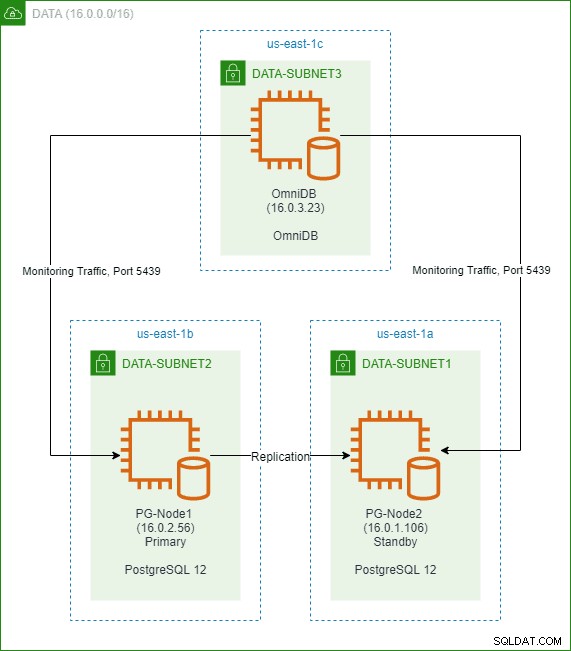
इस श्रृंखला के पिछले लेख में, हमने AWS क्लाउड में दो-नोड PostgreSQL 12 क्लस्टर बनाया था। हमने तीसरे नोड में 2ndQuadrant OmniDB भी स्थापित और कॉन्फ़िगर किया है। नीचे दी गई छवि वास्तुकला को दर्शाती है:
हम ओमनीडीबी के वेब-आधारित यूजर इंटरफेस से प्राथमिक और स्टैंडबाय नोड दोनों से जुड़ सकते हैं। फिर हमने प्राथमिक नोड में "dvdrental" नामक एक नमूना डेटाबेस को पुनर्स्थापित किया जो स्टैंडबाय को दोहराने के लिए शुरू हुआ।
श्रृंखला के इस भाग में, हम सीखेंगे कि ओमनीडीबी में एक मॉनिटरिंग डैशबोर्ड कैसे बनाया जाए और उसका उपयोग कैसे किया जाए। डेटाबेस स्वास्थ्य की दृष्टि से जांच करने के लिए डीबीए और ऑपरेशन टीम अक्सर जटिल प्रश्नों के बजाय ग्राफिकल टूल पसंद करते हैं। OmniDB कई महत्वपूर्ण विजेट्स के साथ आता है जिनका उपयोग मॉनिटरिंग डैशबोर्ड में आसानी से किया जा सकता है। जैसा कि हम बाद में देखेंगे, यह उपयोगकर्ताओं को अपने स्वयं के निगरानी विजेट लिखने की भी अनुमति देता है।
प्रदर्शन निगरानी डैशबोर्ड बनाना
आइए ओमनीडीबी के साथ आने वाले डिफ़ॉल्ट डैशबोर्ड से शुरू करें।
नीचे की छवि में, हम प्राथमिक नोड (PG-Node1) से जुड़े हैं। हम इंस्टेंस नाम पर राइट-क्लिक करते हैं, और फिर पॉप-अप मेनू से "मॉनिटर" चुनें और फिर "डैशबोर्ड" चुनें।
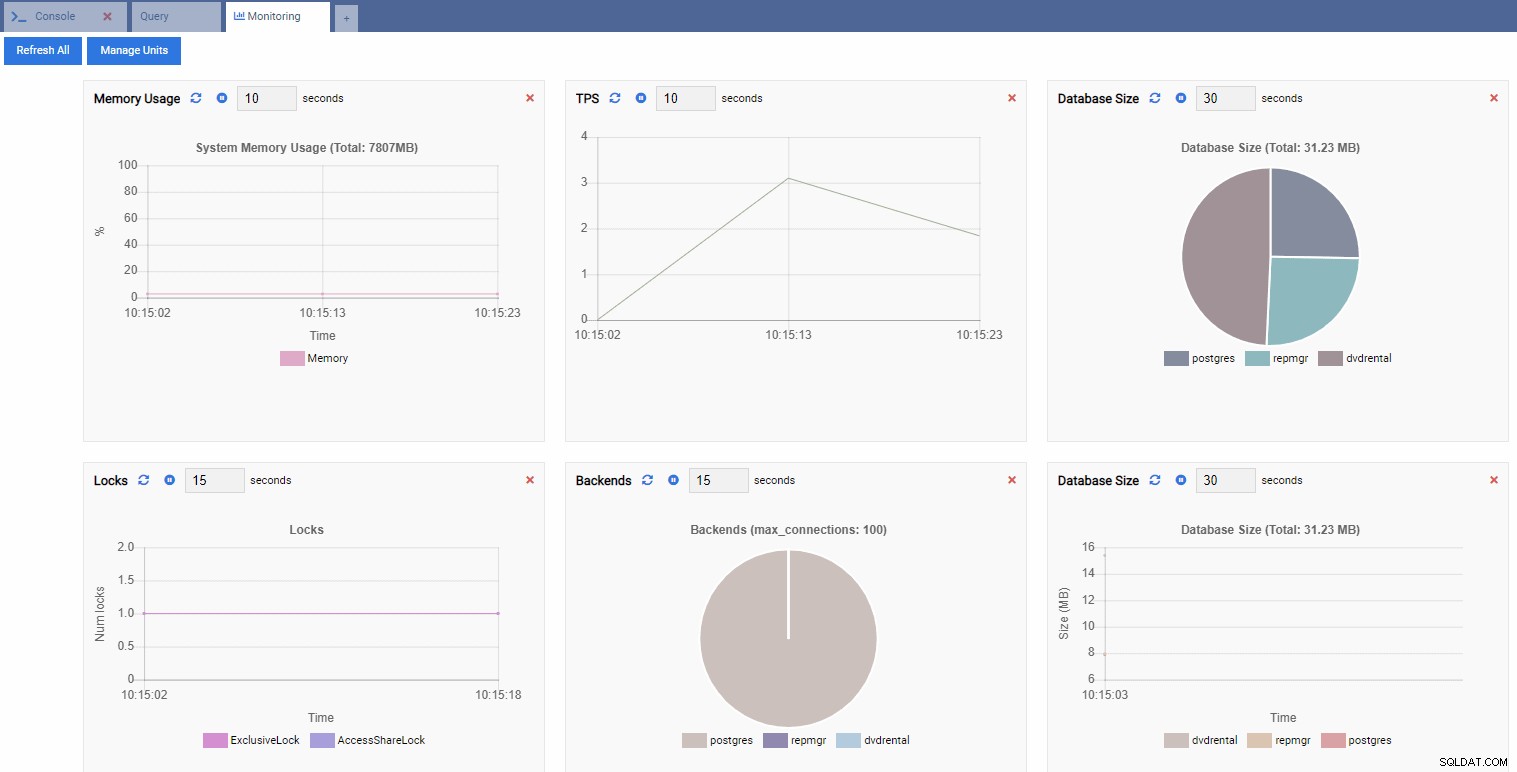
यह कुछ विजेट्स के साथ एक डैशबोर्ड खोलता है।
OmniDB शब्दों में, डैशबोर्ड में आयताकार विजेट को निगरानी इकाइयाँ . कहा जाता है . इनमें से प्रत्येक इकाई PostgreSQL इंस्टेंस से एक विशिष्ट मीट्रिक दिखाती है जिससे यह जुड़ा हुआ है और इसके डेटा को गतिशील रूप से रीफ्रेश करता है।
निगरानी इकाइयों को समझना
OmniDB चार प्रकार की निगरानी इकाइयों के साथ आता है:
