अतिथि लेखक:मोनिका रथबुन (@SQLEspresso)
कभी-कभी हार्डवेयर प्रदर्शन संबंधी समस्याएं, जैसे डिस्क I/O विलंबता, खराब प्रदर्शन करने वाले हार्डवेयर के बजाय गैर-अनुकूलित कार्यभार के लिए उबलती हैं। कई डेटाबेस एडमिन, जिनमें मैं शामिल था, धीमेपन के लिए तुरंत स्टोरेज को दोष देना चाहते हैं। इससे पहले कि आप जाएं और नए हार्डवेयर पर एक टन पैसा खर्च करें, आपको हमेशा अनावश्यक I/O के लिए अपने कार्यभार की जांच करनी चाहिए।
जांच की जाने वाली चीजें
| आइटम | I/O प्रभाव | संभावित समाधान |
|---|---|---|
| अप्रयुक्त अनुक्रमणिका | अतिरिक्त लेखन | अनुक्रमणिका निकालें / अक्षम करें |
| अनुपलब्ध अनुक्रमणिका | अतिरिक्त पढ़ता है | अनुक्रमणिका / कवरिंग अनुक्रमणिका जोड़ें |
| निहित रूपांतरण | अतिरिक्त पढ़ना और लिखना | मूल्य का मूल्यांकन करने से पहले स्रोत पर गुप्त या कास्ट फ़ील्ड |
| कार्य | अतिरिक्त पढ़ना और लिखना | उन्हें हटा दिया, मूल्यांकन से पहले डेटा परिवर्तित करें |
| ETL | अतिरिक्त पढ़ना और लिखना | SSIS, प्रतिकृति, परिवर्तन डेटा कैप्चर, उपलब्धता समूहों का उपयोग करें |
| आदेश और समूह अनुसार | अतिरिक्त पढ़ना और लिखना | जहां संभव हो उन्हें हटा दें |
अप्रयुक्त अनुक्रमणिका
हम सभी एक सूचकांक की शक्ति को जानते हैं। उचित अनुक्रमणिका होने से क्वेरी गति में अंतर का प्रकाश वर्ष हो सकता है। हालांकि, हममें से कितने लोग लगातार अपने इंडेक्स को इंडेक्स के पुनर्निर्माण और पुनर्गठन से ऊपर और परे बनाए रखते हैं? वास्तव में किस इंडेक्स का उपयोग किया जा रहा है, इसका मूल्यांकन करने के लिए एक इंडेक्स स्क्रिप्ट को नियमित रूप से चलाना महत्वपूर्ण है। ऐसा करने के लिए मैं व्यक्तिगत रूप से ग्लेन बेरी के नैदानिक प्रश्नों का उपयोग करता हूं।
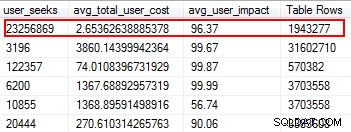
आपको यह जानकर आश्चर्य होगा कि आपकी कुछ अनुक्रमणिकाएँ बिल्कुल भी नहीं पढ़ी गई हैं। ये अनुक्रमणिका संसाधनों पर दबाव हैं, विशेष रूप से अत्यधिक लेन-देन तालिका पर। परिणामों को देखते समय, उन इंडेक्स पर ध्यान दें जिनमें कम संख्या में पढ़ने के साथ संयुक्त संख्या में लिखने की संख्या अधिक होती है। इस उदाहरण में, आप देख सकते हैं कि मैं लेखन को बर्बाद कर रहा हूँ। गैर-संकुल सूचकांक 11 मिलियन बार लिखा गया है, लेकिन केवल दो बार पढ़ा गया है।

