाँ प्राप्त करती है जो बाद में डेटा को पॉप्युलेट करने के लिए उपयोग की जाती है। इस लेख में, हम इस बारे में थोड़ा और अध्ययन करेंगे कि एक्सेस कैसे कुंजियों का प्रबंधन करता है और यह कैसे अनुमान लगाता है कि ओडीबीसी लिंक्ड टेबल के लिए उपयोग की जाने वाली कुंजी के साथ-साथ इसका क्या प्रभाव पड़ता है। हम छँटाई के साथ शुरू करेंगे।
क्वेरी में एक प्रकार जोड़ना
आपने पिछले लेख में देखा था कि हमने एक साधारण SELECT . के साथ शुरुआत की थी बिना किसी विशेष आदेश के। आपने यह भी देखा कि कैसे एक्सेस ने सबसे पहले CityID प्राप्त किया और पहली क्वेरी के परिणाम का उपयोग करने के बाद बाद के प्रश्नों को पॉप्युलेट करने के लिए एक बड़े रिकॉर्डसेट को खोलते समय उपयोगकर्ता को तेज़ होने की उपस्थिति प्रदान करने के लिए उपयोग करें। यदि आपने कभी ऐसी स्थिति का अनुभव किया है जहां किसी क्वेरी में सॉर्ट या ग्रुपिंग जोड़ना अचानक धीमा हो, तो यह समझाएगा कि क्यों।
आइए StateProvinceID . पर एक प्रकार जोड़ें एक्सेस क्वेरी में:
शहरों का चयन करें।*शहरों से शहरों का आदेश। StateProvinceID;अब अगर हम ODBC SQL को ट्रेस करते हैं, तो हमें आउटपुट देखना चाहिए:
SQLExecDirect:"एप्लिकेशन" चुनें। StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" फ्रॉम "एप्लिकेशन"। शहर" जहां "CityID" =?SQLExecute:(GOTO BOOKMARK) SQLPrepare:"CityID" चुनें, " CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "एप्लिकेशन"। या "सिटीआईडी" =? या "सिटीआईडी" =? या "सिटीआईडी" =? या "सिटीआईडी" =? या "सिटीआईडी" =? या "सिटीआईडी" =? या "सिटीआईडी" =? या "सिटीआईडी" =? या "CityID" =?SQLExecute:(मल्टी-रो फ़ेच)SQLExecute:(मल्टी-रो फ़ेच)यदि आप पिछले लेख के ट्रेस से तुलना करते हैं, तो आप देख सकते हैं कि वे पहली क्वेरी को छोड़कर समान हैं। एक्सेस सॉर्टिंग को पहली क्वेरी में रखता है जहां यह चाबियाँ प्राप्त करने के लिए उपयोग करता है। यह समझ में आता है कि रिकॉर्ड्स के माध्यम से चलने के लिए उपयोग की जाने वाली चाबियों पर सॉर्टिंग को लागू करने से, रिकॉर्ड की क्रमिक स्थिति और इसे कैसे सॉर्ट किया जाना चाहिए, के बीच एक से एक पत्राचार होने की गारंटी है। इसके बाद यह ठीक उसी तरह रिकॉर्ड्स को पॉप्युलेट करता है। केवल अंतर कुंजी के क्रम का है जो अन्य प्रश्नों को भरने के लिए उपयोग करता है।
आइए विचार करें कि जब हम GROUP BY जोड़ते हैं तो क्या होता है प्रति राज्य शहरों की गिनती करके:
Cities.StateProvinceID ,Count(Cities.CityID) CountOfCityIDFROM Cities by Cities.StateProvinceID;ट्रेसिंग आउटपुट होना चाहिए:
SQLExecDirect:"एप्लिकेशन" से "StateProvinceID", COUNT("CityID") चुनें। आपने यह भी देखा होगा कि क्वेरी अब धीरे-धीरे खुलती है, और भले ही इसे डायनासेट प्रकार के रिकॉर्डसेट के रूप में सेट किया जा सकता है, एक्सेस ने इसे अनदेखा करना चुना और मूल रूप से इसे स्नैपशॉट प्रकार के रिकॉर्डसेट के रूप में माना। यह समझ में आता है क्योंकि क्वेरी गैर-अपडेट करने योग्य है और क्योंकि आप वास्तव में इस तरह की क्वेरी में मनमानी स्थिति में नेविगेट नहीं कर सकते हैं। इस प्रकार, आपको तब तक प्रतीक्षा करनी चाहिए जब तक कि आप स्वतंत्र रूप से ब्राउज़ करने से पहले सभी पंक्तियों को प्राप्त नहीं कर लेते। StateProvinceID रिकॉर्ड का पता लगाने के लिए इस्तेमाल नहीं किया जा सकता क्योंकि Cities . में कई रिकॉर्ड होंगे टेबल। हालांकि मैंने GROUP BY . का उपयोग किया है इस उदाहरण में, यह एक समूह नहीं होना चाहिए जो एक्सेस को स्नैपशॉट प्रकार के रिकॉर्डसेट का उपयोग करने का कारण बनता है। DISTINCT . का उपयोग करना उदाहरण के लिए एक ही प्रभाव होगा। यह अनुमान लगाने का एक उपयोगी नियम है कि एक्सेस डायनासेट-प्रकार के रिकॉर्डसेट का उपयोग करेगा या नहीं, यह पूछना है कि क्या परिणामी रिकॉर्डसेट में दी गई पंक्ति ओडीबीसी डेटा स्रोत में ठीक एक पंक्ति में वापस आती है। यदि ऐसा नहीं है, तो एक्सेस स्नैपशॉट व्यवहार का उपयोग करेगा, भले ही क्वेरी को डायनासेट का उपयोग करना चाहिए था।
नतीजतन, सिर्फ इसलिए कि डिफ़ॉल्ट एक डायनासेट-प्रकार का रिकॉर्डसेट है, यह गारंटी नहीं देता है कि यह वास्तव में एक डायनासेट-प्रकार का रिकॉर्डसेट होगा। यह केवल एक अनुरोध है , मांग नहीं।
चुनने के लिए उपयोग की जाने वाली कुंजी का निर्धारण
आपने इस और पिछले दोनों लेखों में पिछले ट्रेस किए गए SQL में देखा होगा, एक्सेस ने CityID का उपयोग किया था कुंजी के रूप में। वह कॉलम पहली क्वेरी में लाया गया था, फिर बाद में तैयार किए गए प्रश्नों में उपयोग किया गया था। लेकिन एक्सेस कैसे जानता है कि लिंक की गई तालिका के किस कॉलम का उपयोग करना चाहिए? पहला झुकाव यह कहना होगा कि यह प्राथमिक कुंजी की जांच करता है और इसका उपयोग करता है। हालांकि, यह गलत होगा। वास्तव में, एक्सेस डेटाबेस इंजन ODBC के SQLStatistics . का उपयोग करेगा कौन से सूचकांक उपलब्ध हैं, इसकी जांच करने के लिए तालिका को जोड़ने या फिर से जोड़ने के दौरान कार्य करें। यह फ़ंक्शन सभी इंडेक्स के लिए इंडेक्स में भाग लेने वाले प्रत्येक कॉलम के लिए एक पंक्ति के साथ एक परिणामसेट लौटाएगा। यह परिणामसेट हमेशा सॉर्ट किया जाता है और परंपरा के अनुसार, यह हमेशा क्लस्टर्ड इंडेक्स, हैशेड इंडेक्स और फिर अन्य इंडेक्स प्रकारों को सॉर्ट करेगा। प्रत्येक सूचकांक प्रकार के भीतर, सूचकांकों को उनके नाम के अनुसार वर्णानुक्रम में क्रमबद्ध किया जाएगा। एक्सेस डेटाबेस इंजन पहली अनूठी अनुक्रमणिका का चयन करेगा, भले ही वह वास्तविक प्राथमिक कुंजी न हो। इसे साबित करने के लिए, हम कुछ विषम सूचकांकों के साथ एक मूर्खतापूर्ण तालिका बनाएंगे:
क्रिएट टेबल dbo.SillyTable (आईडी int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255));
यदि हम तालिका को कुछ डेटा के साथ पॉप्युलेट करते हैं और इसे एक्सेस में लिंक करते हैं और लिंक की गई तालिका पर डेटाशीट दृश्य खोलते हैं, तो हम इसे ट्रेस किए गए ओडीबीसी एसक्यूएल में देखेंगे। संक्षिप्तता के लिए, केवल पहले 2 आदेश शामिल हैं। SQLExecDirect:"dbo" चुनें। "=?