- एक ग्रिड एक सारणीबद्ध संरचना है जो एक प्रश्न का परिणाम दिखाती है। उदाहरण के लिए, यह SELECT * FROM pg_stat_replication का आउटपुट हो सकता है। एक ग्रिड इस तरह दिखता है:
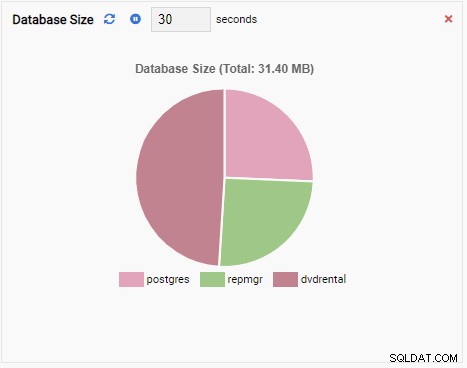
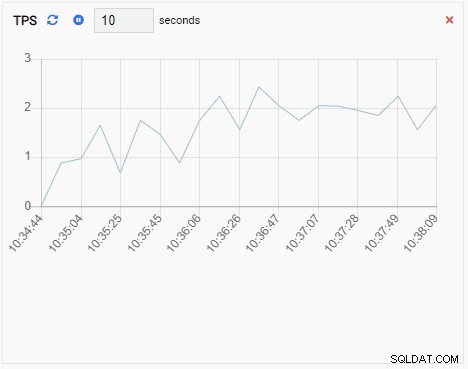
- एक चार्ट डेटा को ग्राफिकल फॉर्मेट में दिखाता है, जैसे लाइन या पाई चार्ट। जब यह रीफ़्रेश होता है, तो पूरे चार्ट को एक नए मान के साथ स्क्रीन पर फिर से खींचा जाता है, और पुराना मान चला जाता है। इन निगरानी इकाइयों के साथ, हम केवल मीट्रिक का वर्तमान मान देख सकते हैं। यहाँ एक चार्ट का उदाहरण दिया गया है:
- एक चार्ट-परिशिष्ट एक चार्ट प्रकार की निगरानी इकाई भी है, जब यह ताज़ा होता है, तो यह मौजूदा श्रृंखला में नया मान जोड़ता है। चार्ट-परिशिष्ट के साथ, हम समय के साथ आसानी से रुझान देख सकते हैं। यहाँ एक उदाहरण है:
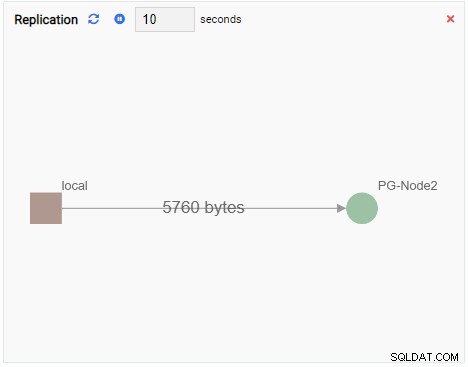
- A ग्राफ़ PostgreSQL क्लस्टर इंस्टेंस और संबंधित मीट्रिक के बीच संबंध दिखाता है। चार्ट मॉनिटरिंग यूनिट की तरह, एक ग्राफ मॉनिटरिंग यूनिट भी अपने पुराने मान को एक नए के साथ ताज़ा करता है। नीचे दिया गया चित्र दिखाता है कि वर्तमान नोड (PG-Node1), PG-Node2 की नकल कर रहा है:
प्रत्येक निगरानी इकाई में कई सामान्य तत्व होते हैं:
- निगरानी इकाई का नाम
- इकाई को मैन्युअल रूप से ताज़ा करने के लिए एक "ताज़ा करें" बटन
- निगरानी इकाई को अस्थायी रूप से ताज़ा करने से रोकने के लिए एक "रोकें" बटन
- वर्तमान रिफ्रेश अंतराल को दर्शाने वाला एक टेक्स्ट बॉक्स। इसे बदला जा सकता है
- मॉनिटरिंग यूनिट को डैशबोर्ड से हटाने के लिए एक "क्लोज़" बटन (रेड क्रॉस मार्क)
- निगरानी का वास्तविक ड्राइंग क्षेत्र
पूर्व-निर्मित निगरानी इकाइयां
OmniDB PostgreSQL के लिए कई मॉनिटरिंग यूनिट्स के साथ आता है जिसे हम अपने डैशबोर्ड में जोड़ सकते हैं। इन इकाइयों तक पहुँचने के लिए, हम डैशबोर्ड के शीर्ष पर "इकाइयों को प्रबंधित करें" बटन पर क्लिक करते हैं:
यह "इकाइयों को प्रबंधित करें" सूची को खोलता है:
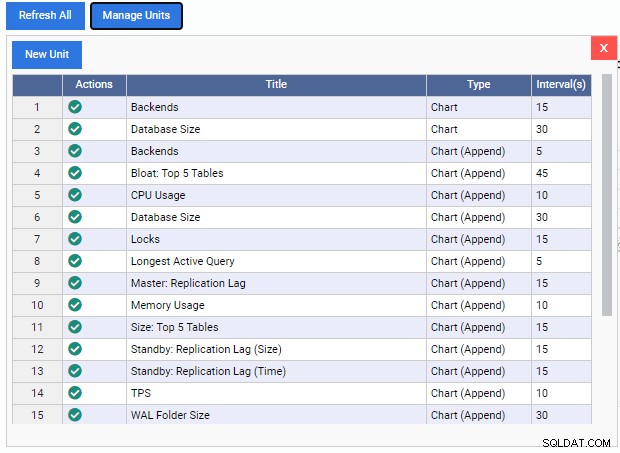
जैसा कि हम देख सकते हैं, यहाँ कुछ पूर्व-निर्मित निगरानी इकाइयाँ हैं। इन निगरानी इकाइयों के लिए कोड 2ndQuadrant के GitHub रेपो से मुफ्त में डाउनलोड किए जा सकते हैं। यहां सूचीबद्ध प्रत्येक इकाई अपना नाम, प्रकार (चार्ट, चार्ट परिशिष्ट, ग्राफ़, या ग्रिड) और डिफ़ॉल्ट ताज़ा दर दिखाती है।
डैशबोर्ड में एक मॉनिटरिंग यूनिट जोड़ने के लिए, हमें बस उस यूनिट के लिए "एक्शन" कॉलम के तहत हरे रंग के टिक मार्क पर क्लिक करना होगा। डैशबोर्ड बनाने के लिए हम अलग-अलग मॉनिटरिंग यूनिट्स को मिक्स एंड मैच कर सकते हैं।
नीचे दी गई छवि में, हमने अपने प्रदर्शन निगरानी डैशबोर्ड के लिए निम्नलिखित इकाइयाँ जोड़ी हैं और बाकी सब कुछ हटा दिया है:
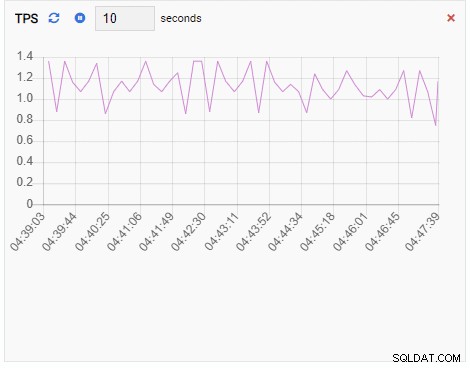
टीपीएस (लेनदेन प्रति सेकंड):
तालों की संख्या:
बैकएंड की संख्या:
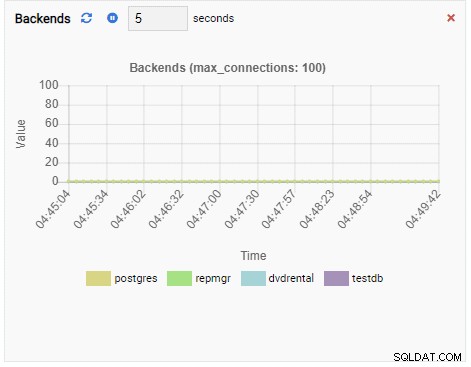
चूँकि हमारा उदाहरण निष्क्रिय है, हम देख सकते हैं कि TPS, Locks, और Backends मान न्यूनतम हैं।
मॉनिटरिंग डैशबोर्ड का परीक्षण करना
अब हम अपने प्राथमिक नोड (PG-Node1) में pgbench चलाएंगे। pgbench एक साधारण बेंचमार्किंग टूल है जो PostgreSQL के साथ शिप करता है। अपनी तरह के अधिकांश अन्य उपकरणों की तरह, pgbench डेटाबेस में एक नमूना OLTP सिस्टम की स्कीमा और टेबल बनाता है जब यह प्रारंभ होता है। उसके बाद, यह कई क्लाइंट कनेक्शनों का अनुकरण कर सकता है, प्रत्येक डेटाबेस पर कई लेन-देन चला रहा है। इस मामले में, हम PostgreSQL प्राथमिक नोड को बेंचमार्क नहीं करेंगे; हम केवल pgbench के लिए डेटाबेस बनाएंगे और देखेंगे कि क्या हमारे डैशबोर्ड मॉनिटरिंग यूनिट सिस्टम स्वास्थ्य में बदलाव को स्वीकार करते हैं।