मैं इस श्रेणी में आने वाले इंडेक्स को अक्षम करके शुरू करता हूं, और फिर उन्हें छोड़ देता हूं जब मैंने पुष्टि की है कि कोई समस्या उत्पन्न नहीं हुई है। इस अभ्यास को नियमित रूप से करने से आपके सिस्टम में अनावश्यक I/O लिखने में काफी कमी आ सकती है, लेकिन ध्यान रखें कि आपके इंडेक्स पर उपयोग के आंकड़े केवल पिछले रीबूट के समान ही अच्छे हैं, इसलिए सुनिश्चित करें कि आप लिखने से पहले एक पूर्ण व्यावसायिक चक्र के लिए डेटा एकत्र कर रहे हैं। "बेकार" के रूप में एक सूचकांक।
अनुक्रमणिका अनुपलब्ध
गुम इंडेक्स ठीक करने की सबसे आसान चीजों में से एक है; आखिरकार, जब आप एक निष्पादन योजना चलाते हैं, तो यह आपको बताएगा कि क्या कोई अनुक्रमणिका नहीं मिली थी, लेकिन यह उपयोगी होता। लेकिन रुकिए, मुझे आशा है कि आप इस सुझाव के आधार पर केवल मनमाने ढंग से अनुक्रमणिका नहीं जोड़ रहे हैं। ऐसा करने से डुप्लिकेट इंडेक्स और इंडेक्स बन सकते हैं जिनका कम से कम उपयोग हो सकता है, और इसलिए I/O बर्बाद हो जाता है। फिर से, ग्लेन की लिपियों पर वापस, वह हमें उपयोगकर्ता की तलाश, उपयोगकर्ता प्रभाव और पंक्तियों की संख्या प्रदान करके एक सूचकांक की उपयोगिता का मूल्यांकन करने के लिए एक महान उपकरण देता है। कम लागत और प्रभाव के साथ उच्च पढ़ने वालों पर ध्यान दें। यह शुरू करने के लिए एक बढ़िया जगह है, और आपको पढ़ने के I/O को कम करने में मदद करेगा।
अंतर्निहित रूपांतरण
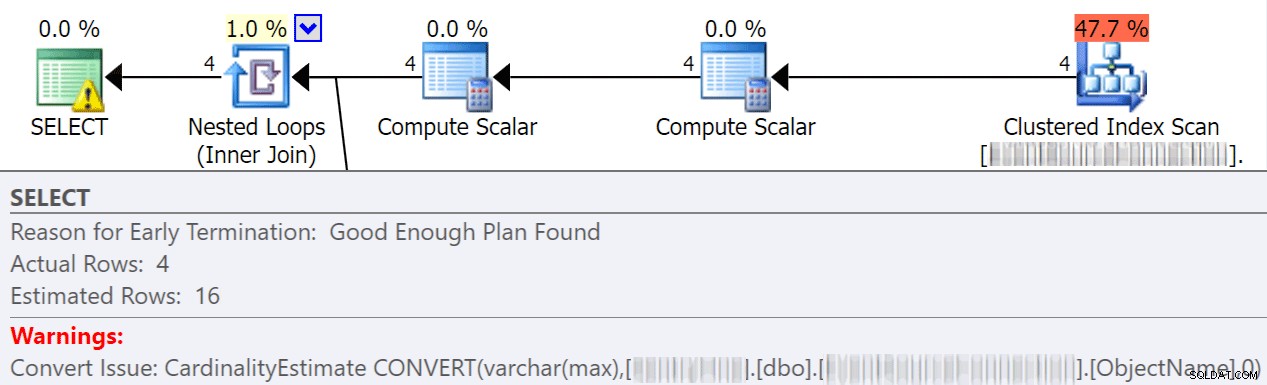
निहित रूपांतरण अक्सर तब होते हैं जब कोई क्वेरी विभिन्न डेटा प्रकारों के साथ दो या दो से अधिक स्तंभों की तुलना कर रही होती है। नीचे दिए गए उदाहरण में, सिस्टम को एक वर्चर (अधिकतम) कॉलम की तुलना nvarchar(4000) कॉलम से करने के लिए अतिरिक्त I/O प्रदर्शन करना पड़ रहा है, जो एक अंतर्निहित रूपांतरण की ओर जाता है, और अंततः एक खोज के बजाय एक स्कैन करता है। मेल खाने वाले डेटा प्रकारों के लिए तालिकाओं को ठीक करके, या मूल्यांकन से पहले बस इस मान को परिवर्तित करके, आप I/O को बहुत कम कर सकते हैं और कार्डिनैलिटी में सुधार कर सकते हैं (अनुमानित पंक्तियाँ जो अनुकूलक को अपेक्षित होनी चाहिए)।
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
जोनाथन केहैयस इस महान पोस्ट में बहुत अधिक विस्तार में जाते हैं:"कॉलम-साइड इंप्लिक्ट रूपांतरण कितने महंगे हैं?"