क्योंकि OtherStuff एक संकुल सूचकांक में भाग लेता है, यह वास्तविक प्राथमिक कुंजी से पहले आया था और इस प्रकार एक्सेस डेटाबेस इंजन द्वारा एक व्यक्तिगत पंक्ति का चयन करने के लिए डायनासेट-प्रकार के रिकॉर्डसेट में उपयोग करने के लिए चुना गया था। यह इस तथ्य के बावजूद भी है कि अद्वितीय क्लस्टर इंडेक्स का नाम प्राथमिक इंडेक्स के नाम के बाद आया होगा। किसी तालिका के लिए किसी विशेष इंडेक्स का चयन करने के लिए एक्सेस डेटाबेस इंजन को मजबूर करने की एक रणनीति इसके प्रकार को बदलना या नाम का नाम बदलना होगा ताकि यह इंडेक्स प्रकार के समूह के भीतर वर्णानुक्रम में क्रमबद्ध हो। SQL सर्वर के मामले में, प्राथमिक कुंजी आमतौर पर क्लस्टर की जाती है, और केवल एक क्लस्टर इंडेक्स हो सकता है, इसलिए यह एक सुखद दुर्घटना है कि यह आमतौर पर एक्सेस डेटाबेस इंजन के उपयोग के लिए सही इंडेक्स है। हालाँकि, यदि SQL सर्वर डेटाबेस में गैर-संकुल प्राथमिक कुंजियों वाली तालिकाएँ हैं और एक क्लस्टर अद्वितीय अनुक्रमणिका है जो इष्टतम विकल्प नहीं हो सकता है। उन मामलों में जहां कोई क्लस्टर इंडेक्स नहीं हैं, आप इंडेक्स का नामकरण करके प्रभावित कर सकते हैं कि कौन से अद्वितीय इंडेक्स का उपयोग किया जाता है ताकि यह अन्य इंडेक्स से पहले सॉर्ट हो सके। यह अन्य RDBMS सॉफ़्टवेयर के साथ सहायक हो सकता है जहाँ प्राथमिक कुंजी के लिए क्लस्टर इंडेक्स बनाना व्यावहारिक या संभव नहीं है। लिंक किए गए SQL व्यू या बिना इंडेक्स वाली टेबल के लिए एक्सेस-साइड इंडेक्स
किसी SQL दृश्य या SQL तालिका से लिंक करते समय जिसमें कोई सूचकांक या प्राथमिक कुंजी परिभाषित नहीं है, एक्सेस डेटाबेस इंजन के उपयोग के लिए कोई सूचकांक उपलब्ध नहीं होगा। यदि आपने लिंक किए गए तालिका प्रबंधक का उपयोग किसी तालिका या SQL दृश्य को बिना किसी सूचकांक के लिंक करने के लिए किया है, तो हो सकता है कि आपने इस तरह का एक संवाद देखा हो:
 अगर हम
अगर हम ID चुनते हैं , लिंकिंग को पूरा करें, लिंक्ड टेबल को डिज़ाइन व्यू में खोलें, और फिर इंडेक्स डायलॉग, हमें यह देखना चाहिए:
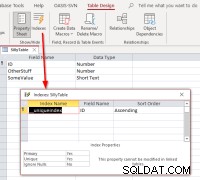 यह दर्शाता है कि तालिका में
यह दर्शाता है कि तालिका में __uniqueindex नामक एक अनुक्रमणिका है लेकिन यह मूल डेटा स्रोत में मौजूद नहीं है। क्या चल रहा है? इसका उत्तर यह है कि एक्सेस ने एक पहुंच-पक्ष बनाया है इसके उपयोग के लिए सूचकांक यह पहचानने में मदद करता है कि ऐसी तालिकाओं या दृश्यों के लिए रिकॉर्ड पहचानकर्ता के रूप में उपयोग किया जा सकता है। यदि आप लिंक्ड टेबल मैनेजर का उपयोग करने के बजाय तालिकाओं को प्रोग्रामेटिक रूप से रीलिंक करते हैं, तो आपको ऐसी लिंक की गई तालिकाओं को अद्यतन करने योग्य बनाने के लिए व्यवहार को दोहराने की आवश्यकता होगी। यह एक्सेस SQL कमांड को निष्पादित करके किया जा सकता है:
अद्वितीय अनुक्रमणिका बनाएं [__uniqueindex] SillyTable (ID) पर;
उदाहरण के लिए आप उपयोग कर सकते हैं, CurrentDb.Execute लिंक किए गए टेबल पर इंडेक्स बनाने के लिए एक्सेस एसक्यूएल को निष्पादित करने के लिए। हालांकि, आपको इसे पास-थ्रू क्वेरी के रूप में निष्पादित नहीं करना चाहिए क्योंकि इंडेक्स वास्तव में सर्वर पर नहीं बनाया गया है। उस लिंक की गई तालिका पर अपडेट करने की अनुमति देना केवल एक्सेस के लाभों के लिए है।