सबसे पहले, हम प्राथमिक नोड में pgbench के लिए एक डेटाबेस बना रहे हैं:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb";CREATE DATABASE
इसके बाद, हम pgbench के लिए "testdb" डेटाबेस को इनिशियलाइज़ कर रहे हैं:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbपुरानी टेबल को छोड़ना...टेबल बनाना...जनरेट करना डेटा... 2000000 टुपल्स (5%) में से 100000 किया गया (बीता हुआ 0.02 s, शेष 0.43 s) 2000000 tuples (10%) में से 200000 किया गया (बीता हुआ 0.05 s, शेष 0.41 s) …… 2000000 tuples का 2000000 (100%) किया गया (1.84 सेकेंड बीत गया, शेष 0.00 सेकेंड) वैक्यूमिंग...प्राथमिक कुंजी बनाना...हो गया।
डेटाबेस को इनिशियलाइज़ करने के साथ, अब हम वास्तविक लोड प्रक्रिया शुरू करते हैं। नीचे दिए गए कोड स्निपेट में, हम pgbench को testdb डेटाबेस के खिलाफ 50 समवर्ती क्लाइंट कनेक्शन के साथ शुरू करने के लिए कह रहे हैं, प्रत्येक कनेक्शन अपने टेबल पर 100000 लेनदेन चला रहा है। लोड टेस्ट दो थ्रेड में चलेगा।
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbस्टार्टिंग वैक्यूम...एंड……
यदि हम अब अपने OmniDB डैशबोर्ड पर वापस जाते हैं, तो हम देखते हैं कि निगरानी इकाइयाँ कुछ बहुत अलग परिणाम दिखा रही हैं।
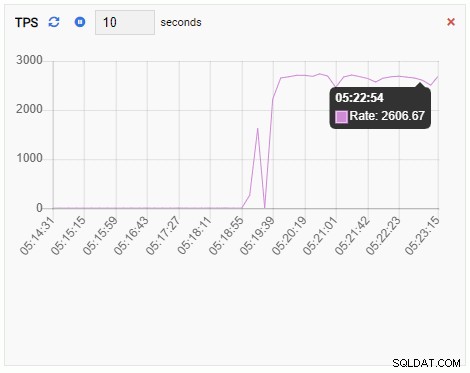
टीपीएस मीट्रिक काफी उच्च मूल्य दिखा रहा है। 2 से कम से 2000 से अधिक की अचानक छलांग है:
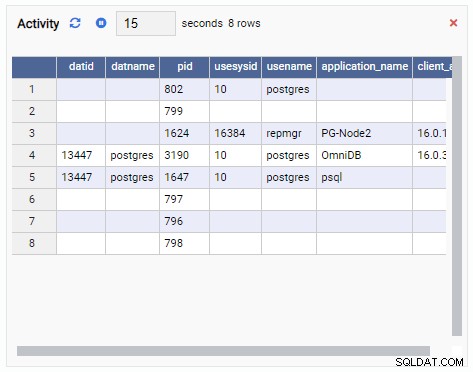
बैकएंड की संख्या में वृद्धि हुई है। जैसा कि अपेक्षित था, टेस्टडीबी के पास इसके खिलाफ 50 कनेक्शन हैं जबकि अन्य डेटाबेस निष्क्रिय हैं:
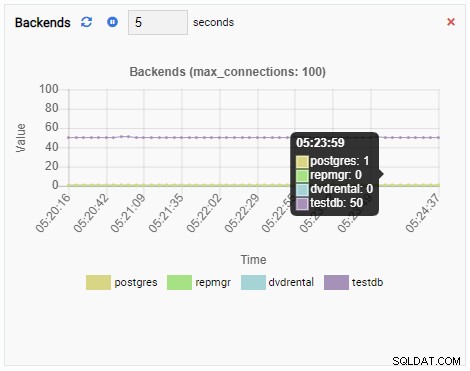
और अंत में, टेस्टडब डेटाबेस में रो एक्सक्लूसिव लॉक की संख्या भी अधिक है:
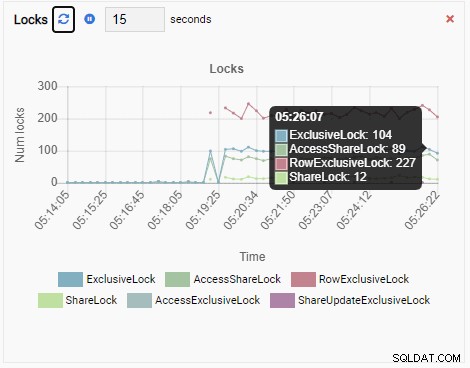
