ओवर और पार्टिशन बाय फंक्शन दोनों फंक्शन हैं जिनका उपयोग निर्दिष्ट मानदंडों के अनुसार परिणाम सेट करने के लिए किया जाता है।
यह लेख बताता है कि कैसे इन दो कार्यों का उपयोग बहुत विशिष्ट तरीकों से विभाजित डेटा को पुनः प्राप्त करने के लिए किया जा सकता है।
कुछ नमूना डेटा तैयार करना
हमारे नमूना प्रश्नों को निष्पादित करने के लिए, पहले "studentdb" नाम का एक डेटाबेस बनाते हैं।
अपनी क्वेरी विंडो में निम्न कमांड चलाएँ:
CREATE DATABASE schooldb;
इसके बाद, हमें "छात्र" डेटाबेस के भीतर "छात्र" तालिका बनाने की आवश्यकता है। छात्र तालिका में पांच कॉलम होंगे:आईडी, नाम, आयु, लिंग और कुल स्कोर।
हमेशा की तरह, नए कोड के साथ प्रयोग करने से पहले सुनिश्चित करें कि आपने अच्छी तरह से बैकअप लिया है। यदि आप सुनिश्चित नहीं हैं तो SQL सर्वर डेटाबेस का बैकअप लेने पर यह लेख देखें।
छात्र तालिका बनाने के लिए निम्न क्वेरी निष्पादित करें।
USE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY IDENTITY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL,
total_score INT NOT NULL,
) अंत में, हमें डेटाबेस में काम करने के लिए कुछ डमी डेटा डालने की आवश्यकता है।
USE schooldb
INSERT INTO student
VALUES ('Jolly', 'Female', 20, 500),
('Jon', 'Male', 22, 545),
('Sara', 'Female', 25, 600),
('Laura', 'Female', 18, 400),
('Alan', 'Male', 20, 500),
('Kate', 'Female', 22, 500),
('Joseph', 'Male', 18, 643),
('Mice', 'Male', 23, 543),
('Wise', 'Male', 21, 499),
('Elis', 'Female', 27, 400); अभी हम किसी समस्या पर काम करने के लिए तैयार हैं और देखते हैं कि इसे हल करने के लिए हम किसके द्वारा ओवर और पार्टिशन बाय का उपयोग कर सकते हैं।
समस्या
हमारे पास छात्र तालिका में 10 रिकॉर्ड हैं और हम सभी छात्रों के लिए नाम, आईडी और लिंग प्रदर्शित करना चाहते हैं, और इसके अलावा हम प्रत्येक लिंग से संबंधित छात्रों की कुल संख्या, औसत आयु भी प्रदर्शित करना चाहते हैं। प्रत्येक लिंग के छात्र और प्रत्येक लिंग के लिए Total_score कॉलम में मानों का योग।
हम जिस परिणाम सेट की तलाश कर रहे हैं, वह इस प्रकार है:
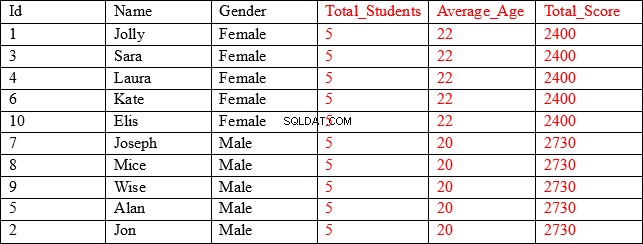
जैसा कि आप देख सकते हैं, पहले तीन कॉलम (काले रंग में दिखाए गए) में प्रत्येक रिकॉर्ड के लिए अलग-अलग मान होते हैं, जबकि अंतिम तीन कॉलम (लाल रंग में दिखाए गए) में लिंग कॉलम द्वारा समूहीकृत समेकित मान होते हैं। उदाहरण के लिए, औसत आयु कॉलम में, पहली पांच पंक्तियां औसत आयु और उन सभी रिकॉर्डों का कुल स्कोर प्रदर्शित करती हैं जहां लिंग महिला है।
हमारे परिणाम सेट में गैर-एकत्रित स्तंभों के साथ जुड़े हुए परिणाम शामिल हैं।
एक विशेष कॉलम के आधार पर समूहीकृत परिणामों को पुनः प्राप्त करने के लिए, हम हमेशा की तरह ग्रुप बाय क्लॉज का उपयोग कर सकते हैं।
USE schooldb SELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
आइए देखें कि हम लिंग के आधार पर छात्रों के कुल_छात्रों, औसत_आयु और कुल_स्कोर को कैसे पुनः प्राप्त कर सकते हैं।
आप निम्नलिखित परिणाम देखेंगे:

अब इसे बढ़ाते हैं और 'आईडी' और 'नाम' (सेलेक्ट स्टेटमेंट में गैर-एकत्रित कॉलम) जोड़ते हैं और देखते हैं कि क्या हम अपना वांछित परिणाम प्राप्त कर सकते हैं।