कार्य
सबसे अधिक परिहार्य, आसान-से-ठीक करने वाली चीजों में से एक जो मैंने आई / ओ खर्च पर बचाई है, वह उन कार्यों को हटा रहा है जहां से क्लॉज हैं। एक आदर्श उदाहरण दिनांक तुलना है, जैसा कि नीचे दिखाया गया है।
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
चाहे वह जॉइन स्टेटमेंट पर हो या WHERE क्लॉज में यह मूल्यांकन से पहले प्रत्येक कॉलम को परिवर्तित करने का कारण बनता है। मूल्यांकन से पहले इन स्तंभों को केवल एक अस्थायी तालिका में परिवर्तित करके आप एक टन अनावश्यक I/O को समाप्त कर सकते हैं।
या, और भी बेहतर, कोई भी रूपांतरण बिल्कुल न करें (इस विशिष्ट मामले के लिए, हारून बर्ट्रेंड यहां जहां क्लॉज में कार्यों से बचने के बारे में बात करता है, और ध्यान दें कि यह अभी भी खराब हो सकता है, भले ही तिथि में कनवर्ट करने योग्य है)।
ETL
यह जांचने के लिए समय निकालें कि आपका डेटा कैसे लोड किया जा रहा है। क्या आप टेबल को छोटा और पुनः लोड कर रहे हैं? क्या आप प्रतिकृति, केवल पढ़ने के लिए एजी प्रतिकृति, या इसके बजाय लॉग शिपिंग लागू कर सकते हैं? क्या सभी टेबल वास्तव में पढ़ने के लिए लिखे जा रहे हैं? आप डेटा कैसे लोड कर रहे हैं? क्या यह संग्रहीत प्रक्रियाओं या एसएसआईएस के माध्यम से है? इस तरह की चीजों की जांच करने से I/O नाटकीय रूप से कम हो सकता है।
अपने परिवेश में, मैंने पाया कि हम प्रतिदिन 48 टेबलों को काट रहे थे, प्रत्येक सुबह 120 मिलियन से अधिक पंक्तियों के साथ। उसके ऊपर हम प्रति घंटा 9.6 मिलियन पंक्तियों को लोड कर रहे थे। आप कल्पना कर सकते हैं कि इसने कितना अनावश्यक I/O बनाया। मेरे मामले में, लेन-देन की प्रतिकृति को लागू करना मेरी पसंद का समाधान था। एक बार लागू होने के बाद हमारे पास हमारे लोड समय के दौरान मंदी की बहुत कम उपयोगकर्ता शिकायतें थीं, जिन्हें शुरू में धीमी भंडारण के लिए जिम्मेदार ठहराया गया था।
आदेश द्वारा और समूह द्वारा