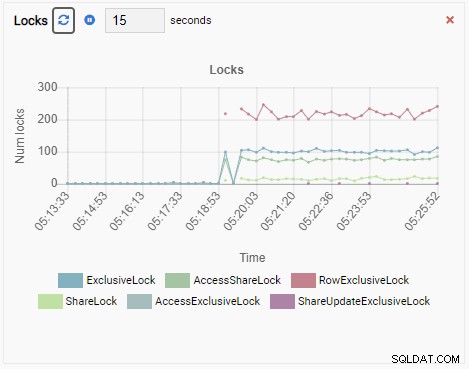
अब यह कल्पना कीजिए। आप एक डीबीए हैं और आप पोस्टग्रेएसक्यूएल इंस्टेंस के बेड़े के प्रबंधन के लिए ओमनीडीबी का उपयोग करते हैं। आपको किसी एक मामले में धीमे प्रदर्शन की जांच करने के लिए कॉल आती है।
डैशबोर्ड का उपयोग करना जैसे हमने अभी देखा (हालांकि यह बहुत आसान है), आप आसानी से मूल कारण ढूंढ सकते हैं। समस्या का कारण क्या है, यह देखने के लिए आप बैकएंड, लॉक, उपलब्ध मेमोरी आदि की संख्या की जांच कर सकते हैं।
और यहीं पर OmniDB वास्तव में सहायक उपकरण हो सकता है।
कस्टम निगरानी इकाइयां बनाना
कभी-कभी हमें अपनी स्वयं की निगरानी इकाइयां बनाने की आवश्यकता होगी। एक नई निगरानी इकाई लिखने के लिए, हम "इकाइयाँ प्रबंधित करें" सूची में "नई इकाई" बटन पर क्लिक करते हैं। यह कोड लिखने के लिए खाली कैनवास के साथ एक नया टैब खोलता है:
स्क्रीन के शीर्ष पर, हमें अपनी निगरानी इकाई के लिए एक नाम निर्दिष्ट करना होगा, इसके प्रकार का चयन करना होगा, और इसके डिफ़ॉल्ट ताज़ा अंतराल को निर्दिष्ट करना होगा। हम एक मौजूदा इकाई को एक टेम्पलेट के रूप में भी चुन सकते हैं।
हेडर सेक्शन में दो टेक्स्ट बॉक्स होते हैं। "डेटा स्क्रिप्ट" संपादक वह जगह है जहां हम अपनी निगरानी इकाई के लिए डेटा प्राप्त करने के लिए कोड लिखते हैं। हर बार जब कोई इकाई रीफ़्रेश की जाती है, तो डेटा स्क्रिप्ट कोड चलेगा. "चार्ट स्क्रिप्ट" संपादक वह जगह है जहां हम वास्तविक इकाई को चित्रित करने के लिए कोड लिखते हैं। यह तब चलाया जाता है जब इकाई पहली बार खींची जाती है।
सभी डेटा स्क्रिप्ट कोड पायथन में लिखे गए हैं। चार्ट प्रकार की निगरानी इकाई के लिए, ओमनीडीबी को चार्ट स्क्रिप्ट को चार्ट.जेएस में लिखे जाने की आवश्यकता है।
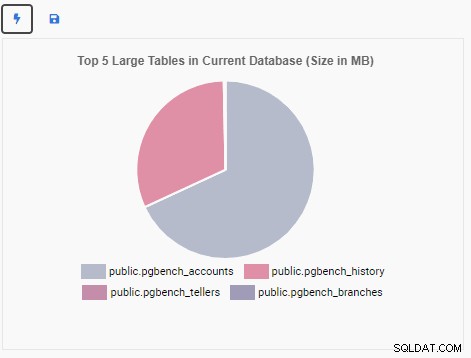