यह ध्यान देने योग्य है कि एक्सेस ऐसी लिंक की गई तालिका के लिए केवल एक इंडेक्स की अनुमति देगा और केवल तभी जब उसके पास पहले से इंडेक्स न हों। फिर भी, आप देख सकते हैं कि SQL दृश्य का उपयोग करना उन मामलों के लिए एक वांछनीय विकल्प हो सकता है जहां डेटाबेस डिज़ाइन आपको क्लस्टर इंडेक्स का उपयोग करने की अनुमति नहीं देता है और आप इस इंडेक्स का उपयोग करने के लिए एक्सेस डेटाबेस इंजन को मनाने के लिए इंडेक्स के नाम के साथ खिलवाड़ नहीं करना चाहते हैं, वह सूचकांक नहीं। SQL व्यू को लिंक करते समय आप इंडेक्स और कॉलम को स्पष्ट रूप से नियंत्रित कर सकते हैं।
निष्कर्ष
पिछले लेख से हमने देखा कि एक डायनासेट-प्रकार का रिकॉर्डसेट आमतौर पर 2 प्रश्न जारी करता है। पहली क्वेरी आम तौर पर पॉप्युलेट करने से संबंधित होती है हमने अधिक बारीकी से देखा कि कैसे एक्सेस कुंजी की आबादी को संभालती है जो इसे डायनासेट-प्रकार के रिकॉर्डसेट के लिए उपयोग करेगी। हमने देखा कि एक्सेस वास्तव में मूल एक्सेस क्वेरी से किसी भी सॉर्टिंग को कैसे परिवर्तित करेगा और फिर इसे प्रमुख जनसंख्या क्वेरी में उपयोग करेगा। हमने देखा कि प्रमुख जनसंख्या क्वेरी का क्रम सीधे तौर पर प्रभावित करता है कि कैसे रिकॉर्डसेट में डेटा को सॉर्ट किया जाएगा और उपयोगकर्ता को प्रस्तुत किया जाएगा। यह उपयोगकर्ता को सूची की क्रमसूचक स्थिति के आधार पर एक अनियंत्रित रिकॉर्ड में कूदने जैसी चीजें करने में सक्षम बनाता है।
फिर हमने देखा कि ग्रुपिंग और अन्य एसक्यूएल ऑपरेशन जो लौटाई गई पंक्ति और मूल पंक्ति के बीच एक-एक मैपिंग को रोकता है, एक्सेस क्वेरी को एक्सेस क्वेरी का इलाज करने का कारण बनता है जैसे कि डायनासेट-प्रकार रिकॉर्डसेट का अनुरोध करने के बावजूद यह स्नैपशॉट-प्रकार रिकॉर्डसेट था।
फिर हमने देखा कि कैसे एक्सेस एक ओडीबीसी लिंक्ड टेबल के साथ अपडेट के प्रबंधन के लिए उपयोग की जाने वाली कुंजी को निर्धारित करता है। हम जो उम्मीद कर सकते हैं, उसके विपरीत, यह आवश्यक रूप से तालिका की प्राथमिक कुंजी का चयन नहीं करेगा, बल्कि सूचकांक के प्रकार और सूचकांक के नाम के आधार पर पहली अनूठी अनुक्रमणिका का चयन करेगा। हमने यह सुनिश्चित करने के लिए रणनीतियों पर चर्चा की कि एक्सेस सही अद्वितीय इंडेक्स का चयन करेगा। हमने एसक्यूएल व्यू को देखा, जिसमें आम तौर पर कोई इंडेक्स नहीं होता है और एक्सेस को सूचित करने के लिए एक विधि पर चर्चा की कि कैसे एक एसक्यूएल व्यू या एक टेबल की कुंजी है जिसमें कोई प्राथमिक कुंजी नहीं है, जिससे हमें इस पर अधिक नियंत्रण की अनुमति मिलती है कि एक्सेस कैसे अपडेट को संभालेगा वे ODBC लिंक्ड टेबल।
अगले लेख में हम देखेंगे कि जब उपयोगकर्ता एक्सेस क्वेरी या रिकॉर्डसोर्स के माध्यम से परिवर्तन करते हैं तो एक्सेस वास्तव में डेटा पर अपडेट कैसे निष्पादित करता है।
हमारे एक्सेस विशेषज्ञ मदद के लिए उपलब्ध हैं। हमें 773-809-5456 पर कॉल करें या हमें sales@itimpact.com पर ईमेल करें।