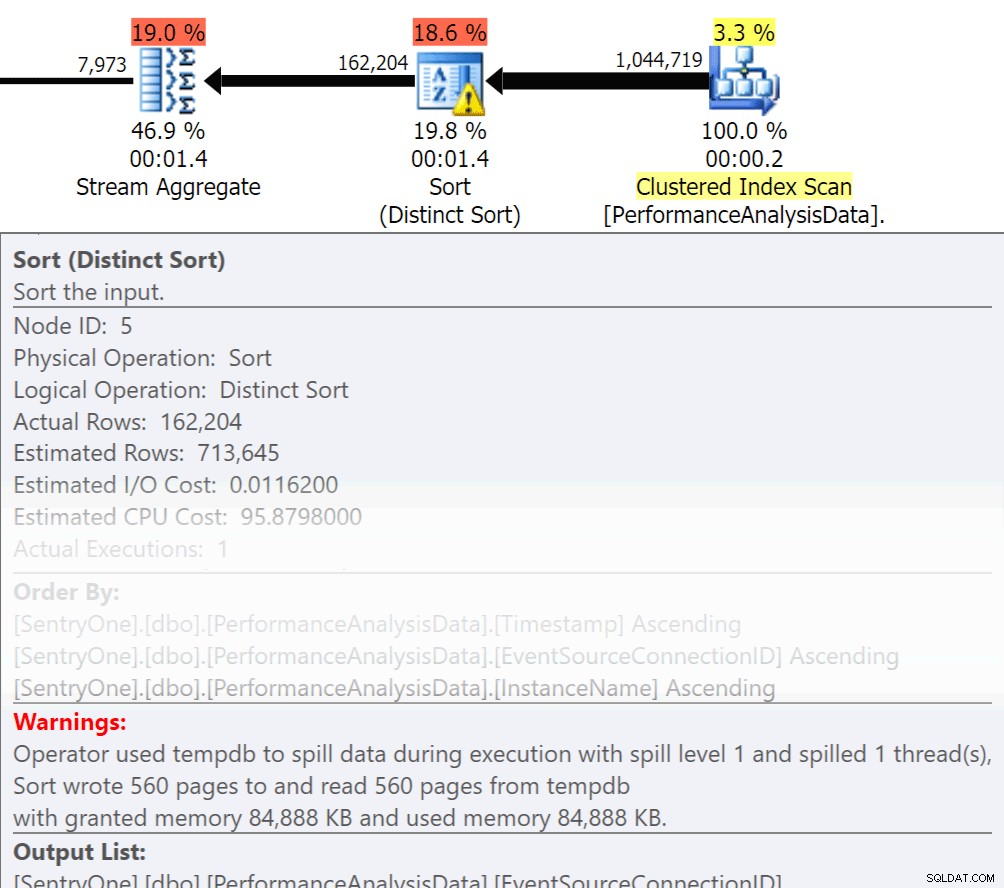 अपने आप से पूछें, क्या उस डेटा को क्रम में वापस करना है? क्या हमें वास्तव में प्रक्रिया में समूह बनाने की ज़रूरत है, या क्या हम इसे किसी रिपोर्ट या आवेदन में संभाल सकते हैं? ऑर्डर बाय और ग्रुप बाय ऑपरेशंस रीड को डिस्क पर फैलाने का कारण बन सकता है, जो अतिरिक्त डिस्क I/O का कारण बनता है। यदि इन कार्यों की आवश्यकता है, तो सुनिश्चित करें कि आपके पास क्रमबद्ध या समूहीकृत किए जा रहे स्तंभों पर सहायक अनुक्रमणिकाएँ और ताज़ा आँकड़े हैं। यह योजना निर्माण के दौरान अनुकूलक की मदद करेगा। चूंकि हम कभी-कभी अस्थायी तालिकाओं में ऑर्डर बाय और ग्रुप बाय का उपयोग करते हैं। सुनिश्चित करें कि आपके पास TEMPDB के साथ-साथ आपके उपयोगकर्ता डेटाबेस के लिए ऑटो क्रिएट स्टैटिस्टिक्स ऑन है। आंकड़े जितने अधिक अद्यतित होंगे, अनुकूलक को उतनी ही बेहतर कार्डिनैलिटी मिल सकती है, जिसके परिणामस्वरूप बेहतर योजनाएं, कम स्पिल ओवर, और कम I/O हो सकता है।
अपने आप से पूछें, क्या उस डेटा को क्रम में वापस करना है? क्या हमें वास्तव में प्रक्रिया में समूह बनाने की ज़रूरत है, या क्या हम इसे किसी रिपोर्ट या आवेदन में संभाल सकते हैं? ऑर्डर बाय और ग्रुप बाय ऑपरेशंस रीड को डिस्क पर फैलाने का कारण बन सकता है, जो अतिरिक्त डिस्क I/O का कारण बनता है। यदि इन कार्यों की आवश्यकता है, तो सुनिश्चित करें कि आपके पास क्रमबद्ध या समूहीकृत किए जा रहे स्तंभों पर सहायक अनुक्रमणिकाएँ और ताज़ा आँकड़े हैं। यह योजना निर्माण के दौरान अनुकूलक की मदद करेगा। चूंकि हम कभी-कभी अस्थायी तालिकाओं में ऑर्डर बाय और ग्रुप बाय का उपयोग करते हैं। सुनिश्चित करें कि आपके पास TEMPDB के साथ-साथ आपके उपयोगकर्ता डेटाबेस के लिए ऑटो क्रिएट स्टैटिस्टिक्स ऑन है। आंकड़े जितने अधिक अद्यतित होंगे, अनुकूलक को उतनी ही बेहतर कार्डिनैलिटी मिल सकती है, जिसके परिणामस्वरूप बेहतर योजनाएं, कम स्पिल ओवर, और कम I/O हो सकता है।
अब समूह द्वारा निश्चित रूप से अपनी जगह है जब एक टन पंक्तियों को वापस करने के बजाय डेटा एकत्र करने की बात आती है। लेकिन यहाँ कुंजी I/O को कम करना है, एकत्रीकरण का जोड़ I/O में जुड़ जाता है।