वर्तमान डेटाबेस में शीर्ष 5 बड़ी तालिकाओं को दिखाने के लिए अब हम एक मॉनिटरिंग यूनिट बनाएंगे। OmniDB में चयनित डेटाबेस के आधार पर, मॉनिटरिंग यूनिट उस डेटाबेस में पांच सबसे बड़ी तालिकाओं के नामों को दर्शाने के लिए अपना प्रदर्शन बदल देगी।
एक नई इकाई लिखने के लिए, मौजूदा टेम्पलेट से शुरुआत करना और उसके कोड को संशोधित करना सबसे अच्छा है। इससे समय और मेहनत दोनों की बचत होगी। निम्नलिखित छवि में, हमने अपनी निगरानी इकाई को "शीर्ष 5 बड़ी तालिकाएँ" नाम दिया है। हमने इसे चार्ट प्रकार (कोई परिशिष्ट नहीं) के रूप में चुना है और 30 सेकंड की ताज़ा दर प्रदान की है। हमने अपनी निगरानी इकाई को डेटाबेस आकार टेम्पलेट पर भी आधारित किया है:
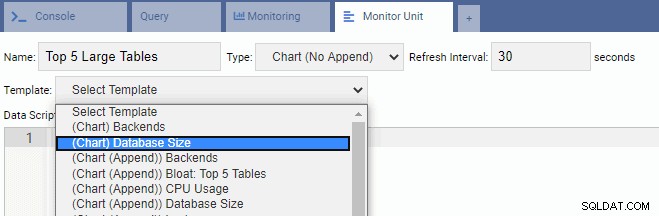
डेटा स्क्रिप्ट टेक्स्ट बॉक्स स्वचालित रूप से डेटाबेस साइज मॉनिटरिंग यूनिट के लिए कोड से भर जाता है:
डेटाटाइम आयात डेटाटाइम से यादृच्छिक आयात randintडेटाबेस =कनेक्शन। क्वेरी (''' d.datname AS डेटानाम चुनें, राउंड (pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS आकार pg_database से pg_database से। datname in ('template0','template1')''')data =[]color =[]label =[]डेटाबेस में db के लिए।पंक्तियाँ: data.append(db["size"]) color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") लेबल.append (db["datname"])total_size =connection.ExecuteScalar(''' चुनें राउंड(योग(pg_catalog.pg_database_size(datname)/1048576.0),2) pg_catalog.pg_database से जहां डेटास्टम्पलेट नहीं है ={' )results ":लेबल, "डेटासेट":[ { "डेटा":डेटा, "पृष्ठभूमि रंग":रंग, "लेबल":"डेटासेट 1" "लेबल":"डेटासेट 1" ] "एमबी)"} और चार्ट स्क्रिप्ट टेक्स्ट बॉक्स भी कोड से भरा होता है:
total_size =connection.ExecuteScalar(''' सिलेक्ट राउंड(योग(pg_catalog.pg_database_size(datname)/1048576.0),2) Pg_catalog.pg_database से जहां" डेटास्टेम्पलेट नहीं '''') परिणाम प्रकार =":" " , "डेटा":कोई नहीं, "विकल्प":{ "उत्तरदायी":सही, "शीर्षक":{ "प्रदर्शन":सही, " ) "पाठ":"डेटाबेस आकार (कुल_ आकार:" + str" } }} डेटाबेस में शीर्ष 5 बड़ी तालिकाएँ प्राप्त करने के लिए हम डेटा स्क्रिप्ट को संशोधित कर सकते हैं। नीचे दी गई स्क्रिप्ट में, हमने SQL कथन को छोड़कर अधिकांश मूल कोड रखा है:
डेटाटाइम आयात डेटाटाइम से यादृच्छिक आयात randinttables =कनेक्शन। क्वेरी (''' nspname चुनें || '।' || "tablename" के रूप में relname, राउंड (pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" pg_class C से बाएं शामिल हों pg_namespace N ON (N.oid =C.relnamespace) जहां nspname नहीं है ('pg_catalog', 'information_schema') और C.relkind <> 'i' और nspname !~t' के रूप में !~p BY 2 DESC LIMIT 5;''')data =[]color =[]label =[]टेबल में टेबल के लिए।पंक्तियां: data.append(table["table_size"]) color.append("rgb(" + str (रैंडिंट(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(table["tablename" ])परिणाम ={ "लेबल":लेबल, "डेटासेट":[ "डेटा":डेटा, "पृष्ठभूमि रंग":रंग, "} " " ]
यहां, हम वर्तमान डेटाबेस में प्रत्येक तालिका और उसके अनुक्रमित का संयुक्त आकार प्राप्त कर रहे हैं। हम परिणामों को अवरोही क्रम में क्रमबद्ध कर रहे हैं और शीर्ष पांच पंक्तियों का चयन कर रहे हैं।
इसके बाद, हम परिणामसेट पर पुनरावृति करके तीन पायथन सरणियों को पॉप्युलेट कर रहे हैं।
अंत में, हम सरणियों के मूल्यों के आधार पर एक JSON स्ट्रिंग बना रहे हैं।
चार्ट स्क्रिप्ट टेक्स्ट बॉक्स में, हमने मूल SQL कमांड को हटाने के लिए कोड को संशोधित किया है। यहां, हम चार्ट के केवल कॉस्मेटिक पहलू को निर्दिष्ट कर रहे हैं। हम चार्ट को पाई प्रकार के रूप में परिभाषित कर रहे हैं और इसके लिए एक शीर्षक प्रदान कर रहे हैं:
परिणाम ={ "प्रकार":"पाई", "डेटा":कोई नहीं, "विकल्प":{ "उत्तरदायी":सच, "शीर्षक":{ " "प्रदर्शन":सच, मौजूदा डेटाबेस में टेबल (आकार एमबी में)" } }}
अब हम लाइटनिंग आइकन पर क्लिक करके यूनिट का परीक्षण कर सकते हैं। यह पूर्वावलोकन ड्राइंग क्षेत्र में नई निगरानी इकाई दिखाएगा:
इसके बाद, हम डिस्क आइकन पर क्लिक करके यूनिट को सेव करते हैं। एक संदेश बॉक्स पुष्टि करता है कि इकाई सहेज ली गई है:

अब हम अपने मॉनिटरिंग डैशबोर्ड पर वापस जाते हैं और नई मॉनिटरिंग यूनिट जोड़ते हैं:
ध्यान दें कि हमारे कस्टम मॉनिटरिंग यूनिट के लिए "एक्शन" कॉलम के तहत हमारे पास दो और आइकन कैसे हैं। एक इसे संपादित करने के लिए है, दूसरा इसे ओमनीडीबी से हटाने के लिए है।
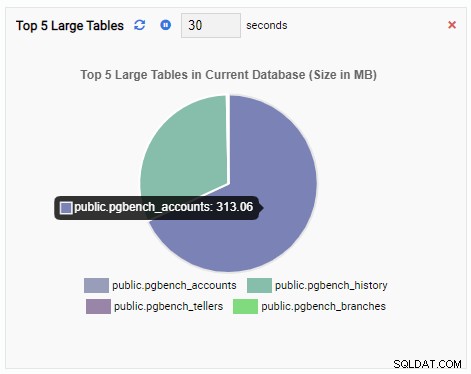
"टॉप 5 लार्ज टेबल्स" मॉनिटरिंग यूनिट अब मौजूदा डेटाबेस में पांच सबसे बड़ी टेबल्स प्रदर्शित करती है:
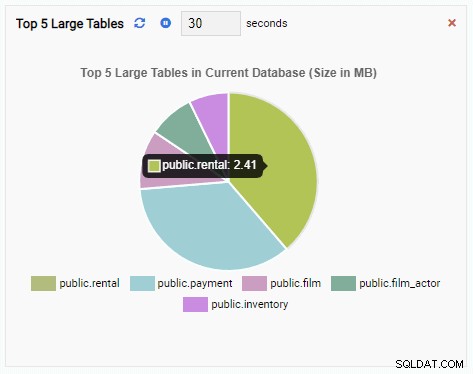
यदि हम डैशबोर्ड को बंद करते हैं, नेविगेशन फलक से दूसरे डेटाबेस पर स्विच करते हैं, और फिर से डैशबोर्ड खोलते हैं, तो हम देखेंगे कि मॉनिटरिंग यूनिट उस डेटाबेस की तालिकाओं को प्रतिबिंबित करने के लिए बदल गई है:
अंतिम शब्द
यह OmniDB पर हमारी दो-भाग श्रृंखला का समापन करता है। जैसा कि हमने देखा, OmniDB में कुछ निफ्टी मॉनिटरिंग इकाइयाँ हैं जो PostgreSQL DBAs प्रदर्शन ट्रैकिंग के लिए उपयोगी साबित होंगी। हमने देखा कि सर्वर में संभावित बाधाओं की पहचान करने के लिए हम इन इकाइयों का उपयोग कैसे कर सकते हैं। हमने यह भी देखा कि अपनी खुद की कस्टम इकाइयाँ कैसे बनाई जाती हैं। पाठकों को उनके विशिष्ट कार्यभार के लिए प्रदर्शन निगरानी इकाइयाँ बनाने और परीक्षण करने के लिए प्रोत्साहित किया जाता है। 2ndQuadrant OmniDB मॉनिटरिंग यूनिट GitHub रेपो में किसी भी योगदान का स्वागत करता है।