USE schooldb SELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
जब आप उपरोक्त क्वेरी चलाते हैं, तो आपको एक त्रुटि दिखाई देगी:

त्रुटि कहती है कि छात्र तालिका का आईडी कॉलम सेलेक्ट स्टेटमेंट में अमान्य है क्योंकि हम क्वेरी में ग्रुप बाय क्लॉज का उपयोग कर रहे हैं।
इसका मतलब है कि हमें आईडी कॉलम पर एक एग्रीगेट फंक्शन लागू करना होगा या हमें इसे ग्रुप बाय क्लॉज में इस्तेमाल करना होगा। संक्षेप में, यह योजना हमारी समस्या का समाधान नहीं करती है।
जॉइन स्टेटमेंट का उपयोग करके समाधान
इसका एक समाधान यह होगा कि गैर-समेकित परिणामों वाले कॉलम में समेकित परिणामों वाले कॉलम को जोड़ने के लिए जॉइन स्टेटमेंट का उपयोग किया जाए।
ऐसा करने के लिए, आपको एक उप-क्वेरी की आवश्यकता है जो लिंग, कुल_छात्र, औसत_आयु और लिंग के आधार पर समूहित छात्रों के कुल_स्कोर को पुनः प्राप्त करती है। इन परिणामों को बाहरी चयन कथन के साथ उप-क्वेरी से प्राप्त परिणामों में जोड़ा जा सकता है। इसे उप-क्वेरी के लिंग कॉलम पर लागू किया जाएगा जिसमें समेकित परिणाम और छात्र तालिका के लिंग कॉलम शामिल होंगे। बाहरी सेलेक्ट स्टेटमेंट में नीचे दिए गए गैर-एकत्रित कॉलम यानी 'आईडी' और 'नाम' शामिल होंगे।
USE schooldb SELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_Score FROM student INNER JOIN (SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_Score FROM student GROUP BY gender) AS Aggregation on Aggregation.gender = student.gender
उपरोक्त क्वेरी आपको वांछित परिणाम देगी लेकिन यह इष्टतम समाधान नहीं है। हमें एक जॉइन स्टेटमेंट और एक सब-क्वेरी का उपयोग करना था जो स्क्रिप्ट की जटिलता को बढ़ाता है। यह एक सुंदर या कुशल समाधान नहीं है।
एक बेहतर तरीका है कि ओवर और पार्टिशन बाय क्लॉज को एक साथ इस्तेमाल किया जाए।
ओवर और पार्टिशन का उपयोग करके समाधान
ओवर और पार्टिशन बाय क्लॉज का उपयोग करने के लिए, आपको बस उस कॉलम को निर्दिष्ट करने की आवश्यकता है जिसके द्वारा आप अपने एकत्रित परिणामों को विभाजित करना चाहते हैं। इसे एक उदाहरण के माध्यम से सबसे अच्छी तरह समझाया गया है।
आइए ओवर और पार्टिशन बाय का उपयोग करके अपना परिणाम प्राप्त करने पर एक नज़र डालें।
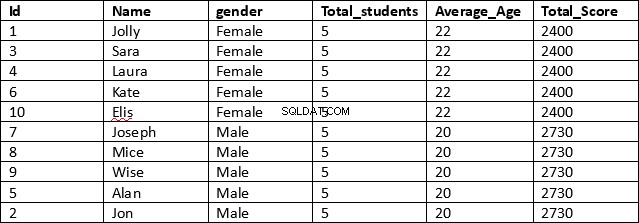
USE schooldb SELECT id, name, gender, COUNT(gender) OVER (PARTITION BY gender) AS Total_students, AVG(age) OVER (PARTITION BY gender) AS Average_Age, SUM(total_score) OVER (PARTITION BY gender) AS Total_Score FROM student
यह बहुत अधिक कुशल परिणाम है। स्क्रिप्ट की पहली पंक्ति में आईडी, नाम और लिंग कॉलम पुनर्प्राप्त किए जाते हैं। इन स्तंभों में कोई समेकित परिणाम नहीं है।
अगला, उन स्तंभों के लिए जिनमें समेकित परिणाम होते हैं, हम केवल समेकित फ़ंक्शन निर्दिष्ट करते हैं, उसके बाद ओवर क्लॉज और फिर कोष्ठक के भीतर हम कॉलम के नाम के बाद पार्टिशन द्वारा निर्दिष्ट करते हैं कि हम चाहते हैं कि हमारे परिणाम दिखाए गए अनुसार विभाजित हों नीचे।
संदर्भ
- माइक्रोसॉफ्ट - ओवर क्लॉज को समझना
- मध्यरात्रि डीबीए - ओवर एंड पार्टिशन का परिचय
- StackOverflow - PARTITION BY और GROUP BY के बीच अंतर