सारांश
ये केवल टिप-ऑफ-द-हिमशैल प्रकार की चीजें हैं, लेकिन I/O को कम करने के लिए शुरू करने के लिए एक शानदार जगह है। इससे पहले कि आप अपने विलंबता के मुद्दों पर हार्डवेयर को दोष दें, एक नज़र डालें कि डिस्क दबाव को कम करने के लिए आप क्या कर सकते हैं।
लेखक के बारे में
 मोनिका रथबुन वर्तमान में डेनी चेरी एंड एसोसिएट्स कंसल्टिंग में एक सलाहकार हैं, और एक माइक्रोसॉफ्ट डेटा प्लेटफॉर्म एमवीपी हैं। SQL सर्वर और Oracle के सभी पहलुओं के साथ काम करते हुए, वह 15 वर्षों से एक अकेली DBA रही हैं। वह कई लोगों के काम कैसे कर सकती है, इस पर तकनीकों के साथ अन्य लोन डीबीए की मदद करने के लिए SQLSaturdays में बोलते हुए यात्रा करती है। मोनिका हैम्पटन रोड्स एसक्यूएल सर्वर यूजर ग्रुप की लीडर हैं और मिड-अटलांटिक पास रीजनल मेंटर हैं। आप हमेशा मोनिका को ट्विटर (@SQLEspresso) पर अपने फॉलोअर्स को उपयोगी टिप्स और ट्रिक्स देते हुए पा सकते हैं। जब वह काम में व्यस्त नहीं होती है, तो आप उसे अपनी दो बेटियों के लिए डांस क्लास के लिए टैक्सी ड्राइवर की भूमिका निभाते हुए पाएंगे।
मोनिका रथबुन वर्तमान में डेनी चेरी एंड एसोसिएट्स कंसल्टिंग में एक सलाहकार हैं, और एक माइक्रोसॉफ्ट डेटा प्लेटफॉर्म एमवीपी हैं। SQL सर्वर और Oracle के सभी पहलुओं के साथ काम करते हुए, वह 15 वर्षों से एक अकेली DBA रही हैं। वह कई लोगों के काम कैसे कर सकती है, इस पर तकनीकों के साथ अन्य लोन डीबीए की मदद करने के लिए SQLSaturdays में बोलते हुए यात्रा करती है। मोनिका हैम्पटन रोड्स एसक्यूएल सर्वर यूजर ग्रुप की लीडर हैं और मिड-अटलांटिक पास रीजनल मेंटर हैं। आप हमेशा मोनिका को ट्विटर (@SQLEspresso) पर अपने फॉलोअर्स को उपयोगी टिप्स और ट्रिक्स देते हुए पा सकते हैं। जब वह काम में व्यस्त नहीं होती है, तो आप उसे अपनी दो बेटियों के लिए डांस क्लास के लिए टैक्सी ड्राइवर की भूमिका निभाते हुए पाएंगे।